spark的standlone模式安装和application 提交
spark的standlone模式安装
安装一个standlone模式的spark集群,这里是最基本的安装,并测试一下如何进行任务提交。
require:提前安装好jdk 1.7.0_80 ;scala 2.11.8
可以参考官网的说明:http://spark.apache.org/docs/latest/spark-standalone.html
1. 到spark的官网下载spark的安装包
http://spark.apache.org/downloads.html
spark-2.0.2-bin-hadoop2.7.tgz.tar
2. 解压缩
cd /home/hadoop/soft
tar -zxvf spark-2.0.2-bin-hadoop2.7.tgz.tar
ln -s /home/hadoop/soft/spark-2.0.2-bin-hadoop2.7 /usr/local/spark
3.配置环境变量
su - hadoop
vi ~/.bashrc
export SPARK_HOME="/usr/local/spark"
export PATH="$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH"
source ~/.bashrc
which spark-shell
4.修改spark的配置
进入spark配置目录进行配置:
cd /usr/local/spark/conf
cp log4j.properties.template log4j.properties ##修改 log4j.rootCategory=WARN, console
cp spark-env.sh.template spark-env.sh
vi spark-env.sh ##设置spark的环境变量,进入spark-env.sh文件添加:
export SPARK_HOME=/usr/local/spark
export SCALA_HOME=/usr/local/scala
至此,Spark就已经安装好了
5. 运行spark:
Spark-Shell命令可以进入spark,可以使用Ctrl D组合键退出Shell:
Spark-Shell
hadoop@ubuntuServer01:~$ spark-shell
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel).
16/12/08 16:44:41 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
16/12/08 16:44:44 WARN SparkContext: Use an existing SparkContext, some configuration may not take effect.
Spark context Web UI available at http://192.168.17.50:4040
Spark context available as 'sc' (master = local[*], app id = local-1481186684381).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.0.2
