程序员修仙之路--优雅快速的统计千万级别uv(留言送书)
菜菜,咱们网站现在有多少PV和UV了?
Y总,咱们没有统计pv和uv的系统,预估大约有一千万uv吧

写一个统计uv和pv的系统吧
网上有现成的,直接接入一个不行吗?
别人的不太放心,毕竟自己写的,自己拥有主动权。给你两天时间,系统性能不要太差呀
好吧~~~

通过以上的概念,可以清晰的看出pv是比较好设计的,网站的每一次被访问,pv都会增加,但是uv就不一定会增加了,uv本质上记录的是按照某个标准划分的自然人,这个标准其实我们可以自己去定义,比如:可以定义同一个IP的访问者为同一个UV,这也是最常见的uv定义之一,另外还有根据cookie定义等等。无论是pv还是uv,都需要一个时间段来加以描述,平时我们所说的pv,uv数量指的都是24小时之内(一个自然日)的数据。
pv相比较uv来说,技术上比较容易一些,今天咱们就来说一说uv的统计,为什么说uv的统计相对来说比较难呢,因为uv涉及到同一个标准下的自然人的去重,尤其是一个uv千万级别的网站,设计一个好的uv统计系统也许并非想象的那么容易。
那我们就来设计一个以一个自然日为时间段的uv统计系统,一个自然人(uv)的定义为同一个来源IP(当然你也可以自定义其他标准),数据量级别假设为每日千万uv的量级。

注意:今天我们讨论的重点是获取到自然人定义的信息之后如何设计uv统计系统,并非是如何获取自然人的定义。uv系统的设计并非想象的那么简单,因为uv可能随着网站的营销策略会出现瞬间大流量,比如网站举办了一个秒杀活动。
服务端编程有一句名言曰:没有一个表解决不了的功能,如果有那就两个表三个表。一个uv统计系统确实可以基于数据库来实现,而且也不复杂,uv统计的记录表可以类似如下(不要太纠结以下表设计是否合理):
| 字段 | 类型 | 描述 |
|---|---|---|
| IP | varchar(30) | 客户端来源ip |
| DayID | int | 时间的简写,例如 20190629 |
| 其他字段 | int | 其他字段描述 |
当一个请求到达服务器,服务端每次需要查询一次数据库是否有当前IP和当前时间的访问记录,如果有,则说明是同一个uv,如果没有,则说明是新的uv记录,插入数据库。当然以上两步也可以写到一个sql语句中:
if exists( select 1 from table where ip='ip' and dayid=dayid )
Begin
return 0
End
else
Begin
insert into table .......
End所有基于数据库的解决方案,在数据量大的情况下几乎都更容易出现瓶颈。面对每天千万级别的uv统计,基于数据库的这种方案也许并不是最优的。
面对每一个系统的设计,我们都应该沉下心来思考具体的业务。至于uv统计这个业务有几个特点:
1. 每次请求都需要判断是否已经存在相同的uv记录
2. 持久化uv数据不能影响正常的业务
3. uv数据的准确性可以忍受一定程度的误差
哈希表
基于数据库的方案中,在大数据量的情况下,性能的瓶颈引发原因之一就是:判断是否已经存在相同记录,所以要优化这个系统,肯定首先是要优化这个步骤。根据菜菜以前的文章,是否可以想到解决这个问题的数据结构,对,就是哈希表。哈希表根据key来查找value的时间复杂度为O(1)常数级别,可以完美的解决查找相同记录的操作瓶颈。
也许在uv数据量比较小的时候,哈希表也许是个不错的选择,但是面对千万级别的uv数据量,哈希表的哈希冲突和扩容,以及哈希表占用的内存也许并不是好的选择了。假设哈希表的每个key和value 占用10字节,1千万的uv数据大约占用 100M,对于现代计算机来说,100M其实不算大,但是有没有更好的方案呢?
优化哈希表
基于哈希表的方案,在千万级别数据量的情况下,只能算是勉强应付,如果是10亿的数据量呢?那有没有更好的办法搞定10亿级数据量的uv统计呢?这里抛开持久化数据,因为持久化设计到数据库的分表分库等优化策略了,咱们以后再谈。有没有更好的办法去快速判断在10亿级别的uv中某条记录是否存在呢?
