感知机的对偶形式——python3实现
运用对偶的(对应原始)感知机算法实现线性分类。
参考书目:《统计学习方法》(李航)
算法原理:



代码实现:
环境:win7 32bit + Anaconda3 +spyder
和原始算法的实现基本框架是类似的,只是判断和权值的更新算法有点变化。
# -*- coding: utf-8 -*-
"""
Created on Fri Nov 18 01:29:35 2016 @author: Administrator
""" import numpy as np
from matplotlib import pyplot as plt # train matrix
def get_train_data():
M1 = np.random.random((100,2))
# 将label加到最后,方便后面操作
M11 = np.column_stack((M1,np.ones(100))) M2 = np.random.random((100,2)) - 0.7
M22 = np.column_stack((M2,np.ones(100)*(-1)))
# 合并两类,并将位置索引加到最后
MA = np.vstack((M11,M22))
MA = np.column_stack((MA,range(0,200))) # 作图操作
plt.plot(M1[:,0],M1[:,1], 'ro')
plt.plot(M2[:,0],M2[:,1], 'go')
# 为了美观,根据数据点限制之后分类线的范围
min_x = np.min(M2)
max_x = np.max(M1)
# 分隔x,方便作图
x = np.linspace(min_x, max_x, 100)
# 此处返回 x 是为了之后作图方便
return MA,x # GRAM计算
def get_gram(MA):
GRAM = np.empty(shape=(200,200))
for i in range(len(MA)):
for j in range(len(MA)):
GRAM[i,j] = np.dot(MA[i,][:2], MA[j,][:2])
return GRAM # 方便在train函数中识别误分类点
def func(alpha,b,xi,yi,yN,index,GRAM):
pa1 = alpha*yN
pa2 = GRAM[:,index]
num = yi*(np.dot(pa1,pa2)+b)
return num # 训练training data
def train(MA, alpha, b, GRAM, yN):
# M 存储每次处理后依旧处于误分类的原始数据
M = []
for sample in MA:
xi = sample[0:2]
yi = sample[-2]
index = int(sample[-1])
# 如果为误分类,改变alpha,b
# n 为学习率
if func(alpha,b,xi,yi,yN,index,GRAM) <= 0:
alpha[index] += n
b += n*yi
M.append(sample)
if len(M) > 0:
# print('迭代...')
train(M, alpha, b, GRAM, yN)
return alpha,b # 作出分类线的图
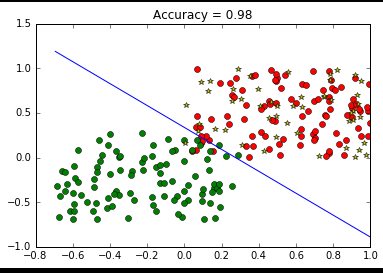
def plot_classify(w,b,x, rate0):
y = (w[0]*x+b)/((-1)*w[1])
plt.plot(x,y)
plt.title('Accuracy = '+str(rate0)) # 随机生成testing data 并作图
def get_test_data():
M = np.random.random((50,2))
plt.plot(M[:,0],M[:,1],'*y')
return M
# 对传入的testing data 的单个样本进行分类
def classify(w,b,test_i):
if np.sign(np.dot(w,test_i)+b) == 1:
return 1
else:
return 0 # 测试数据,返回正确率
def test(w,b,test_data):
right_count = 0
for test_i in test_data:
classx = classify(w,b,test_i)
if classx == 1:
right_count += 1
rate = right_count/len(test_data)
return rate if __name__=="__main__":
MA,x= get_train_data()
test_data = get_test_data()
GRAM = get_gram(MA)
yN = MA[:,2]
xN = MA[:,0:2]
# 定义初始值
alpha = [0]*200
b = 0
n = 1
# 初始化最优的正确率
rate0 = 0 # print(alpha,b)
# 循环不同的学习率n,寻求最优的学习率,即最终的rate0
# w0,b0为对应的最优参数
for i in np.linspace(0.01,1,100):
n = i
alpha,b = train(MA, alpha, b, GRAM, yN)
alphap = np.column_stack((alpha*yN,alpha*yN))
w = sum(alphap*xN)
rate = test(w,b,test_data)
# print(w,b)
rate = test(w,b,test_data)
if rate > rate0:
rate0 = rate
w0 = w
b0 = b
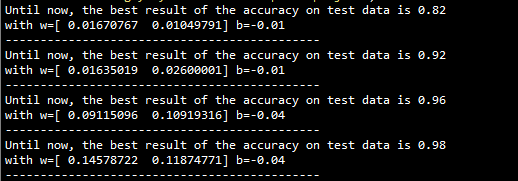
print('Until now, the best result of the accuracy on test data is '+str(rate))
print('with w='+str(w0)+' b='+str(b0))
print('---------------------------------------------')
# 在选定最优的学习率后,作图
plot_classify(w0,b0,x,rate0)
plt.show()
输出:
感知机的对偶形式——python3实现的更多相关文章
- 2. 感知机(Perceptron)基本形式和对偶形式实现
1. 感知机原理(Perceptron) 2. 感知机(Perceptron)基本形式和对偶形式实现 3. 支持向量机(SVM)拉格朗日对偶性(KKT) 4. 支持向量机(SVM)原理 5. 支持向量 ...
