Spark-1(概念)
1. 什么是Spark?
Apache Spark™是用于大规模数据处理的统一分析引擎。
spark是一个实现快速通用的集群计算平台。它是由加州大学伯克利分校AMP实验室开发的通用内存并行计算框架,用来构建大型的、低延迟的数据分析应用程序。它扩展了广泛使用的MapReduce计算模型。高效的支撑更多计算模式,包括交互式查询和流处理。spark的一个主要特点是能够在内存中进行计算,即使依赖磁盘进行复杂的运算,Spark依然比MapReduce更加高效。
Spark是MapReduce的替代方案,而且兼容HDFS、Hive,可融入Hadoop的生态系统,以弥补MapReduce的不足。
相对MapReduce,Spark具有如下优势:
- MapReduce通常将中间结果放到HDFS上,Spark是基于内存并行大数据框架,中间结果存放到内存,对于迭代数据Spark效率高。
- MapReduce总是消耗大量时间排序,而有些场景不需要排序,Spark可以避免不必要的排序带来的开销。
- Spark 是一张有向无环图(从一个点出发最终无法回到该点的一个拓扑),并对其进行优化。
与 Hadoop 对比,如何看待 Spark 技术?
2. Spark的四大特性
- 高效性:运行速度提高100倍。Apache Spark使用最先进的DAG调度程序,查询优化程序和物理执行引擎,实现批量和流式数据的高性能。
易用性:Spark支持Java、Python和Scala的API,还支持超过80种高级算法,使用户可以快速构建不同的应用。而且Spark支持交互式的Python和Scala的shell,可以非常方便地在这些shell中使用Spark集群来验证解决问题的方法。
通用性:Spark提供了统一的解决方案。Spark可以用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。这些不同类型的处理都可以在同一个应用中无缝使用。Spark统一的解决方案非常具有吸引力,毕竟任何公司都想用统一的平台去处理遇到的问题,减少开发和维护的人力成本和部署平台的物力成本。
兼容性:
Spark可以非常方便地与其他的开源产品进行融合。比如,Spark可以使用Hadoop的YARN和Apache Mesos作为它的资源管理和调度器,并且可以处理所有Hadoop支持的数据,包括HDFS、HBase和Cassandra等。这对于已经部署Hadoop集群的用户特别重要,因为不需要做任何数据迁移就可以使用Spark的强大处理能力。Spark也可以不依赖于第三方的资源管理和调度器,它实现了Standalone作为其内置的资源管理和调度框架,这样进一步降低了Spark的使用门槛,使得所有人都可以非常容易地部署和使用Spark。此外,Spark还提供了在EC2上部署Standalone的Spark集群的工具。
Mesos:Spark可以运行在Mesos里面(Mesos 类似于yarn的一个资源调度框架)
standalone:Spark自己可以给自己分配资源(master,worker)
YARN:Spark可以运行在yarn上面
Kubernetes:Spark接收 Kubernetes的资源调度
3. Spark的架构及生态

- SparkCore:将分布式数据抽象为弹性分布式数据集(RDD),实现了应用任务调度、RPC、序列化和压缩,并为运行在其上的上层组件提供API。负责从HDFS、Amazon S3和HBase等持久层读取数据;在YARN和Standalone等为资源管理器中调度Job完成分布式计算;
包括两个重要部件:有向无环图(DAG)的分布式并行计算框架;弹性分布式数据集RDD (Resilient Distributed Dataset);
- SparkSQL:Spark Sql 是Spark来操作结构化数据的程序包,可以让我使用SQL语句的方式来查询数据,Spark支持多种数据源,包含Hive表,parquets以及JSON等内容。
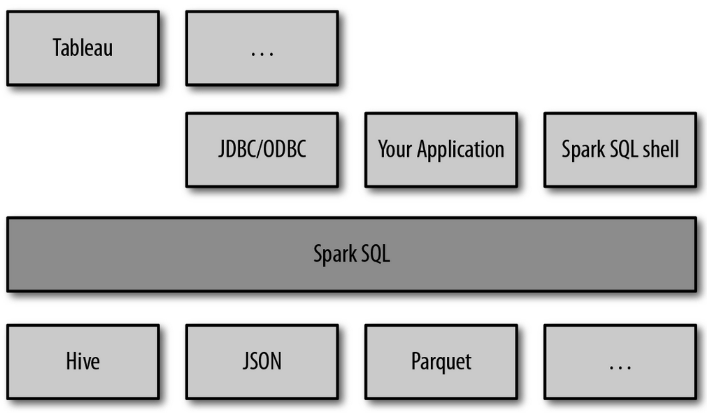
- SparkStreaming: 是Spark提供的实时数据进行流式计算的组件。
- MLlib:提供常用机器学习算法的实现库。
- GraphX:提供一个分布式图计算框架,能高效进行图计算。
- Cluster Managers:Spark 中用来管理机群或节点的软件平台.这包括Hadoop YARN, Apache Mesos,和 Standalone Scheduler (Spark 自带的用于单机系统)等。
BlinkDB:用于在海量数据上进行交互式SQL的近似查询引擎。
