Restricted Boltzmann Machines
转自:http://deeplearning.net/tutorial/rbm.html
http://blog.csdn.net/mytestmy/article/details/9150213
能量函数
一个事物有相应的稳态,如在一个碗内的小球会停留在碗底,即使受到扰动偏离了碗底,在扰动消失后,它会回到碗底。学过物理的人都知道,稳态是它势能最低的状态。因此稳态对应与某一种能量的最低状态。将这种概念引用到Hopfield网络中去,Hopfield构造了一种能量函数的定义。这是他所作的一大贡献。引进能量函数概念可以进一步加深对这一类动力系统性质的认识,可以把求稳态变成一个求极值与优化的问题,从而为Hopfield网络找到一个解优化问题的应用。
针对RBM模型而言,输入v向量和隐含层输出向量h之间的能量函数值为:
而这2者之间的联合概率为:
其中Z是归一化因子,其值为:
这里为了习惯,把输入v改成函数的自变量x,则关于x的概率分布函数为:
令一个中间变量F(x)为:
则x的概率分布可以重新写为:
这时候它的偏导函数取负后为:
从上面能量函数的抽象介绍中可以看出,如果要使系统(这里即指RBM网络)达到稳定,则应该是系统的能量值最小,由上面的公式可知,要使能量E最小,应该使F(x)最小,也就是要使P(x)最大。因此此时的损失函数可以看做是-P(x),且求导时需要是加上负号的。
另外在图RBM中,可以很容易得到下面的概率值公式:
此时的F(v)为(也就是F(x)):
这个函数也被称做是自由能量函数。另外经过一些列的理论推导,可以求出损失函数的偏导函数公式为:
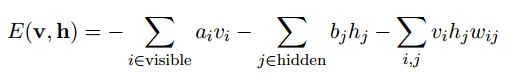
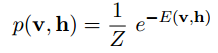
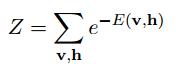
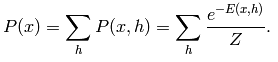
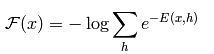

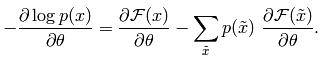
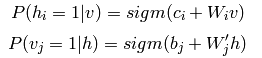
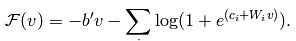
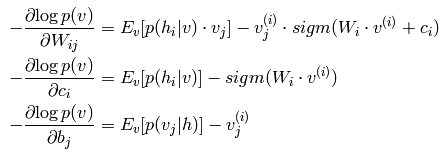
RBM的使用说明
一个普通的RBM网络结构如下。
以上的RBM网络结构有m个可视节点和n个隐藏节点,其中每个可视节点只和n个隐藏节点相关,和其他可视节点是独立的,就是这个可视节点的状态只受n个隐藏节点的影响,对于每个隐藏节点也是,只受m个可视节点的影响,这个特点使得RBM的训练变得容易了。
RBM网络有几个参数,一个是可视层与隐藏层之间的权重矩阵
,一个是可视节点的偏移量b=(b1,b2⋯bm),一个是隐藏节点的偏移量c=(c1,c2⋯cn),这几个参数决定了RBM网络将一个m维的样本编码成一个什么样的n维的样本。
RBM网络的功能有下面的几种,就简单地先描述一下。
首先为了描述容易,先假设每个节点取值都在集合{0,1}中,即。
一个训练样本x过来了取值为x=(x1,x2⋯xm),根据RBM网络,可以得到这个样本的m维的编码后的样本y=(y1,y2⋯yn),这n维的编码也可以认为是抽取了n个特征的样本。而这个m维的编码后的样本是按照下面的规则生成的:对于给定的x=(x1,x2⋯xm),隐藏层的第i个节点的取值为1(编码后的样本的第i个特征的取值为1)的概率为
