从有值的ID到汉字编码
前些日子漫无目的地刷着朋友圈,突然一个ID从字丛中闯入我的眼睛——"某&字"(为保护当事人隐私,此处用'某''字'代替),浸淫于计算机而产生的直觉告诉我,这是一个有值的表达式,这位姑娘用这个表达式当ID,那她这ID的值,到底是啥呢?
一、计算机存储汉字的方法——汉字编码
话说在计算机中,姑娘们的照片和她们的ID本质上都一样,都是冷冰冰的二进制0和1。既然都是一个bit,那就有了位操作求值的——咳咳——"科学依据"。
与和英文打字键盘完全兼容的拉丁字母不同,输入汉字便成了人们必须研究的课题。从近40年前的GB2312,到扩展后的GBK标准,再到全球化的Unicode,后来又出现了Unicode的Plus版本——UTF标准。
好了,说完汉字编码的历史,我们回到计算机中。当初推出GB2312时,为了不和原有的ascii码混肴,智慧的中国人规定,当两个值都大于127的字节连在一起的时候,就表示一个汉字,前面的字节称为高字节(0xA1-0xf7),后面的字节称为低字节(0xA1-0xFE)。但后来人们发现GB2312里的汉字不够用,于是干脆降低要求,不在规定低字节一定得是大于127的值,这样,拓展的GBK诞生了,再之后又经拓展,就成了人们口中的"DBCS"(Double Byte Charecter Set 双字节字符集)。在这个标准中,程序员必须注意每一个字节的值,如果大于127,那么就有一个汉字要出现了。
而目前使用最广的UTF-8作为一种变长的编码方式,可根据不同的符号变化字节长度(1-4个字节)。在GB2312中,一个汉字为两个字节,而在UTF-8中,一个汉字为3个字节。
二、简单版本
百度得到dev-cpp的字符编码为GB-2312(此处大雾,后文会详细解释),所以一个汉字占两个字符。
因为涉及位操作,所以新建一个union结构nameBit,一个nameBit占2*16位,也就是4个字节。
- union nameBit{
- short short1[2];
- struct {
- char c0;
- char c1;
- char c2;
- char c3;
- }byte;
- };
这个结构存储了两个汉字的GB-2312编码,分别用一个short表示,byte和short共享内存,所以c0,c1用于存储第一个汉字,c2,c3存储第二个汉字的字符编码。
- /*
- 初级版本---
- */
- #include <stdio.h>
- union nameBit{
- short short1[2];
- struct {
- char c0;
- char c1;
- char c2;
- char c3;
- }byte;
- };
- int main (void)
- {
- union nameBit value1;
- char arr[5];
- printf("请输入两个汉字,中间无需空格隔开:\n");
- fgets(arr,5,stdin);
- for(int i = 0;i<4;i++)
- {
- char *p = &value1.byte.c0 + i;
- *p = arr[i];
- }
- printf("%c%c & %c%c = ",value1.byte.c0,value1.byte.c1,value1.byte.c2,value1.byte.c3);
- value1.short1[0] = value1.short1[0] & value1.short1[1];
- printf("%c%c",value1.byte.c0,value1.byte.c1);
- return 0;
- }
把输入存到一个字符串中,在一字节一字节的复制到union。
输入示例"啊哈":
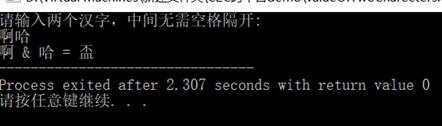
'啊'的GB2312编码为B0A1,'哈'的GB2312编码为B9FE,所以B0A1 & B9FE的结果为B0A0,查GB2312编码表发现这个编码并没有值,而拓展的GBK编码中B0A0对应为'盃'(同'杯')。
所以可知,该程序运行时遵循的编码方式为GBK。
三、移植到Linux后出现的种种问题
将该.c文件直接移至虚拟机的共享文件夹后,在Linux中运行此程序,出现如下情况:
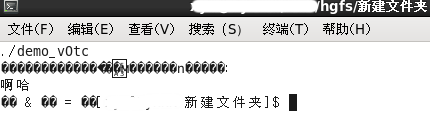
将终端的字符编码改为GBK后,再次执行。
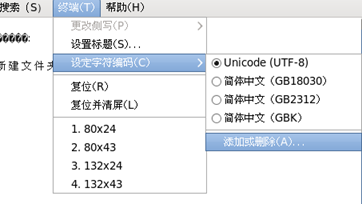
文件内字符正常显示,但是终端上的汉字出现乱码。
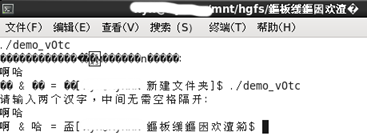
怀疑是源代码文件和终端上的编码不同,用file命令查看.c编码
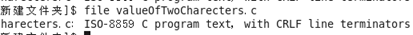
再用strace命令查看细节,发现

其中,/345/225/212转换成16进制就是 E5 95 8A,/345/223/210就是E5 93 88,这正是"啊哈"这两个字的UTF-8编码。所以情况就很明显了,源代码用的dev-cpp的编辑器,保存为ANSI(GB2312),将文件移至Linux,编译运行后,终端和程序的编码不同,导致输出出现乱码,程序运行时,用的又是UTF-8编码一个汉字占三个字节
