Java NIO(二)缓冲区
概念
缓冲区:一个用于特定基本数据类型的容器,由java.nio包定义的所有缓冲区都是Buffer抽象类的子类。其作用于与NIO的通道进行交互,数据从通道读入缓冲区,数据从缓冲区写入通道
Buffer的基本用法
使用Buffer读写数据一般遵循以下四个步骤:
- 写入数据到Buffer
- 调用flip()方法
- 从Buffer中读取数据
- 调用clear()方法或compact()方法清除缓冲区中的数据
当向Buffer中写入数据时,Buffer会记录写下了多少数据,一旦要读取数据,通过flip()方法将Buffer从写模式切换到读模式。在读模式下,通道可以读取之前写入到Buffer的所有数据
一旦读取完所有数据,就需要调用clear()或compact()清空缓冲区,让它可以再次被写入。clear()方法会清空缓冲区里的所有数据,compact()方法只会清除已经读取过的数据,任何未读的数据都被移到缓冲区的起始处,新写入的数据将放到缓冲区未读数据的后面
缓冲区的本质是一块可以写数据,可以从中读取数据的内存
Buffer常用子类:
- ByteBuffer
- MappedByteBuffer
- CharBuffer
- DoubleBuffer
- FloatBuffer
- IntBuffer
- LongBuffer
- ShortBuffe
上述类都采用类似的方法管理数据,都是通过下面的方法获取Buffer对象:
static XxxBuffer allocate(int capacity):创建一个容量为capacity的对象
补充: 这些缓冲区都为抽象类,不能被实例化,所以通过allocate()方法来实例化。实例化的对象为HeapXxxBuffer,默认大小为100,如HeapCharBuffer等
Buffer的基本属性
容量(capacity): 表示Buffer的最大数据容量,不能为负,且创建后不能修改
限制(limit): 第一个不应该读取或写入的数据的索引,即位于limit之后的数据都不能读写,该值不能为负且不能大于capacity。在写模式下,该值等于capacity,在读模式下,该值会被设置成读模式下的position
位置(position): 下一个要读取或写入的数据的索引,其值不能为负且不能大于limit,其初始值为0,最大值可为capacity-1。当Buffer从写模式切换到读模式时,position置为0
标记(mark)与重置(reset): 标记是一个索引,通过mark()方法指定Buffer中一个特定的position,之后调用reset()方法恢复到这个position