Tachyon:以内存为中心高容错的的分布式文件系统。
4. 应用场景
Yahoo将Spark用在Audience Expansion中的应用,进行点击预测和即席查询等
淘宝技术团队使用了Spark来解决多次迭代的机器学习算法、高计算复杂度的算法等。应用于内容推荐、社区发现等
腾讯大数据精准推荐借助Spark快速迭代的优势,实现了在“数据实时采集、算法实时训练、系统实时预测”的全流程实时并行高维算法,最终成功应用于广点通pCTR投放系统上。
优酷土豆将Spark应用于视频推荐(图计算)、广告业务,主要实现机器学习、图计算等迭代计算。
5. Spark架构组成
如下图所示,Spark运行架构包括集群资源管理器(Cluster Manager)、运行作业任务的工作节点(Worker Node)、每个应用的任务控制节点(Driver)和每个工作节点上负责具体任务的执行进程(Executor)。其中,集群资源管理器可以是Spark自带的资源管理器,也可以是YARN或Mesos等资源管理框架。
与Hadoop MapReduce计算框架相比,Spark所采用的Executor有两个优点:一是利用多线程来执行具体的任务(Hadoop MapReduce采用的是进程模型),减少任务的启动开销;二是Executor中有一个BlockManager存储模块,会将内存和磁盘共同作为存储设备,当需要多轮迭代计算时,可以将中间结果存储到这个存储模块里,下次需要时,就可以直接读该存储模块里的数据,而不需要读写到HDFS等文件系统里,因而有效减少了IO开销;或者在交互式查询场景下,预先将表缓存到该存储系统上,从而可以提高读写IO性能。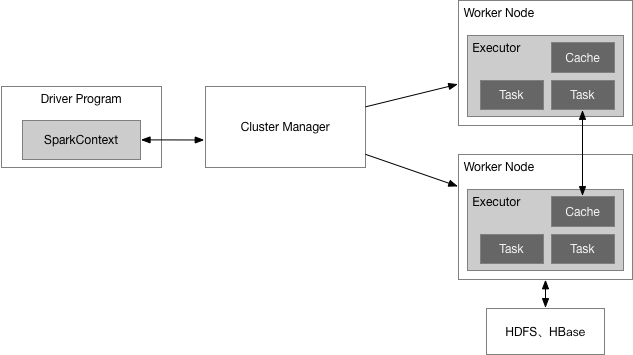
6. Spark基本概念
- Application:用户编写的Spark应用程序,包括一个Driver功能的代码和分布在集群中多个节点上运行的Executor代码;
- Driver:Spark中的Driver即运行上述Application的main函数并创建SparkContext,创建SparkContext的目的是为了准备Spark应用程序的运行环境,在Spark中由SparkContext负责与ClusterManager通信,进行资源申请、任务的分配和监控等,当Executor部分运行完毕后,Driver同时负责将SparkContext关闭,通常用SparkContext代表Driver;
- Executor: 某个Application运行在worker节点上的一个进程,该进程负责运行某些Task, 并且负责将数据存到内存或磁盘上,每个Application都有各自独立的一批Executor, 在Spark on Yarn模式下,其进程名称为CoarseGrainedExecutor Backend。一个CoarseGrainedExecutor Backend有且仅有一个Executor对象, 负责将Task包装成taskRunner,并从线程池中抽取一个空闲线程运行Task, 这个每一个CoarseGrainedExecutor Backend能并行运行Task的数量取决与分配给它的cpu个数;
Cluter Manager:指的是在集群上获取资源的外部服务。目前有三种类型:
Standalone:spark原生的资源管理,由Master负责资源的分配;
Apache Mesos:与hadoop MR兼容性良好的一种资源调度框架;
Hadoop Yarn:主要是指Yarn中的ResourceManager;
- Worker: 集群中任何可以运行Application代码的节点,在Standalone模式中指的是通过slave文件配置的Worker节点,在Spark on Yarn模式下就是NoteManager节点;
- Task:被送到某个Executor上的工作单元,与hadoopMR中的MapTask和ReduceTask概念一样,是运行Application的基本单位,多个Task组成一个Stage,而Task的调度和管理等是由TaskScheduler负责;
- Job:包含多个Task组成的并行计算,往往由Spark Action触发生成, 一个Application中往往会产生多个Job;
- Stage:每个Job会被拆分成多组Task,作为一个TaskSet,其名称为Stage,Stage的划分和调度是由DAGScheduler来负责的,Stage有非最终的Stage(Shuffle Map Stage)和最终的Stage(Result Stage)两种,Stage的边界就是发生shuffle的地方;
