Spark入门实战系列--5.Hive(上)--Hive介绍及部署
【注】该系列文章以及使用到安装包/测试数据 可以在《倾情大奉送--Spark入门实战系列》获取
、Hive介绍
1.1 Hive介绍
月开源的一个数据仓库框架,提供了类似于SQL语法的HQL语句作为数据访问接口,Hive有如下优缺点:
l 优点:
1.Hive 使用类SQL 查询语法, 最大限度的实现了和SQL标准的兼容,大大降低了传统数据分析人员学习的曲线;
2.使用JDBC 接口/ODBC接口,开发人员更易开发应用;
3.以MR 作为计算引擎、HDFS 作为存储系统,为超大数据集设计的计算/ 扩展能力;
4.统一的元数据管理(Derby、MySql等),并可与Pig 、Presto 等共享;
l 缺点:
1.Hive 的HQL 表达的能力有限,有些复杂运算用HQL 不易表达;
2.由于Hive自动生成MapReduce 作业, HQL 调优困难;
3.粒度较粗,可控性差
1.2 Hive运行架构
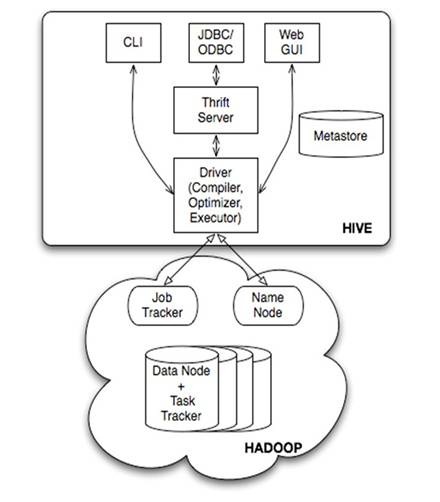
由上图可知,Hadoop的MapReduce是Hive架构的根基。Hive架构包括如下组件:CLI(Command Line Interface)、JDBC/ODBC、Thrift Server、WEB GUI、Metastore和Driver(Complier、Optimizer和Executor),这些组件分为两大类:服务端组件和客户端组件。
服务端组件:
lDriver组件:该组件包括Complier、Optimizer和Executor,它的作用是将HiveQL(类SQL)语句进行解析、编译优化,生成执行计划,然后调用底层的MapReduce计算框架;
lMetastore组件:元数据服务组件,这个组件存储Hive的元数据,Hive的元数据存储在关系数据库里,Hive支持的关系数据库有Derby和Mysql。元数据对于Hive十分重要,因此Hive支持把Metastore服务独立出来,安装到远程的服务器集群里,从而解耦Hive服务和Metastore服务,保证Hive运行的健壮性;
lThrift服务:Thrift是Facebook开发的一个软件框架,它用来进行可扩展且跨语言的服务的开发,Hive集成了该服务,能让不同的编程语言调用Hive的接口。
客户端组件:
lCLI:Command Line Interface,命令行接口。
lThrift客户端:上面的架构图里没有写上Thrift客户端,但是Hive架构的许多客户端接口是建立在Thrift客户端之上,包括JDBC和ODBC接口。
lWEBGUI:Hive客户端提供了一种通过网页的方式访问Hive所提供的服务。这个接口对应Hive的HWI组件(Hive Web Interface),使用前要启动HWI服务。
Hive的执行流程

三种部署模式
1.单用户模式 此模式连接到一个In-Memory 的数据库Derby,一般用于Unit Test。

2.多用户模式 通过网络连接到一个数据库中,是最经常使用到的模式。

3. 远程服务器模式 用于非Java客户端访问元数据库,在服务器端启动MetaStoreServer,客户端利用Thrift协议通过MetaStoreServer访问元数据库。