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_80)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
启动spark服务:
start-master.sh ##
hadoop@ubuntuServer01:~$ start-master.sh
starting org.apache.spark.deploy.master.Master, logging to /usr/local/spark/logs/spark-hadoop-org.apache.spark.deploy.master.Master-1-ubuntuServer01.out
hadoop@ubuntuServer01:~$ jps
2630 Master
2683 Jps
这里我们启动了主结点,jps多了一个Master的spark进程。
如果主节点启动成功,master默认可以通过web访问:http://ubuntuServer01:8080,查看sparkMaster的UI。
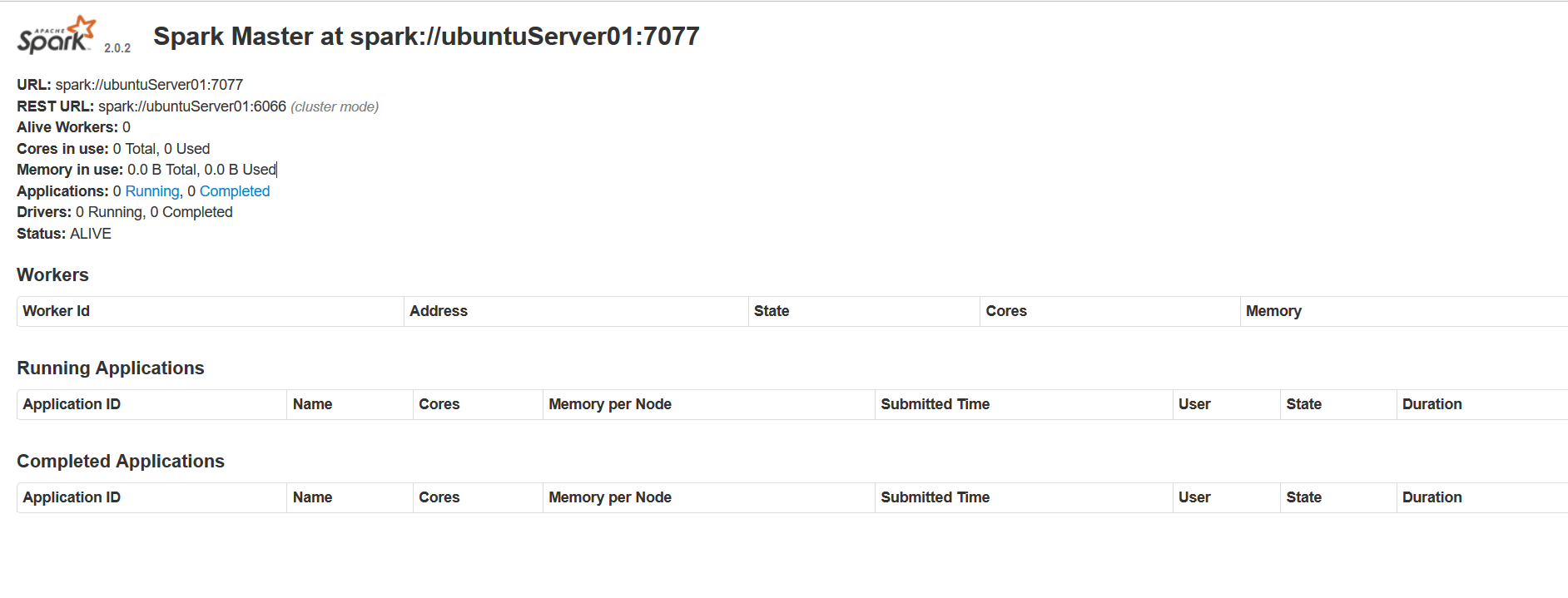
图中所述的spark://ubuntuServer01:7077 就是从结点启动的参数。
spark的master节点HA可以通过zookeeper和Local File System两种方法实现,具体可以参考官方的文档 http://spark.apache.org/docs/latest/spark-standalone.html#high-availability。
启动spark的slave从节点
start-slave.sh spark://ubuntuServer01:7077
hadoop@ubuntuServer01:~$ start-slave.sh spark://ubuntuServer01:7077
starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-ubuntuServer01.out
hadoop@ubuntuServer01:~$ jps
2716 Worker
2765 Jps
2630 Master
hadoop@ubuntuServer01:~$
运行jps命令,发现多了一个spark的worker进程。UI页面上的workers列表中也多了一条记录。
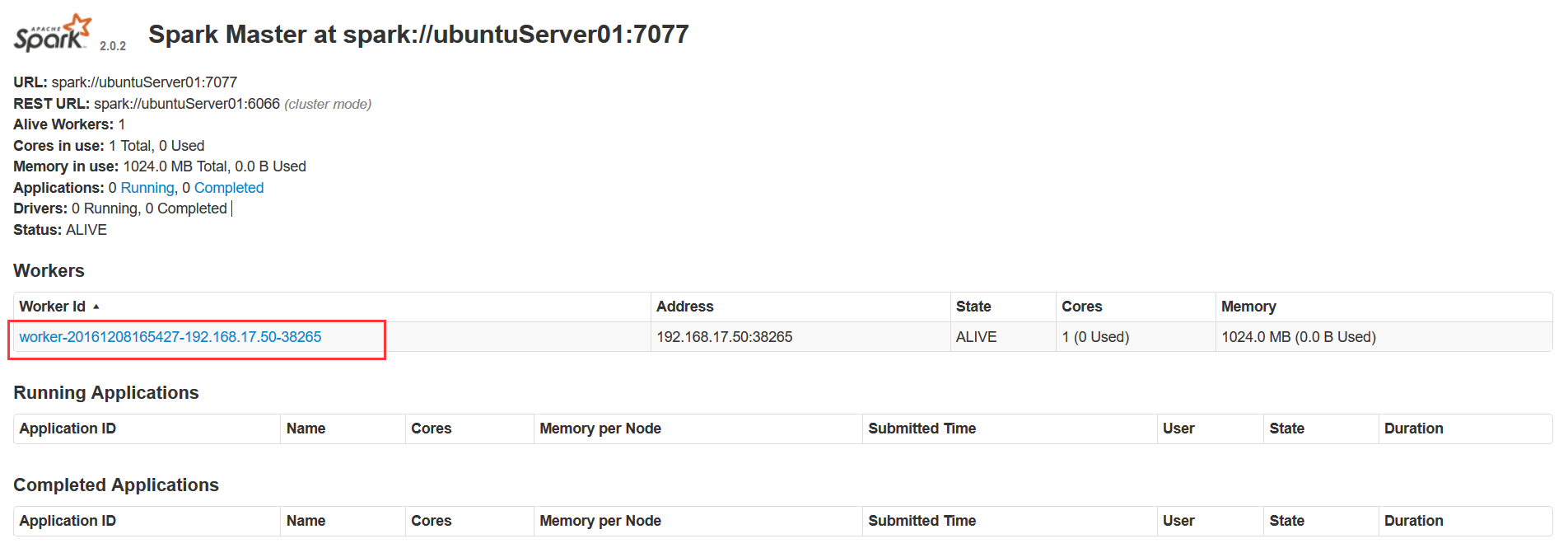
6. 运行一个Application在spark集群上。
运行一个交互式的spark shell在spark集群中:通过如下命令行:
spark-shell --master spark://ubuntuServer01:7077
hadoop@ubuntuServer01:~$ spark-shell --master spark://ubuntuServer01:7077
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel).
16/12/08 17:51:01 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
16/12/08 17:51:05 WARN SparkContext: Use an existing SparkContext, some configuration may not take effect.
Spark context Web UI available at http://192.168.17.50:4040