,其中的v取值就是x,hi的取值就是yi,其中
,是sigmoid函数。也就是说,编码后的样本y的第i个位置的取值为1的概率是p(hi=1|v)。所以,生成yi的过程就是:
i)先利用公式
ii)然后产生一个0到1之间的随机数,如果它小于p(hi=1|v),yi的取值就是1,否则就是0(假如p(hi=1|v)=0.6,这里就是因为yi的取值就是1的概率是,0.6,而这个随机数小于0.6的概率也是0.6;如果这个随机数小于0.6,就是这个事件发生了,那就可以认为yi的取值是1这个事件发生了,所以把yi取值为1)。
反过来,现在知道了一个编码后的样本y,想要知道原来的样本x,即解码过程,跟上面也是同理,过程如下:
i)先利用公式,根据y的值计算概率p(vj=1|h),其中hi的取值就是yi的值。
ii)然后按照均匀分布产生一个0到1之间的随机浮点数,如果它小于p(vj=1|h),vj的取值就是1,否则就是0。对于(ii)的说明:不说别的——比如吧,你现在出去逛街,走到一个岔路口,你只想随便逛逛,所以你是有0.5的概率往左边的路,0.5的概率往右边的路;但是你不知道怎么选择哪个路,所以你选择了抛硬币,正面朝上你就向左,反面朝上就向右。现在你只抛一次,发现他是正面朝上的,你就向左走了。
——回到上面的问题,某节点A取值为1的概率是0.6(假如),也可以看做一个找不均匀的硬币,正面朝上的概率是0.6,反面朝上的概率是0.4;现在要给节点A取值,就拿这个硬币抛一下,正面朝上就取值1,反面朝上就取值0,这个就相当于抛硬币决定走哪个路的那个过程。
——现在假如找不到这样的不均匀的硬币,就拿随机数生成器来代替(生成的数是0-1之间的浮点数);因为随机数生成器取值小于0.6的概率也是0.6,大于0.6的概率是0.4。

RBM的用途
RBM的用途主要是两种,一是对数据进行编码,然后交给监督学习方法去进行分类或回归,二是得到了权重矩阵和偏移量,供BP神经网络初始化训练。
第一种可以说是把它当做一个降维的方法来使用。
第二种就用途比较奇怪。其中的原因就是神经网络也是要训练一个权重矩阵和偏移量,但是如果直接用BP神经网络,初始值选得不好的话,往往会陷入局部极小值。根据实际应用结果表明,直接把RBM训练得到的权重矩阵和偏移量作为BP神经网络初始值,得到的结果会非常地好。
第三种,RBM可以估计联合概率p(v,h),如果把v当做训练样本,h当成类别标签(隐藏节点只有一个的情况,能得到一个隐藏节点取值为1的概率),就可以利用利用贝叶斯公式求p(h|v),然后就可以进行分类,类似朴素贝叶斯、LDA、HMM。说得专业点,RBM可以作为一个生成模型(Generative model)使用。
第四种,RBM可以直接计算条件概率p(h|v),如果把v当做训练样本,h当成类别标签(隐藏节点只有一个的情况,能得到一个隐藏节点取值为1的概率),RBM就可以用来进行分类。说得专业点,RBM可以作为一个判别模型(Discriminative model)使用。
能量模型定义
能量模型是个什么样的东西呢?直观上的理解就是,把一个表面粗糙又不太圆的小球,放到一个表面也比较粗糙的碗里,就随便往里面一扔,看看小球停在碗的哪个地方。一般来说停在碗底的可能性比较大,停在靠近碗底的其他地方也可能,甚至运气好还会停在碗口附近(这个碗是比较浅的一个碗);能量模型把小球停在哪个地方定义为一种状态,每种状态都对应着一个能量,这个能量由能量函数来定义,小球处在某种状态的概率(如停在碗底的概率跟停在碗口的概率当然不一样)可以通过这种状态下小球具有的能量来定义(换个说法,如小球停在了碗口附近,这是一种状态,这个状态对应着一个能量E,而发生“小球停在碗口附近”这种状态的概率p,可以用E来表示,表示成p=f(E),其中f是能量函数),这就是我认为的能量模型。