1.3 Hive数据模型
Hive没有专门的数据存储格式,用户可以自由的组织Hive中的表,只需要在创建表的时候告诉Hive数据中的列分隔符和行分隔符,Hive就可以解析数据。Hive中所有的数据都存储在HDFS中,存储结构主要包括数据库、文件、表和视图。Hive中包含以下数据模型:Table内部表,External Table外部表,Partition分区,Bucket桶。Hive默认可以直接加载文本文件,还支持sequence file 、RCFile。
1.Hive数据库
类似传统数据库的DataBase,在第三方数据库里实际是一张表
简单示例命令行: create database test_database;
2.内部表
Hive的内部表与数据库中的Table在概念上是类似。每一个Table在Hive中都有一个相应的目录存储数据。例如一个表tbInner,它在HDFS中的路径为/user/hive/warehouse/tbInner,其中/user/hive/warehouse是在hive-site.xml中由${hive.metastore.warehouse.dir} 指定的数据仓库的目录,所有的Table数据(不包括External Table)都保存在这个目录中。内部表删除时,元数据与数据都会被删除。
内部表简单示例:
创建数据文件:test_inner_table.txt
创建表:create table test_inner_table (key string);
加载数据:LOAD DATA LOCAL INPATH 'filepath' INTO TABLE test_inner_table;
查看数据:select * from test_inner_table;
删除表:drop table test_inner_table;
3. 外部表
外部表指向已经在HDFS中存在的数据,并可以创建Partition。它和内部表在元数据的组织上是相同的,而实际数据的存储则有较大的差异。内部表的创建过程和数据加载过程这两个过程可以分别独立完成,也可以在同一个语句中完成,在加载数据的过程中,实际数据会被移动到数据仓库目录中;之后对数据对访问将会直接在数据仓库目录中完成。删除表时,表中的数据和元数据将会被同时删除。而外部表只有一个过程,加载数据和创建表同时完成(CREATE EXTERNAL TABLE ……LOCATION),实际数据是存储在LOCATION后面指定的 HDFS 路径中,并不会移动到数据仓库目录中。当删除一个External Table时,仅删除该链接。
外部表简单示例:
创建数据文件:test_external_table.txt
创建表:create external table test_external_table (key string);
加载数据:LOAD DATA INPATH ‘filepath’ INTO TABLE test_inner_table;
查看数据:select * from test_external_table;
删除表:drop table test_external_table;
4.分区
Partition对应于数据库中的Partition列的密集索引,但是Hive中Partition的组织方式和数据库中的很不相同。在Hive中,表中的一个Partition对应于表下的一个目录,所有的Partition的数据都存储在对应的目录中。例如pvs表中包含ds和city两个Partition,则对应于ds = 20090801, ctry = US 的HDFS子目录为/user/hive/warehouse/pvs/ds=20090801/ctry=US;对应于 ds = 20090801, ctry = CA 的HDFS子目录为/user/hive/warehouse/pvs/ds=20090801/ctry=CA。
分区表简单示例:
创建数据文件:test_partition_table.txt
创建表:create table test_partition_table (key string) partitioned by (dt string);
’);
查看数据:select * from test_partition_table;
删除表:drop table test_partition_table;
5.桶
个bucket,首先对user列的值计算Hash,对应Hash值为0的HDFS目录为/user/hive/warehouse/pvs/ds=20090801/ctry=US/part-00000;Hash值为20的HDFS目录为/user/hive/warehouse/pvs/ds=20090801/ctry=US/part-00020。如果想应用很多的Map任务这样是不错的选择。
桶的简单示例:
创建数据文件:test_bucket_table.txt
创建表:create table test_bucket_table (key string) clustered by (key) into 20 buckets;
加载数据:LOAD DATA INPATH ‘filepath’ INTO TABLE test_bucket_table;
查看数据:select * from test_bucket_table; set hive.enforce.bucketing = true;
6.Hive的视图
视图与传统数据库的视图类似。视图是只读的,它基于的基本表,如果改变,数据增加不会影响视图的呈现;如果删除,会出现问题。如果不指定视图的列,会根据select语句后的生成。
示例:create view test_view as select * from test;
1.4 Hive数据类型
Hive支持两种数据类型,一类叫原子数据类型,一类叫复杂数据类型。
l 原子数据类型包括数值型、布尔型和字符串类型,具体如下表所示:
|
基本数据类型 |
||
|
类型 |
描述 |
示例 |
|
TINYINT |
个字节(8位)有符号整数 |
|
|
SMALLINT |
字节(16位)有符号整数 |
|
|
INT |
字节(32位)有符号整数 |
|
|
BIGINT |
字节(64位)有符号整数 |
|
|
FLOAT |
字节(32位)单精度浮点数 |
1.0 |
|
DOUBLE |
字节(64位)双精度浮点数 |
1.0 |
|
BOOLEAN |
true/false |
true |
|
STRING |
字符串 |
‘xia’,”xia” |
由上表我们看到Hive不支持日期类型,在Hive里日期都是用字符串来表示的,而常用的日期格式转化操作则是通过自定义函数进行操作。
字节、2字节、4字节和8字节有符号整数。Hive的浮点数据类型FLOAT和DOUBLE,对应于Java的基本类型Float和Double类型。而Hive的BOOLEAN类型相当于Java的基本数据类型Boolean。对于Hive的String类型相当于数据库的Varchar类型,该类型是一个可变的字符串,不过它不能声明其中最多能存储多少个字符,理论上它可以存储2GB的字符数。
l 复杂数据类型包括数组(ARRAY)、映射(MAP)和结构体(STRUCT),具体如下所示:

1.5 Hive与关系数据库的区别
由于Hive采用了SQL的查询语言HQL,因此很容易将Hive理解为数据库。其实从结构上来看,Hive和数据库除了拥有类似的查询语言,再无类似之处。数据库可以用在Online的应用中,但是Hive是为数据仓库而设计的,清楚这一点,有助于从应用角度理解Hive的特性。
Hive和数据库的比较如下表:
|
Hive |
RDBMS |
|
|
查询语言 |
HQL |
SQL |
|
数据存储 |
HDFS |
Raw Device or Local FS |
|
数据格式 |
用户定义 |
系统决定 |
|
数据更新 |
不支持 |
支持 |
|
索引 |
无 |
有 |
|
执行 |
MapReduce |
Executor |
|
执行延迟 |
高 |
低 |
|
处理数据规模 |
大 |
小 |
|
可扩展性 |
高 |
低 |
、Hive搭建过程
2.1 安装MySql数据库
2.1.1 下载MySql安装文件
下载地址:http://dev.mysql.com/downloads/mysql/#downloads,使用系统为CentOS选择 Red Hat Enterprise Linux/Oracle系列:
位,选择对应安装包进行下载:



下载在本地目录如下图:

2.1.2 上传MySql安装文件
把下载的mysql安装包,使用SSH Secure File Transfer工具(参见《Spark编译与部署(上)--基础环境搭建》1.3.1介绍)上传到/home/hadoop/upload 目录下,如下图所示:

2.1.3 卸载旧的MySql
(1)查找以前是否安装有mysql
使用命令查看是否已经安装过mysql:
$rpm -qa | grep -i mysql
可以看到如下图的所示:

说明之前安装了:
MySQL-client-5.6.21-1.el6.x86_64
MySQL-server-5.6.21-1.el6.x86_64
MySQL-devel-5.6.21-1.el6.x86_64
如果没有结果,可以进行mysql数据库安装
(2)停止mysql服务、删除之前安装的mysql
停止mysql服务、删除之前安装的mysql删除命令:rpm -e –nodeps 包名
$sudo rpm -ev MySQL-server-5.6.21-1.el6.x86_64
$sudo rpm -ev MySQL-devel-5.6.21-1.el6.x86_64
$sudo rpm -ev MySQL-client-5.6.21-1.el6.x86_64