Spark context available as 'sc' (master = spark://ubuntuServer01:7077, app id = app-20161208175104-0000).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.0.2
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_80)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
从运行日志中可以看到job的UI(Spark web UI)页面地址:http://192.168.17.50:4040
和application id "app-20161208175104-0000",任务运行结束后,Spark web UI页面也会随之关闭。
使用spark-submit脚本执行一个spark任务:
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://ubuntuServer01:7077 \
--executor-memory 1G \
--total-executor-cores 1 \
$SPARK_HOME/examples/jars/spark-examples_2.11-2.0.2.jar \
10
使用spark-submit 提交 application可以参考spark的官方文档。
http://spark.apache.org/docs/latest/submitting-applications.html
spark的standlone模式安装和application 提交的更多相关文章
- 【Spark】Spark的Standalone模式安装部署
Spark执行模式 Spark 有非常多种模式,最简单就是单机本地模式,还有单机伪分布式模式,复杂的则执行在集群中,眼下能非常好的执行在 Yarn和 Mesos 中.当然 Spark 还有自带的 St ...
- spark运行模式之二:Spark的Standalone模式安装部署
Spark运行模式 Spark 有很多种模式,最简单就是单机本地模式,还有单机伪分布式模式,复杂的则运行在集群中,目前能很好的运行在 Yarn和 Mesos 中,当然 Spark 还有自带的 Stan ...
- spark运行模式之一:Spark的local模式安装部署
Spark运行模式 Spark 有很多种模式,最简单就是单机本地模式,还有单机伪分布式模式,复杂的则运行在集群中,目前能很好的运行在 Yarn和 Mesos 中,当然 Spark 还有自带的 Stan ...
- spark跑YARN模式或Client模式提交任务不成功(application state: ACCEPTED)
不多说,直接上干货! 问题详情 电脑8G,目前搭建3节点的spark集群,采用YARN模式. master分配2G,slave1分配1G,slave2分配1G.(在安装虚拟机时) export SPA ...
- spark跑YARN模式或Client模式提交任务不成功(application state: ACCEPTED)(转)
不多说,直接上干货! 问题详情 电脑8G,目前搭建3节点的spark集群,采用YARN模式. master分配2G,slave1分配1G,slave2分配1G.(在安装虚拟机时) export SPA ...
