小记---------spark优化之更优分配资源
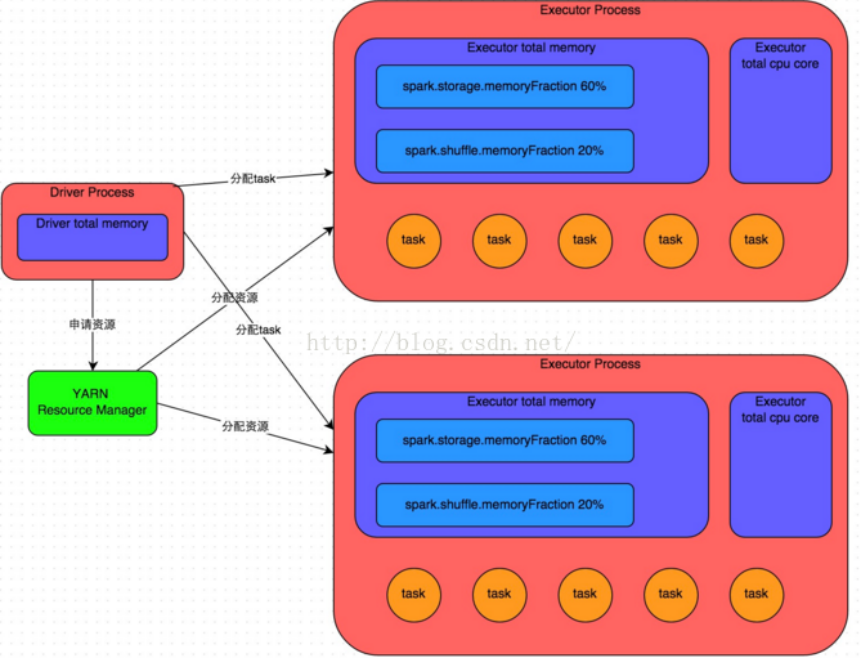
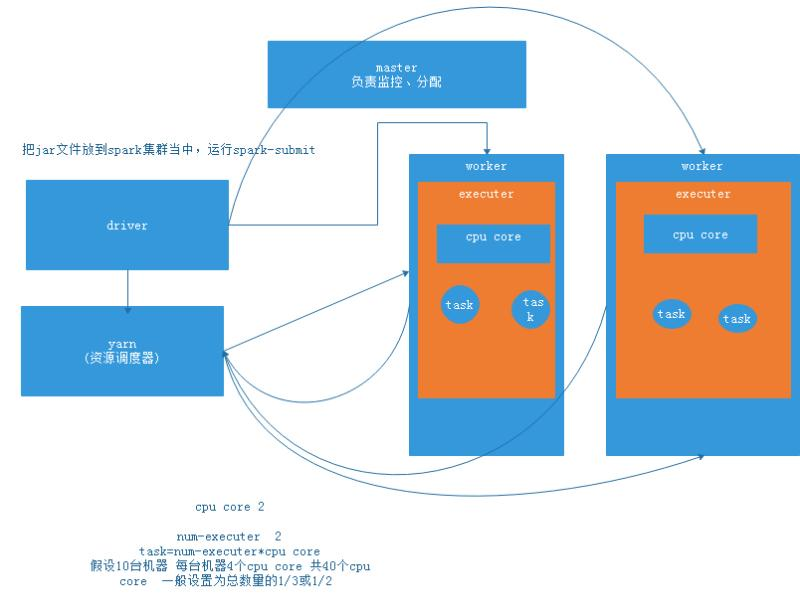
|
属性名称
|
默认值
|
含义
|
|
spark.app.name
|
(none)
|
你的应用程序的名字。这将在UI和日志数据中出现
|
|
spark.driver.cores
|
1
|
driver程序运行需要的cpu内核数
|
|
spark.driver.maxResultSize
|
1g
|
每个Spark action(如collect)所有分区的序列化结果的总大小限制。设置的值应该不小于1m,0代表没有限制。如果总大小超过这个限制,程序将会终止。大的限制值可能导致driver出现内存溢出错误(依赖于spark.driver.memory和JVM中对象的内存消耗)。
|
|
spark.driver.memory
|
512m
|
driver进程使用的内存数
|
|
spark.executor.memory
|
512m
|
每个executor进程使用的内存数。和JVM内存串拥有相同的格式(如512m,2g)
|
|
spark.extraListeners
|
(none)
|
注册监听器,需要实现SparkListener
|
|
spark.local.dir
|
/tmp
|
Spark中暂存空间的使用目录。在Spark1.0以及更高的版本中,这个属性被SPARK_LOCAL_DIRS(Standalone, Mesos)和LOCAL_DIRS(YARN)环境变量覆盖。
|
|
spark.logConf
|
false
|
当SparkContext启动时,将有效的SparkConf记录为INFO。
|
|
spark.master
|
(none)
|
集群管理器连接的地方
|
小记---------spark优化之更优分配资源的更多相关文章
- Spark(六)Spark之开发调优以及资源调优
Spark调优主要分为开发调优.资源调优.数据倾斜调优.shuffle调优几个部分.开发调优和资源调优是所有Spark作业都需要注意和遵循的一些基本原则,是高性能Spark作业的基础:数据倾斜调优,主 ...
