使用kibana可视化报表实时监控你的应用程序,从日志中找出问题,解决问题
先结果导向,来看我在kibana dashborad中制作的几张监控图。
一:先睹为快
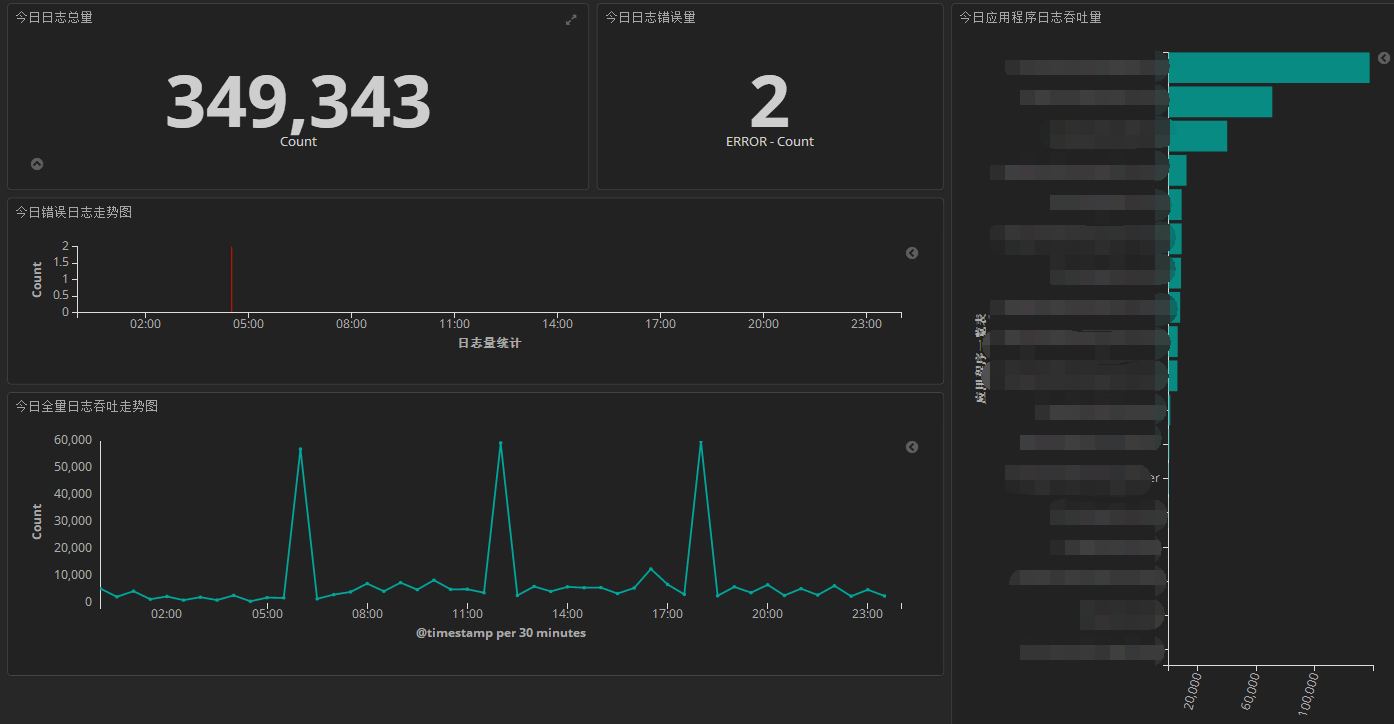
dashboard1:监控几个维度的日志,这么点日志量是因为把无用的清理掉了,而且只接入了部分应用。
<1> 每日日志总数。
<2> 每日日志错误数,从log4net中level=ERROR抠出来的。
<3> 每个应用贡献的日志量(按照应用程序分组)
<4> 今日错误日志时间分布折线图。
<5> 今日全量日志时间分布折线图。
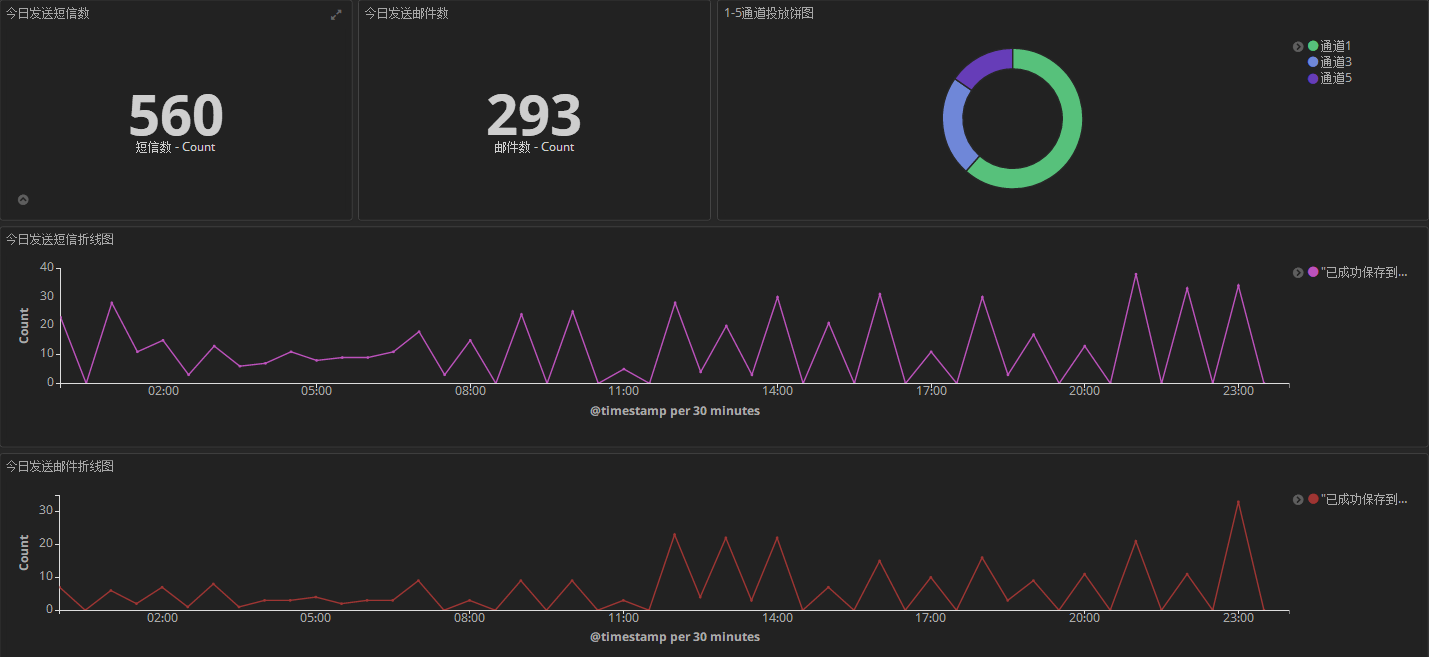
dashboard2:这个主要用来监控某日智能精准触发的短信数和邮件数以及通道占比情况。
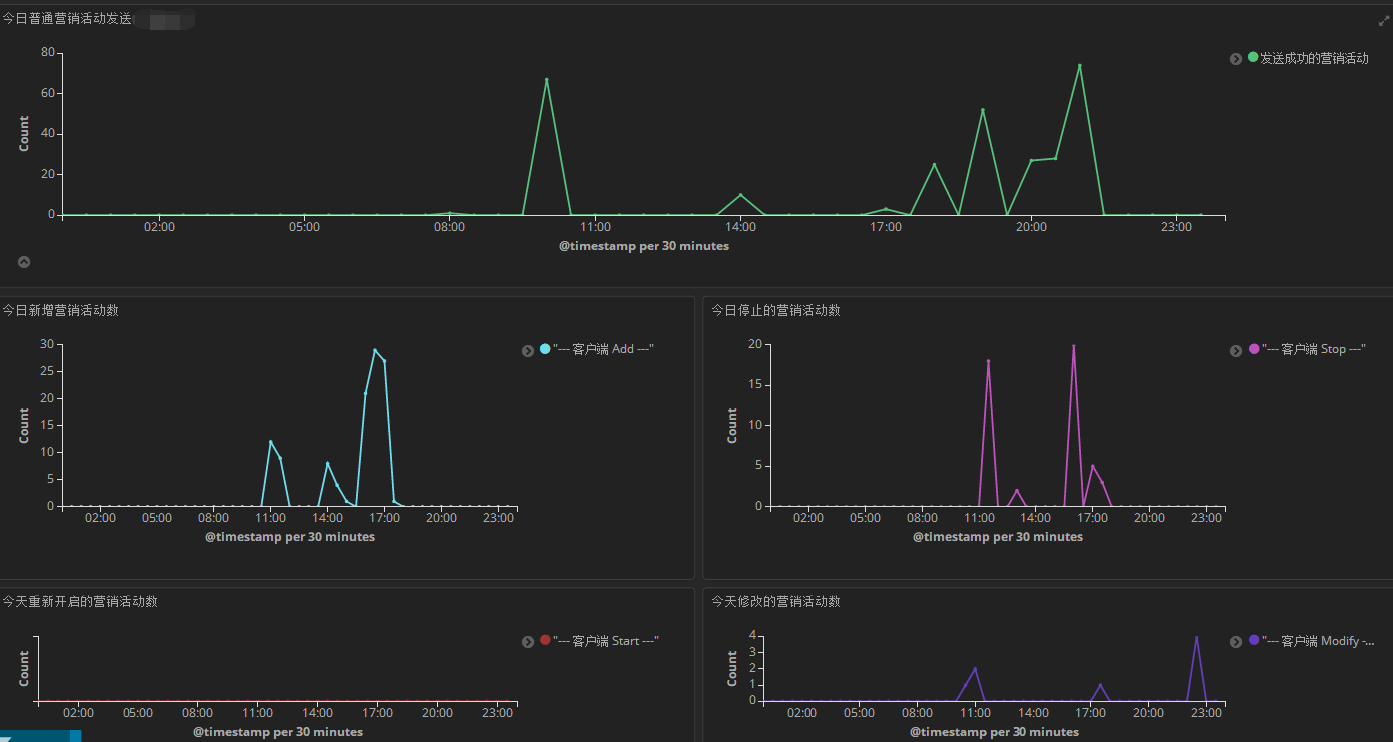
dashboard3: 某日发送的营销活动概况,一目了然。
二:采集注意事项
接下来我们聊聊这个流程中注意的问题。
1. 使用fileBeat 清洗掉垃圾日志
采集端使用的是filebeat,一个应用程序配置一个prospectors探测器。
#=========================== Filebeat prospectors ============================= filebeat.prospectors: # Each - is a prospector. Most options can be set at the prospector level, so