为了尽量缩小使用的内存,我们可以这样设计,可以预先分配bit类型的数组,数组的大小是统计的最大数据量的一个倍数,这个倍数可以自定义调整。现在假设系统的uv最大数据量为1千万,系统可以预先分配一个长度为5千万的bit数组,bit占用的内存最小,只占用一位。按照一个哈希冲突比较小的哈希函数计算每一个数据的哈希值,并设置bit数组相应哈希值位置的值为1。由于哈希函数都有冲突,有可能不同的数据会出现相同的哈希值,出现误判,但是我们可以用多个不同的哈希函数来计算同一个数据,来产生不同的哈希值,同时把这多个哈希值的数组位置都设置为1,从而大大减少了误判率,刚才新建的数组为最大数据量的一个倍数也是为了减小冲突的一种方式(容量越大,冲突越小)。当一个1千万的uv数据量级,5千万的bit数组占用内存才几十M而已,比哈希表要小很多,在10亿级别下内存占用差距将会更大。
以下为代码示例:
class BloomFilter
{
BitArray container = null;
public BloomFilter(int length)
{
container = new BitArray(length);
}
public void Set(string key)
{
var h1 = Hash1(key);
var h2 = Hash2(key);
var h3 = Hash3(key);
var h4 = Hash4(key);
container[h1] = true;
container[h2] = true;
container[h3] = true;
container[h4] = true;
}
public bool Get(string key)
{
var h1 = Hash1(key);
var h2 = Hash2(key);
var h3 = Hash3(key);
var h4 = Hash4(key);
return container[h1] && container[h2] && container[h3] && container[h4];
}
//模拟哈希函数1
int Hash1(string key)
{
int hash = 5381;
int i;
int count;
char[] bitarray = key.ToCharArray();
count = bitarray.Length;
while (count > 0)
{
hash += (hash << 5) + (bitarray[bitarray.Length - count]);
count--;
}
return (hash & 0x7FFFFFFF) % container.Length;
}
int Hash2(string key)
{
int seed = 131; // 31 131 1313 13131 131313 etc..
int hash = 0;
int count;
char[] bitarray = (key+"key2").ToCharArray();
count = bitarray.Length;
while (count > 0)
{
hash = hash * seed + (bitarray[bitarray.Length - count]);
count--;
}
return (hash & 0x7FFFFFFF)% container.Length;
}
int Hash3(string key)
{
int hash = 0;
int i;
int count;
char[] bitarray = (key + "keykey3").ToCharArray();
count = bitarray.Length;
for (i = 0; i < count; i++)
{
if ((i & 1) == 0)
{
hash ^= ((hash << 7) ^ (bitarray[i]) ^ (hash >> 3));
}
else
{
