【ASE高级软件工程】第二次结对作业
重现baseline
我们选择重现CODEnn模型(论文:Deep Code Search),因为它结构简单、端到端可训练,且相比其它方法拥有较高的性能。
Baseline原理
为了根据给定的query(文本)查询相关的代码,需要计算文本和所有代码之间的相似度,从而选择相似度最高的k个代码作为查询结果。由于文本与代码为异构数据,需要将它们编码到统一的embedding space中。CODEnn是一种端到端模型,用两个encoder分别将文本和代码编码到同一高维空间中,并用cosine similarity计算文本与代码间的相似度。其整体结构可以用下图简要概括:
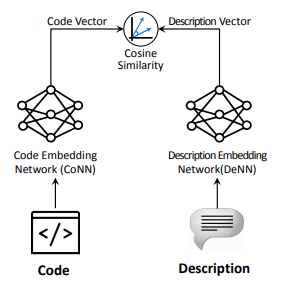
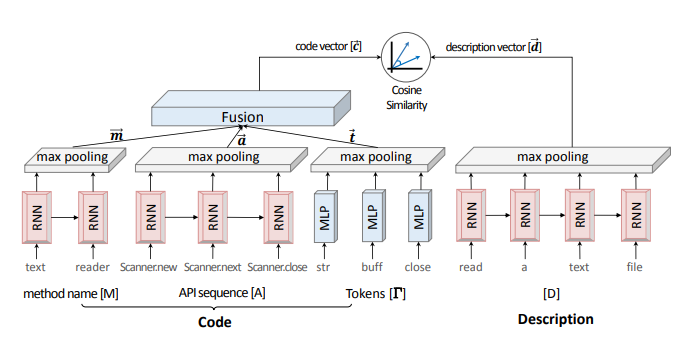
完整结构图如下:
RNN
RNN经常用于编码序列数据,能够有效捕捉序列中不同时刻之间的关联性。其结构如下:
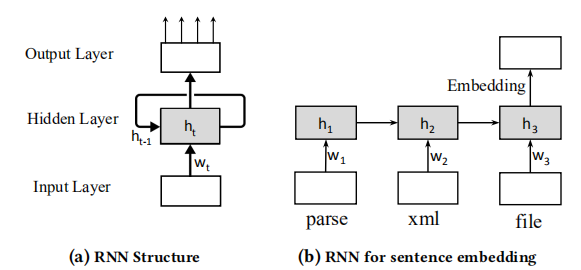
RNN按顺序处理顺序输入数据,用hidden state(图中\(h\))保存上下文信息,从而能够处理不同时刻之间的依赖关系并对序列进行编码。
Code Embedding Network
Code embedding network对代码的三个方面分别编码:method名字、调用的API序列、代码tokens。网络结构如下:
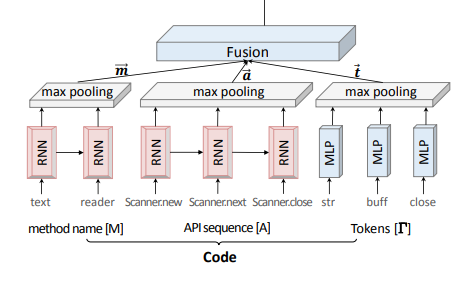
其中:
- method名字可以表示为单词序列 \(M = w_1, w_2, ..., w_{N_M}\),经过RNN模块为每个时间产生一个embedding,再经过max pooling模块,得到序列的embedding向量\(\vec{m}\)。
- API序列 \(A = a_1, a_2, ..., a_{N_A}\) 可以通过AST结构获得。类似method名字,经过RNN模块与max pooling模块编码为向量\(\vec{a}\)。
- 代码中的tokens表示为集合 \(\Gamma = \{ \tau_1, \tau_2, ..., \tau_{N_\Gamma} \}\),因为代码中 tokens 较多、可能重复,不应该表示为序列。因此,\(\Gamma\)不使用RNN编码,直接经过MLP模块与max pooling模块编码为向量\(\vec{t}\)。
最终的code embedding为\(\vec{c} = \text{tanh}(W^C [\vec{m}, \vec{a}, \vec{t}])\)。
Text Embedding Network
文本(query内容,或对代码的描述)可以表示为单词序列\(D = w_1, w_2, ..., w_{N_D}\),因此也使用RNN与max pooling模块编码为向量\(\vec{d}\)。
相似度计算
本文采用余弦相似度作为向量相似度指标:
