Python笔记(28)-----继承
来自https://blog.csdn.net/sunwukong_hadoop/article/details/80175292
1、Python的继承以及调用父类成员
python子类调用父类成员有2种方法,分别是普通方法和super方法。
假设Base是基类。
class Base(object):
def __init__(self):
print “Base init”
普通方法:
class Leaf(Base):
def __init__(self):
Base.__init__(self)
print “Leaf init”
super方法:
class Leaf(Base):
def __init__(self):
super(Leaf, self).__init__()
print “Leaf init”
在上面简单的场景下,两个效果是一样的:
>>> leaf = Leaf()
Base init
Leaf init
2、钻石继承遇到的难题
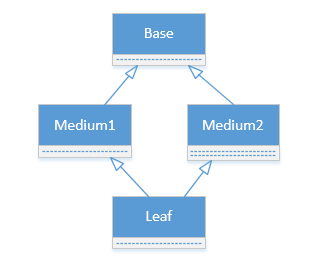
普通方法:
class Base(object):
def __init__(self):
print “Base init” class Medium1(Base):
def __init__(self):
Base.__init__(self)
print “Medium1 init” class Medium2(Base):
def __init__(self):
Base.__init__(self)
print “Medium2 init” class Leaf(Medium1, Medium2):
def __init__(self):
Medium1.__init__(self)
Medium2.__init__(self)
print “Leaf init”
当我们生成Leaf对象时,结果如下:
>>> leaf = Leaf()
Base init
Medium1 init
Base init
Medium2 init
Leaf init
可以看到Base被初始化了两次!这是由于Medium1和Medium2各自调用了Base的初始化函数导致的。


super方法:
class Base(object):
def __init__(self):
print “Base init” class Medium1(Base):
def __init__(self):
super(Medium1, self).__init__()
print “Medium1 init” class Medium2(Base):
def __init__(self):
super(Medium2, self).__init__()
print “Medium2 init” class Leaf(Medium1, Medium2):
def __init__(self):
super(Leaf, self).__init__()
print “Leaf init”
我们生成Leaf对象:
>>> leaf = Leaf()
Base init
Medium2 init
Medium1 init
Leaf init
可以看到整个初始化过程符合我们的预期,Base只被初始化了1次。而且重要的是,相比原来的普通写法,super方法并没有写额外的代码,也没有引入额外的概念
4. super的内核:mro
要理解super的原理,就要先了解mro。mro是method resolution order的缩写,表示了类继承体系中的成员解析顺序。
在python中,每个类都有一个mro的类方法。我们来看一下钻石继承中,Leaf类的mro是什么样子的:
>>> Leaf.mro()
[<class '__main__.Leaf'>, <class '__main__.Medium1'>, <class '__main__.Medium2'>, <class '__main__.Base'>, <type 'object'>]
可以看到mro方法返回的是一个祖先类的列表。Leaf的每个祖先都在其中出现一次,这也是super在父类中查找成员的顺序。
通过mro,python巧妙地将多继承的图结构,转变为list的顺序结构。super在继承体系中向上的查找过程,变成了在mro中向右的线性查找过程,任何类都只会被处理一次。
通过这个方法,python解决了多继承中的2大难题:
1. 查找顺序问题。从Leaf的mro顺序可以看出,如果Leaf类通过super来访问父类成员,那么Medium1的成员会在Medium2之前被首先访问到。如果Medium1和Medium2都没有找到,最后再到Base中查找。
2. 钻石继承的多次初始化问题。在mro的list中,Base类只出现了一次。事实上任何类都只会在mro list中出现一次。这就确保了super向上调用的过程中,任何祖先类的方法都只会被执行一次。
至于mro的生成算法,可以参考这篇wiki:https://en.wikipedia.org/wiki/C3_linearization
5. super的具体用法
5.1. super(type, obj)
当我们在Leaf的__init__中写这样的super时:
- class Leaf(Medium1, Medium2):
- def __init__(self):
- super(Leaf, self).__init__()
- print “Leaf init”
super(Leaf, self).__init__()的意思是说:
- 获取self所属类的mro, 也就是[Leaf, Medium1, Medium2, Base]
- 从mro中Leaf右边的一个类开始,依次寻找__init__函数。这里是从Medium1开始寻找
- 一旦找到,就把找到的__init__函数绑定到self对象,并返回
从这个执行流程可以看到,如果我们不想调用Medium1的__init__,而想要调用Medium2的__init__,那么super应该写成:super(Medium1, self)__init__()
5.2. super(type, type2)
当我们在Leaf中写类方法的super时:
class Leaf(Medium1, Medium2):
def __new__(cls):
obj = super(Leaf, cls).__new__(cls)
print “Leaf new”
return obj
super(Leaf, cls).__new__(cls)的意思是说:
- 获取cls这个类的mro,这里也是[Leaf, Medium1, Medium2, Base]
- 从mro中Leaf右边的一个类开始,依次寻找__new__函数
- 一旦找到,就返回“非绑定”的__new__函数
由于返回的是非绑定的函数对象,因此调用时不能省略函数的第一个参数。这也是这里调用__new__时,需要传入参数cls的原因
同样的,如果我们想从某个mro的某个位置开始查找,只需要修改super的第一个参数就行
Python笔记(28)-----继承的更多相关文章
- Python笔记(三)继承和多态、动态语言
一.继承 先定义一个A类 class A(object): def fun(self): print "Run A fun()" 在定义一个B类 class B(A): pass ...
