Spark学习之RDD编程总结
Spark 对数据的核心抽象——弹性分布式数据集(Resilient Distributed Dataset,简称 RDD)。RDD 其实就是分布式的元素集合。在 Spark 中,对数据的所有操作不外乎创建 RDD、转化已有 RDD 以及调用 RDD 操作进行求值。而在这一切背后,Spark 会自动将RDD 中的数据分发到集群上,并将操作并行化执行。
一、RDD基础
Spark 中的 RDD 就是一个不可变的分布式对象集合。每个 RDD 都被分为多个分区,这些分区运行在集群中的不同节点上。RDD 可以包含 Python、Java、Scala 中任意类型的对象,甚至可以包含用户自定义的对象。用户可以使用两种方法创建 RDD:读取一个外部数据集,或在驱动器程序里分发驱动器程序中的对象集合(比如 list 和 set)。
创建出来后,RDD 支持两种类型的操作:转化操作(transformation)和行动操作(action)。转化操作会由一个 RDD 生成一个新的 RDD。另一方面,行动操作会对 RDD 计算出一个结果,并把结果返回到驱动器程序中,或把结果存储到外部存储系统(如 HDFS)中。
转化操作和行动操作的区别在于 Spark 计算 RDD 的方式不同。虽然你可以在任何时候定义新的 RDD,但 Spark 只会惰性计算这些 RDD。它们只有第一次在一个行动操作中用到时,才会真正计算。这种策略刚开始看起来可能会显得有些奇怪,不过在大数据领域是很有道理的。例如 Spark 在我们运行 lines = sc.textFile(...) 时就把文件中所有的行都读取并存储起来,就会消耗很多存储空间,而我们马上就要筛选掉其中的很多数据。相反, 一旦 Spark 了解了完整的转化操作链之后,它就可以只计算求结果时真正需要的数据。事实上,在行动操作 first() 中,Spark 只需要扫描文件直到找到第一个匹配的行为止,而不需要读取整个文件。
最后,默认情况下,Spark 的 RDD 会在你每次对它们进行行动操作时重新计算。如果想在多个行动操作中重用同一个 RDD,可以使用 RDD.persist() 让 Spark 把这个 RDD 缓存下来。我们可以让 Spark 把数据持久化到许多不同的地方。在第一次对持久化的 RDD 计算之后,Spark 会把 RDD 的内容保存到内存中(以分区方式存储到集群中的各机器上),这样在之后的行动操作中,就可以重用这些数据了。
在任何时候都能进行重算是我们为什么把 RDD 描述为“弹性”的原因。当保存 RDD 数据的一台机器失败时,Spark 还可以使用这种特性来重算出丢掉的分区,这一过程对用户是完全透明的。
总的来说,每个 Spark 程序或 shell 会话都按如下方式工作。
(1) 从外部数据创建出输入 RDD。
(2) 使用诸如 filter() 这样的转化操作对 RDD 进行转化,以定义新的 RDD。
(3) 告诉 Spark 对需要被重用的中间结果 RDD 执行 persist() 操作。
(4) 使用行动操作(例如 count() 和 first() 等)来触发一次并行计算,Spark 会对计算进行优化后再执行。
二、创建RDD
Spark 提供了两种创建 RDD 的方式:读取外部数据集,以及在驱动器程序中对一个集合进行并行化。更常用的方式是从外部存储中读取数据来创建 RDD。
// 初始化Spark
// local 集群url
val conf = new SparkConf().setMaster("local").setAppName("My App")
val sc = new SparkContext(conf)
// 第一种方式创建RDD
// val lines = sc.textFile("words.txt")
// 第二种方式创建RDD
val lines = sc.parallelize(List("pandas","i like pandas"))
println(lines.count());
println(lines.first())
三、RDD操作
RDD 支持两种操作:转化操作和行动操作。RDD 的转化操作是返回一个新的 RDD 的操作,比如 map() 和 filter() ,而行动操作则是向驱动器程序返回结果或把结果写入外部系统的操作,会触发实际的计算,比如 count() 和 first() 。Spark 对待转化操作和行动操作的方式很不一样,因此理解你正在进行的操作的类型是很重要的。如果对于一个特定的函数是属于转化操作还是行动操作感到困惑,你可以看看它的返回值类型:转化操作返回的是 RDD,而行动操作返回的是其他的数据类型。