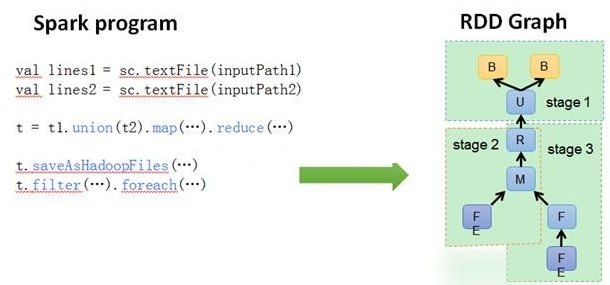
- DAGScheduler:根据Job构建基于Stage的DAG(Directed Acyclic Graph有向无环图),并提交Stage给TASKScheduler。 其划分Stage的依据是RDD之间的依赖的关系找出开销最小的调度方法,如下图;
- TASKScheduler:将TaskSET提交给worker运行,每个Executor运行什么Task就是在此处分配的。TaskScheduler维护所有TaskSet,当Executor向Driver发生心跳时,TaskScheduler会根据资源剩余情况分配相应的Task。另外TaskScheduler还维护着所有Task的运行标签,重试失败的Task。下图展示了TASKScheduler的作用。
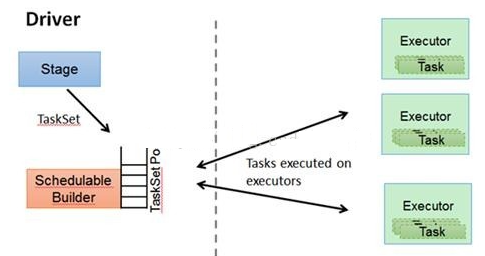
- 在不同运行模式中任务调度器具体为:Spark on Standalone模式为TaskScheduler;YARN-Client模式为YarnClientClusterScheduler;YARN-Cluster模式为YarnClusterScheduler;
- RDD:是弹性分布式数据集(Resilient Distributed Dataset)的简称,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型;
- 将这些术语串起来的运行层次图如下:
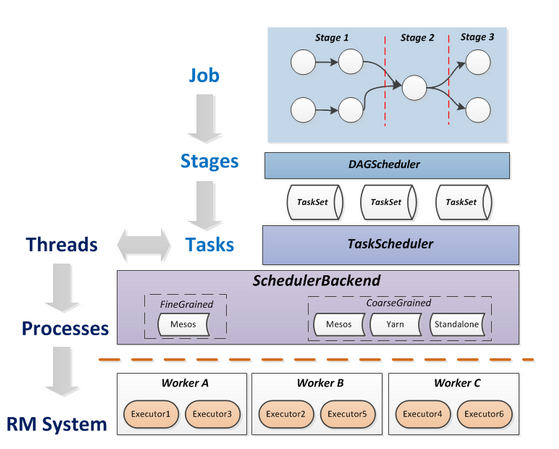
7. Spark运行流程
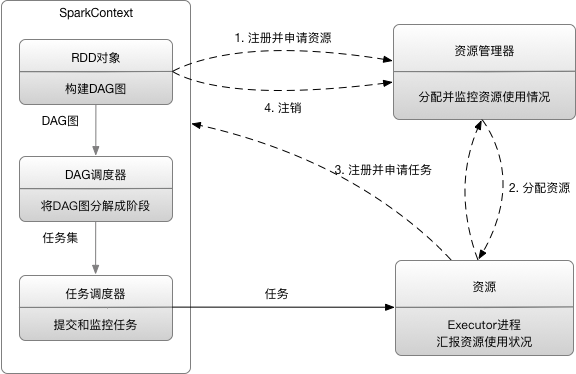
当一个Spark应用被提交时,首先需要为这个应用构建起基本的运行环境,即由任务控制节点(Driver)创建一个SparkContext,由SparkContext负责和资源管理器(Cluster Manager)的通信以及进行资源的申请、任务的分配和监控等。SparkContext会向资源管理器注册并申请运行Executor的资源;
资源管理器为Executor分配资源,并启动Executor进程,Executor运行情况将随着“心跳”发送到资源管理器上;
SparkContext根据RDD的依赖关系构建DAG图,DAG图提交给DAG调度器(DAGScheduler)进行解析,将DAG图分解成多个“阶段”(每个阶段都是一个任务集),并且计算出各个阶段之间的依赖关系,然后把一个个“任务集”提交给底层的任务调度器(TaskScheduler)进行处理;Executor向SparkContext申请任务,任务调度器将任务分发给Executor运行,同时,SparkContext将应用程序代码发放给Executor;
任务在Executor上运行,把执行结果反馈给任务调度器,然后反馈给DAG调度器,运行完毕后写入数据并释放所有资源;
Spark运行特点
- 每个Application获取专属的executor进程,该进程在Application期间一直驻留,并以多线程方式运行Task。这种Application隔离机制是有优势的,无论是从调度角度看(每个Driver调度他自己的任务),还是从运行角度看(来自不同Application的Task运行在不同JVM中),当然这样意味着Spark Application不能跨应用程序共享数据,除非将数据写入外部存储系统;
- Spark与资源管理器无关,只要能够获取executor进程,并能保持相互通信就可以了;
- 提交SparkContext的Client应该靠近Worker节点(运行Executor的节点),最好是在同一个Rack里,因为Spark Application运行过程中SparkContext和Executor之间有大量的信息交换;
- Task采用了数据本地性和推测执行的优化机制;
8. Spark运行模式
Local模式
该模式被称为Local[N]模式,是用单机的多个线程来模拟Spark分布式计算,通常用来验证开发出来的应用程序逻辑上有没有问题。
其中N代表可以使用N个线程,每个线程拥有一个core。如果不指定N,则默认是1个线程(该线程有1个core)。
Spark运行模式(一)-----Spark独立模式
Spark On Yarn模式
Yarn框架流程
Yarn框架的基本流程如下:
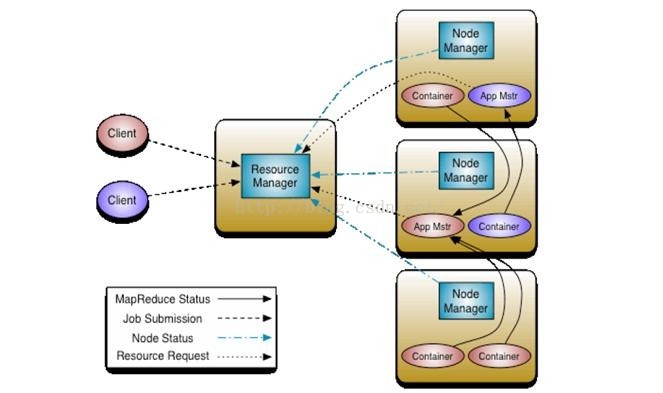