hash ^= (~((hash << 11) ^ (bitarray[i]) ^ (hash >> 5)));
}
count--;
}
return (hash & 0x7FFFFFFF) % container.Length;
}
int Hash4(string key)
{
int hash = 5381;
int i;
int count;
char[] bitarray = (key + "keykeyke4").ToCharArray();
count = bitarray.Length;
while (count > 0)
{
hash += (hash << 5) + (bitarray[bitarray.Length - count]);
count--;
}
return (hash & 0x7FFFFFFF) % container.Length;
}
}测试程序为:
BloomFilter bf = new BloomFilter(200000000);
int exsitNumber = 0;
int noExsitNumber = 0;
for (int i=0;i < 10000000; i++)
{
string key = $"ip_{i}";
var isExsit= bf.Get(key);
if (isExsit)
{
exsitNumber += 1;
}
else
{
bf.Set(key);
noExsitNumber += 1;
}
}
Console.WriteLine($"判断存在的数据量:{exsitNumber}");
Console.WriteLine($"判断不存在的数据量:{noExsitNumber}");测试结果:
判断存在的数据量:7017
判断不存在的数据量:9992983
占用内存40M,误判率不到 千分之1,在这个业务场景下在可接受范围之内。在真正的业务当中,系统并不会在启动之初就分配这么大的bit数组,而是随着冲突增多慢慢扩容到一定容量的。
异步优化
当判断一个数据是否已经存在这个过程解决之后,下一个步骤就是把数据持久化到DB,如果数据量较大或者瞬间数据量较大,可以考虑使用mq或者读写IO比较大的NOSql来代替直接插入关系型数据库。
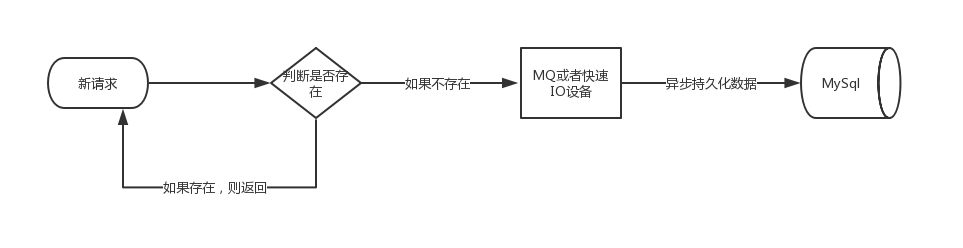
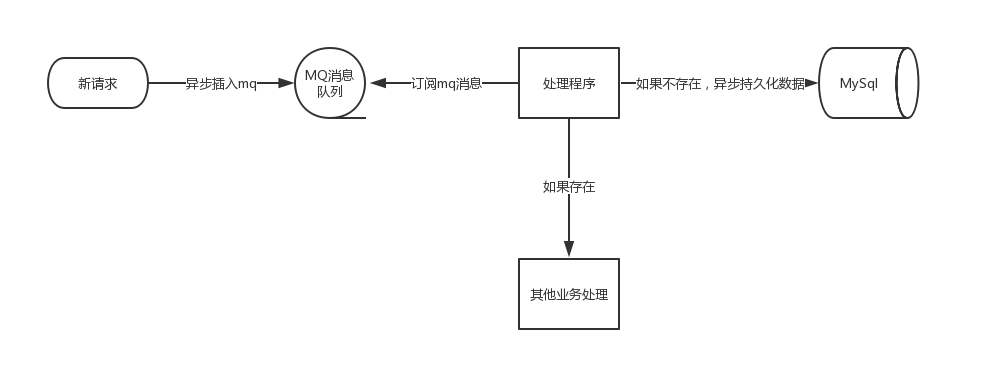
思路一转,整个的uv流程其实也都可以异步化,而且也推荐这么做。

公众号的本文第5,15,30个留言者将获得技术书一本(自付邮费),添加菜菜微信领取吧。福利群内会经常送书哦!!

架构师之路,菜菜与君一起成长
长按识别二维码关注
程序员修仙之路--优雅快速的统计千万级别uv(留言送书)的更多相关文章
- 程序员修仙之路--优雅快速的统计千万级别uv
菜菜,咱们网站现在有多少PV和UV了? Y总,咱们没有统计pv和uv的系统,预估大约有一千万uv吧 写一个统计uv和pv的系统吧 网上有现成的,直接接入一个不行吗? 别人的不太放心,毕竟自己写的,自己 ...
- 程序员修神之路--用NOSql给高并发系统加速(送书)
随着互联网大潮的到来,越来越多网站,应用系统需要海量数据的支撑,高并发.低延迟.高可用.高扩展等要求在传统的关系型数据库中已经得不到满足,或者说关系型数据库应对这些需求已经显得力不从心了.关系型数据库 ...
- 快速的统计千万级别uv
菜菜,咱们网站现在有多少PV和UV了? Y总,咱们没有统计pv和uv的系统,预估大约有一千万uv吧 写一个统计uv和pv的系统吧 网上有现成的,直接接入一个不行吗? 别人的不太放心,毕竟自己写的,自己 ...
- 程序员修仙之路- CXO让我做一个计算器!!
菜菜呀,个税最近改革了,我得重新计算你的工资呀,我需要个计算器,你开发一个吧 CEO,CTO,CFO于一身的CXO X总,咱不会买一个吗? 菜菜 那不得花钱吗,一块钱也是钱呀··这个计算器支持加减乘除 ...