所以这个程序需要重构。
四、更新的版本
因为在Windows和Linux中运行时所用的编码不同,所以直接用一个10个字节的数组来存储编码。
又由于需要在两个平台运行,所以需要有一定的移植性。这个可以用__linux__和_WIN32两个宏来区分。
- #if _WIN32
- //windows
- #elif __linux__
- //Linux
- #else
- //other
- #endif
最终版本如下:
- #include <stdio.h>
- #define Win_N 2
- #define Linux_N 3
- int main (void)
- {
- char arr[10];
- printf("Please input two Chinese charecters:");
- printf("(请输入两个汉字)\n");
- fgets(arr,10,stdin);
- #if _WIN32
- printf("%c%c & %c%c = ",arr[0],arr[1],arr[2],arr[3]);
- for(int i = 0;i<Win_N;i++)
- arr[i] = arr[i]&arr[i+Win_N];
- printf("%c%c\n",arr[0],arr[1]);
- #elif __linux__
- printf("%c%c%c & %c%c%c = ",arr[0],arr[1],arr[2],arr[3],arr[4],arr[5]);
- for(int i = 0;i<Linux_N;i++)
- arr[i] = arr[i]&arr[i+Linux_N];
- printf("%c%c%c\n",arr[0],arr[1],arr[2]);
- #else
- printf("Errors that occur when selecting an operating system\n");
- #endif
- return 0;
- }
为了防止第十行的汉字在Linux中出现乱码,把该.c文件用Notepad++打开,转为UTF-8格式。
之后再在Linux中运行,先测试一下。
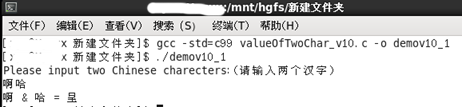
'啊'的UTF-8编码为E5 95 8A ,'哈'为E5 93 88 ,E5 95 8A & E5 93 88 = E591 88, 正好是'呈'的UTF-8编码。
五、乱码的根源(注①)
1、源码字符集,执行字符集与运行环境编码
源码字符集:英文the source character set,是指源代码文件是使用何种编码字符集保存的。
执行字符集:英文the execution character set,是指源代码经过编译、链接后的可执行文件是使用何种编码字符集保存的,程序实际执行时,内存中的字符串编码就是执行字符集。
运行环境编码:是指操作系统(或者当前控制台环境)用于显示文字的编码字符集。
2、乱码的根源
源代码文件(源码字符集)经过编译/链接,生成可执行文件(执行字符集),最后程序运行于实际环境中(运行环境编码)。
在这过程中如果有字符集不匹配,最终就无法显示预期的文字信息,甚至产生乱码。
编译器在编译源代码时,会将源码字符集转化为执行字符集,如果编译器不能正确识别源码字符集,就得不到正确的字符串数据。
可执行文件在实际运行环境中执行时,为了在控制台(或者其他UI)上显示出字符串,就要将执行字符集转化为运行环境的字符集。如果运行环境的字符集与执行字符集不同,也会导致乱码。
3、编译器层面的字符转码工作
GCC:GCC的源码字符集与执行字符集默认都是UTF-8编码,也就是说默认情况下GCC都是按UTF-8来解析源码,编译后的执行字符集也是UTF-8。
、识别源码字符集:源码文件有BOM签名的,就按BOM的编码来解析源文件;否则使用本地Locale字符集解析源文件(随系统设置而变)。
2、转化执行字符集:对于char类型,如果有设置预处理选项"#pragma execution_character_set",编译源码时,转换为预编译所设定的执行字符集;
否则使用本地Locale作为执行字符集。对于wchar_t类型,总是使用UTF-16编码。
六、结语及声明
回到开头的那个话题,朋友圈的那个表达式ID在我电脑的两个系统中有两个值,分别对应于GB2312及UTF-8下的编码,所以输入姑娘的ID,得到了两个截然不同的值(笑)。


这个结果仅供娱乐,没有任何意义,这只是偶尔的心血来潮,庸常生活里的一点趣味。
在即将结束这篇博文的这个时候,浏览器里仍然还有十几个与字符编码有关的网页,我也仅仅是掌握了一些皮毛,却已获益匪浅。拙作初成,还请多多指教。
声明:
1、引用,即"注①"
内容来源于博文浅谈C/C++编程中的字符编码转换——许振坪
2、除上文引用外,一些有干货的文章
字符集编码与 C/C++ 源文件字符编译乱弹——Breaker
从有值的ID到汉字编码的更多相关文章
- Jmeter 通过json Extracted 来获取 指定的值的id
在没有 精确或模糊查询的接口时可以使用jmeter 获取指定的值的ID import java.lang.String ; String getTargetName="iphone632g& ...