其中,ResourceManager负责将集群的资源分配给各个应用使用,而资源分配和调度的基本单位是Container,其中封装了机器资源,如内存、CPU、磁盘和网络等,每个任务会被分配一个Container,该任务只能在该Container中执行,并使用该Container封装的资源。NodeManager是一个个的计算节点,主要负责启动Application所需的Container,监控资源(内存、CPU、磁盘和网络等)的使用情况并将之汇报给ResourceManager。ResourceManager与NodeManagers共同组成整个数据计算框架,ApplicationMaster与具体的Application相关,主要负责同ResourceManager协商以获取合适的Container,并跟踪这些Container的状态和监控其进度。
Spark on Yarn
在Spark中,根据Driver在集群中的位置分为两种模式,即Yarn-Client和Yarn-Cluster可以运行在Yarn上,通常Yarn-Cluster适用于生产环境,而Yarn-Client更适用于交互,调试模式。
优势
- Spark支持资源动态共享,运行于Yarn的框架都共享一个集中配置好的资源池
- 可以很方便的利用Yarn的资源调度特性来做分类·,隔离以及优先级控制负载,拥有更灵活的调度策略
- Yarn可以自由地选择executor数量
- Yarn是唯一支持Spark安全的集群管理器,使用Yarn,Spark可以运行于Kerberized Hadoop之上,在它们进程之间进行安全认证
此模式分为yarn-client和yarn-cluster
YARN-Cluster
在YARN-Cluster模式中,当用户向YARN中提交一个应用程序后,YARN将分两个阶段运行该应用程序:
- 第一个阶段是把Spark的Driver作为一个ApplicationMaster在YARN集群中先启动;
- 第二个阶段是由ApplicationMaster创建应用程序,然后为它向ResourceManager申请资源,并启动Executor来运行Task,同时监控它的整个运行过程,直到运行完成;
其工作流程如下图所示:

Yarn-cluster模式下作业执行流程:
Spark Yarn Client向YARN中提交应用程序,包括ApplicationMaster程序、启动ApplicationMaster的命令、需要在Executor中运行的程序等;
ResourceManager收到请求后,在集群中选择一个NodeManager,为该应用程序分配第一个Container,要求它在这个Container中启动应用程序的ApplicationMaster,其中ApplicationMaster进行SparkContext等的初始化
ApplicationMaster向ResourceManager注册,这样用户可以直接通过ResourceManager查看应用程序的运行状态,然后它将采用轮询的方式通过RPC协议为各个任务申请资源,并监控它们的运行状态直到运行结束;
一旦ApplicationMaster申请到资源(也就是Container)后,便与对应的NodeManager通信,要求它在获得的Container中启动启动CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend启动后会向ApplicationMaster中的SparkContext注册并申请Task。这一点和Standalone模式一样,只不过SparkContext在Spark Application中初始化时,使用CoarseGrainedSchedulerBackend配合YarnClusterScheduler进行任务的调度,其中YarnClusterScheduler只是对TaskSchedulerImpl的一个简单包装,增加了对Executor的等待逻辑等;
ApplicationMaster中的SparkContext分配Task给CoarseGrainedExecutorBackend执行,CoarseGrainedExecutorBackend运行Task并向ApplicationMaster汇报运行的状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务;
应用程序运行完成后,ApplicationMaster向ResourceManager申请注销并关闭自己。
Yarn-Client
Yarn-Client模式中,Driver在客户端本地运行,这种模式可以使得Spark Application和客户端进行交互,因为Driver在客户端,所以可以通过webUI访问Driver的状态,默认是http://hadoop1:4040访问,而YARN通过http:// hadoop1:8088访问。