波尔兹曼网络是一种随机网络。描述一个随机网络,总结起来主要有两点。
第一,概率分布函数。由于网络节点的取值状态是随机的,从贝叶斯网的观点来看,要描述整个网络,需要用三种概率分布来描述系统。即联合概率分布,边缘概率分布和条件概率分布。从贝叶斯网的观点看,受限波尔兹曼网络也可以看作一个双向的有向图,即从输入层节点可以计算隐层节点取某一种状态值的概率,反之亦然。
第二,能量函数。随机神经网络是根植于统计力学的。受统计力学中能量泛函的启发,引入了能量函数。能量函数是描述整个系统状态的一种测度。系统越有序或者概率分布越集中,系统的能量越小。反之,系统越无序或者概率分布越趋于均匀分布,则系统的能量越大。能量函数的最小值,对应于系统的最稳定状态。
能量模型的作用
第一、RBM网络是一种无监督学习的方法,无监督学习的目的是最大可能的拟合输入数据,所以学习RBM网络的目的是让RBM网络最大可能地拟合输入数据。
第二、对于一组输入数据来说,现在还不知道它符合那个分布,那是非常难学的。好在天无绝人之路——统计力学的结论表明,任何概率分布都可以转变成基于能量的模型,而且很多的分布都可以利用能量模型的特有的性质和学习过程,有些甚至从能量模型中找到了通用的学习方法。
第三、在马尔科夫随机场(MRF)中能量模型主要扮演着两个作用:一、全局解的度量(目标函数);二、能量最小时的解(各种变量对应的配置)为目标解。也就是能量模型能为无监督学习方法提供两个东西:a)目标函数;b)目标解。
换句话说,就是——使用能量模型使得学习一个数据的分布变得容易可行了。
能否把最优解嵌入到能量函数中至关重要,决定着我们具体问题求解的好坏。统计模式识别主要工作之一就是捕获变量之间的相关性,同样能量模型也要捕获变量之间的相关性,变量之间的相关程度决定了能量的高低。把变量的相关关系用图表示出来,并引入概率测度方式就构成了概率图模型的能量模型。
RBM作为一种概率图模型,引入了概率就可以使用采样技术求解,在CD(contrastive divergence)算法中采样部分扮演着模拟求解梯度的角色。
能量模型需要一个定义能量函数,RBM的能量函数的定义如下
这个能量函数的意思就是,每个可视节点和隐藏节点之间的连接结构都有一个能量,通俗来说就是可视节点的每一组取值和隐藏节点的每一组取值都有一个能量,如果可视节点的一组取值(也就是一个训练样本的值)为(1,0,1,0,1,0),隐藏节点的一组取值(也就是这个训练样本编码后的值)为(1,0,1),然后分别代入上面的公式,就能得到这个连接结构之间的能量。
能量函数的意义是有一个解释的,叫做专家乘积系统(POE,product of expert),这个理论也是hinton发明的,他把每个隐藏节点看做一个“专家”,每个“专家”都能对可视节点的状态分布产生影响,可能单个“专家”对可视节点的状态分布不够强,但是所有的“专家”的观察结果连乘起来就够强了。具体我也看不太懂,各位有兴趣看hinton的论文吧,中文的也有,叫《专家乘积系统的原理及应用,孙征,李宁》。
从能量函数到概率
为了引入概率,需要定义概率分布。根据能量模型,有了能量函数,就可以定义一个可视节点和隐藏节点的联合概率
