数据集偏斜 - class skew problem - 以SVM松弛变量为例
原文
接下来要说的东西其实不是松弛变量本身,但由于是为了使用松弛变量才引入的,因此放在这里也算合适,那就是惩罚因子C。回头看一眼引入了松弛变量以后的优化问题:

注意其中C的位置,也可以回想一下C所起的作用(表征你有多么重视离群点,C越大越重视,越不想丢掉它们)。这个式子是以前做SVM的人写的,大家也就这么用,但没有任何规定说必须对所有的松弛变量都使用同一个惩罚因子,我们完全可以给每一个离群点都使用不同的C,这时就意味着你对每个样本的重视程度都不一样,有些样本丢了也就丢了,错了也就错了,这些就给一个比较小的C;而有些样本很重要,决不能分类错误(比如中央下达的文件啥的,笑),就给一个很大的C。
当然实际使用的时候并没有这么极端,但一种很常用的变形可以用来解决分类问题中样本的“偏斜”问题。
先来说说样本的偏斜问题,也叫数据集偏斜(unbalanced),它指的是参与分类的两个类别(也可以指多个类别)样本数量差异很大。比如说正类有10,000个样本,而负类只给了100个,这会引起的问题显而易见,可以看看下面的图:
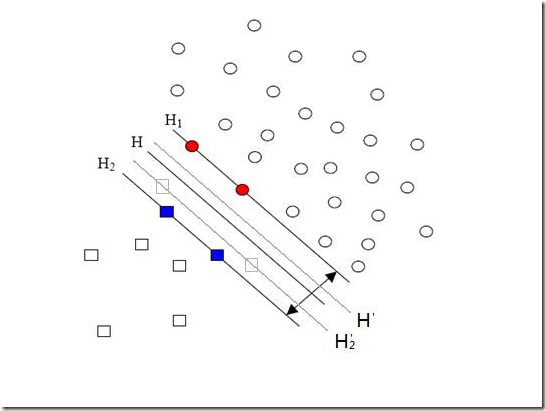
方形的点是负类。H,H1,H2是根据给的样本算出来的分类面,由于负类的样本很少很少,所以有一些本来是负类的样本点没有提供,比如图中两个灰色的方形点,如果这两个点有提供的话,那算出来的分类面应该是H’,H2’和H1,他们显然和之前的结果有出入,实际上负类给的样本点越多,就越容易出现在灰色点附近的点,我们算出的结果也就越接近于真实的分类面。但现在由于偏斜的现象存在,使得数量多的正类可以把分类面向负类的方向“推”,因而影响了结果的准确性。
对付数据集偏斜问题的方法之一就是在惩罚因子上作文章,想必大家也猜到了,那就是给样本数量少的负类更大的惩罚因子,表示我们重视这部分样本(本来数量就少,再抛弃一些,那人家负类还活不活了),因此我们的目标函数中因松弛变量而损失的部分就变成了:

其中i=1…p都是正样本,j=p+1…p+q都是负样本。libSVM这个算法包在解决偏斜问题的时候用的就是这种方法。
那C+和C-怎么确定呢?它们的大小是试出来的(参数调优),但是他们的比例可以有些方法来确定。咱们先假定说C+是5这么大,那确定C-的一个很直观的方法就是使用两类样本数的比来算,对应到刚才举的例子,C-就可以定为500这么大(因为10,000:100=100:1嘛)。
但是这样并不够好,回看刚才的图,你会发现正类之所以可以“欺负”负类,其实并不是因为负类样本少,真实的原因是负类的样本分布的不够广(没扩充到负类本应该有的区域)。说一个具体点的例子,现在想给政治类和体育类的文章做分类,政治类文章很多,而体育类只提供了几篇关于篮球的文章,这时分类会明显偏向于政治类,如果要给体育类文章增加样本,但增加的样本仍然全都是关于篮球的(也就是说,没有足球,排球,赛车,游泳等等),那结果会怎样呢?虽然体育类文章在数量上可以达到与政治类一样多,但过于集中了,结果仍会偏向于政治类!所以给C+和C-确定比例更好的方法应该是衡量他们分布的程度。比如可以算算他们在空间中占据了多大的体积,例如给负类找一个超球——就是高维空间里的球啦——它可以包含所有负类的样本,再给正类找一个,比比两个球的半径,就可以大致确定分布的情况。显然半径大的分布就比较广,就给小一点的惩罚因子。
但是这样还不够好,因为有的类别样本确实很集中,这不是提供的样本数量多少的问题,这是类别本身的特征(就是某些话题涉及的面很窄,例如计算机类的文章就明显不如文化类的文章那么“天马行空”),这个时候即便超球的半径差异很大,也不应该赋予两个类别不同的惩罚因子。
看到这里读者一定疯了,因为说来说去,这岂不成了一个解决不了的问题?然而事实如此,完全的方法是没有的,根据需要,选择实现简单又合用的就好(例如libSVM就直接使用样本数量的比)。