如下图所示:
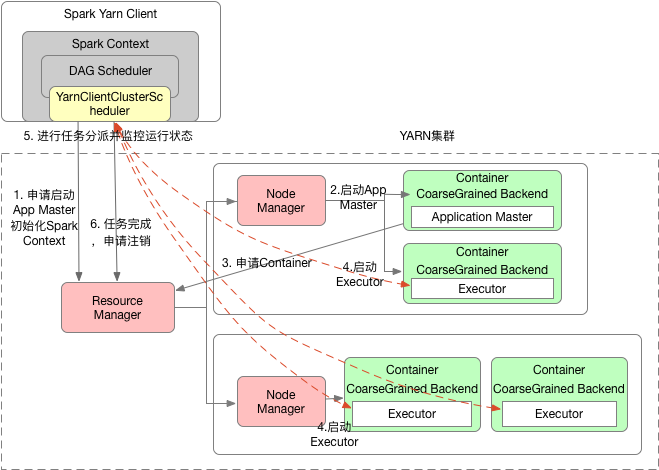
Yarn-client模式下作业执行流程:
- Spark Yarn Client向YARN的ResourceManager申请启动Application Master。同时在SparkContext初始化中将创建DAGScheduler和TASKScheduler等,由于我们选择的是Yarn-Client模式,程序会选择YarnClientClusterScheduler和YarnClientSchedulerBackend;
- ResourceManager收到请求后,在集群中选择一个NodeManager,为该应用程序分配第一个Container,要求它在这个Container中启动应用程序的ApplicationMaster,与YARN-Cluster区别的是在该ApplicationMaster不运行SparkContext,只与SparkContext进行联系进行资源的分派;
- Client中的SparkContext初始化完毕后,与ApplicationMaster建立通讯,向ResourceManager注册,根据任务信息向ResourceManager申请资源(Container);
- 一旦ApplicationMaster申请到资源(也就是Container)后,便与对应的NodeManager通信,要求它在获得的Container中启动CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend启动后会向Client中的SparkContext注册并申请Task;
- client中的SparkContext分配Task给CoarseGrainedExecutorBackend执行,CoarseGrainedExecutorBackend运行Task并向Driver汇报运行的状态和进度,以让Client随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务;
- 应用程序运行完成后,Client的SparkContext向ResourceManager申请注销并关闭自己;
Spark Client与Spark Cluster的区别
理解YARN-Client和YARN-Cluster深层次的区别之前先清楚一个概念:Application Master。在YARN中,每个Application实例都有一个ApplicationMaster进程,它是Application启动的第一个容器。它负责和ResourceManager打交道并请求资源,获取资源之后告诉NodeManager为其启动Container。从深层次的含义讲YARN-Cluster和YARN-Client模式的区别其实就是ApplicationMaster进程的区别。
- YARN-Cluster模式下,Driver运行在AM(Application Master)中,它负责向YARN申请资源,并监督作业的运行状况。当用户提交了作业之后,就可以关掉Client,作业会继续在YARN上运行,因而YARN-Cluster模式不适合运行交互类型的作业;
- YARN-Client模式下,Application Master仅仅向YARN请求Executor,Client会和请求的Container通信来调度他们工作,也就是说Client不能离开。
Standalone模式
独立集群运行模式。Standalone模式使用Spark自带的资源调度框架;采用Master/Slaves的典型架构,选用ZooKeeper来实现Master的HA;其框架结构如下图:

该模式主要的节点有Client节点、Master节点和Worker节点。其中Driver既可以运行在Master节点上中,也可以运行在本地Client端。当用spark-shell交互式工具提交Spark的Job时,Driver在Master节点上运行;当使用spark-submit工具提交Job或者在Eclips、IDEA等开发平台上使用”new SparkConf.setManager(“spark://master:7077”)”方式运行Spark任务时,Driver是运行在本地Client端上的。
其运行过程如下图:
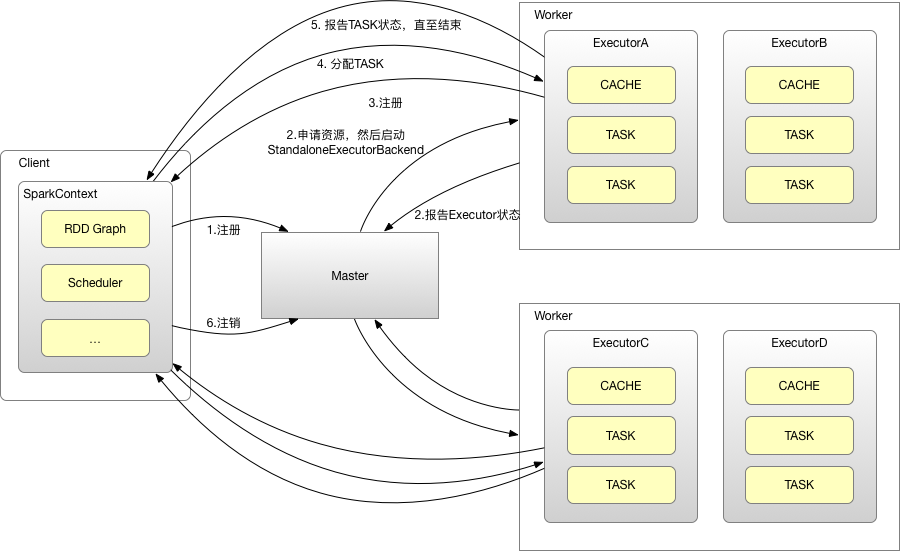
- SparkContext连接到Master,向Master注册并申请资源(CPU Core 和Memory);