# you can use different prospectors for various configurations.
# Below are the prospector specific configurations. ################## 1. IntelligentMarketing.Service3 ##################
-
enabled: true
paths:
D:\Services\channel3\log\*.log
exclude_lines: ['^----------','重新排队,暂停 100。$']
fields:
appname: IntelligentMarketing.Service3
ipnet: 10.153.204.199
ippub: 121.41.176.41
encoding: gbk
multiline.pattern: ^(\s|[A-Z][a-z]|-)
multiline.match: after ################## 2. IntelligentMarketing.Service4 ##################
-
enabled: true
paths:
D:\Services\channel4\log\*.log
exclude_lines: ['^----------','重新排队,暂停 100。$']
fields:
appname: IntelligentMarketing.Service4
ipnet: 10.153.204.199
ippub: 121.41.176.41
encoding: gbk
multiline.pattern: ^(\s|[A-Z][a-z]|-)
multiline.match: after
《1》 exclude_lines
这个用来过滤掉我指定的垃圾日志,比如说以 ----------- 开头的 和 “重新排队,暂停100。”结尾的日志,反正正则怎么用,这里就怎么配吧,有一点注意,
尽量不要配置 contain模式的正则,比如: '.*暂未获取到任何mongodb记录*.' 这样会导致filebeat cpu爆高。
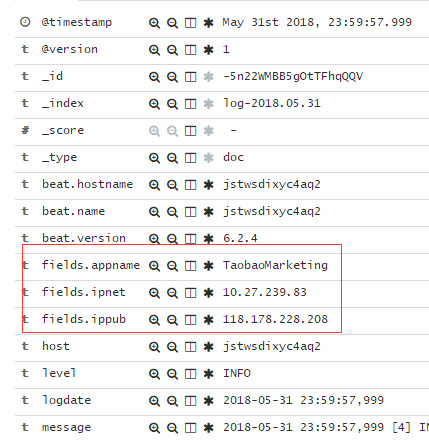
《2》 fields
这个用于配置应用程序专属的一些信息,比如我配置了appname,内网ip,外网ip,方便做后期的日志检索,检索出来就是下面这样子。
《3》 multiline
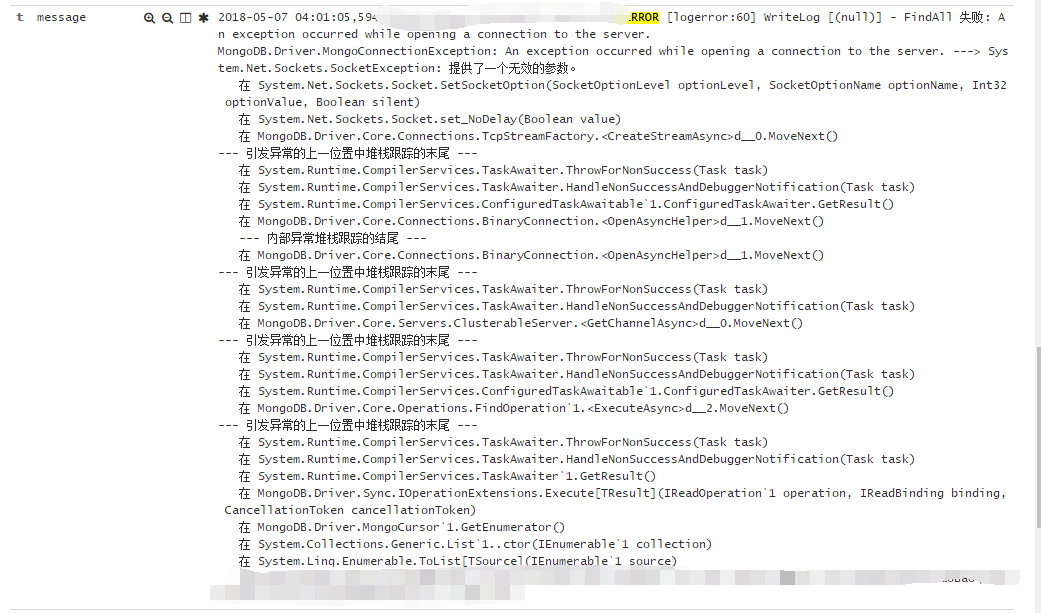
有时候应用程序会抛异常,就存在着如何合并多行信息的问题,我这里做的配置就是如果当前行是以‘空格’,‘字母‘ 和 ‘-’开头的,那么就直接合并到上
一行,比如下面这个Mongodb的FindALL异常堆栈。