如果存在CentOS自带mysql-libs-5.1.71-1.el6.x86_64使用下面的命令卸载即可
$sudo rpm -ev --nodeps mysql-libs-5.1.71-1.el6.x86_64

(3)查找之前老版本mysql的目录并且删除老版本mysql的文件和库
$sudo find / -name mysql

删除对应的mysql目录
$sudo rm -rf /usr/lib64/mysql
$sudo rm -rf /var/lib/mysql

(4)再次查找机器是否安装mysql
$sudo rpm -qa | grep -i mysql
无结果,说明已经卸载彻底、接下来直接安装mysql即可

2.1.4 安装MySql
进入安装文件的目录,安装mysql服务端
$cd /home/hadoop/upload
$sudo rpm -ivh MySQL-server-5.6.21-1.el6.x86_64.rpm
安装mysql客户端、mysql-devel
$sudo rpm -ivh MySQL-client-5.6.21-1.el6.x86_64.rpm
$sudo rpm -ivh MySQL-devel-5.6.21-1.el6.x86_64.rpm

2.1.5 设置root密码
在CentOS6.5下安装mysql设置root密码时,出现如下错误:

/usr/bin/mysqladmin: connect to server at 'localhost' failed
error: 'Access denied for user 'root'@'localhost' (using password: NO)'
可以进入安全模式进行设置root密码
(1)停止mysql服务
使用如下命令停止mysql服务:
$sudo service mysql stop
$sudo service mysql status

(2)跳过验证启动mysql
使用如下命令验证启动mysql,由于&结尾是后台运行进程,运行该命令可以再打开命令窗口或者Ctr+C继续进行下步操作,由于mysql启动时间会长点,需要等待几分钟再查看启动状态:
$sudo mysqld_safe --skip-grant-tables &
$sudo service mysql status

(3)跳过验证启动MySQL
验证mysql服务已经在后台运行后,执行如下语句,其中后面三条命令是在mysql语句:
mysql -u root
mysql>use mysql;
mysql>update user set password = password('root') where user = 'root';
mysql>flush privileges;
mysql>quit;
(4)跳过验证启动MySQL
重启mysql服务并查看状态
$sudo service mysql stop
$sudo service mysql start
$sudo service mysql status

2.1.6 设置Hive用户
进入mysql命令行,创建Hive用户并赋予所有权限:
mysql -uroot -proot
mysql>set password=password('root');
mysql>create user 'hive' identified by 'hive';
mysql>grant all on *.* TO 'hive'@'%' with grant option;
mysql>flush privileges;
mysql>quit;
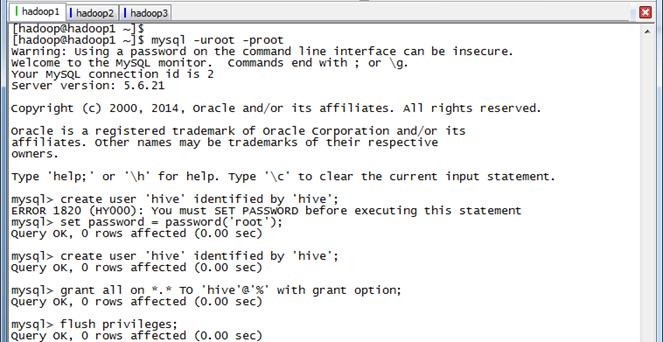
(注意:如果是root第一次登录数据库,需要重新设置一下密码,所报异常信息如下:ERROR 1820 (HY000): You must SET PASSWORD before executing this statement)
2.1.7 创建Hive数据库
使用hive用户登录,创建Hive数据库:
mysql -uhive -phive
mysql>create database hive;
mysql>show databases;