- Master根据SparkContext的资源申请要求和Worker心跳周期内报告的信息决定在哪个Worker上分配资源,然后在该Worker上获取资源,然后启动StandaloneExecutorBackend;
- StandaloneExecutorBackend向SparkContext注册;
- SparkContext将Applicaiton代码发送给StandaloneExecutorBackend;并且SparkContext解析Applicaiton代码,构建DAG图,并提交给DAG Scheduler分解成Stage(当碰到Action操作时,就会催生Job;每个Job中含有1个或多个Stage,Stage一般在获取外部数据和shuffle之前产生),然后以Stage(或者称为TaskSet)提交给Task Scheduler,Task Scheduler负责将Task分配到相应的Worker,最后提交给StandaloneExecutorBackend执行;
- StandaloneExecutorBackend会建立Executor线程池,开始执行Task,并向SparkContext报告,直至Task完成;
- 所有Task完成后,SparkContext向Master注销,释放资源;
// saucxs let a = { name: "saucxs", book: { title: "You Don't Know JS", price: "45" } } let b = Object.assign({}, a); console.log(b); // { // name: "saucxs", // book: {title: "You Don't Know JS", price: "45"} // } a.name = "change"; a.book.price = "55"; console.log(a); // { // name: "change", // book: {title: "You Don't Know JS", price: "55"} // } console.log(b); // { // name: "saucxs", // book: {title: "You Don't Know JS", price: "55"} // }
上面代码改变对象 a 之后,对象 b 的基本属性保持不变。但是当改变对象 a 中的对象 `book` 时,对象 b 相应的位置也发生了变化。
2.2 展开语法 `Spread`
// saucxs let a = { name: "saucxs", book: { title: "You Don't Know JS", price: "45" } } let b = {...a}; console.log(b); // { // name: "saucxs", // book: {title: "You Don't Know JS", price: "45"} // } a.name = "change"; a.book.price = "55"; console.log(a); // { // name: "change", // book: {title: "You Don't Know JS", price: "55"} // } console.log(b); // { // name:www.tianscpt.com "saucxs", // book: {title: "You Don't Know JS", price: "55"} // }2.3 Array.prototype.slice方法
slice不会改变原数组,`slice()` 方法返回一个新的数组对象,这一对象是一个由 `begin`和 `end`(不包括`end`)决定的原数组的**浅拷贝**。
// saucxs let a = [0, "1", [2, 3]]; let b = a.slice(1); console.log(b); // ["1", [2, 3]] a[1] = "99"; a[2][0] = 4; console.log(a); // [0, "99", [4, 3]] console.log(b); // ["1", [4, 3]]可以看出,改变 `a[1]` 之后 `b[0]` 的值并没有发生变化,但改变 `a[2][0]` 之后,相应的 `b[1][0]` 的值也发生变化。
说明 `slice()` 方法是浅拷贝,相应的还有`concat`等,在工作中面对复杂数组结构要额外注意。
三、深拷贝(Deep Copy)
3.1 什么是深拷贝?
