Python爬虫——request实例:爬取网易云音乐华语男歌手top10歌曲
requests是python的一个HTTP客户端库,跟urllib,urllib2类似,但比那两个要简洁的多,至于request库的用法,
推荐一篇不错的博文:https://cuiqingcai.com/2556.html
话不多说,先说准备工作:
1,下载需要的库:request,BeautifulSoup( 解析html和xml字符串),xlwt(将爬取到的数据存入Excel表中)
2,至于BeautifulSoup 解析html方法,推荐一篇博文:http://blog.csdn.net/u013372487/article/details/51734047
3,re库,我们要用正则表达式来筛选爬取到的内容
好的,开始爬:
首先我们找到网易云音乐华语男歌手页面入口的URL:url = 'http://music.163.com/discover/artist/cat?id=1001'
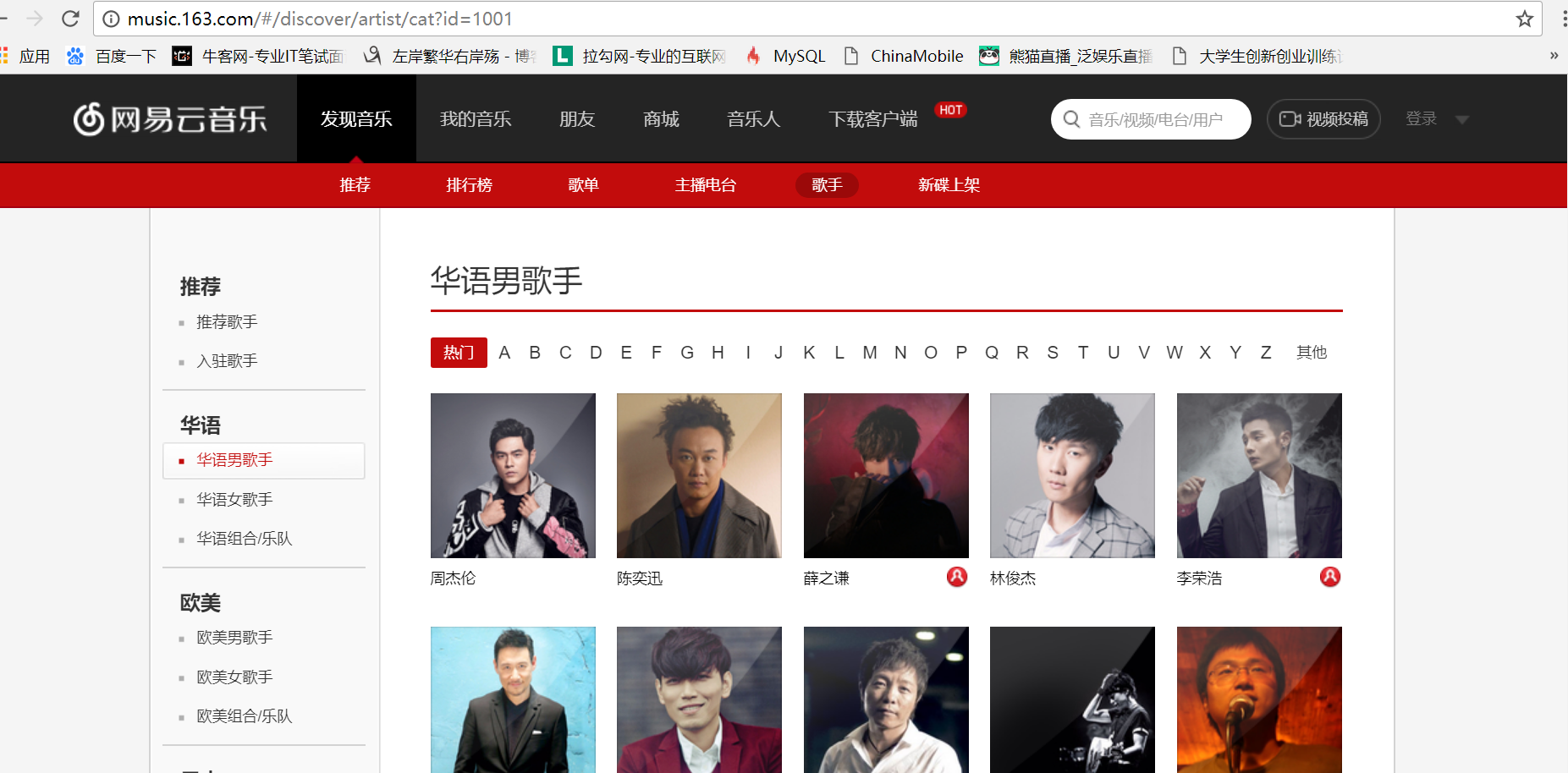
把整个网页爬取下来: html= requests.get(url).text
soup = BeautifulSoup(html,'html.parser'
我们要找到进入top10歌手页面的url,用浏览器的开发者工具,我们发现歌手的信息
都在<div class="u-cover u-cover-5">......</div>这个标签里面,如图:
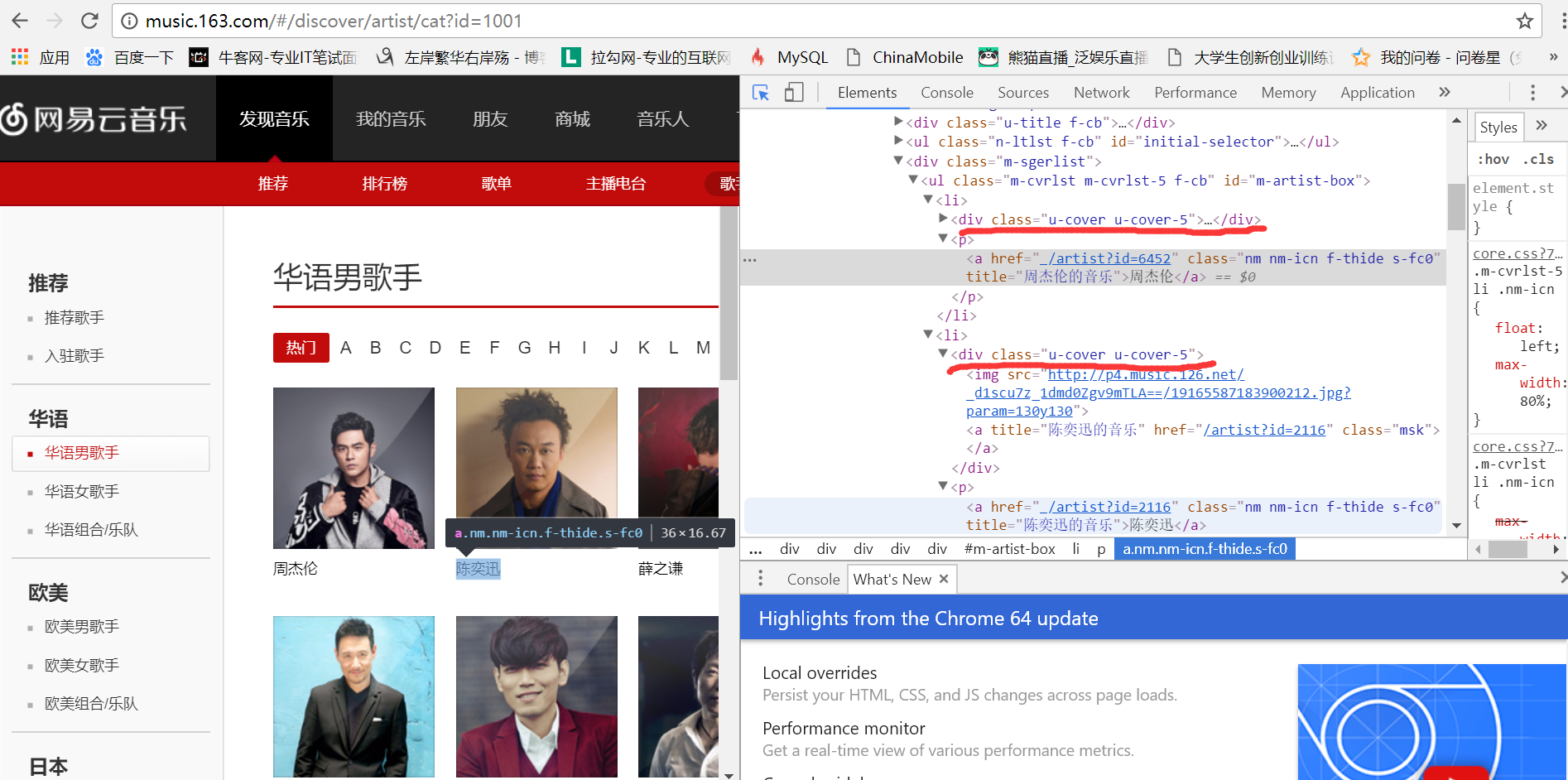
于是,我们把top10歌手的信息筛选出来:
top_10 = soup.find_all('div',attrs = {'class':'u-cover u-cover-5'})
singers = []
for i in top_10:
singers.append(re.findall(r'.*?<a class="msk" href="(/artist\?id=\d+)" title="(.*?)的音乐"></a>.*?',str(i))[0])
获取到歌手的信息后,依次进入歌手的界面,把他们的热门歌曲爬取并写入Excel表中,原理同上
附上完整代码:
import xlwt
import requests
from bs4 import BeautifulSoup
import re url = 'http://music.163.com/discover/artist/cat?id=1001'#华语男歌手页面
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
html=r.text #获取整个网页 soup = BeautifulSoup(html,'html.parser') #
top_10 = soup.find_all('div',attrs = {'class':'u-cover u-cover-5'})
#print(top_10) singers = []
for i in top_10:
singers.append(re.findall(r'.*?<a class="msk" href="(/artist\?id=\d+)" title="(.*?)的音乐"></a>.*?',str(i))[0])
#print(singers) url = 'http://music.163.com'
for singer in singers:
try:
new_url = url + str(singer[0])
#print(new_url)
songs=requests.get(new_url).text
soup = BeautifulSoup(songs,'html.parser')
Info = soup.find_all('textarea',attrs = {'style':'display:none;'})[0]
songs_url_and_name = soup.find_all('ul',attrs = {'class':'f-hide'})[0]
#print(songs_url_and_name)
datas = []
data1 = re.findall(r'"album".*?"name":"(.*?)".*?',str(Info.text))
data2 = re.findall(r'.*?<li><a href="(/song\?id=\d+)">(.*?)</a></li>.*?',str(songs_url_and_name)) for i in range(len(data2)):
datas.append([data2[i][1],data1[i],'http://music.163.com/#'+ str(data2[i][0])])
#print(datas)
book = xlwt.Workbook()
sheet1=book.add_sheet('sheet1',cell_overwrite_ok = True)
sheet1.col(0).width = (25*256)
sheet1.col(1).width = (30*256)
sheet1.col(2).width = (40*256)
heads=['歌曲名称','专辑','歌曲链接']
count=0 for head in heads:
sheet1.write(0,count,head)
count+=1 i=1
for data in datas:
j=0
for k in data:
sheet1.write(i,j,k)
j+=1
i+=1
book.save(str(singer[1])+'.xls')#括号里写存入的地址 except:
continue
Python爬虫——request实例:爬取网易云音乐华语男歌手top10歌曲的更多相关文章
- 如何用Python网络爬虫爬取网易云音乐歌曲
今天小编带大家一起来利用Python爬取网易云音乐,分分钟将网站上的音乐down到本地. 跟着小编运行过代码的筒子们将网易云歌词抓取下来已经不再话下了,在抓取歌词的时候在函数中传入了歌手ID和歌曲名两 ...
- python网络爬虫&&爬取网易云音乐
#爬取网易云音乐 url="https://music.163.com/discover/toplist" #歌单连接地址 url2 = 'http://music.163.com ...
- python爬虫+词云图,爬取网易云音乐评论
又到了清明时节,用python爬取了网易云音乐<清明雨上>的评论,统计词频和绘制词云图,记录过程中遇到一些问题 爬取网易云音乐的评论 一开始是按照常规思路,分析网页ajax的传参情况.看到 ...
- 爬取网易云音乐评论!python 爬虫入门实战(六)selenium 入门!