\[sim(\vec{c}, \vec{d}) = cos(\vec{c}, \vec{d}) = \frac{\vec{d}^T \vec{d}}{\|\vec{c}\| \|\vec{d}\|}\]
比起L2距离,余弦相似度能够不受向量尺度影响,而更好地表征两个向量之间的相似度。详见Cosine Similarity – Understanding the math and how it works (with python codes)。
训练
训练过程中,每个样本包含一段代码\(\vec{c}\)、代码的正确描述\(\vec{d}_+\)和随机采样的一段错误描述\(\vec{d}_-\)。采用triplet loss的思路设计损失函数:
\[L(\vec{c}, \vec{d}) = \max (0, \epsilon - cos (\vec{c}, \vec{d}_+) + cos (\vec{c}, \vec{d}_-) ) \]
其目的在于增大代码\(\vec{c}\)与正确描述\(\vec{d}_+\)之间的相似度、减小代码\(\vec{c}\)与错误描述\(\vec{d}_-\)之间的相似度,且增大相似度的margin、使之大于\(\epsilon\),从而使正确样本与错误样本易于分辨。可以参考下图:

模型优缺点
优点:
- 将代码与文本两种不同domain的数据编码到同一个高维空间里,从而能够直接计算相似度
- 模型经过端到端训练,比rule-based methods能更好地捕捉代码或文本的语义
缺点:
- 个人认为,code embedding network只对代码的三个方面(method名字、调用的API序列、代码tokens)编码,利用的信息不够多。且代码的语义比较微妙,更改少数几个token就可能对整体语义产生较大的影响,这样的编码方式不能充分编码代码语义。
- 干净的数据量太少:大部分代码没有完整的描述,质量高的(code, description) pair较少,不足以训练参数较多的RNN网络。
模型重现结果
我们将模型训练了200个epochs,在第200个epochs处在测试集上对模型进行了测试。测试结果如下,其中k表示选择的搜索结果数量:
| k | Success Rate | MAP | nDCG |
|---|---|---|---|
| 1 | 0.28 | 0.28 | 0.28 |
| 5 | 0.55 | 0.39 | 0.42 |
| 10 | 0.68 | 0.40 | 0.46 |
可以看出,随k增大,模型各项性能都更好;然而我们没有复现原repo结果,原因未知。
可视化
我们通过PCA将code embedding与text embedding投影到二维;下图为所有测试数据的embedding的散点图。
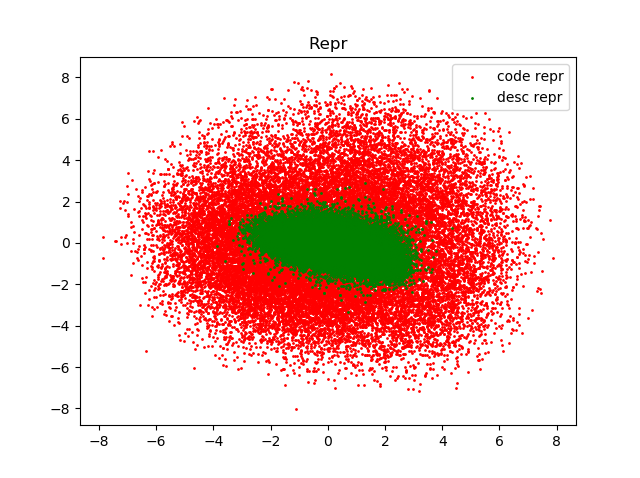
可以看出,code embedding与text embedding尺度上不完全一致,这进一步印证选择cosine similarity衡量相似度是正确的。