补充:标记,位置,限制,容量遵循以下不变式: 0<=mark<=position<=limit<=capacity
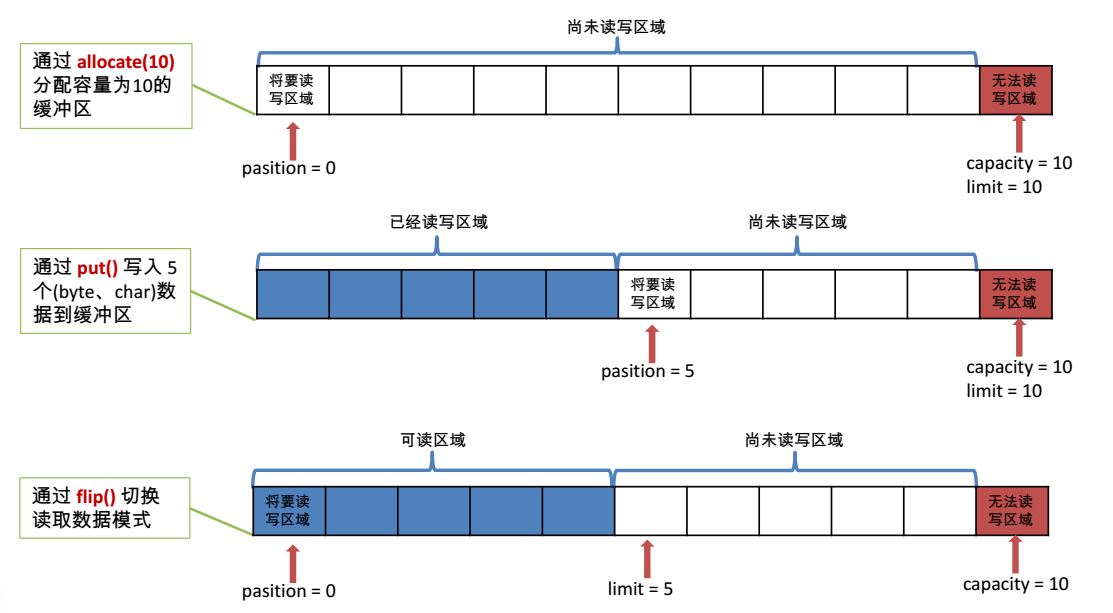
向Buffer中写数据
写数据到Buffer中有两种方式:
- 从Channel写到Buffer
- 通过Buffer的put()方法
int bytes = channel.read(buf);
或
buf.put(127);
注意: put方法有很多版本,允许以不同的方式把数据写入到Buffer中。例如, 写到一个指定的位置,或者把一个字节数组写入到Buffer(批量写入)
从Buffer中读数据
从Buffer中读数据的两种方式:
- 从Buffer中读取数据到Channel
- 通过Buffer的get()方法
int bytes = channel.write(buf);
或
buf.get();
注意: get方法有很多版本,允许你以不同的方式从Buffer中读取数据。例如,从指定position读取,或者从Buffer中读取数据到字节数组(批量读取数据)
flip()方法
flip()方法将Buffer从写模式切换到读模式。将limit设置为position的值,再将position置为0
rewind()方法
rewind()方法将position置为0,limit保持不变。你能够重读Buffer中的所有数据
clear()与compact()方法
调用clear()方法,position置为0,limit设为capacity的值,Buffer被清空了,但Buffer的数据未被清除,只是这些标记告诉我们从哪个位置将数据写入到Buffer中
如果Buffer中有一些未读的数据,调用clear()方法,数据将“被遗忘”,意味着不再有任何标记会告诉你哪些数据被读过,哪些还没有
compact()方法将所有未读的数据复制到Buffer的起始处,然后将position设置为未读的数据的最后一个的后面,limit设置为capacity的值
mark()和reset()方法
通过mark()方法指定Buffer中一个特定的position,之后调用reset()方法恢复到这个position
equals()方法
当满足以下条件时,两个Buffer相等:
- 有相同的类型(如byte,char等)
- Buffer中剩余的byte,char等的个数相等
- Buffer中所有剩余的byte,char等都相等