- name值与id值在Js获取元素时的区别
1.适用范围 除base.head.html.script.meta.title标签外,id都可以用:name只适用于select.form.frame.iframe.img.a.input等中. H ...
- Mysql 查询表中某字段的重复值,删除重复值保留id最小的数据
1 查询重复值 ); 2 删除重复值 -- 创建临时表 ) ); -- 把重复数据放进临时表 INSERT Hb_Student_a SELECT id,studentNumber FROM Hb_S ...
- 【JS】js获得下拉列表选中项的值和id
function tijiao(){ var elem = document.getElementById("dish_sort"); var index=elem.selecte ...
- ID属性值为小数
获取带有.的id值 <h1 id="123.45">dom对象</h1> <script> $('#123\\.45').attr('id') ...
- HTML控件ID和NAME属性及在CS页面获得.ASPX页面中HTML控件的值
<转载>来自网络 一.ID是在客户端脚本里用!NAME是用于获取提交表单的某表单域信息,在form里面,如果不指定Name的话,就不会发送到服务器端,所以有name属性的控件,必须指定na ...
- HTML控件ID和NAME属性的区别,以及如何在asp.net页面的.CS文件中获得.ASPX页面中HTML控件的值
在html中:name指的是用户名称,ID指的是用户注册是系统自动分配给用户的一个序列号. name是用来提交数据的,提供给表单用,可以重复: id则针对文档操作时候用,不能重复.如:document ...
- SSM获取表单数据插入数据库并返回插入记录的ID值
以下指示插入操作以及获取记录值的ID的部分操作代码!!! 首先是简单的表单实现 <%@ page language="java" contentType="text ...
- Vue 2.0 v-for 响应式key, index及item.id参数对v-bind:key值造成差异研究
Vue 2.0 v-for 响应式key, index及item.id参数对v-bind:key值造成差异研究 在github上阅览README.md以获得最佳阅读体验,点这里 v-for响应式key ...
随机推荐
- Volley网络框架完全解析(使用篇)
在Android中,网络请求无非就这两种:HttpURLConnection和HttpClient( Apache),我们在使用时一般都会对它们进行一系列的封装,但是这过程不免有些繁琐,所以,Goog ...
- 调用start()方法和直接调用run()方法的区别
调用start()方法和直接调用run()方法的区别 新建一个线程,只需要使用new关键字创建一个线程对象,并且调用start()方法即可. Thread thread = new Thread(); ...
- libcoro:在c++中支持coroutine
起因 在第一个版本的libtnet开发完成之后,我一直在思考如何让异步方式的网络编程更加简单. 虽然libtnet通过c++ shared_ptr以及function等技术很大程度上面解决了异步代码编 ...
- 基于FT5x06嵌入式Linux电容触摸屏驱动
**************************************************************************************************** ...
- Linux下top命令详解
Linux下top命令详解 top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器.top是一个动态显示过程,即可以通过用户按键来不断刷 ...
- Java-ServletResponse-ServletResponseWrapper
/** * Defines an object to assist a servlet in sending a response to the client. * The servlet conta ...
- 【LaTeX排版】LaTeX使用--入门基础<一>
经过两个多星期,毕业论文终于写完了.由于自己对Word软件并不是很熟悉,再加上在数模时见识过LaTex的强大之处,于是就决定用LaTex进行论文的排版.使用LaTex可以避免像Word那样换台机器而出 ...
- Struts2技术内幕 读书笔记三 表示层的困惑
表示层能有什么疑惑?很简单,我们暂时忘记所有的框架,就写一个注册的servlet来看看. index.jsp <form id="form1" name="form ...
- 芯片SIAT-002测试PCB板设计
这个板子,从原理图到PCB板,总共画了6天,接近一个星期!虽然说各种麻烦,但总算学到了一些新知识.谨记以备后查. 附注: 模拟地与数字地详解 单片机晶振电路 1. 走线规划 针对采用BGA封装及引脚数 ...
- Android开发技巧——自定义单选或多选的ListView
这篇其实应该是属于写自定义单选或多选的ListView的基础教程,无奈目前许多人对此的实现大多都绕了远路,反而使得这正规的写法倒显得有些技巧性了. 本文原创,转载请注明在CSDN上的出处: http: ...