1、转化操作
RDD 的转化操作是返回新 RDD 的操作。我们会在 上面讲到,转化出来的 RDD 是惰性求值的,只有在行动操作中用到这些 RDD 时才会被计算。许多转化操作都是针对各个元素的,也就是说,这些转化操作每次只会操作 RDD 中的一个元素。不过并不是所有的转化操作都是这样的。举个例子,假定我们有一个日志文件 log.txt,内含有若干消息,希望选出其中的错误消息。我们可以使用前面说过的转化操作 filter() 。
val conf = new SparkConf().setAppName("Test").setMaster("local")
val sc = new SparkContext(conf)
// val lines = sc.parallelize(List("pandas","i like pandas"))
// *****RDD转化操作*********
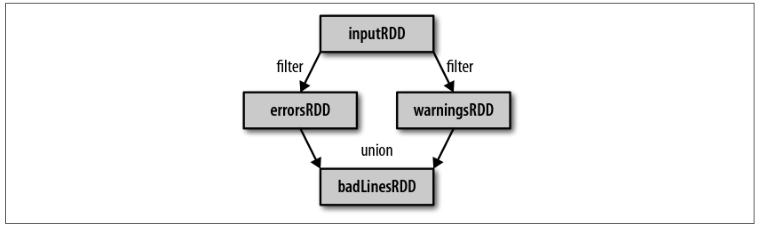
val inputRDD = sc.textFile("log.txt")
val errorsRDD = inputRDD.filter(line => line.contains("ERROR"))
val warningRDD = inputRDD.filter(line => line.contains("WARN"))
val badLinesRDD = errorsRDD.union(warningRDD)
// *****RDD行动操作***********
val x = badLinesRDD.count()
println("Input had "+badLinesRDD.count()+" concerning lines")
println("Here are x examples:")
badLinesRDD.take(10).foreach(println)


通过转化操作,你从已有的 RDD 中派生出新的 RDD,Spark 会使用谱系图(lineage graph)来记录这些不同 RDD 之间的依赖关系。Spark 需要用这些信息来按需计算每个 RDD,也可以依靠谱系图在持久化的 RDD 丢失部分数据时恢复所丢失的数据。下面展示上面代码中创建出的RDD谱系图:
2、行动操作
我们已经看到了如何通过转化操作从已有的 RDD 创建出新的 RDD,不过有时,我们希望对数据集进行实际的计算。行动操作是第二种类型的 RDD 操作,它们会把最终求得的结果返回到驱动器程序,或者写入外部存储系统中。由于行动操作需要生成实际的输出,它
们会强制执行那些求值必须用到的 RDD 的转化操作。我们可能想输出关于 badLinesRDD 的一些信息。为此,需要使用两个行动操作来实现:用 count() 来返回计数结果,用 take() 来收集RDD 中的一些元素。这些代码在上面一节中的示例代码已经体现。
除此之外,只有当你的整个数据集能在单台机器的内存中放得下时,才能使用 collect() ,因此, collect() 不能用在大规模数据集上。在大多数情况下,RDD 不能通过 collect() 收集到驱动器进程中,因为它们一般都很大。此时,我们通常要把数据写到诸如 HDFS 或 Amazon S3 这样的分布式的存储系统中。你可以使用 saveAsTextFile() 、 saveAsSequenceFile() ,或者任意的其他行动操作来把 RDD 的数据内容以各种自带的格式保存起来。
3、惰性求值
RDD 的转化操作都是惰性求值的。这意味着在被调用行动操作之前 Spark 不会开始计算。这对新用户来说可能与直觉有些相违背之处,但是对于那些使用过诸如 Haskell等函数式语言或者类似 LINQ 这样的数据处理框架的人来说,会有些似曾相识。
惰性求值意味着当我们对 RDD 调用转化操作(例如调用 map() )时,操作不会立即执行。相反,Spark 会在内部记录下所要求执行的操作的相关信息。我们不应该把 RDD 看作存放着特定数据的数据集,而最好把每个 RDD 当作我们通过转化操作构建出来的、记录如何计算数据的指令列表。把数据读取到 RDD 的操作也同样是惰性的。因此,当我们调用sc.textFile() 时,数据并没有读取进来,而是在必要时才会读取。和转化操作一样的是,读取数据的操作也有可能会多次执行。
虽然转化操作是惰性求值的,但还是可以随时通过运行一个行动操作来强制Spark 执行 RDD 的转化操作,比如使用 count() 。这是一种对你所写的程序进行部分测试的简单方法。
