正则表达式 第五篇:C# 正则表达式
本文整理C#正则表达式的元字符,正则表达式是由字符构成的表达式,每个字符代表一个规则,表达式中的字符分为两种类型:普通字符和元字符。普通字符是指字面含义不变的字符,按照完全匹配的方式匹配文本,而元字符具有特殊的含义,代表一类字符。
把文本看作是字符流,每个字符放在一个位置上,例如,正则表达式 “Room\d\d\d”,前面四个字符Room是普通字符,后面的字符\是转义字符,和后面的字符d组成一个元字符\d,表示该位置上有任意一个数字。
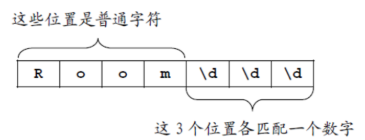
用正则表达式的语言来描述是:正则表达式 “Room\d\d\d”共捕获7个字符,表示“以Room开头、以三个数字结尾”的一类字符串,我们把这一类字符串称作一个模式(Pattern),也称作是一个正则。
一,转义字符
转义字符是\,把普通字符转义为具有特殊含义的元字符,常用的转义字符有:
- \t:水平制表符
- \v:垂直制表符
- \r:回车
- \n:换行
- \\:表示字符 \,也就说,把转义字符 \ 转义为普通的字符 \
- \":表示字符 ",在C#中,双引号用于定义字符串,字符串包含的双引号用 \" 来表示
二,字符类
在进行正则匹配时,把输入文本看作是有顺序的字符流,字符类元字符匹配的对象是字符,并会捕获字符。所谓捕获字符是指,一个元字符捕获的字符,不会被其他元字符匹配,后续的元字符只能从剩下的文本中重新匹配。
常用的字符类元字符:
- [ char_group]:匹配字符组中的任意一个字符
- [^char_group]:匹配除字符组之外的任意一个字符
- [first-last]:匹配从first到last的字符范围中的任意一个字符,字符范围包括first和last。
- . :通配符,匹配除\n之外的任意一个字符
- \w:匹配任意一个单词(word)字符,单词字符通常是指A-Z、a-z和0-9
- \W:匹配任意一个非单词字符,是指除A-Z、a-z和0-9之外的字符
- \s:匹配任意一个空白字符
- \S:匹配任意一个非空白字符
- \d:匹配任意一个数字字符
- \D:匹配任意一个非数字字符
注意,转义字符也属于字符类元字符,在进行正则匹配时,也会捕获字符。
三,定位符
定位符匹配(或捕获)的对象是位置,它根据字符的位置来判断模式匹配是否成功,定位符不会捕获字符,是零宽的(宽度为0),常用的定位符有:
- ^:默认情况下,匹配字符串的开始位置;在多行模式下,匹配每行的开始位置;
- $:默认情况下,匹配字符串的结束位置,或 字符串结尾的\n之前的位置;在多行模式下,匹配每行结束之前的位置,或者每行结尾的\n之前的位置。
- \A:匹配字符串的开始位置;
- \Z:匹配字符串的结束位置,或 字符串结尾的\n之前的位置;
- \z:匹配字符串的结束位置;
- \G:匹配上一个匹配结束的位置;
- \b:匹配一个单词的开始或结束的位置;
- \B:匹配一个单词的中间位置;

四,量词、贪婪和懒惰
量词是指限定前面的一个正则出现的次数,量词分为两种模式:贪婪模式和懒惰模式,贪婪模式是指匹配尽可能多的字符,而懒惰模式是指匹配尽可能少的字符。默认情况下,量词处于贪婪模式,在量词的后面加上?来启用懒惰模式。
- *:出现0次或多次
- +:出现1次或多次
- ?:出现0次或1次
- {n}:出现n次
- {n,}:出现至少n次
- {n,m}:出现n到m次
注意,出现多次是指前面的元字符出现多次,例如,\d{2} 等价于 \d\d,只是出现两个数字,并不要求两个数字是相同的。要表示相同的两个数字,必须使用分组来实现。

五,分组和捕获字符
() 括号不仅确定表达式的范围,还创建分组,()内的表达式就是一个分组,引用分组表示两个分组匹配的文本是完全相同的。定义一个分组的基本语法:
(pattern)
该类型的分组会捕获字符,所谓捕获字符是指:一个元字符捕获的字符,不会被其他元字符匹配,后续的元字符只能从剩下的文本中重新匹配。
1,分组编号和命名
默认情况下,每个分组自动分配一个组号,规则是:从左向右,按分组左括号的出现顺序进行编号,第一个分组的组号为1,第二个为2,以此类推。也可以为分组指定名称,该分组称作命名分组,命名分组也会被自动编号,编号从1开始,逐个加1,为分组指定名称的语法是:
(?<name>pattern)
通常来说,分组分为命名分组和编号分组,引用分组的方式有:
- 通过分组名称来引用分组:\k<name>
- 通过分组编号来引用分组:\number
注意,分组只能后向引用,也就是说,从正则表达式文本的左边开始,分组必须先定义,然后才能在定义之后面引用。
在正则表达式里引用分组的语法为“\number”,比如“\1”代表与分组1 匹配的子串,“\2”代表与分组2 匹配的字串,以此类推。
例如,对于 "<(.*?)>.*?</\1>" 可以匹配 <h2>valid</h2>,在引用分组时,分组对应的文本是完全相同的。
2,分组构造器
分组构造方法如下:
- (pattern):捕获匹配的子表达式,并为分组分配一个组号