也就是一个可视节点的一组取值(一个状态)和一个隐藏节点的一组取值(一个状态)发生的概率p(v,h)是由能量函数来定义的。
这个概率不是随便定义的,而是有统计热力学的解释的——在统计热力学上,当系统和它周围的环境处于热平衡时,一个基本的结果是状态i发生的概率如下面的公式
其中表示系统在状态i时的能量,T为开尔文绝对温度,为Boltzmann常数,Z为与状态无关的常数。
我们这里的变成了E(v,h),因为(v,h)也是一个状态,其他的参数T和由于跟求解无关,就都设置为1了,Z就是我们上面联合概率分布的分母,这个分母是为了让我们的概率的和为1,这样才能保证p(v,h)是一个概率。—— 归一化常量
现在我们得到了一个概率,其实也得到了一个分布,其实这个分布还有一个好听点的名字,可以叫做Gibbs分布,当然不是一个标准的Gibbs分布,而是一个特殊的Gibbs分布,这个分布是有一组参数的,就是能量函数的那几个参数w,b,c。
有了这个联合概率,就可以得到一些条件概率,是用积分去掉一些不想要的量得到的。

从概率到极大似然
上面得到了一个样本和其对应编码的联合概率,也就是得到了RBM网络的Gibbs分布的概率密度函数,引入能量模型的目的是为了方便求解的。
现在回到求解的目标——让RBM网络的表示Gibbs分布最大可能的拟合输入数据。
其实求解的目标也可以认为是让RBM网络表示的Gibbs分布与输入样本的分布尽可能地接近。
现在看看“最大可能的拟合输入数据”这怎么定义。
假设Ω表示样本空间,q是输入样本的分布,即q(x)表示训练样本x的概率, q其实就是要拟合的那个样本表示分布的概率;再假设p是RBM网络表示的Gibbs分布的边缘分布(只跟可视节点有关,隐藏节点是通过积分去掉了,可以理解为可视节点的各个状态的分布),输入样本的集合是S,那现在就可以定义样本表示的分布和RBM网络表示的边缘分布的KL距离
如果输入样本表示的分布与RBM表示的Gibbs分布完全符合,这个KL距离就是0,否则就是一个大于0的数。
第一项其实就是输入样本的熵(熵的定义),输入样本定了熵就定了;第二项没法直接求,但是如果用蒙特卡罗抽样(后面有章节会介绍),让抽中的样本是输入样本(输入样本肯定符合分布q(x)),第二项可以用
来估计,其中的l表示训练样本个数。由于KL的值肯定是不小于0,所以第一项肯定不小于第二项,让第二项取得最大值,就能让KL距离最小;最后,还可以发现,最大化
,而这就是极大似然估计。
结论就是求解输入样本的极大似然,就能让RBM网络表示的Gibbs分布和样本本身表示的分布最接近。
这就是为什么RBM问题最终可以转化为极大似然来求解。
既然要用极大似然来求解,这个当然是有意义的——当RBM网络训练完成后,如果让这个RBM网络随机发生若干次状态(当然一个状态是由(v,h)组成的),这若干次状态中,可视节点部分(就是v)出现训练样本的概率要最大。
这样就保证了,在反编码(从隐藏节点到可视节点的编码过程)过程中,能使训练样本出现的概率最大,也就是使得反编码的误差尽最大的可能最小。
例如一个样本(1,0,1,0,1)编码到(0,1,1),那么,(0,1,1)从隐藏节点反编码到可视节点的时候也要大概率地编码到(1,0,1,0,1)。
下面就说怎么求解了。求解的意思就是求RBM网络里面的几个参数w,b,c的值,这个就是解,而似然函数(对数似然函数)是目标函数。最优化问题里面的最优解和目标函数的关系大家务必先弄清楚。

求解极大似然
既然是求解极大似然,就要对似然函数求最大值,
求解的过程就是对参数就导,然后用梯度上升法不断地把目标函数提升,最终到达停机条件(在这里看不懂的同学就去看参考文献中的《从极大似然到EM》),