2.2 安装Hive
2.2.1 下载Hive安装文件
可以到Apache基金hive官网http://hive.apache.org/downloads.html,选择镜像下载地址:http://mirrors.cnnic.cn/apache/hive/下载一个稳定版本,这里选择下载apache-hive-0.13.1-bin.tar.gz文件,如下图所示:
2.2.2 下载MySql驱动
到mysql官网进入下载页面:http://dev.mysql.com/downloads/connector/j/,默认情况下是Windows安装包,这里需要选择Platform Independent版本下载zip格式的文件
2.2.3 上传Hive安装文件和MySql驱动
把下载的hive安装包和mysql驱动包,使用SSH Secure File Transfer工具(参见《Spark编译与部署(上)--基础环境搭建》1.3.1介绍)上传到/home/hadoop/upload 目录下,如下图所示:

2.2.4 解压缩
到上传目录下,用如下命令解压缩hive安装文件:
cd /home/hadoop/upload
tar -zxf hive-0.13.1-bin.tar.gz

改名并迁移到/app/hadoop目录下:
sudo mv apache-hive-0.13.1-bin /app/hadoop/hive-0.13.1
ll /app/hadoop

2.2.5 把MySql驱动放到Hive的lib目录下
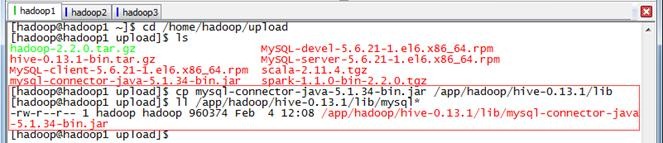
把下载的hive安装包和mysql驱动包,使用
cd /home/hadoop/upload
cp mysql-connector-java-5.1.34-bin.jar /app/hadoop/hive-0.13.1/lib
2.2.6 配置/etc/profile环境变量
使用如下命令打开/etc/profile文件:
sudo vi /etc/profile

设置如下参数:
export HIVE_HOME=/app/hadoop/hive-0.13.1
export PATH=$PATH:$HIVE_HOME/bin
export CLASSPATH=$CLASSPATH:$HIVE_HOME/bin

使配置文件生效:
source /etc/profile

2.2.7 设置hive-env.sh配置文件
进入hive-0.13.1/conf目录,复制hive-env.sh.templaete为hive-env.sh:
cd /app/hadoop/hive-0.13.1/conf
cp hive-env.sh.template hive-env.sh
ls
使用如下命令边界配置文件
sudo vi hive-env.sh
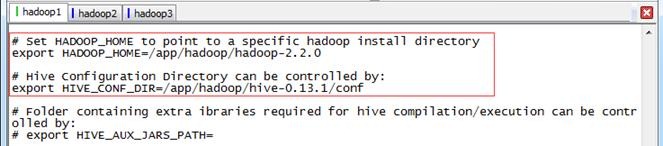
分别设置HADOOP_HOME和HIVE_CONF_DIR两个值:
# Set HADOOP_HOME to point to a specific hadoop install directory
export HADOOP_HOME=/app/hadoop/hadoop-2.2.0
# Hive Configuration Directory can be controlled by:
export HIVE_CONF_DIR=/app/hadoop/hive-0.13.1/conf
2.2.8 设置hive-site.xml配置文件
复制hive-default.xml.templaete为hive-site.xml
cp hive-default.xml.template hive-site.xml
sudo vi hive-site.xml

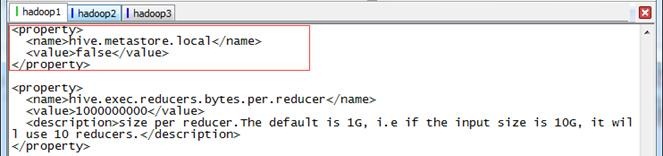
(1)加入配置项
默认metastore在本地,添加配置改为非本地
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
(2)修改配置项
hive默认为derby数据库,derby数据只运行单个用户进行连接,这里需要调整为mysql数据库
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop1:9083</value>
<description>Thrift URI for the remote metastore. ...</description>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop1:3306/hive?=createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
.......
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<description>password to use against metastore database</description>
</property>