(?<name>pattern):把匹配的子表达式捕获到命名的分组中(?:pattern):非捕获的分组,并未分组分配一个组号(?>pattern):贪婪分组
3,贪婪分组
贪婪分组也称作非回溯分组,该分组禁用了回溯,正则表达式引擎将尽可能多地匹配输入文本中的字符。如果无法进行进一步的匹配,则不会回溯尝试进行其他模式匹配。
(?> pattern )
4,二选一
| 的意思是或,匹配两者中的任意一个,注意,|把左右两边的表达式分为两部分。
pattern1 | pattern2
六,零宽断言
零宽是指宽度为0,匹配的是位置,所以匹配的子串不会出现在匹配结果中,而断言是指判断的结果,只有断言为真,才算匹配成功。
对于定位符,可以匹配一句话的开始、结束(^ $)或者匹配一个单词的开始、结束(\b),这些元字符只匹配一个位置,指定这个位置满足一定的条件,而不是匹配某些字符,因此,它们被成为 零宽断言。所谓零宽,指的是它们不与任何字符相匹配,而匹配一个位置;所谓断言,指的是一个判断,正则表达式中只有当断言为真时才会继续进行匹配。零宽断言可以精确的匹配一个位置,而不仅仅是简单的指定句子或者单词。
正则表达式把文本看作从左向右的字符流,向右叫做后向(Look behind),向左叫做前向(Look ahead)。对于正则表达式,只有当匹配到指定的模式(Pattern)时,断言为True,叫做肯定式,把不匹配模式为True,叫做否定式。
按照匹配的方向和匹配的定性,把零宽断言分为四种类型:
(?=pattern):前向、肯定断言(?!pattern):前向、否定断言(?<=pattern):后向、肯定断言(?<!pattern):后向、否定断言
1,前向肯定断言
前向肯定断言定义一个模式必须存在于文本的末尾(或右侧),但是该模式匹配的子串不会出现在匹配的结果中,前向断言通常出现在正则表达式的右侧,表示文本的右侧必须满足特定的模式:
(?=subexpression)
使用前向肯定断言可以定一个模糊匹配,后缀必须包含特定的字符:
\b\w+(?=\sis\b)
对正则表达式进行分析:
- \b:表示单词的边界
- \w+:表示单词至少出现一次
- (?=\sis\b):前向肯定断言,\s 表示一个空白字符, is 是普通字符,完全匹配,\b 是单词的边界。
从分析中,可以得出,匹配该正则表达式的文本中必须包含 is 单词,is是一个单独的单词,不是某一个单词的一个部分。举个例子
Sunday is a weekend day 匹配该正则,匹配的值是Sunday,而The island has beautiful birds 不匹配该正则。
2,后向肯定断言
后向肯定断言定义一个模式必须存在于文本的开始(或左侧),但是该模式匹配的子串不会出现在匹配的结果中,后向断言通常出现在正则表达式的左侧,表示文本的左侧必须满足特定的模式:
(?<= subexpression )
使用后向肯定断言可以定一个模糊匹配,前缀必须包含特定的字符:
(?<=\b20)\d{}\b
对正则表达式进行分析:
- (?<=\b20):后向断言,\b表示单词的开始,20是普通字符
- \d{2}:表示两个数字,数字不要求相同
- \b:单词的边界
该正则表达式匹配的文本具备的模式是:文本以20开头、以两个数字结尾。
七,用正则从格式化的文本中扣值
有如下的JSON格式的文本,从文本中扣出字段(CustomerId、CustomerName、CustomerIdSource和CustomerType)的值:
{"CustomerDetails":"[{\"CustomerId\":\"57512f19\",\"CustomerName\":\"cust xyz\",\"CustomerIdSource\":\"AadTenantId\",\"CustomerType\":\"Enterprise\"}]"}
注意,该文本转换为C#中的字符时,需要对双引号和转义字符进行转义。由于这四个字段提取规则相同,可以写一个通用的模式来提取:
public static string GetNestedItem(string txt, string key)
{
string pat = string.Format("(?<=\\\\\"{0}\\\\\":\\\\\").*?(?=\\\\\")", key);
return Regex.Match(txt, pat, RegexOptions.IgnoreCase).Value;
}
正则表达式得解析:
- (?<=\\\\\"{0}\\\\\":\\\\\"):后向断言,用于匹配字段名、双引号和冒号
- .*?:懒惰模式,匹配尽可能少的文本
- (?=\\\\\"):前向断言,用于匹配字段值得双引号
参考文档:
Regular Expression Language - Quick Reference
正则表达式 第五篇:C# 正则表达式的更多相关文章
- 正则表达式 第五篇:C# 正则元字符
本文整理C#正则表达式的元字符,正则表达式是由字符构成的表达式,每个字符代表一个规则,表达式中的字符分为两种类型:普通字符和元字符.普通字符是指字面含义不变的字符,按照完全匹配的方式匹配文本,而元字符 ...