- 程序猿修仙之路--数据结构之你是否真的懂数组? c#socket TCP同步网络通信 用lambda表达式树替代反射 ASP.NET MVC如何做一个简单的非法登录拦截
程序猿修仙之路--数据结构之你是否真的懂数组? 数据结构 但凡IT江湖侠士,算法与数据结构为必修之课.早有前辈已经明确指出:程序=算法+数据结构 .要想在之后的江湖历练中通关,数据结构必不可少. ...
- 程序员修神之路--kubernetes是微服务发展的必然产物
菜菜哥,我昨天又请假出去面试了 战况如何呀? 多数面试题回答的还行,但是最后让我介绍微服务和kubernetes的时候,挂了 话说微服务和kubernetes内容确实挺多的 那你给我大体介绍一下呗 可 ...
- 程序员修神之路--redis做分布式锁可能不那么简单
菜菜哥,复联四上映了,要不要一起去看看? 又想骗我电影票,对不对? 呵呵,想去看了叫我呀 看来你工作不饱和呀 哪有,这两天我刚基于redis写了一个分布式锁,很简单 不管你基于什么做分布式锁,你觉得很 ...
- 程序员修神之路--🤠分布式高并发下Actor模型如此优秀🤠
写在开始 一般来说有两种策略用来在并发线程中进行通信:共享数据和消息传递.使用共享数据方式的并发编程面临的最大的一个问题就是数据条件竞争.处理各种锁的问题是让人十分头痛的一件事. 传统多数流行的语言并 ...
- 程序员修神之路--为什么有了SOA,我们还用微服务?
菜菜哥,我最近需要做一个项目,老大让我用微服务的方式来做 那挺好呀,微服务现在的确很流行 我以前在别的公司都是以SOA的方式,SOA也是面向服务的方式呀 的确,微服务和SOA有相同之处 面向服务的架构 ...
随机推荐
- 从编译,执行过程理解c#
上节我们说过C#所开发的程序源代码并不是编译成能够直接在操作系统上执行的二进制代码.与Java类似,它被编译成为中间代码,然后通过.NET Framework的虚拟机——被称之为通用语言运行时(CLR ...
- Method and system for public-key-based secure authentication to distributed legacy applications
A method, a system, an apparatus, and a computer program product are presented for an authentication ...
- Linux性能测试 ulimit命令
功能说明:控制shell程序的资源. 语 法:ulimit [-aHS][-c <core文件上限>][-d <数据节区大小>][-f <文件大 小>][-m &l ...
- scipy —— 丰富的子包(io、cluster)
io,顾名思义,input/output,输入输出接口: 1. io Input and output (scipy.io) - SciPy v0.18.1 Reference Guide wavfi ...
- CCPlace,CCFlip*,CCToggleVisibility,CCMoveTo*,CCJumpTo*,CCScale*,CCRotate*,CCSkew*,fade,CCCardinalSp*
1 CCAction动作 CCAction作为一个基类.事实上质是一个接口(即抽象类),由它派生的实现类(如运动和转动等)才是我们实际使用的动作.CCAction 的绝大多数实现类都派生自CCF ...
- Swift是一个提供RESTful HTTP接口的对象存储系统,目的是为了提供一个和AWS S3竞争的服务
Swift是一个提供RESTful HTTP接口的对象存储系统,最初起源于Rackspace的Cloud Files,目的是为了提供一个和AWS S3竞争的服务. Swift于2010年开源,是Ope ...
- glibc头文件和宏定义
头文件没啥好说的,无非就是" "和< >的区别,这估计只要是学过C/C++的人都明白.现在的编译器对头文件的包含顺序没有要求,但老的C实现则不一样.当然,我们现在无需关 ...
- nginx配置 负载均衡
配置nginx #配置虚拟主机 server { listen 80; server_name www.testaaa.com; location / { #root /usr/local/nginx ...
- 在vs2015上使用asp.net core+ef core
官方的文档https://docs.asp.net/en/latest/tutorials/first-mvc-app/start-mvc.html 先来看一下实现的效果
- Android Camera2拍照(一)——使用SurfaceView
原文:Android Camera2拍照(一)--使用SurfaceView Camera2 API简介 Android 从5.0(21)开始,引入了新的Camera API Camera2,原来的a ...