- 1. 感知机原理(Perceptron)
1. 感知机原理(Perceptron) 2. 感知机(Perceptron)基本形式和对偶形式实现 3. 支持向量机(SVM)拉格朗日对偶性(KKT) 4. 支持向量机(SVM)原理 5. 支持向量 ...
- 机器学习理论基础学习3.1--- Linear classification 线性分类之感知机PLA(Percetron Learning Algorithm)
一.感知机(Perception) 1.1 原理: 感知机是二分类的线性模型,其输入是实例的特征向量,输出的是事例的类别,分别是+1和-1,属于判别模型. 假设训练数据集是线性可分的,感知机学习的目标 ...
- 机器学习笔记(一)· 感知机算法 · 原理篇
这篇学习笔记强调几何直觉,同时也注重感知机算法内部的动机.限于篇幅,这里仅仅讨论了感知机的一般情形.损失函数的引入.工作原理.关于感知机的对偶形式和核感知机,会专门写另外一篇文章.关于感知机的实现代码 ...
- 统计学习方法与Python实现(一)——感知机
统计学习方法与Python实现(一)——感知机 iwehdio的博客园:https://www.cnblogs.com/iwehdio/ 1.定义 假设输入的实例的特征空间为x属于Rn的n维特征向量, ...
- 吴裕雄 python 机器学习——人工神经网络与原始感知机模型
import numpy as np from matplotlib import pyplot as plt from mpl_toolkits.mplot3d import Axes3D from ...
- 感知机算法(PLA)代码实现
目录 1. 引言 2. 载入库和数据处理 3. 感知机的原始形式 4. 感知机的对偶形式 5. 多分类情况-one vs. rest 6. 多分类情况-one vs. one 7. sklearn实现 ...
- 【python与机器学习实战】感知机和支持向量机学习笔记(一)
对<Python与机器学习实战>一书阅读的记录,对于一些难以理解的地方查阅了资料辅以理解并补充和记录,重新梳理一下感知机和SVM的算法原理,加深记忆. 1.感知机 感知机的基本概念 感知机 ...
- 原始感知机入门——python3实现
运用最简单的原始(对应的有对偶)感知机算法实现线性分类. 参考书目:<统计学习方法>(李航) 算法原理: 踩到的坑:以为误分类的数据只使用一次,造成分类结果很差,在train函数内加个简单 ...
随机推荐
- 使用caffe时遇到的问题
1.Error: (unix time) try if you are using GNU date 问题所在: 在训练train.txt图片列表位置和生成的lmbd数据不符. 解决方案: 修改tra ...
- Android的常用adb命令
第一部分:1. ubuntu下配置环境anroid变量:在终端执行 sudo gedit /etc/profile 打开文本编辑器,在最后追加#setandroid environment2. 运行E ...
- mybatis高级(2)_数据库中的列和实体类不匹配时的两种解决方法_模糊查询_智能标签
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "- ...
- Python【8】-分析json文件
一.本节用到的基础知识 1.逐行读取文件 for line in open('E:\Demo\python\json.txt'): print line 2.解析json字符串 Python中有一些内 ...
- 新手使用django-pagination分页
首先使用pip instal pagination 即可完成安装. (pycharm里就是安装个django-pagination外包) 完成后配置如下: 1. 将安装文件中的 pagination ...
- 工作需求----表单多选框checkbox交互
关于多选框,反选及选取几个: 1.html内容 <!--begin checkbox--> <div class="c_n_manage_tablexx"> ...
- js中正则表达式 ---- 现成
1 . 校验密码强度 密码的强度必须是包含大小写字母和数字的组合,不能使用特殊字符,长度在8-10之间. ^(?=.*\\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$ 2. 校验中 ...
- 用 QGIS 画矢量交通路线图
一.准备工作 1.安装插件 为了方便画图,我们安装了OpenLayers,QuickOSM两个插件. 如何安装插件,度娘上都有答案.下图中打勾的部分为安装好的插件: OpenLayers提供了一些开放 ...
- textbox button 模拟fileupload
方案一: <%@ Page Language="C#" AutoEventWireup="true" CodeBehind="test.asp ...
- QT 做软件盘
最近搞了一个组织细胞脱水机项目,当然,对于国内的项目都是仿来仿去的,我们也不例外,开启被仿机器后,第一个看到的界面就是用户登录界面,需要输入中文,作为一个程序员,我的第一反应就是我需要采用什么用的框架 ...