说到爬虫,第一时间可能就会想到网易云音乐的评论.网易云音乐评论里藏了许多宝藏,那么让我们一起学习如何用 python 挖宝藏吧! 既然是宝藏,肯定是用要用钥匙加密的.打开 Chrome 分析 Head ...
- python爬虫:了解JS加密爬取网易云音乐
python爬虫:了解JS加密爬取网易云音乐 前言 大家好,我是"持之以恒_liu",之所以起这个名字,就是希望我自己无论做什么事,只要一开始选择了,那么就要坚持到底,不管结果如何 ...
- 用Python爬取网易云音乐热评
用Python爬取网易云音乐热评 本文旨在记录Python爬虫实例:网易云热评下载 由于是从零开始,本文内容借鉴于各种网络资源,如有侵权请告知作者. 要看懂本文,需要具备一点点网络相关知识.不过没有关 ...
- Python爬取网易云音乐歌手歌曲和歌单
仅供学习参考 Python爬取网易云音乐网易云音乐歌手歌曲和歌单,并下载到本地 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经做 ...
- python爬取网易云音乐歌曲评论信息
网易云音乐是广大网友喜闻乐见的音乐平台,区别于别的音乐平台的最大特点,除了“它比我还懂我的音乐喜好”.“小清新的界面设计”就是它独有的评论区了——————各种故事汇,各种金句频出.我们可以透过歌曲的评 ...
- python3爬虫应用--爬取网易云音乐(两种办法)
一.需求 好久没有碰爬虫了,竟不知道从何入手.偶然看到一篇知乎的评论(https://www.zhihu.com/question/20799742/answer/99491808),一时兴起就也照葫 ...
随机推荐
- html标签详解
html标签详解 <!DOCTYPE> 标签 <!DOCTYPE> 声明必须是 HTML 文档的第一行,位于 <html> 标签之前. <!DOCTYPE ...
- visual studio调试功能简述
vs调试简述 1.调试功能简述 vs提供了很强大的调试功能,能够让我们一步步执行中找到每个变量的值,便于查错改错.很多IDE都有调试功能,在使用调试功能时,记得先创建一个项目,哪怕是一个文件,也创建一 ...
- eclipse快捷键及设置
1.Eclipse设置新建菜单初始项 windows-->Perspective-->Customize Perspective--> 2.Eclipse快捷键 1. ctrl+sh ...
- 【java学习笔记】正则表达式
一.正则表达式 1.预定义字符集 . 表示任意一个字符 \d 表示任意一个数字 \w 表示任意一个单词字符(只能是数字.字母.下划线) \s 表示任意一个空白字符(\t\r\n\f\x0B) \D ...
- Typescript 基础应用
什么是 TypeScript TypeScript 是微软开发的 JavaScript 的超集,TypeScript兼容JavaScript,可以载入JavaScript代码然后运行.TypeScri ...
- 【前端】Vue2全家桶案例《看漫画》之五、引入axios
转载请注明出处:http://www.cnblogs.com/shamoyuu/p/vue_vux_app_5.html 项目github地址:https://github.com/shamoyuu/ ...
- python调试
如果很简单的程序,建议还是pirnt打出来. 对于Linux环境,使用pdb/ipdb是一个不错的选择. 安装ipdb sudo pip install ipdb 开启调试 手动在需要调试的地方写入s ...
- 对于vxworks下硬盘驱动
1.曾经看到帖子说vxworks5.5下没有sata驱动,vxworks6.6下有,这样的说法恐怕不正确,由 于俺在5.5下也运用运用了sata硬盘,请注重这里俺只是说运用运用,没有说运用运用了sat ...
- 使用ffserver实现转发实时流媒体(摄像头捕获)
本系统为ubuntu 10.04LTS 说明1:本实验在本机成功测试通过: 说明2:本实验仅仅测试了视频流,未测试音频流. 1.配置ffserver.conf -------------------- ...
- AM335x(TQ335x)学习笔记——Nand&&网卡驱动移植
移植完成声卡驱动之后本想再接再励,移植网卡驱动,但没想到的是TI维护的内核太健壮,移植网卡驱动跟之前移植按键驱动一样简单,Nand驱动也是如此,于是,本人将Nand和网卡放在同一篇文章中介绍.介绍之前 ...