Hadoop系列008-HDFS的数据流
本人微信公众号,欢迎扫码关注!

HDFS的数据流
1 HDFS写数据流程
1.1 剖析文件写入

1)客户端向namenode请求上传文件,namenode检查目标文件是否已存在,父目录是否存在。
2)namenode返回是否可以上传。
3)客户端请求第一个 block上传到哪几个datanode服务器上。
4)namenode返回3个datanode节点,分别为dn1、dn2、dn3。
5)客户端请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成
6)dn1、dn2、dn3逐级应答客户端
7)客户端开始往dn1上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,dn1收到一个packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答
8)当一个block传输完成之后,客户端再次请求namenode上传第二个block的服务器。(重复执行3-7步)
1.2 网络拓扑概念
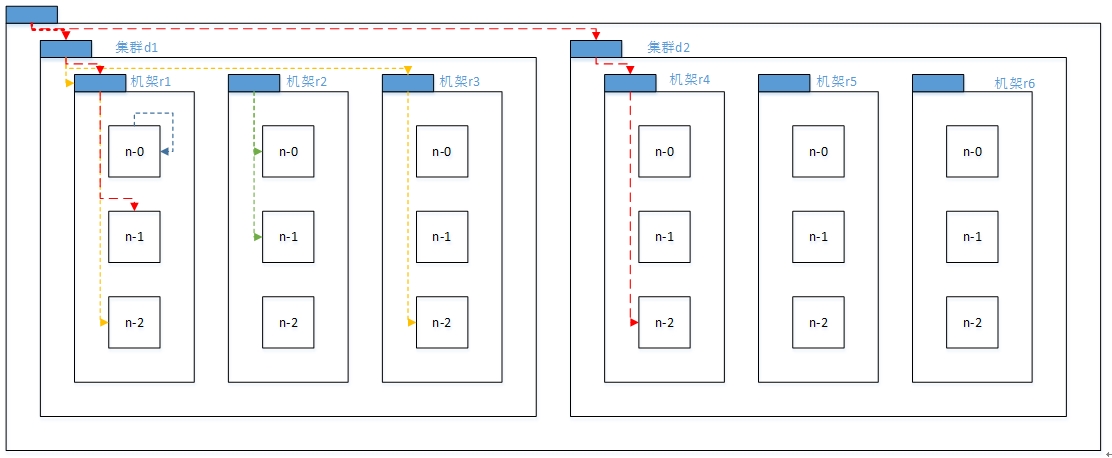
在本地网络中,两个节点被称为“彼此近邻”是什么意思?在海量数据处理中,其主要限制因素是节点之间数据的传输速率——带宽很稀缺。这里的想法是将两个节点间的带宽作为距离的衡量标准。
节点距离:两个节点到达最近的共同祖先的距离总和。
例如,假设有数据中心d1机架r1中的节点n1。该节点可以表示为/d1/r1/n1。利用这种标记,这里给出四种距离描述。
Distance(/d1/r1/n1, /d1/r1/n1)=0(同一节点上的进程)
Distance(/d1/r1/n1, /d1/r1/n2)=2(同一机架上的不同节点)
Distance(/d1/r1/n1, /d1/r3/n2)=4(同一数据中心不同机架上的节点)
Distance(/d1/r1/n1, /d2/r4/n2)=6(不同数据中心的节点)
1.3 机架感知(副本节点选择)
1.3.1 官方地址
http://hadoop.apache.org/docs/r2.7.3/hadoop-project-dist/hadoop-common/RackAwareness.html
1.3.2 低版本Hadoop复本节点选择
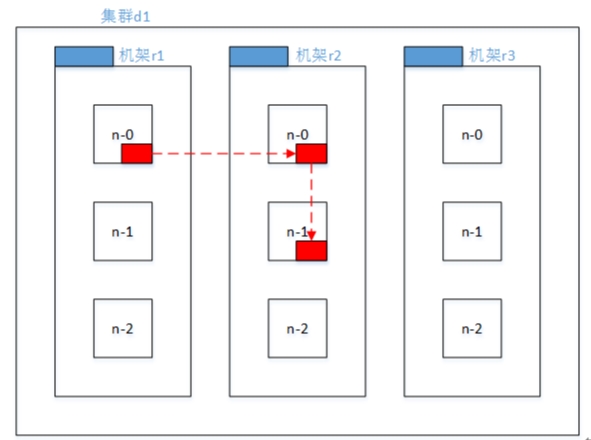
- 第一个复本在client所处的节点上。如果客户端在集群外,随机选一个。
- 第二个复本和第一个复本位于不相同机架的随机节点上。
- 第三个复本和第二个复本位于相同机架,节点随机。
1.3.3 Hadoop2.7.2副本节点选择
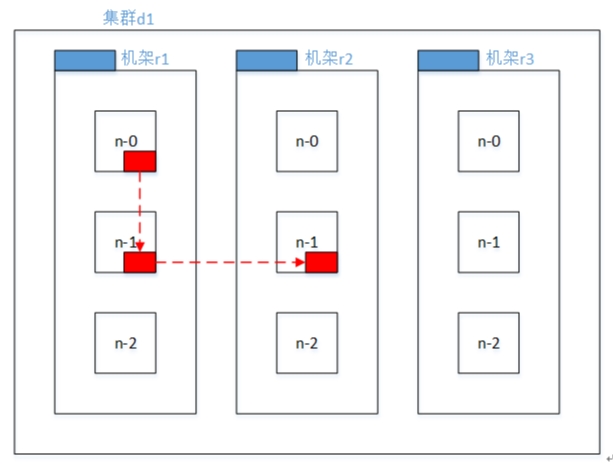
- 第一个副本在client所处的节点上。如果客户端在集群外,随机选一个。
- 第二个副本和第一个副本位于相同机架,随机节点。
- 第三个副本位于不同机架,随机节点。
1.3.4 自定义机架感知
(0)环境准备
(a)数据节点的量
[rack1]:hadoop102、hadoop103
[rack2]:hadoop104、hadoop105
(b)增加一个数据节点
(1)克隆一个节点
(2)启动新节点