equals只是比较Buffer的一部分,而不是全部,实际上它只比较Buffer的剩余元素
compareTo()方法
compareTo()方法必将两个Buffer的剩余元素,如果满足下列条件,则认为一个Buffer小于另一个Buffer:
- 第一个不相等的元素小于另一个Buffer中对应的元素
- 所有元素都相等,但第一个Buffer比另外一个先耗尽(第一个Buffer的元素比另外一个少)
注意: 剩余元素是position到limit之间的元素
字节缓冲区
字节缓冲区和其它缓冲区最明显的不同在于它们可能成为通道所执行I/O的源头或目标,通道只接收ByteBuffer作为参数
操作系统在内存区域进行I/O操作,这些内存区域就操作系统方面而言是相连的字节序列,于是,只有字节缓冲区有资格参与I/O操作。而在JVM中,字节数组可能不会在内存中连续存储或者无用存储单元收集可能随时对其进行移动。且在JVM中,数组是对象,数据存储在对象中的方式在不同的JVM中实现也不同
所以,引出了直接缓冲区的概念
直接缓冲区
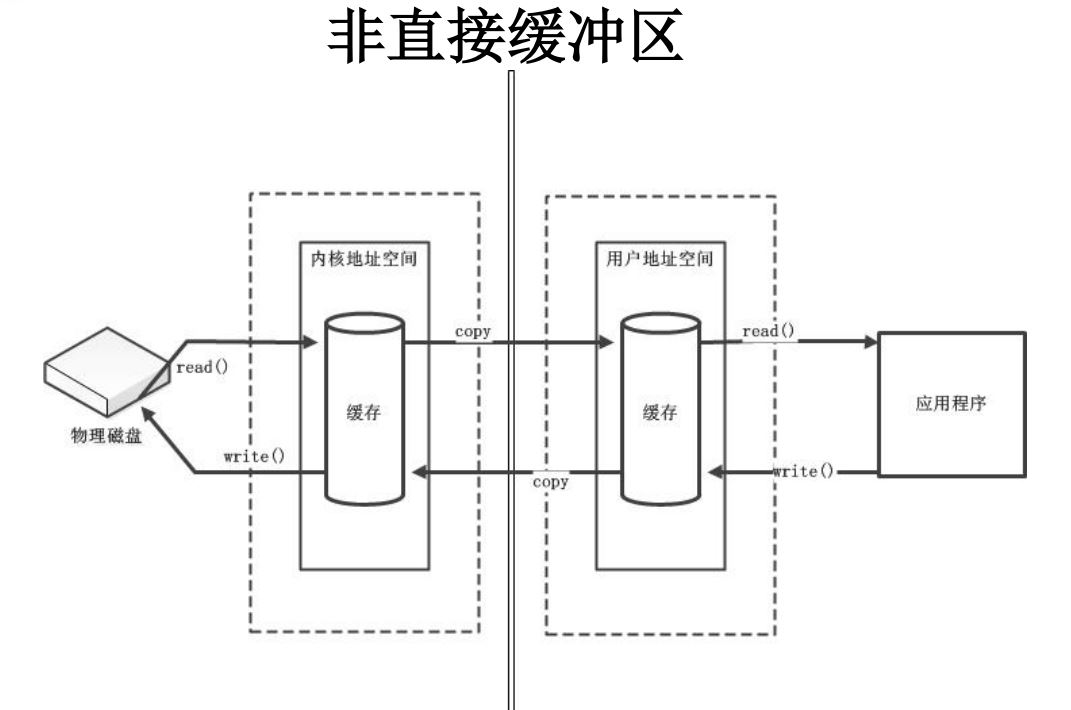
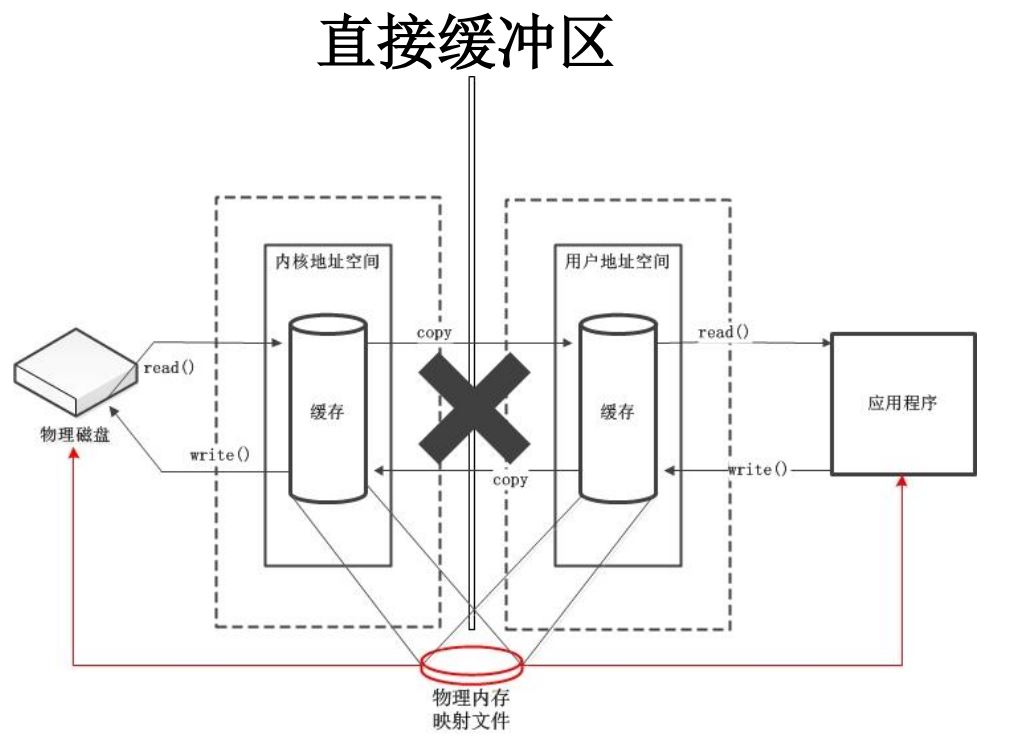
API中直接缓冲区的介绍:
- 字节缓冲区要么是直接的,要么是非直接的。如果为直接字节缓冲区,则 Java 虚拟机会尽最大努力直接在此缓冲区上执行本机 I/O 操作。也就是说,在每次调用基础操作系统的一个本机 I/O 操作之前(或之后),虚拟机都会尽量避免将缓冲区的内容复制到中间缓冲区中(或从中间缓冲区中复制内容)。
- 直接字节缓冲区可以通过调用此类的 allocateDirect()工厂方法来创建。此方法返回的缓冲区进行分配和取消分配所需成本通常高于非直接缓冲区。直接缓冲区的内容可以驻留在常规的垃圾回收堆之外,因此,它们对应用程序的内存需求量造成的影响可能并不明显。所以,建议将直接缓冲区主要分配给那些易受基础系统的本机 I/O 操作影响的大型、持久的缓冲区。一般情况下,最好仅在直接缓冲区能在程序性能方面带来明显好处时分配它们。
- 直接字节缓冲区还可以通过FileChannel的map()方法将文件区域直接映射到内存中来创建。Java 平台的实现有助于通过 JNI 从本机代码创建直接字节缓冲区。如果以上这些缓冲区中的某个缓冲区实例指的是不可访问的内存区域,则试图访问该区域不会更改该缓冲区的内容,并且将会在访问期间或稍后的某个时间导致抛出不确定的异常。
- 字节缓冲区是直接缓冲区还是非直接缓冲区可通过调用其 isDirect方法来确定。提供此方法是为了能够在性能关键型代码中执行显式缓冲区管理。