- Lex与Yacc学习(五)之正则表达式篇
正则表达式语法 lex模式是由编辑程序和实用程序使用的正则表达式的扩展版本.正则表达式由常规字符(代表它们本身)和元字符(在一种模式中具有特殊含义)组成. 元字符 . . 匹配除了换行符 \n 之外的 ...
- JavaScript中的正则表达式(终结篇)
JavaScript中的正则表达式(终结篇) 在之前的几篇文章中,我们了解了正则表达式的基本语法,但那些语法不是针对于某一个特定语言的.这篇博文我们将通过下面几个部分来了解正则表达式在JavaScri ...
- Java正则表达式入门基础篇
正则表达式是一种可以用于模式匹配和替换的规范,一个正则表达式就是由普通的字符(例如字符a到z)以及特殊字符(元字符)组成的文字模式,它 用以描述在查找文字主体时待匹配的一个或多个字符串.正则表达式作为 ...
- Linux基础篇,正则表达式
一.正则表达式特殊符号: 二.grep的用法 grep [-A|B|a|c|i|n|v] [--color=auto] '搜索字串' filename -A ===> after缩写,后面接数字 ...
- [Python笔记]第九篇:re正则表达式
一.正则表达式基础 1.正则表达式介绍 正则表达式并不是Python的一部分.正则表达式是用于处理字符串的强大工具,拥有自己独特的语法以及一个独立的处理引擎,效率上可能不如str自带的方法,但功能十分 ...
- 【Python之路】特别篇--Python正则表达式
正则表达式的基础 正则表达式并不是Python的一部分. 正则表达式是用于处理字符串的强大工具,拥有自己独特的语法以及一个独立的处理引擎,效率上可能不如str自带的方法,但功能十分强大. 得益于这一点 ...
- 【Python五篇慢慢弹】快速上手学python
快速上手学python 作者:白宁超 2016年10月4日19:59:39 摘要:python语言俨然不算新技术,七八年前甚至更早已有很多人研习,只是没有现在流行罢了.之所以当下如此盛行,我想肯定是多 ...
- 【Python五篇慢慢弹(5)】类的继承案例解析,python相关知识延伸
类的继承案例解析,python相关知识延伸 作者:白宁超 2016年10月10日22:36:57 摘要:继<快速上手学python>一文之后,笔者又将python官方文档认真学习下.官方给 ...
随机推荐
- pwn学习日记Day13 《程序员的自我修养》读书笔记
重定位就是把程序的逻辑地址空间变换成内存中的实际物理地址空间的过程.它是实现多道程序在内存中同时运行的基础.重定位有两种,分别是动态重定位与静态重定位. 静态重定位:即在程序装入内存的过程中完成,是指 ...
- Hive-概述
Hive:由 Facebook 开源用于解决海量结构化日志的数据统计. Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类 SQL 查询功能. 本质是:将 ...
- [转][C#].Net反编译利器
来自:https://www.cnblogs.com/zsuxiong/p/5117465.html 有以下8款非常不错的.Net反编译利器: 1.Reflector Reflector是最为流行的. ...
- LC 987. Vertical Order Traversal of a Binary Tree
Given a binary tree, return the vertical order traversal of its nodes values. For each node at posit ...
- MySQLUNION_连接两个以上的 SELECT 语句的结果组合到一个结果集合
MySQL UNION 操作符用于连接两个以上的 SELECT 语句的结果组合到一个结果集合中.多个 SELECT 语句会删除重复的数据. 描述 MySQL UNION 操作符用于连接两个以上的 SE ...
- [Java读书笔记] Effective Java(Third Edition) 第 6 章 枚举和注解
Java支持两种引用类型的特殊用途的系列:一种称为枚举类型(enum type)的类和一种称为注解类型(annotation type)的接口. 第34条:用enum代替int常量 枚举是其合法值由一 ...
- c++ for each
#include <iostream>#include <vector>#include <list> using namespace std; int main( ...
- Linq Introduce
Linq学习网址: http://www.java2s.com/Code/CSharp/LINQ/CatalogLINQ.htm
- dbtreeview
http://www.delphipages.com/comp/dynamic_dbtreeview-6302.html https://files.cnblogs.com/files/jijm123 ...
- Kibana——安装部署
1.准备 JDK:1.8版本及以上: Kibana:6.2.4版本: 2.安装 2.1.下载解压 wget https://artifacts.elastic.co/downloads/kibana/ ...