(3)修改克隆的ip和主机名
(4)在hadoop102上ssh到新节点
(5)修改xsync.sh和xcall.sh文件
(6)修改hadoop102 slaves文件,再分发
(1)创建类实现DNSToSwitchMapping接口
public class MyDNSToSwichMapping implements DNSToSwitchMapping {
// 传递的是客户端的ip列表,返回机架感知的路径列表
public List<String> resolve(List<String> names) { ArrayList<String> lists = new ArrayList<String>();
if (names != null && names.size() > 0) {
for (String name : names) {
int ip = 0;
// 获取ip地址
if (name.startsWith("hadoop")) {
String no = name.substring(6);
// hadoop102
ip = Integer.parseInt(no);
} else if (name.startsWith("192")) {
// 192.168.10.102
ip = Integer.parseInt(name.substring(name.lastIndexOf(".") + 1));
} // 定义机架
if (ip < 104) {
lists.add("/rack1/" + ip);
} else {
lists.add("/rack2/" + ip);
}
}
} // 把ip地址打印出来
try {
FileOutputStream fos = new FileOutputStream("/home/atguigu/name.txt"); for (String name : lists) {
fos.write((name + "\r\n").getBytes());
}
fos.close();
} catch (Exception e) {
e.printStackTrace();
}
return lists;
}
public void reloadCachedMappings() {
}
public void reloadCachedMappings(List<String> names) {
}
}
(2)配置core-site.xml
默认的:
<!-- Topology Configuration -->
<property>
<name>net.topology.node.switch.mapping.impl</name>
<value>org.apache.hadoop.net.ScriptBasedMapping</value>
</property>
配置后的
<!-- Topology Configuration -->
<property>
<name>net.topology.node.switch.mapping.impl</name>
<value>com.atguigu.hdfs.MyDNSToSwichMapping</value>
</property>
(3)分发core-site.xml