我们绘制了测试集中部分代码embedding与其描述的embedding在embedding space中的分布。下面两幅图表示code 0、desc 0、code 1、desc 1的embedding分别在原始embedding space中与L2归一化后的embedding space中分布,其中desc 0为"manage pende entry",code 0为其对应代码;desc 1为"Read mesh datum file",code 1为其对应代码。
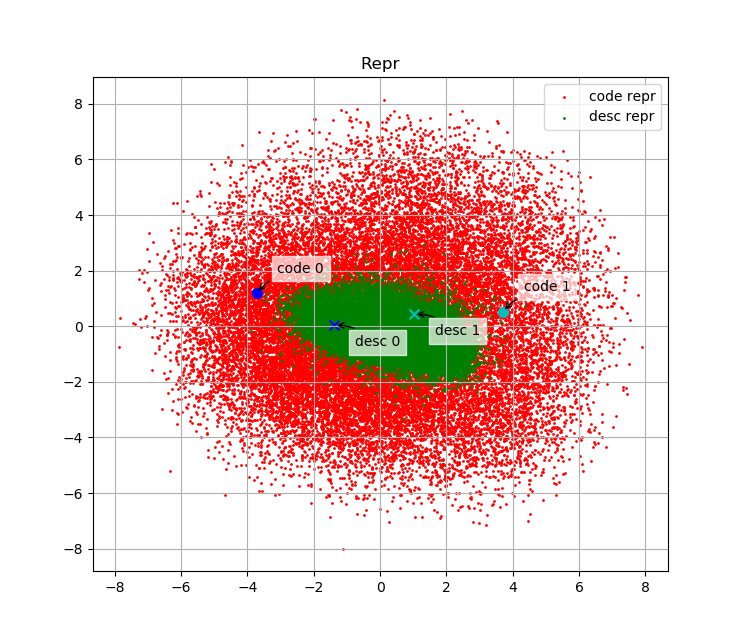
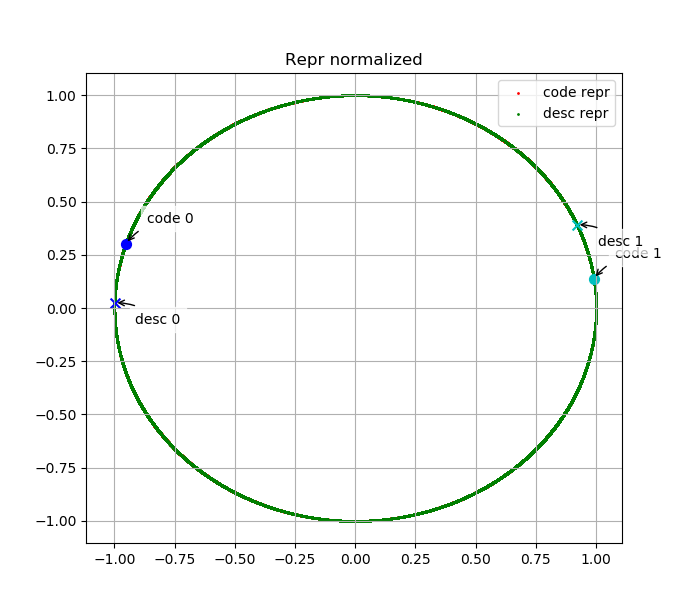
可以看出,语义上相关的代码与文本embedding相似度高、无关的代码或文本embedding相似度低,说明我们的模型是有效的。
改进方法
我个人认为CODEnn框架end-to-end training的思路很好,但是对code和对文本的embedding方式可以改进。另外,模型的评估方式也有一定的问题。我能想到的改进方法如下:
改用更好的encoder
如缺点中所说,我认为CODEnn的code embedding network不能充分编码代码语义。个人认为可以改为其它能够捕捉更多信息的code embedding方法,如code2vec;或者,由于代码可以表示为ast树形结构,可以用Tree LSTM或GNN。
预训练模型
同样如缺点中所说,质量高的(code, description) pair较少,即可以用于将代码embedding与文本embedding投影到同一个embedding space的数据较少;然而无监督的数据,无论是代码(github上有大量开源代码)还是文本(互联网上无监督语料极多)都几乎是无限的。我们可以用已有的大量无监督代码训练encoder、使之已经能表达一定的语义,然后在(code, description) pair数据上进行finetuning。
预训练text embedding network
用语言模型对language encoder进行预训练是NLP中的常用方法。网络上,LSTM和更新的Transformer都有相应的预训练模型发布;也可以自己用与代码有关的文本语料(如爬取stackoverflow的文本)预训练一个模型。
预训练code embedding network
对于如何训练code embedding network,有两种可能的思路:
- 利用有监督数据训练,如code2vec利用代码的属性作为监督,训练code embedding方法。code2vec自己也有发布预训练模型,可以直接使用。
- 训练“语言模型”:这个方法由黄志鹏同学提出,可以用类似NLP中语言模型预训练的方法,通过mask掉代码中的某一行或一个token、要求模型通过上下文预测被mask的部分。现在也有一些类似的工作(如The Effectiveness of Pre-trained Code Embeddings),但是效果并不算好。