设参数为(注意是参数是一组参数),则似然函数可以写为
为了省事L(v│θ)=p(v|θ)写成p(v)了,然后就可以对它的对数进行求导了(因为直接求一个连乘的导数太复杂,所以变成对数来求)
可以看到,是对每个p(v)求导后再加和,然后就有了下面的推导了。
到了这一步的时候,我们又可以发现问题了。我们可以看到的是,对每一个样本,第二个等号后面的两项其实都像是在求一个期望,第一项求的是
这个函数在概率p(h|v)下的期望,第二项求的是
还有论文是这么解释的,上面的公式,对w求偏导,还可以再进一步转化

注意:从第二个“=”号到第三个“=”号的时候,第二个“=”号的方括号里面的第一项是把蒙特卡罗抽样的用法反过来了,从抽样回到了积分,所以得到了一个期望;第二项就是因为对每个训练样本,第二项的值算出来都一样,所以累加以后的结果除以l,相当于没有变化,还是那个期望,只是表达的形式换了。这样的话,这个梯度还可以这么理解,第一项等于输入样本数据的自由能量函数偏导在样本本身的那个分布下的期望值(q(v,h)=p(h|v)q(v),q表示输入样本和他们对应的隐藏增状态表示的分布),而第二项是自由能量函数的偏导在RBM网络表示的Gibbs分布下的期望值。
第一项是可以求的,因为训练样本有了,也就是使用蒙特卡罗估算期望的时候需要的样本已经抽好了,只要求个均值就可以了。
第二项也是可以求的,但是要对v和h的组合的所有可能的取值都遍历一趟,这就可能没法算了;想偷懒的话,悲剧就在于,现在是没有RBM网络表示的Gibbs分布下的样本的(当然后面会介绍这些怎么抽)。
为了进行下面的讨论,把这个梯度再进一步化简,看看能得到什么。根据能量函数的公式,是有三个参数的w,b和c,就分别对这三个参数求导
到了这一步,来分析一下,从上面的联合概率那一堆,我们可以得到下面的
要求第二项,就要遍历所有可能的v的值,然后根据公式去计算几个梯度的值,那样够麻烦的了,还好蒙特卡罗给出了一个偷懒的方法,见后面的章。
只要抽取一堆样本,这些样本符合RBM网络表示的Gibbs分布的(也就是符合参数确定的Gibbs分布p(x)的),就可以把上面的三个偏导数估算出来。
对于上面的情况,是这么处理的,对每个训练样本x,都用某种抽样方法抽取一个它对应的符合RBM网络表示的Gibbs分布的样本(对应的意思就是符合参数确定的Gibbs分布p(x)的),假如叫y;那么,对于整个的训练集{x1,x2,…xl}来说,就得到了一组符合RBM网络表示的Gibbs分布的样本{y1,y2,…,yl},然后拿这组样本去估算第二项,那么梯度就可以用下面的公式来近似了
其中xk表示第k个训练样本,yk表示第k个训练样本对应的RBM网络表示的Gibbs分布(不妨将这个分布称为R)的样本(yk是根据分布R抽取的样本,而且这个样本是从xk出发,用Gibbs抽样抽取出来的,也就是说yk服从分布R,可以用来估算第二项,同时yk跟xk有关),Vyk表示可视节点取值为yk的时候的状态,那么Vykj就表示yk的第j个特征的取值。
这样,梯度出来了,这个极大似然问题可以解了,最终经过若干论迭代,就能得到那几个参数w,b,c的解。
式子中的v是指{x1,x2,…xl}中的一个样本,因为
,对样本进行累加时,第一项是对所有样本进行累加,而第二项都是一样的(是一个积分的结果,与被积变量无关,是一个标量),所以累加后1/l就没有了,只有对l项y进行累加,到了下面CD-k算法的时候,每次只对一个x和一个y进行处理,最外层对x做L次循环后得到的累加结果是一样的.