把hive.metastore.schema.verification配置项值修改为false
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
<desc....>
</property>

2.3 启动并验证Hive
2.3.1 启动Hive
实际使用时,一般通过后台启动metastore和hiveserver实现服务,命令如下:
hive --service metastore &
hive --service hiveserver &
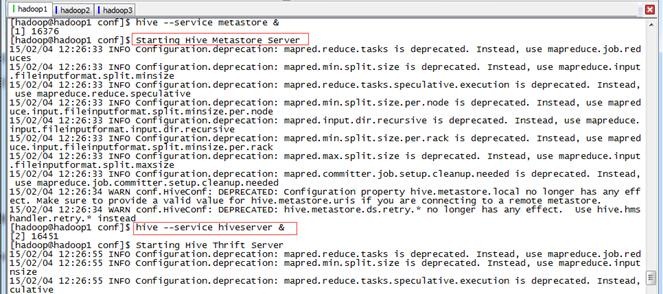
启动用通过jps命令可以看到两个进行运行在后台
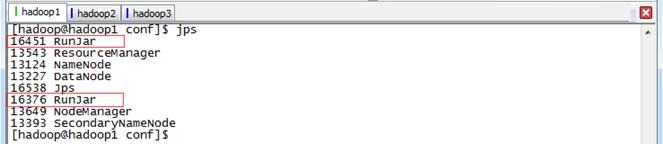
2.3.2 在Hive中操作
登录hive,在hive创建表并查看该表,命令如下:
hive
hive>create table test(a string, b int);
hive>show tables;
hive>desc test;
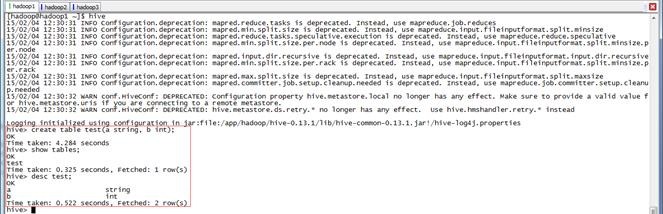
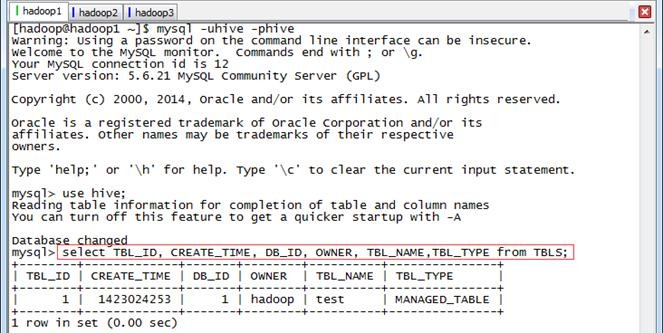
登录mysql,在TBLS表中查看新增test表:
mysql -uhive -phive
mysql>use hive;
mysql>select TBL_ID, CREATE_TIME, DB_ID, OWNER, TBL_NAME,TBL_TYPE from TBLS;
、问题解决
3.1 设置MySql数据库root用户密码报错
在CentOS6.5下安装mysql设置root密码时,出现如下错误:

/usr/bin/mysqladmin: connect to server at 'localhost' failed
error: 'Access denied for user 'root'@'localhost' (using password: NO)'
(1)停止mysql服务
使用如下命令停止mysql服务:
sudo service mysql stop
sudo service mysql status

(2)跳过验证启动mysql
使用如下命令验证启动mysql,由于&结尾是后台运行进程,运行该命令可以再打开命令窗口或者Ctr+C继续进行下步操作:
mysqld_safe --skip-grant-tables &
sudo service mysql status