深拷贝会拷贝所有的属性,并拷贝属性指向的动态分配的内存。当对象和它所引用的对象一起拷贝时即发生深拷贝。深拷贝相比于浅拷贝速度较慢并且花销较大。拷贝前后两个对象互不影响。

3.2 使用深拷贝的场景
3.2.1 JSON.parse(JSON.stringify(object))
// saucxs let a = { name: "saucxs", book: { title: "You Don't Know JS", price: "45" } } let b = JSON.parse(JSON.stringify(a)); console.log(b); // { // name: "saucxs", // book: {title: "You Don't Know JS", price: "45"} // } a.name = "change"; a.book.price = "55"; console.log(a); // { // name: "change", // book: {title: "You Don't Know JS", price: "55"} // } console.log(b); // { // name: "saucxs", // book: {title: "You Don't Know JS", price: "45"} // }完全改变变量 a 之后对 b 没有任何影响,这就是深拷贝的魔力。
我们看下对数组深拷贝效果如何。
// saucxs let a = [0, "1", [2, 3]]; let b = JSON.parse(JSON.stringify(www.javachenglei.com/ a.slice(1) )); console.log(b); // ["1", [2, 3]] a[1] = "99"; a[2][0] = 4; console.log(a); // [0, "99", [4, 3]] console.log(b); // ["1", [2, 3]]对数组深拷贝之后,改变原数组不会影响到拷贝之后的数组。
但是该方法有以下几个问题:
(1)会忽略 `undefined`
(2)会忽略 `symbol`
(3)不能序列化函数
(4)不能解决循环引用的对象
(5)不能正确处理`new Date()`
(6)不能处理正则
其中(1)(2)(3) `undefined`、`symbol` 和函数这三种情况,会直接忽略。
// saucxs let obj = { name: 'saucxs', a: undefined, b: Symbol('saucxs'), c: function() {} } console.log(obj); // { // name:www.shenzhenztgs.com "saucxs", // a: undefined, // b: Symbol(saucxs), // c: ƒ () // } let b = JSON.parse(JSON.stringify(www.gracegift-a.com/ obj)); console.log(b); // {name: "saucxs"}其中(4)循环引用会报错
// saucxs let obj = { a: 1, b: { c: 2, d: 3 } } obj.a = obj.b; obj.b.c = obj.a; let b = JSON.parse(JSON.stringify(obj)); // Uncaught TypeError: Converting circular structure to JSON其中(5)* `new Date` 情况下,转换结果不正确。
// saucxs new Date(); // Mon Dec 24 2018 10:59:14 GMT+0800 (China Standard Time) JSON.stringify(new Date(www.feishenbo.cn)); // ""2018-12-24T02:59:25.776Z"" JSON.parse(JSON.stringify(new Date())); // "2018-12-24T02:59:41.523Z"解决方法转成字符串或者时间戳就好了。
// saucxs let date = (new Date()).valueOf(); // 1545620645915 JSON.stringify(date); // "1545620673267" JSON.parse(JSON.stringify(date)); // 1545620658688其中(6)正则情况下
// saucxs let obj = { name: "saucxs", a: /'123'/ } console.log(obj); // {name: "saucxs", a: www.dfgjpt.com/'123'/} let b = JSON.parse(JSON.stringify(obj)); console.log(b);
参考:Spark官网 Spark学习笔记总结 Spark的运行架构分析(二)之运行模式详解
Spark-1(概念)的更多相关文章
- 【Spark深入学习-11】Spark基本概念和运行模式
----本节内容------- 1.大数据基础 1.1大数据平台基本框架 1.2学习大数据的基础 1.3学习Spark的Hadoop基础 2.Hadoop生态基本介绍 2.1Hadoop生态组件介绍 ...