抽样方法
一般来说,在hinton教授还没弄出CD-k之前,解决RBM的抽样问题是用Gibbs抽样的。
Gibbs抽样是一种基于马尔科夫蒙特卡罗(Markov Chain Monte Carlo,MCMC)策略的抽样方法。具体就是,对于一个d维的随机向量x=(x1,x2,…xd),假设我们无法求得x的联合概率分布p(x),但我们知道给定x的其他分量时,其第i个分量xi的条件分布,即p(xi|xi-),xi-=(x1,x2,…xi-1,xi+1…xd)。那么,我们可以从x的一个任意状态(如(x1(0),x2(0),…,xd(0)))开始,利用条件分布p(xi|xi-),迭代地对这状态的每个分量进行抽样,随着抽样次数n的增加,随机变量(x1(n),x2(n),…,xd(n))的概率分布将以n的几何级数的速度收敛与x的联合概率分布p(v)。
Gibbs抽样其实就是可以让我们可以在位置联合概率分布p(v)的情况下对其进行抽样。
基于RBM模型的对称结构,以及其中节点的条件独立行,我们可以使用Gibbs抽样方法得到服从RBM定义的分布的随机样本。在RBM中进行k步Gibbs抽样的具体算法为:用一个训练样本(或者可视节点的一个随机初始状态)初始化可视节点的状态v0,交替进行下面的抽样:
在抽样步数n足够大的情况下,就可以得到RBM所定义的分布的样本(即符合参数确定的Gibbs分布的样本)了,得到这些样本我们就可以拿去计算梯度的第二项了。
可以看到,上面进行了k步的抽样,这个k一般还要比较大,所以是比较费时间的,尤其是在训练样本的特征数比较多(可视节点数大)的时候,所以hinton教授就弄一个简化的版本,叫做CD-k,也就对比散度。
对比散度是英文ContrastiveDivergence(CD)的中文翻译。与Gibbs抽样不同,hinton教授指出当使用训练样本初始化v0的时候,仅需要较少的抽样步数(一般就一步)就可以得到足够好的近似了。
在CD算法一开始,可见单元的状态就被设置为一个训练样本,并用上面的几个条件概率来对隐藏节点的每个单元都从{0,1}中抽取到相应的值,然后再利用 来对可视节点的每个单元都从{0,1}中抽取相应的值,这样就得到了v1了,一般v1就够了,就可以拿来估算梯度了。
下面给出RBM的基于CD-k的快速学习的主要步骤。
其中,之所以第二项没有了那个1/l,就是因为这个梯度会对所有样本进行累加(极大似然是所有训练样本的梯度的和),最终加和的结果跟现在这样算是相等的(刚好是l个样本,l个第二项相加后,最终结果刚好等于每一个第二项的那个累加符号后面的那一项,而这里所有结果加和后,也能得到相同的值)。


MCMC
最早的蒙特卡罗方法,是由物理学家发明的,旨在于通过随机化的方法计算积分。假设给定函数h(x),我们想计算积分
,但是又没有办法对区间内的所有x的取值都算一遍,我们可以将h(x)分解为某个函数f(x)和一个定义在(a, b)上的概率密度函数p(x)的乘积。这样整个积分就可以写成:

这样一来,原积分就等同于f(x)在p(x)这个分布上的均值(期望)。这时,如果我们从分布p(x)上采集大量的样本x1, x2, ..., xn,这些样本符合分布p(x),即,那么,我们就可以通过这些样本来逼近这个均值:

这就是蒙特卡罗方法的基本思想。
然后剩下的就是怎么样能够采样到符合分布p(x)的样本了,这个简单来说就是一个随机的初始样本,通过马尔科夫链进行多次转移,最终就能得到符合分布p(x)的样本。上面介绍的Gibbs是一种比较常用的抽样算法。
Restricted Boltzmann Machines的更多相关文章
- (六)6.14 Neurons Networks Restricted Boltzmann Machines
1.RBM简介 受限玻尔兹曼机(Restricted Boltzmann Machines,RBM)最早由hinton提出,是一种无监督学习方法,即对于给定数据,找到最大程度拟合这组数据的参数.RBM ...
- 受限波兹曼机导论Introduction to Restricted Boltzmann Machines
Suppose you ask a bunch of users to rate a set of movies on a 0-100 scale. In classical factor analy ...
- CS229 6.14 Neurons Networks Restricted Boltzmann Machines
1.RBM简介 受限玻尔兹曼机(Restricted Boltzmann Machines,RBM)最早由hinton提出,是一种无监督学习方法,即对于给定数据,找到最大程度拟合这组数据的参数.RBM ...