xsync /opt/module/hadoop-2.7.2/etc/hadoop/core-site.xml
(4)编译程序,打成jar,分发到所有节点的hadoop的classpath下
cd /opt/module/hadoop-2.7.2/share/hadoop/common/lib
xsync MyDNSSwitchToMapping.jar
(5)重新启动集群
(6)在名称节点hadoop103主机上查看名称
(7)查看结果
(1)在hadoop105节点上传文件到hdfs文件系统,查看复本存放位置
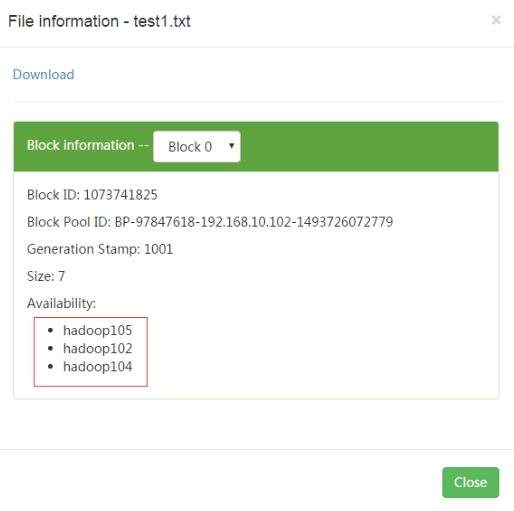
(2)在hadoop102节点上传文件到hdfs文件系统,查看复本存放位置
(3)结论
第一个副本在client所处的节点上。如果客户端在集群外,随机选一个。
第二个副本和第一个副本位于相同机架,随机节点。
第三个副本位于不同机架,随机节点。
2 HDFS读数据流程
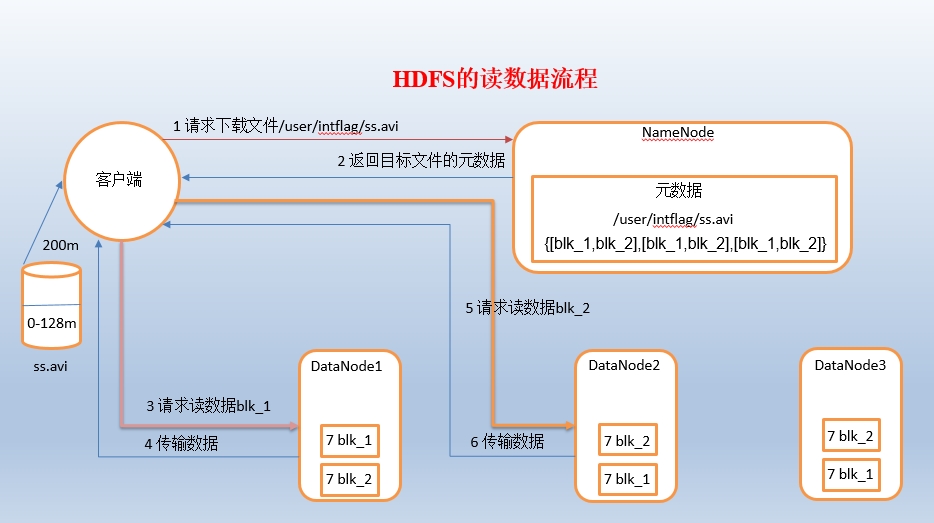
1)客户端向namenode请求下载文件,namenode通过查询元数据,找到文件块所在的datanode地址。
2)挑选一台datanode(就近原则,然后随机)服务器,请求读取数据。
3)datanode开始传输数据给客户端(从磁盘里面读取数据放入流,以packet为单位来做校验)。
4)客户端以packet为单位接收,先在本地缓存,然后写入目标文件。
3 一致性模型
3.1 debug调试如下代码
@Test
public void writeFile() throws Exception{
// 1 创建配置信息对象
Configuration configuration = new Configuration();
fs = FileSystem.get(configuration);
// 2 创建文件输出流
Path path = new Path("hdfs://hadoop102:8020/user/atguigu/hello.txt");
FSDataOutputStream fos = fs.create(path);
// 3 写数据
fos.write("hello".getBytes());
// fos.flush();
fos.hflush();
//
// fos.write("welcome to atguigu".getBytes());
// fos.hsync();
fos.close();
}
3.2 总结
- 写入数据时,如果希望数据被其他client立即可见,调用如下方法
- FsDataOutputStream.hflus(); //清理客户端缓冲区数据,被其他client立即可见
- FsDataOutputStream.hsync(); //清理客户端缓冲区数据,被其他client不能立即可见
Hadoop系列008-HDFS的数据流的更多相关文章
- hadoop系列二:HDFS文件系统的命令及JAVA客户端API
转载请在页首明显处注明作者与出处 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的一些内容,如hadoop,spark,storm,机器学习等. 当前使用的hadoop版本为2.6 ...