- Spark 基本概念 & 安装
1. Spark 基本概念 1.0 官网 传送门 1.1 简介 Spark 是用于大规模数据处理的快如闪电的统一分析引擎. 1.2 速度 Spark 可以获得更高的性能,针对 batch 计算和流计算 ...
- spark基本概念
Client:客户端进程,负责提交作业到Master. Application:Spark Application的概念和Hadoop MapReduce中的类似,指的是用户编写的Spark应用程序, ...
- Spark核心概念理解
本文主要内容来自于<Hadoop权威指南>英文版中的Spark章节,能够说是个人的翻译版本号,涵盖了基本的Spark概念.假设想获得更好地阅读体验,能够訪问这里. 安装Spark 首先从s ...
- Spark基本概念快速入门
Spark集群 一组计算机的集合,每个计算机节点作为独立的计算资源,又可以虚拟出多个具备计算能力的虚拟机,这些虚拟机是集群中的计算单元.Spark的核心模块专注于调度和管理虚拟机之上分布式计算任务 ...
- Spark 概念学习系列之Spark基本概念和模型(十八)
打好基础,别小瞧它! spark的运行模式多种多样,在单机上既可以本地模式运行,也可以伪分布模式运行.而当以分布式的方式在集群中运行时.底层的资源调度可以使用Mesos或者Yarn,也可使用spark ...
- spark基本概念整理
app 基于spark的用户程序,包含了一个driver program和集群中多个executor driver和executor存在心跳机制确保存活3 --conf spark.executor. ...
- 深入理解Spark(一):Spark核心概念RDD
RDD全称叫做弹性分布式数据集(Resilient Distributed Datasets),它是一种分布式的内存抽象,表示一个只读的记录分区的集合,它只能通过其他RDD转换而创建,为此,RDD支持 ...
- Spark核心概念
1.Application 基于spark的用户程序,包含了一个Driver Program以及集群上中多个executor: spark中只要有一个sparkcontext就是一个a ...
- Spark核心概念之RDD
RDD: Resilient Distributed Dataset RDD的特点: 1.A list of partitions 一系列的分片:比如说64M一片:类似于Hadoop中的s ...
随机推荐
- Ambiguous HTTP method Actions require an explicit HttpMethod binding for Swagger 2.0
异常内容 NotSupportedException: Ambiguous HTTP method for action . Actions require an explicit HttpMetho ...
- EF Core 快速上手——创建应用的DbContext
系列文章 EF Core 快速上手--EF Core 入门 EF Core 快速上手--EF Core的三种主要关系类型 本节导航 定义应用的DbContext 创建DbContext的一个实例 创建 ...
- 【转载】 Sqlserver限制最大占用内存
在Sqlserver数据库管理软件中,Sqlserver对系统内存的管理原则是:按需分配,并且分配完成后为了查询有更好的性能,并不会立即自动释放内存,数据取出后,还会一直占用着内存,所以在Sqlser ...
- 三星5.0以上设备最完美激活XPOSED框架的经验
对于喜欢钻研手机的小伙伴来说,常常会接触到Xposed框架以及种类繁多功能强大的模块,对于5.0以下的系统版本,只要手机能获得Root权限,安装和激活Xposed框架是异常简易的,但随着系统版本的不断 ...
- Express NodeJs Web框架 入门笔记
Express 是一个简洁而灵活的 node.js Web应用框架, 提供了一系列强大特性帮助你创建各种 Web 应用,和丰富的 HTTP 工具. 使用 Express 可以快速地搭建一个完整功能的网 ...
- Python使用Plotly绘图工具,绘制饼图
今天我们来学习一下如何使用Python的Plotly绘图工具,绘制饼图 使用Plotly绘制饼图的方法,我们需要使用graph_objs中的Pie函数 函数中最常用的两个属性values,用于赋值给需 ...
- jQuery字母大小写转换函数
toLowerCase() ------ 将字符串中的所有字符都转换成小写: toUpperCase() ------ 将字符串中的所有字符都转换成大写:
- nexus 10 救砖 安装lineage OS 15 并 root
因为平板自带的谷歌应用太烦人了,想root之后卸载它们. 一.root nexus 10 官方系统 1.把img拷贝到platform-tools(Android官网下载)文件夹 2.platform ...
- 数据库【mongodb篇】基本命令学习笔记
MongoDB基本命令用 MongoDB基本命令用 成功启动MongoDB后,再打开一个命令行窗口输入mongo,就可以进行数据库的一些操作. 输入help可以看到基本操作命令: show dbs ...
- centos7 安装 pyspider 出现的一系列问题及解决方案集合
先安装python3 和 pip3 wget https://www.python.org/ftp/python/3.6.5/Python-3.6.5.tgz 安装zlib-devel包(后面安装pi ...