- Convolutional Restricted Boltzmann Machines
参考论文:1.Stacks of Convolutional Restricted Boltzmann Machines for Shift-Invariant Feature Learning ...
- Introduction to Restricted Boltzmann Machines
转载,原贴地址:Introduction to Restricted Boltzmann Machines,by Edwin Chen, 2011/07/18. Suppose you ask a b ...
- 限制波尔兹曼机(Restricted Boltzmann Machines)
能量模型的概念从统计力学中得来,它描述着整个系统的某种状态,系统越有序,系统能量波动越小,趋近于平衡状态,系统越无序,能量波动越大.例如:一个孤立的物体,其内部各处的温度不尽相同,那么热就从温度较高的 ...
- 受限玻尔兹曼机(RBM, Restricted Boltzmann machines)和深度信念网络(DBN, Deep Belief Networks)
受限玻尔兹曼机对于当今的非监督学习有一定的启发意义. 深度信念网络(DBN, Deep Belief Networks)于2006年由Geoffery Hinton提出.
- 限制Boltzmann机(Restricted Boltzmann Machine)
起源:Boltzmann神经网络 Boltzmann神经网络的结构是由Hopfield递归神经网络改良过来的,Hopfield中引入了统计物理学的能量函数的概念. 即,cost函数由统计物理学的能量函 ...
- 限制玻尔兹曼机(Restricted Boltzmann Machine)RBM
假设有一个二部图,每一层的节点之间没有连接,一层是可视层,即输入数据是(v),一层是隐藏层(h),如果假设所有的节点都是随机二值变量节点(只能取0或者1值)同时假设全概率分布满足Boltzmann 分 ...
随机推荐
- SpringBoot项目maven 打包时跳过测试
在打包spring boot项目时,如果测试用例特别多,打包时间会增加: 而且测试用例有时忘记了做相应修改,在打包时则会报错而终止打包,就很烦. 所以这时会想在打包时跳过测试,大致有2种方法: 方法一 ...
- Java NIO笔记(一):NIO介绍
Java NIO即Java Non-blocking IO(Java非堵塞I/O),由于是在Jdk1.4之后添加的一套新的操作I/O工具包,所以通常会被叫做Java New IO.NIO是为提供I/O ...
- Pleasant sheep and big big wolf
pid=3046">点击打开链接 题目:在一个N * M 的矩阵草原上,分布着羊和狼.每一个格子仅仅能存在0或1仅仅动物.如今要用栅栏将全部的狼和羊分开.问怎么放,栅栏数放的最少,求出 ...
- Import Example Dataset
Overview The examples in this guide use the restaurants collection in the test database. The followi ...
- spark pipeline 例子
""" Pipeline Example. """ # $example on$ from pyspark.ml import Pipeli ...
- MDNS的漏洞报告——mdns的最大问题是允许广域网的mdns单播查询,这会暴露设备信息,或者被利用用于dns放大攻击
Vulnerability Note VU#550620 Multicast DNS (mDNS) implementations may respond to unicast queries ori ...
- Square roots
Loops are often used in programs that compute numerical results by starting with an approximate answ ...
- 机器学习规则:ML工程最佳实践----rules_of_ml section 2【翻译】
作者:黄永刚 ML Phase II: 特征工程 第一阶段介绍了机器学习的一个周期,为学习系统获取训练数据,通过有趣的引导设计指标,创建一个服务框架.在有了一个完整系统之后,就进入了第一阶段. 第二阶 ...
- theano import error (win10 python2.7)
因为项目需要,在win10-64位电脑上配置theano.但是一直有 import error的错误,找不到解决方法.作为一个python新手,实在搞不定,请大家不吝赐教!小女子不胜感激! 按照网上的 ...
- bootstrap如何自定义5列
废话少说,先上代码: <!DOCTYPE html><html> <head> <meta charset="utf-8"> < ...