Finetuning
对于如何finetune预训练好的模型,也有多种可能的思路:
- 直接将预训练模型放入完整模型进行训练:最直观的方法,但由于预训练模型可能将代码和文本编码到不同的子空间,直接训练可能会大幅改变预训练模型参数、破坏预训练模型捕捉到的语义
- 将预训练模型参数固定,在模型后加入线性变换(参数不固定),作为embedding network放入完整模型进行训练:个人觉得更合理的方法,虽然引入了更多的参数,但是。如果需要对预训练模型本身进一步微调,可以在模型收敛后,再对整个模型进行训练,从而不至于破坏预训练模型捕捉的语义。
模型评估
由于code search这个问题缺乏benchmark数据库,对于给定的搜索结果难以判断其搜索质量,因此较难进行评估。
我们实验中,为了评估模型的质量,我们利用测试集中的(code, desc) pair评估模型搜索结果的准确性,即假设一段文本仅对应一段代码;但实际使用中,由于存在大量代码、代码之间会有关联甚至重复,一段文本可以对应多段代码,这样的评估方法无法准确评价模型性能。CODEnn中,为了计算不同k下的precision,作者邀请了少量评审人员对少量的搜索结果打分,但这样对模型的评估不确定性大、主观性强。
在该领域具备足够的benchmark dataset之前,可能的解决方法是评估时增加人手。
评价合作伙伴
这次因为一点意外,我中途加入了黄志鹏同学和许嘉琪同学的队伍,如果打扰到了两位同学原本的合作节奏对两位同学表示歉意~
两位合作伙伴都非常好。黄志鹏同学代码能力很强,我们的参考代码中有一些bug,他很快修复了代码、搭出了一个可以实验的demo。许嘉琪同学对论文的理解和数理基础都很深,我们的一迷惑都经过跟他讨论得到了很好的解答。我们共有的一个问题是时间管理不够好、没有很好地预先规划,训练模型的时间太长,以至于发现模型效果不好之后没有充分的时间调参,导致我们发现这一点我们以后会尽量改进。

【ASE高级软件工程】第二次结对作业的更多相关文章
- 【ASE高级软件工程】第一次结对作业
问题定义 具体规则见:讲义.大致规则如下: N个同学(N通常大于10),每人写一个0~100之间的有理数 (不包括0或100),交给裁判,裁判算出所有数字的平均值,然后乘以0.618(所谓黄金分割常数 ...
- ASE —— 第二次结对作业
目录 重现基线模型 基线模型原理 模型的优缺点 模型重现结果 提出改进 改进动机 新模型框架 评价合作伙伴 重现基线模型 基线模型原理 我们选用的的模型为DeepCS,接下来我将解释一下它的原理. 我 ...
- 2016福州大学软件工程第二次团队作业——预则立&&他山之石成绩统计
第二次团队作业--预则立&&他山之石成绩统计结果如下: T:团队成绩 P:个人贡献比 T+P:折算个人成绩,计算公式为T+T/15*团队人数*P 学号 组别 Team P T+P 03 ...