直接字节缓冲区通常是I/O操作最好的选择。在设计方面,它们支持JVM可用的最高效I/O机制,非直接字节缓冲区可以被传递给通道,但是这样可能导致性能损耗,通常非直接缓冲不可能成为一个本地I/O操作的目标,如果开发者向一个通道中传递一个非直接ByteBuffer对象用于写入,通道可能会在每次调用中隐含地进行下面的操作:
- 创建一个临时的直接ByteBuffer对象
- 将非直接缓冲区的内容复制到直接缓冲区中
- 使用临时缓冲区执行低层次的I/O操作
- 临时缓冲区对象离开作用域,被回收
这可能导致缓冲区在每个I/O上复制并产生大量的对象,这是应该极力避免的
直接缓冲区是I/O的最佳选择,但可能比创建非直接缓冲区要花费更高的成本。直接缓冲区使用的内存是通过调用本地操作系统的代码分配的,绕过了标准JVM堆栈。直接缓冲区的内存区域不受无用存储单元收集支配,因为它们位于标准JVM堆栈之外。
那么是否在创建缓冲区时,都应该创建直接缓冲区呢?
不一定,因为滥用allocateDirect()方法创建直接字节缓冲区是有风险的
使用allocateDirect方法在堆外分配内存,这块内存区域的回收依赖Full GC,且回收效率不高,这样将导致内存越来越大,甚至导致内存溢出。普通的创建字节缓冲区的方法,内存分配在年轻代,易于回收
Java NIO(二)缓冲区的更多相关文章
- Java NIO——2 缓冲区
一.缓冲区基础 1.缓冲区并不是多线程安全的. 2.属性(容量.上界.位置.标记) capacity limit 第一个不能被读或写的元素 position 下一个要被读或写的元素索引 mark ...
- Java NIO ———— Buffer 缓冲区详解 入门
引言缓冲区是一个用于特定基本类型的容器.由java.nio 包定义,所有缓冲区都是 Buffer 抽象类的子类. Java NIO 中的 Buffer ,主要用于与NIO 通道进行交互.数据从通道存入 ...
- Java NIO 之缓冲区
缓冲区基础 所有的缓冲区都具有四个属性来 供关于其所包含的数据元素的信息. capacity(容量):缓冲区能够容纳数据的最大值,创建缓冲区后不能改变. limit(上界):缓冲区的第一个不能被读或写 ...
- Java NIO之缓冲区Buffer
Java NIO的核心部件: Buffer Channel Selector Buffer 是一个数组,但具有内部状态.如下4个索引: capacity:总容量 position:下一个要读取/写入的 ...