- hadoop系列(二)分布式文件系统HDFS
根据core-site.xml的配置,接下来就可以通过:hdfs://localhost:9000来对hdfs进行操作了. 1.创建输入目录 C:\WINDOWS\system32>hadoop ...
- hadoop系列一:hadoop集群安装
转载请在页首明显处注明作者与出处 http://www.cnblogs.com/zhuxiaojie/p/6384393.html 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据 ...
- hadoop系列三:mapreduce的使用(一)
转载请在页首明显处注明作者与出处 http://www.cnblogs.com/zhuxiaojie/p/7224772.html 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的 ...
- hadoop系列四:mapreduce的使用(二)
转载请在页首明显处注明作者与出处 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的一些内容,如hadoop,spark,storm,机器学习等. 当前使用的hadoop版本为2.6 ...
- Hadoop系列007-HDFS客户端操作
title: Hadoop系列007-HDFS客户端操作 date: 2018-12-6 15:52:55 updated: 2018-12-6 15:52:55 categories: Hadoop ...
- Hadoop系列004-Hadoop运行模式(上)
title: Hadoop系列004-Hadoop运行模式(上) date: 2018-11-20 14:27:00 updated: 2018-11-20 14:27:00 categories: ...
- Hadoop 系列(三)Java API
Hadoop 系列(三)Java API <dependency> <groupId>org.apache.hadoop</groupId> <artifac ...
- Hadoop系列之(二):Hadoop集群部署
1. Hadoop集群介绍 Hadoop集群部署,就是以Cluster mode方式进行部署. Hadoop的节点构成如下: HDFS daemon: NameNode, SecondaryName ...
随机推荐
- 在Windows Server 2008 R2下搭建jsp环境(二)-JDK的下载安装
因为服务器上的Tomcat的运行环境需要JDK的支持,所以,掌握JDK的安装与下载和配置是一个重要步骤. 1.首先下载最新的JDK版本.网络上提供了最新版本的JDK下载,如图所示.首先选择&quo ...
- kv_storage.go
package storage //kv 存储引擎实现 import ( "github.com/cznic/kv" "io" ) //kv 存 ...
- 使用jvisualvm
jvisualvm是java开发,调试,监控,分析内存的一个可视化工具,可以在安装完JDK中找到,一般在bin目录下 之前调试tomca内存分配,现在总结下心得, windows下的tomcat修改c ...
- BZOJ_1146_[CTSC2008]网络管理Network_主席树+树状数组
BZOJ_1146_[CTSC2008]网络管理Network_主席树 Description M公司是一个非常庞大的跨国公司,在许多国家都设有它的下属分支机构或部门.为了让分布在世界各地的N个 部门 ...
- 【Canal源码分析】parser工作过程
本文主要分析的部分是instance启动时,parser的一个启动和工作过程.主要关注的是AbstractEventParser的start()方法中的parseThread. 一.序列图 二.源码分 ...
- 三元运算符 与 return
有三元运算符可以很好的代替if else简单语句 但是在使用的时候发现 与 return使用的时候 需要用这种形式 错误形式: $a ? return 1 ? return 0; 正确形式: retu ...
- (6)STM32使用HAL库实现modbus的简单通讯
1.判断地址.校验 2.读取本机数据并校验打包 3.发送数据包 4.本机数据长度比要读取的长度短怎么办 4.校验错误怎么办
- C# 指定父層級目錄
lstrcatW(pszpath, "\\..\\..\\"); DWORD dwlen = GetFullPathNameW(pszpath, 0u, null, null); ...
- 关于table表格 td里内容较多换行的处理方法
最近在用table的时候由于td内容较多默认换行了,很不美观.于是找到处理方法: 在声明table的时候添加一个样式: <table id="tbOffice" data-r ...
- iPhone6 AirDrop找不到我的mac解决方法!注销mac和iPhone的icloud账号
注销mac和iPhone的icloud账号,icloud 会自动同步个人热点,个人热点开启状态,mac 和 iPhone 无法看到对方!