- ASE高级软件工程 第一次结对作业
黄金点游戏Bot Bot8前来报道 1.问题定义 a) 问题描述 N个玩家,每人写一个0~100之间的有理数 (不包括0或100),提交给服务器,服务器在当前回合结束时算出所有数字的平均值,然后乘以0 ...
- ASE高级软件工程 第一周博客作业
1.自我介绍 我叫姚顺,是来自哈尔滨工业大学计算机学院的一名大四本科生,专业方向计算机科学,目前在KC组实习.平时的业余时间主要用来打篮球,听音乐,跑步,当然还有游戏(划掉).之前的大学三年主要用来做 ...
- 高级软件工程第二次作业:随机生成N个不重复的已解答完毕的数独棋盘
#include <stdio.h> #include "SuduCheck.h" ][],int i,int j,int k) //判断是否可以将第i行.第j列的数设 ...
- ASE code search -- 第二次结对编程作业
baseline 复现 baseline模型 我们再这次实验中选择了deep code search方法作为了解并复现.下面介绍一下这两种方法 deep code search 模型的结构在论文中已经 ...
- 第二次结对作业-WordCount进阶需求
原博客 队友博客 github项目地址 目录 具体分工 需求分析 PSP表格 解题思路描述与设计实现说明 爬虫使用 代码组织与内部实现设计(类图) 算法的关键与关键实现部分流程图 附加题设计与展示 设 ...
- 高级软件工程第三次作业 赵坤&黄亦薇
0.小组成员 赵坤2017282110261 黄亦薇201728210260 1.项目Github地址 https://github.com/zkself/homework3 PS:建议使用chro ...
随机推荐
- python根据数组数据绘图
转载自网络,版权归原作者所有 hello3.txt文件内部数据如下 ......7,2,6,-12,-10,-7,-1,2,9,...... python脚本 import numpy as np i ...
- 使用redis做为MySQL的缓存-C语言编写UDF
介绍 在实际项目中,MySQL数据库服务器有时会位于另外一台主机,需要通过网络来访问数据库:即使应用程序与MySQL数据库在同一个主机中,访问MySQL也涉及到磁盘IO操作(MySQL也有一些数据预读 ...
- python reduce和偏函数partial
functools模块 reduce方法: reduce方法 reduce方法,顾名思义就是减少 可迭代对象不能为空,初始值没提供就在可迭代对象中去一个元素 from functools import ...
- CSS3 @font-face详细用法
@font-face是CSS3中的一个模块,他主要是把自己定义的Web字体嵌入到你的网页中,随着@font-face模块的出现,我们在Web的开发中使用字体就不用再为只能使用Web安全字体烦恼了!肯定 ...
- 【Leetcode_easy】703. Kth Largest Element in a Stream
problem 703. Kth Largest Element in a Stream 题意: solution1: priority_queue这个类型没有看明白... class KthLarg ...
- JsonSchema用法
JsonSchema用法 简介 JSON Schema是基于JSON格式,用于定义JSON数据结构以及校验JSON数据内容.JSON Schema官网地址:http://json-schema.org ...
- vue中的$listeners属性作用
一.当组件的根元素不具备一些DOM事件,但是根元素内部元素具备相对应的DOM事件,那么可以使用$listeners获取父组件传递进来的所有事件函数,再通过v-on="xxxx"绑定 ...
- mybatis 找不到映射器xml文件 (idea)
原因是: idea不会编译src的java目录的xml文件 所以解决思路就是:将IDEA maven项目中src源代码下的xml等资源文件编译进classes文件夹 具体操作方法就是:配置maven的 ...
- eNSP——OSPF的基础配置
原理: 模拟实验: 拓扑图: 实验编址: 1.基本配置 根据实验编址和拓扑图进行基本配置,并测试连通性. 2.部署OSPF网络 首先使用ospf命令创建并运行OSPF,1代表进程号 接着使用area命 ...
- python3.7 完美安装
在安装python3.7的过程中,我发现如果不加注意,pip3是无法被安装的.而这就不能算是完整安装python3了. 所以,我总结一下,如何完美安装python3.7. 依赖 yum insta ...