数据集偏斜 - class skew problem - 以SVM松弛变量为例的更多相关文章
- Relation Extraction中SVM分类样例unbalance data问题解决 -松弛变量与惩罚因子
转载自:http://blog.csdn.net/yangliuy/article/details/8152390 1.问题描述 做关系抽取就是要从产品评论中抽取出描述产品特征项的target短语以及 ...
- 7. SVM松弛变量
我们之前讨论的情况都是建立在样例线性可分的假设上,当样例线性不可分时,我们可以尝试使用核函数来将特征映射到高维,这样很可能就可分了.然而,映射后我们也不能100%保证可分.那怎么办呢,我们需要将模型进 ...
- Python实现鸢尾花数据集分类问题——基于skearn的SVM
Python实现鸢尾花数据集分类问题——基于skearn的SVM 代码如下: # !/usr/bin/env python # encoding: utf-8 __author__ = 'Xiaoli ...
- SVM松弛变量-记录毕业论文3
上一篇博客讨论了高维映射和核函数,也通过例子说明了将特征向量映射到高维空间中可以使其线性可分.然而,很多情况下的高维映射并不能保证线性可分,这时就可以通过加入松弛变量放松约束条件.同样这次的记录仍然通 ...
- SVM python小样例
SVM有很多种实现,但是本章只关注其中最流行的一种实现,即序列最小化(SMO)算法在此之后,我们将介绍如何使用一种称为核函数的方式将SVM扩展到更多的数据集上基于最大间隔的分割数据优点:泛化错误率低, ...
- SVM学习(五):松弛变量与惩罚因子
https://blog.csdn.net/qll125596718/article/details/6910921 1.松弛变量 现在我们已经把一个本来线性不可分的文本分类问题,通过映射到高维空间而 ...
- SVM学习(续)核函数 & 松弛变量和惩罚因子
SVM的文章可以看:http://www.cnblogs.com/charlesblc/p/6193867.html 有写的最好的文章来自:http://www.blogjava.net/zhenan ...
- SVM学习(续)
SVM的文章可以看:http://www.cnblogs.com/charlesblc/p/6193867.html 有写的最好的文章来自:http://www.blogjava.net/zhenan ...
- 【转】 SVM算法入门
课程文本分类project SVM算法入门 转自:http://www.blogjava.net/zhenandaci/category/31868.html (一)SVM的简介 支持向量机(Supp ...
随机推荐
- python 数据类型---列表使用 之一
列表的表现形式:其中的元素可以使任何数据类型,像 字符串,数字, 字典, 列表,变量 等任何类型 age = 28 name = ["Frank", "Lee" ...
- Java - I/O
File类 java.io 操作文件和目录,与平台无关.具体的常用实例方法: File file = new File("."); // 以当前路径创建名为 ".&quo ...
- glibc 各版本发布时间以及内核默认glibc版本
最近有些软件要求glibc 2.14+,centos 6.x自带的版本是2.12的,特查了下glibc 各版本发布时间以及与对应的内核,如下: Complete glibc release histo ...
- HTML5-电影影评网
学习完了HTML5的新标签,然后结合之前的案例做了第一个小案例.自我感觉良好.下面我来展示一下图片 这是我浏览其他网站的时候以为发现的新功能可以运行代码,这是运行之后截得图片.自我感觉照片还是蛮高大上 ...
- iOS---The maximum number of apps for free development profiles has been reached.
真机调试免费App ID出现的问题The maximum number of apps for free development profiles has been reached.免费应用程序调试最 ...
- SQL Server 2012 新特性:服务角色管理
数据库角色管理,已经可以使用alter role,create role和drop role. 2012增加了几个ddl语句,可以操作服务级别的角色管理, CREATE SERVER ROLE 用 ...
- javascript继承笔记
//原型(prototype):原型是一个对象,其他对象可以通过它实现属性继承 /*笔记: * 1.类式继承:通过原型链继承的方式 * 2.原型式继承:对类式继承的封装 * 3.寄生式继承:对原型继承 ...
- MySQL Performance-Schema(二) 理论篇
MySQL Performance-Schema中总共包含52个表,主要分为几类:Setup表,Instance表,Wait Event表,Stage Event表Statement Event表,C ...
- 烂泥:centos6 yum方式升级内核
本文由ilanniweb提供友情赞助,首发于烂泥行天下 想要获得更多的文章,可以关注我的微信ilanniweb 最近没有时间好久没有写文章了,今天由于需要安装docker学习虚拟容器的知识,需要升级O ...
- Fedora javac 命令提示 [javac: 未找到命令...]
[joy@localhost ~]$ java -version openjdk version "1.8.0_91" OpenJDK Runtime Environment (b ...