(3)跳过验证启动MySQL
验证mysql服务已经在后台运行后,执行如下语句,其中后面三条命令是在mysql语句:
mysql -u root
mysql>use mysql;
mysql>update user set password = password('root') where user = 'root';
mysql>flush privileges;
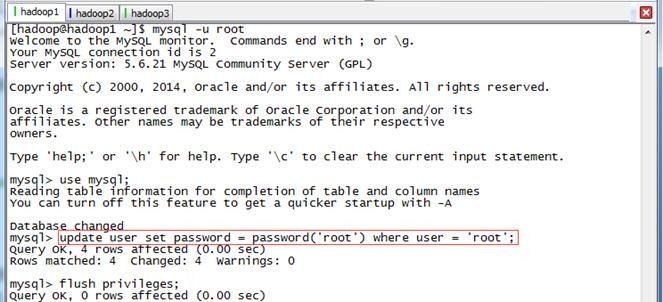
(4)跳过验证启动MySQL
重启mysql服务并查看状态
sudo service mysql stop
sudo service mysql start
sudo service mysql status

3.2 Hive启动,报CommandNeedRetryException异常
启动Hive时,出现CommandNeedRetryException异常,具体信息如下:

Exception in thread "main" java.lang.NoClassDefFoundError:org/apache/hadoop/hive/ql/CommandNeedRetryException
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:270)
at org.apache.hadoop.util.RunJar.main(RunJar.java:149)
Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.hive.ql.CommandNeedRetryException
at java.net.URLClassLoader$1.run(URLClassLoader.java:366)
at java.net.URLClassLoader$1.run(URLClassLoader.java:355)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:354)
at java.lang.ClassLoader.loadClass(ClassLoader.java:425)
at java.lang.ClassLoader.loadClass(ClassLoader.java:358)
由于以前使用hadoop时,修改hadoop-env.sh的HADOOP_CLASSPATH配置项,由以前的:
export HADOOP_CLASSPATH=/usr/local/hadoop-1.1.2/myclass
修改为:
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:/usr/local/hadoop-1.1.2/myclass


3.3 在Hive中使用操作语言
启动Hive后,使用HSQL出现异常,需要启动metastore和hiveserver
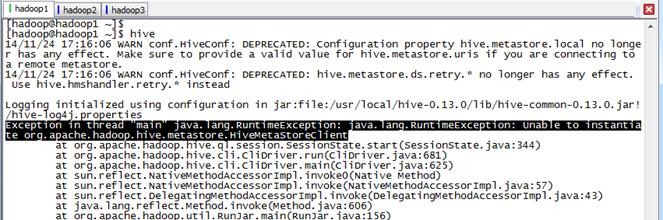
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.metastore.HiveMetaStoreClient
在使用hive之前需要启动metastore和hiveserver服务,通过如下命令启用:
hive --service metastore &
hive --service hiveserver &
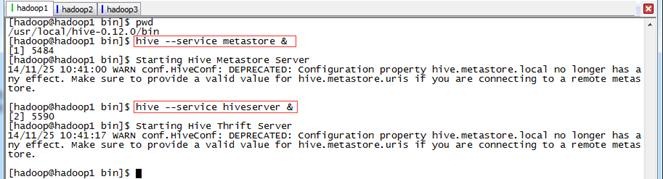
启动用通过jps命令可以看到两个进行运行在后台