Spark 使用惰性求值,这样就可以把一些操作合并到一起来减少计算数据的步骤。在类似Hadoop MapReduce 的系统中,开发者常常花费大量时间考虑如何把操作组合到一起,以减少 MapReduce 的周期数。而在 Spark 中,写出一个非常复杂的映射并不见得能比使用很多简单的连续操作获得好很多的性能。因此,用户可以用更小的操作来组织他们的程序,这样也使这些操作更容易管理。
四、常见的转化操作和行动操作
对一个数据为{1, 2, 3, 3}的RDD进行基本的RDD转化操作

对数据分别为{1, 2, 3}和{3, 4, 5}的RDD进行针对两个RDD的转化操作

对一个数据为{1, 2, 3, 3}的RDD进行基本的RDD行动操作

五、持久化(缓存)
Spark RDD 是惰性求值的,而有时我们希望能多次使用同一个 RDD。如果简单地对 RDD 调用行动操作,Spark 每次都会重算 RDD 以及它的所有依赖。这在迭代算法中消耗格外大,因为迭代算法常常会多次使用同一组数据。下面 就是先对 RDD 作一次计数、再把该 RDD 输出的一个小例子。
val conf = new SparkConf().setAppName("wordcount").setMaster("local")
val sc = new SparkContext(conf)
val input = sc.parallelize(List(1,2,3,4))
val result = input.map(x=>x*x)
// 两次执行RDD转化操作
println(result.count())
println(result.collect().mkString(","))
为了避免多次计算同一个 RDD,可以让 Spark 对数据进行持久化。当我们让 Spark 持久化存储一个 RDD 时,计算出 RDD 的节点会分别保存它们所求出的分区数据。如果一个有持久化数据的节点发生故障,Spark 会在需要用到缓存的数据时重算丢失的数据分区。如果希望节点故障的情况不会拖累我们的执行速度,也可以把数据备份到多个节点上。出于不同的目的,我们可以为 RDD 选择不同的持久化级别。在 Scala 中,默认情况下 persist() 会把数据以序列化的形式缓存在 JVM 的堆空间中。cache() 与使用默认存储级别调用 persist() 是一样的。
org.apache.spark.storage.StorageLevel 中的持久化级别;如有必要,可以通过在存储级别的末尾加上“_2”来把持久化数据存为两份

// 在Scala中使用persist()
val conf = new SparkConf().setAppName("wordcount").setMaster("local")
val sc = new SparkContext(conf)
val input = sc.parallelize(List(1,2,3,4))
val result = input.map(x=>x*x)
result.persist(StorageLevel.DISK_ONLY)
println(result.count()) // 输出 4
println(result.collect().mkString(",")) // 输出1,4,9,16
我们在第一次对这个 RDD 调用行动操作前就调用了 persist() 方法。 persist() 调用本身不会触发强制求值。
如果要缓存的数据太多,内存中放不下,Spark 会自动利用最近最少使用(LRU)的缓存策略把最老的分区从内存中移除。对于仅把数据存放在内存中的缓存级别,下一次要用到已经被移除的分区时,这些分区就需要重新计算。但是对于使用内存与磁盘的缓存级别的
分区来说,被移除的分区都会写入磁盘。不论哪一种情况,都不必担心你的作业因为缓存了太多数据而被打断。不过,缓存不必要的数据会导致有用的数据被移出内存,带来更多重算的时间开销。
最后,RDD 还有一个方法叫作 unpersist() ,调用该方法可以手动把持久化的 RDD 从缓存中移除。
这篇博文主要来自《Spark快速大数据分析》这本书里面的第三章,内容有删减,还有本书的一些代码的实验结果。
Spark学习之RDD编程总结的更多相关文章
- Spark学习之RDD编程(2)
Spark学习之RDD编程(2) 1. Spark中的RDD是一个不可变的分布式对象集合. 2. 在Spark中数据的操作不外乎创建RDD.转化已有的RDD以及调用RDD操作进行求值. 3. 创建RD ...