- Java NIO Buffer缓冲区
原文链接:http://tutorials.jenkov.com/java-nio/buffers.html Java NIO Buffers用于和NIO Channel交互.正如你已经知道的,我们从 ...
- Java NIO之缓冲区
1.简介 Java NIO 相关类在 JDK 1.4 中被引入,用于提高 I/O 的效率.Java NIO 包含了很多东西,但核心的东西不外乎 Buffer.Channel 和 Selector.这其 ...
- java NIO (二) 一个故事讲清楚NIO
假设某银行只有10个职员.该银行的业务流程分为以下4个步骤: 1) 顾客填申请表(5分钟): 2) 职员审核(1分钟): 3) 职员叫保安去金库取钱(3分钟): 4) 职员打印票据,并将钱和票据返回给 ...
- Java NIO -- 直接缓冲区与非直接缓冲区
直接缓冲区与非直接缓冲区: 非直接缓冲区:通过 allocate() 方法分配缓冲区,将缓冲区建立在 JVM 的内存中直接缓冲区:通过 allocateDirect() 方法分配直接缓冲区,将缓冲区建 ...
- Java NIO流 -- 缓冲区(Buffer,ByteBuffer)
用来定义缓冲区的所有类都以Buffer类为基类,Buffer定义了缓冲区的基本特征. 直接子类: ByteBuffer 用来存储byte类型的缓冲区,可以在这种缓冲区中存储任意其他基本类型的二进制值( ...
- 海纳百川而来的一篇相当全面的Java NIO教程
目录 零.NIO包 一.Java NIO Channel通道 Channel的实现(Channel Implementations) Channel的基础示例(Basic Channel Exampl ...
随机推荐
- 【Oracle】RAC控制文件多路复用
1.—关闭数据库,各个节点都要关闭: [oracle@rac1 ~]$ srvctl stop database -d racdb -o immediate 2.—启动任一节点到nomount状态: ...
- Findbugs分析工具介绍
Findbugs是一个静态分析工具,它检查类或者JAR 文件,将字节码与一组缺陷模式进行对比以发现可能的问题.Findbugs自带检测器,其中有60余种Bad practice,80余种Correct ...
- C#自定义控件实现控件随窗口大小改变
1.新建用户控件,取名MyForm. 2.将默认的UserControl改成Form 3.在类中添加以下代码 private float X, Y; //获得控件的长度.宽度.位置.字体大小的数据 p ...
- 服务器控件使用eval()绑定属性出现服务器标记的格式不正确
在使用asp.net服务器端控件的时候,想要动态绑定控件某属性的值,或者动态绑定控件事件方法的参数,例如一个<asp:RadioButton ID="RadioButton5" ...
- 图片无损放大工具PhotoZoom如何进行打印设置
我们使用PhotoZoom对照片进行无失真放大后,想将照片给打印出来需要设置一些常规参数时.那么这些参数我们该从哪里设置,怎么设置呢? PhotoZoom下载:pan.baidu.com/s/1cXb ...
- IIS访问php页面问题,报告404错误
IIS访问php页面出现问题,所有php页面找不到,显示404页面,html页面可以正常访问. 搜索结果: 方案1: 打开WEB服务扩展,把“所有未知ISAPI扩展”设为允许! 方案2: PHP没有完 ...
- appium不能获取webview内容的解决办法
在用appium对小猿搜题app进行自动化测试时,准备用page_source打印出文章的xml内容 但是发现只能打印出外部结构内容,实际的文章内容却没有显示 截图如下 查询之后,得知需要通过cont ...
- webpack学习笔记(3)--webpack.config.js
module 参数 使用下面的实例来说明 module.exports = { module: { rules: [ { test: /\.css$/, use: 'css-loader' }, { ...
- CNN实现terecord、数据集、模型训练
AlexNet(Alex Krizhevsky,ILSVRC2012冠军)适合做图像分类.层自左向右.自上向下读取,关联层分为一组,高度.宽度减小,深度增加.深度增加减少网络计算量. 训练模型数据集 ...
- nodejs-app.js
设置静态目录 1 2 app.use(express.static(path.join(__dirname, 'public'))); //设置模版渲染的js,css,images的静态文件目录 设置 ...