- Spark性能优化--开发调优与资源调优
参考: https://tech.meituan.com/spark-tuning-basic.html https://zhuanlan.zhihu.com/p/22024169 一.开发调优 1. ...
- 如何用Serverless让SaaS获得更灵活的租户隔离和更优的资源开销
关于SaaS和Serverless,相信关注我的很多读者都已经不陌生,所以这篇不会聊它们的技术细节,而将重点放在SaaS软件架构中引入Serverless之后,能给我们的SaaS软件带来多大的收益. ...
- spark性能调优:资源优化
在开发完Spark作业之后,就该为作业配置合适的资源了.Spark的资源参数,基本都可以在spark-submit命令中作为参数设置.很多Spark初学者,通常不知道该设置哪些必要的参数,以及如何设置 ...
- Spark学习之路 (十二)SparkCore的调优之资源调优
摘抄自:https://tech.meituan.com/spark-tuning-basic.html 一.概述 在开发完Spark作业之后,就该为作业配置合适的资源了.Spark的资源参数,基本都 ...
- Spark在实际项目中分配更多资源
Spark在实际项目中分配更多资源 Spark在实际项目中分配更多资源 性能调优概述 分配更多资源 性能调优问题 解决思路 为什么调节了资源以后,性能可以提升? 性能调优概述 分配更多资源 性能调优的 ...
- Spark学习之路 (十二)SparkCore的调优之资源调优[转]
概述 在开发完Spark作业之后,就该为作业配置合适的资源了.Spark的资源参数,基本都可以在spark-submit命令中作为参数设置.很多Spark初学者,通常不知道该设置哪些必要的参数,以及如 ...
- Spark的性能调优杂谈
下面这些关于Spark的性能调优项,有的是来自官方的,有的是来自别的的工程师,有的则是我自己总结的. 基本概念和原则 <1> 每一台host上面可以并行N个worker,每一个worke ...
- Spark(九)Spark之Shuffle调优
一.概述 大多数Spark作业的性能主要就是消耗在了shuffle环节,因为该环节包含了大量的磁盘IO.序列化.网络数据传输等操作.因此,如果要让作业的性能更上一层楼,就有必要对shuffle过程进行 ...
随机推荐
- 51 Nod 1092 回文字符串
1092 回文字符串 基准时间限制:1 秒 空间限制:131072 KB 分值: 10 难度:2级算法题 收藏 关注 回文串是指aba.abba.cccbccc.aaaa这种左右对称的字符串.每 ...
- Ubuntu安装jdk10
一:去官网下载jdk,和jre 因为jdk10之后jdk和jre是分开的 jdk下载 jre下载 二:解压缩,并放到指定目录 # 创建目录 sudo mkdir /usr/lib/java ...
- gitk、Git GUI 图形化工具中文显示乱码的解决方案
在Windows下使用gitk.Git-Gui时,可能会出现代码中的中文乱码的情况.解决方法:在软件的安装目录下,在Git\mingw64\etc\gitconfig文件末尾添加: [gui]enco ...
- 创建docker静态化IP
配置桥接网络 桥接本地物理网络的目的,是为了局域网内用户方便访问 docker 实例中服务,不需要各种端口映射即可访问服务. 但是这样做,又违背了 docker 容器的安全隔离的原则,工作中辩证的选择 ...
- [CSP-S模拟测试]:地理课(并查集+线段树分治)
题目传送门(内部题146) 输入格式 从$geography.in$读入数据. 第一行两个数$n,m$,表示有$n$个点,$m$个时刻.接下来$m$行每行三个数,要么是$1\ u\ v$,要么是$2\ ...
- Android学习_服务
一. 服务1. Android多线程 每一个Android应用程序都会分别运行在一个独立的Dalvik(或ART?)虚拟机中,而每个虚拟机在启动时会运行一个UI主线 ...
- 【面试】Spring 执行流程
Spring Aop的实现原理: AOP 的全称是 Aspect Orient Programming ,即面向切面编程.是对 OOP (Object Orient Programming) 的一 ...
- springboot 2.2.0 SNAPSHOT 解决 repositories.repository.id must be unique 的问题
如果打包 jar 也报错了 ,那也是这个的原因,注释掉即可 <!-- 这个仓库必须注释掉 否则打包 war 的时候 , 会报错 'repositories.repository.id' must ...
- LeetCode 113. 路径总和 II(Path Sum II)
题目描述 给定一个二叉树和一个目标和,找到所有从根节点到叶子节点路径总和等于给定目标和的路径. 说明: 叶子节点是指没有子节点的节点. 示例: 给定如下二叉树,以及目标和 sum = 22, 5 / ...
- 浏览器缓存及vw和vh的使用
在浏览器缓存中不仅有 cookie 还有了别的选择 Storage 浏览器又分了两种缓存:sessionStorage localStorage localStorage 缓存:是一种永久的缓存,也就 ...