- Spark学习笔记——RDD编程
1.RDD——弹性分布式数据集(Resilient Distributed Dataset) RDD是一个分布式的元素集合,在Spark中,对数据的操作就是创建RDD.转换已有的RDD和调用RDD操作 ...
- Spark学习(2) RDD编程
什么是RDD RDD(Resilient Distributed Dataset)叫做分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.弹性.里面的元素可并行计算的集合 RDD允 ...
- 02、体验Spark shell下RDD编程
02.体验Spark shell下RDD编程 1.Spark RDD介绍 RDD是Resilient Distributed Dataset,中文翻译是弹性分布式数据集.该类是Spark是核心类成员之 ...
- Spark学习之RDD
RDD概述 什么是RDD RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可并行计算的集合 ...
- spark实验(四)--RDD编程(1)
一.实验目的 (1)熟悉 Spark 的 RDD 基本操作及键值对操作: (2)熟悉使用 RDD 编程解决实际具体问题的方法. 二.实验平台 操作系统:centos6.4 Spark 版本:1.5.0 ...
- Spark学习摘记 —— RDD行动操作API归纳
本文参考 参考<Spark快速大数据分析>动物书中的第三章"RDD编程",前一篇文章已经概述了转化操作相关的API,本文再介绍行动操作API 和转化操作API不同的是, ...
- spark 中的RDD编程 -以下基于Java api
1.RDD介绍: RDD,弹性分布式数据集,即分布式的元素集合.在spark中,对所有数据的操作不外乎是创建RDD.转化已有的RDD以及调用RDD操作进行求值.在这一切的背后,Spark会自动 ...
- spark学习(10)-RDD的介绍和常用算子
RDD(弹性分布式数据集,里面并不存储真正要计算的数据,你对RDD的操作,他会在Driver端转换成Task,下发到Executor计算分散在多台集群上的数据) RDD是一个代理,你对代理进行操作,他 ...
随机推荐
- Android的颜色值转换
Android的颜色int值比较变态,是个负值,用计算机术语讲叫补码,手工转换比较麻烦,首先看看文档 https://developer.android.com/reference/android/g ...
- 技术人应该学习的行话--UML统一建模语言
新生代码农如何在硝烟弥漫的商业丛林中生存和崛起? 洞见,让一部分先遇见未来. 最近公司技术部在组织架构师培训,有幸参与.导师老刘特别推荐了UML语言的学习.回想多年来,自己习惯做一些流程图,框图或者所 ...
- C++中遍历读取数组中的元素
答案来源:https://zhidao.baidu.com/question/187071815.html 对于字符数组str[N],判断方法有以下三种: 第一种:用库函数strlen 1 len = ...
- mysql 基本命令操作
1. 查看存储引擎 show engines; 2. 查看数据存储位置 show variables like 'datadir': 3. 存储引擎 create table mytest engin ...
- javascript 易漏点
javascript 是一种解释型语言,不是java或c++那样的编译语言.javascript指令以普通文本形式传递给浏览器,然后依次解释执行.它们不必首先“编译”成只有计算机处理器能理解的机器码. ...
- MySQL常见备份方案
MySQL常见备份方案有以下三种: mysqldump + binlog lvm + binlog xtrabackup 本例为方便演示,数据库里面数据为空.下面开始动手 mkdir /opt/bac ...
- 浅谈java中的"=="和eqals区别
在初学Java时,可能会经常碰到下面的代码: 1 String str1 = new String("hello"); 2 String str2 = new String(&qu ...
- Struts2中数据封装方式
一.通过ActionContext类获取 public class ActionContextDemo extends ActionSupport { @Override public S ...
- BigDecimal.setScale 处理java小数点
BigDecimal.setScale()方法用于格式化小数点setScale(1)表示保留一位小数,默认用四舍五入方式 setScale(1,BigDecimal.ROUND_DOWN)直接删除多余 ...
- C++的反思[转]
最近两年 C++又有很多人出来追捧,并且追捧者充满了各种优越感,似乎不写 C++你就一辈子是低端程序员了,面对这种现象,要不要出来适时的黑一下 C++呢?呵呵呵. 咱们要有点娱乐精神,关于 C++的笑 ...