参考资料:
(1)《Hive体系结构》 http://blog.csdn.net/zhoudaxia/article/details/8855937
(2)《大数据时代的技术hive:hive的数据类型和数据模型》http://www.cnblogs.com/sharpxiajun/archive/2013/06/03/3114560.html
Spark入门实战系列--5.Hive(上)--Hive介绍及部署的更多相关文章
- Spark入门实战系列--10.分布式内存文件系统Tachyon介绍及安装部署
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Tachyon介绍 1.1 Tachyon简介 随着实时计算的需求日益增多,分布式内存计算 ...
- Spark入门实战系列--9.Spark图计算GraphX介绍及实例
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .GraphX介绍 1.1 GraphX应用背景 Spark GraphX是一个分布式图处理 ...
- Spark入门实战系列--5.Hive(下)--Hive实战
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 1.Hive操作演示 1.1 内部表 1.1.1 创建表并加载数据 第一步 启动HDFS ...
- Spark入门实战系列--6.SparkSQL(上)--SparkSQL简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .SparkSQL的发展历程 1.1 Hive and Shark SparkSQL的前身是 ...
- Spark入门实战系列--2.Spark编译与部署(上)--基础环境搭建
[注] 1.该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取: 2.Spark编译与部署将以CentOS 64位操作系统为基础,主要是考虑到实际应用 ...
- Spark入门实战系列--3.Spark编程模型(上)--编程模型及SparkShell实战
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark编程模型 1.1 术语定义 l应用程序(Application): 基于Spar ...
- Spark入门实战系列--7.Spark Streaming(上)--实时流计算Spark Streaming原理介绍
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark Streaming简介 1.1 概述 Spark Streaming 是Spa ...
- Spark入门实战系列--8.Spark MLlib(上)--机器学习及SparkMLlib简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .机器学习概念 1.1 机器学习的定义 在维基百科上对机器学习提出以下几种定义: l“机器学 ...
- Spark入门实战系列--1.Spark及其生态圈简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .简介 1.1 Spark简介 年6月进入Apache成为孵化项目,8个月后成为Apache ...
随机推荐
- 【C-循环结构】
C语言提供了多种循环语句,可以组成各种不同形式的循环结构: 用goto语句和if语句构成循环: 用while语句: 用do-while语句: 用for语句: 一.goto语句 goto语句是一种无条件 ...
- (转)将win7电脑无线网变身WiFi热点,让手机、笔记本共享上网
将win7电脑变身WiFi热点,让手机.笔记本共享上网 功能:开启windows 7的隐藏功能:虚拟WiFi和SoftAP(即虚拟无线AP),就可以让电脑变成无线路由器,实现共享上网,节省网费和路由器 ...
- Linux内核--网络栈实现分析(三)--驱动程序层+链路层(上)
本文分析基于Linux Kernel 1.2.13 原创作品,转载请标明http://blog.csdn.net/yming0221/article/details/7497260 更多请看专栏,地址 ...
- Ajax的同步与异步
原文地址:http://www.cnblogs.com/Joetao/articles/3525007.html <%@ Page Language="C#" AutoEve ...
- java多线程(精华版)
在 Java 程序中使用多线程要比在 C 或 C++ 中容易得多,这是因为 Java 编程语言提供了语言级的支持.本文通过简单的编程示例来说明 Java 程序中的多线程是多么直观.读完本文以后,用户应 ...
- Java 程序性能优化
1. singleton延时初始化 class Singleton { private static Singleton _instance = null; public synchronized S ...
- unity初始篇 选择游戏对象
之前两任社长都在一直强调要写博客,一直没有写过,现在我已经踏上了博客的道路! 首先声明:本人才疏学浅,对unity认识不深,有错误的地方欢迎大家指出,在此谢过! 本文所说的选择对象,是指在游戏过程中动 ...
- DataPager 分页样式(css)
<asp:DataPager ID="> <Fields> <asp:NextPreviousPagerField ShowFirstPageButton=&q ...
- 一种基于Orleans的分布式Id生成方案
基于Orleans的分布式Id生成方案,因Orleans的单实例.单线程模型,让这种实现变的简单,贴出一种实现,欢迎大家提出意见 public interface ISequenceNoGenerat ...
- [.net 面向对象编程基础] (11) 面向对象三大特性——封装
[.net 面向对象编程基础] (11) 面向对象三大特性——封装 我们的课题是面向对象编程,前面主要介绍了面向对象的基础知识,而从这里开始才是面向对象的核心部分,即 面向对象的三大特性:封装.继承. ...