- python笔记28(TCP,UDP,socket协议)
今日内容 1.TCP协议 协议的特点:三次握手,四次挥手: 2.UDP协议 3.OSI七层模型:每层的物理设备,每一层协议. 4.代码部分: ①介绍socket: ②使用socket完成tcp协议的w ...
- python基础学习笔记—— 多继承
本节主要内容: 1.python多继承 2.python经典类的MRO 3.python新式类的MRO.C3算法 4.super是什么鬼? 一.python多继承 在前⾯的学习过程中. 我们已经知道了 ...
- python基础学习笔记——单继承
1.为什么要有类的继承性?(继承性的好处)继承性的好处:①减少了代码的冗余,提供了代码的复用性②提高了程序的扩展性 ③(类与类之间产生了联系)为多态的使用提供了前提2.类继承性的格式:单继承和多继承# ...
- 20.Python笔记之SqlAlchemy使用
Date:2016-03-27 Title:20.Python笔记之SqlAlchemy使用 Tags:python Category:Python 作者:刘耀 博客:www.liuyao.me 一. ...
- 8.python笔记之面向对象基础
title: 8.Python笔记之面向对象基础 date: 2016-02-21 15:10:35 tags: Python categories: Python --- 面向对象思维导图 (来自1 ...
- python笔记 - day8
python笔记 - day8 参考: http://www.cnblogs.com/wupeiqi/p/4766801.html http://www.cnblogs.com/wupeiqi/art ...
- python笔记 - day7-1 之面向对象编程
python笔记 - day7-1 之面向对象编程 什么时候用面向对象: 多个函数的参数相同: 当某一些函数具有相同参数时,可以使用面向对象的方式,将参数值一次性的封装到对象,以后去对象中取值即可: ...
- python笔记 - day7
python笔记 - day7 参考: http://www.cnblogs.com/wupeiqi/articles/5501365.html 面向对象,初级篇: http://www.cnblog ...
- python笔记 - day5
python笔记 - day5 参考: http://www.cnblogs.com/wupeiqi/articles/5484747.html http://www.cnblogs.com/alex ...
随机推荐
- Pyhton学习——Day2
Python开发IDE(工具)Pycharm.eclipse1.循环while 条件 #循环体 #条件为真则执行 #条件为假则执行break用于退出所有循环continue用于退出当前循环 2.Pyc ...
- IOS - 零碎
---恢复内容开始--- 1.模拟器目录: ProjectNameApk.documents.library(cache.preference.cookies).temp 2.Edit-Refacto ...
- 【JavaScript框架封装】实现一个类似于JQuery的选择框架的封装
// 选择框架 (function (xframe) { // 需要参与链式访问的(必须使用prototype的方式来给对象扩充方法) xframe.extend({}); // 不需要参与链式访问的 ...
- immutable-js基础
Immutable.js(和原生方法不同): 用于深层次的数组和对象的比较 数据结构:Map Set Seq List Rang(和原生不同) 首先:先忘记es5 es6的数组对象方法 官 ...
- Linux中的gpio口使用方法
Linux中的IO使用方法 应该是新版本内核才有的方法.请参考:./Documentation/gpio.txt文件 提供的API:驱动需要包含 #include <linux/gpio.h&g ...
- 小松之LINUX 驱动学习笔记(二)
这两天一直在看字符驱动那块,后来从网上找啦几个例子,自己编译啦下,安装啥的都挺正常,就是用测试程序测试的时候总出问题,现在找到一个能测试的代码,自己先看看和原来的那个代码有啥不同,后面会继续更新,说下 ...
- 猫狗分类--Tensorflow实现
贴一张自己画的思维导图 数据集准备 kaggle猫狗大战数据集(训练),微软的不需要FQ 12500张cat 12500张dog 生成图片路径和标签的List step1:获取D:/Study/Py ...
- ZOJ 3888 Twelves Monkeys
Twelves Monkeys Time Limit: 5000ms Memory Limit: 32768KB This problem will be judged on ZJU. Origina ...
- java陷阱之spring事物未提交和回滚导致不可预知问题
案发现场 //防止全局配置了 所以这里定义sprnig 不托管事物 @Transactional(propagation = Propagation.NOT_SUPPORTED) public boo ...
- 如何计算合适的InnoDB log file size
原文链接:http://www.mysqlperformanceblog.com/2008/11/21/how-to-calculate-a-good-innodb-log-file-size/ Pe ...