- Spark on YARN模式的安装(spark-1.6.1-bin-hadoop2.6.tgz + hadoop-2.6.0.tar.gz)(master、slave1和slave2)(博主推荐)
说白了 Spark on YARN模式的安装,它是非常的简单,只需要下载编译好Spark安装包,在一台带有Hadoop YARN客户端的的机器上运行即可. Spark on YARN简介与运行wor ...
- Spark的StandAlone模式原理和安装、Spark-on-YARN的理解
Spark是一个内存迭代式运算框架,通过RDD来描述数据从哪里来,数据用那个算子计算,计算完的数据保存到哪里,RDD之间的依赖关系.他只是一个运算框架,和storm一样只做运算,不做存储. Spark ...
- Spark集群模式&Spark程序提交
Spark集群模式&Spark程序提交 1. 集群管理器 Spark当前支持三种集群管理方式 Standalone-Spark自带的一种集群管理方式,易于构建集群. Apache Mesos- ...
- 【Spark篇】---Spark中yarn模式两种提交任务方式
一.前述 Spark可以和Yarn整合,将Application提交到Yarn上运行,和StandAlone提交模式一样,Yarn也有两种提交任务的方式. 二.具体 1.yarn-clien ...
随机推荐
- 如何使用抓包工具fiddler对app进行接口分析
如果你还不知道什么是抓包,点我 如果你还不知道什么是http,点它 如果你想知道什么是fiddler 什么是接口测试 正文来了.安装fiddler后,打开界面,点击tools,找到如图的options ...
- 解决从jenkins打开robot framework报告会提示‘Opening Robot Framework log failed ’的问题
最新的jenkins打开jenkins robot framework报告会提示如下 Verify that you have JavaScript enabled in your browser. ...
- 代码审计之SQL注入
0x00概况说明 0x01报错注入及利用 环境说明 kali LAMP 0x0a 核心代码 现在注入的主要原因是程序员在写sql语句的时候还是通过最原始的语句拼接来完成,另外SQL语句有Select. ...
- WebForm Repeater使用
Repeater: HeaderTemplate: 在加载开始执行一遍 ItemTemplate : 有多少条数据,执行多少遍 FooterTemplate :在加载最后执行一遍 Alternatin ...
- HDU 1880 魔咒词典(字符串哈希)
题目链接 Problem Description 哈利波特在魔法学校的必修课之一就是学习魔咒.据说魔法世界有100000种不同的魔咒,哈利很难全部记住,但是为了对抗强敌,他必须在危急时刻能够调用任何一 ...
- 用于 Linux 平台的 Java
切换到所需的安装目录.键入:cd directory_path_name例如,要将软件安装到 /usr/java/ 目录中,请键入:cd /usr/java/ 将 .tar.gz 档案二进制文件移到当 ...
- python生成器实现杨辉三角
def triangels(): """ 杨辉三角 """ lst = [1] n_count = 2 # 下一行列表长度 while Tr ...
- 如何在Python中实现这五类强大的概率分布
R编程语言已经成为统计分析中的事实标准.但在这篇文章中,我将告诉你在Python中实现统计学概念会是如此容易.我要使用Python实现一些离散和连续的概率分布.虽然我不会讨论这些分布的数学细节,但我会 ...
- 《利用python进行数据分析》读书笔记--第八章 绘图和可视化
http://www.cnblogs.com/batteryhp/p/5025772.html python有许多可视化工具,本书主要讲解matplotlib.matplotlib是用于创建出版质量图 ...
- 《利用python进行数据分析》读书笔记--第六章 数据加载、存储与文件格式
http://www.cnblogs.com/batteryhp/p/5021858.html 输入输出一般分为下面几类:读取文本文件和其他更高效的磁盘存储格式,加载数据库中的数据.利用Web API ...