2. logstash解析日志
主要还是使用 grok 正则,比如下面这条日志,我需要提取出‘date’,‘threadID’,和 “ERROR” 这三个重要信息。
2017-11-13 00:00:36,904 [65] ERROR [xxx.Monitor.Worker:83] Tick [(null)] - 这是一些测试数据。。
那么就可以使用如下的grok模式。
match => { "message" => "%{TIMESTAMP_ISO8601:logdate} \[%{NUMBER:threadId}\] %{LOGLEVEL:level}"}
上面这段话的意思就是:提取出的时间给logdate,65给threadId,ERROR给level,然后整个内容整体给默认的message字段,下面是完整的logstash.yml。
input {
beats {
port => 5044
}
}
filter {
grok {
match => { "message" => "%{TIMESTAMP_ISO8601:logdate} \[%{NUMBER:threadId}\] %{LOGLEVEL:level}"}
}
if ([message] =~ "^----------") {
drop {}
}
date {
match => ["logdate", "yyyy-MM-dd HH:mm:ss,SSS"]
# target => "@timestamp"
timezone => "Asia/Shanghai"
}
ruby {
code => "event.timestamp.time.localtime"
}
}
output {
stdout {
codec => rubydebug { }
}
elasticsearch {
hosts => "10.132.166.225"
index => "log-%{+YYYY.MM.dd}"
}
}
三: kibana制作
1. 今日全量日志吞吐走势图
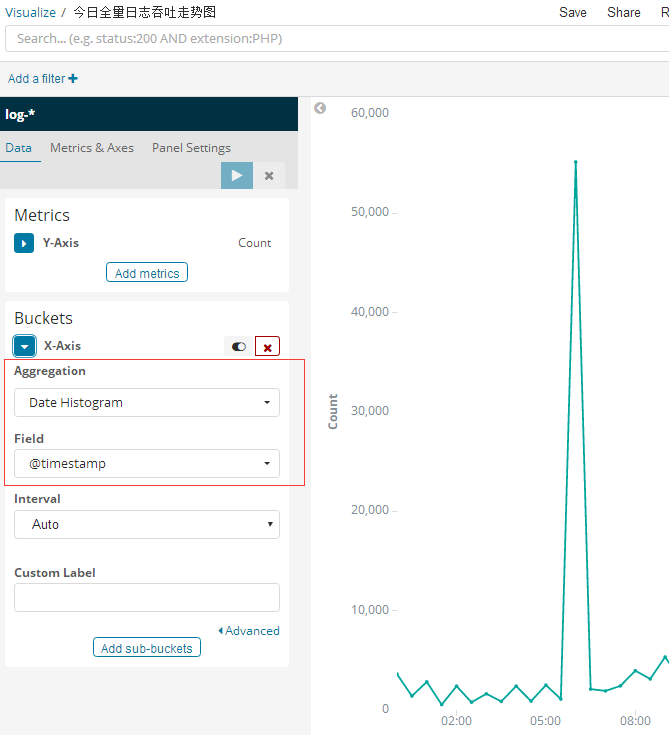
这个比较简单。因为本质上是一个聚合计算,aggreration按照 Date Histogram聚合即可。
2. 今日错误日志走势图
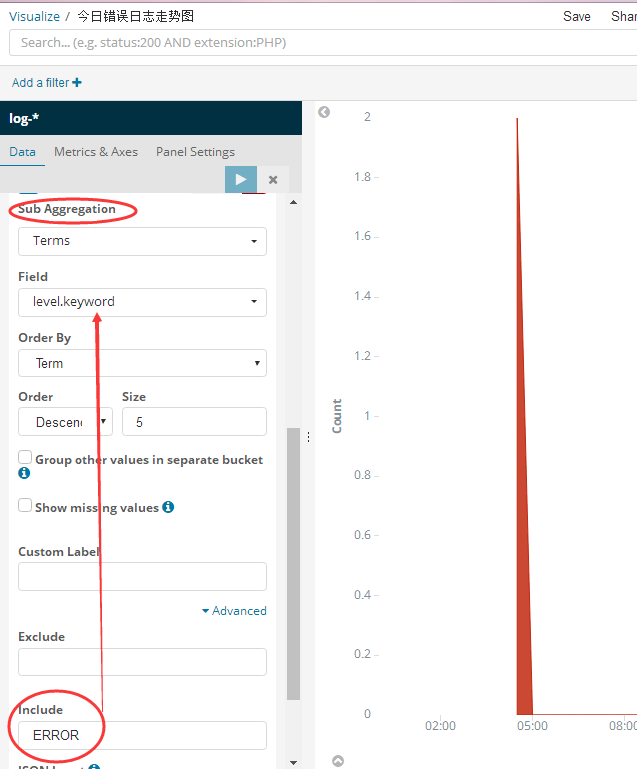
这个相当于在上面那个按时间聚合分组之后,然后在每一个bucket中再做一个 having level=‘ERROR’的筛选即可。
3. 今日普通营销活动发送
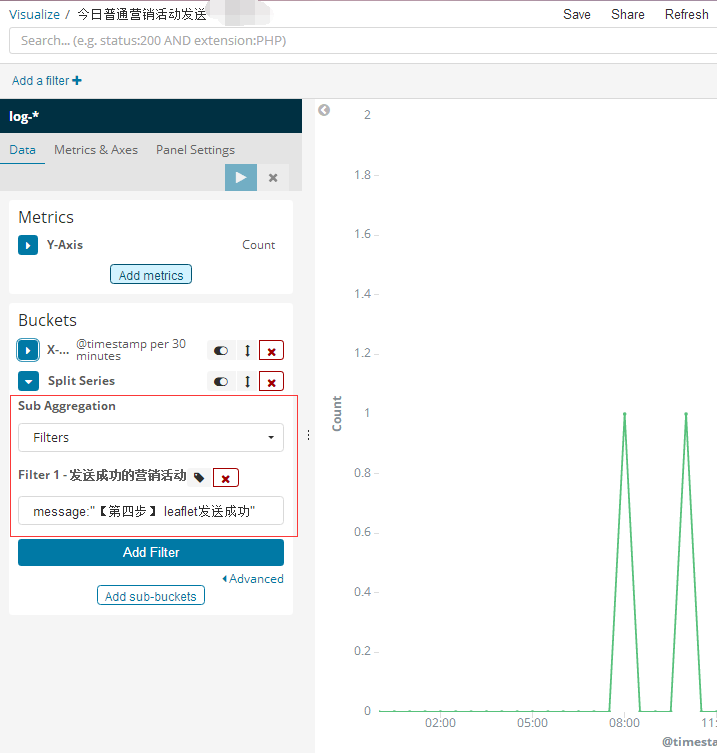
这个就是在bucket桶中做了一个 having message like '%【第四步】 leaflet发送成功%' ,为什么这么写是因为只要发送成功,我都会追加这么一条日志,
所以大概就是这么个样子,性能上大家应该也知道,对吧。
4. 今日应用程序日志吞吐量
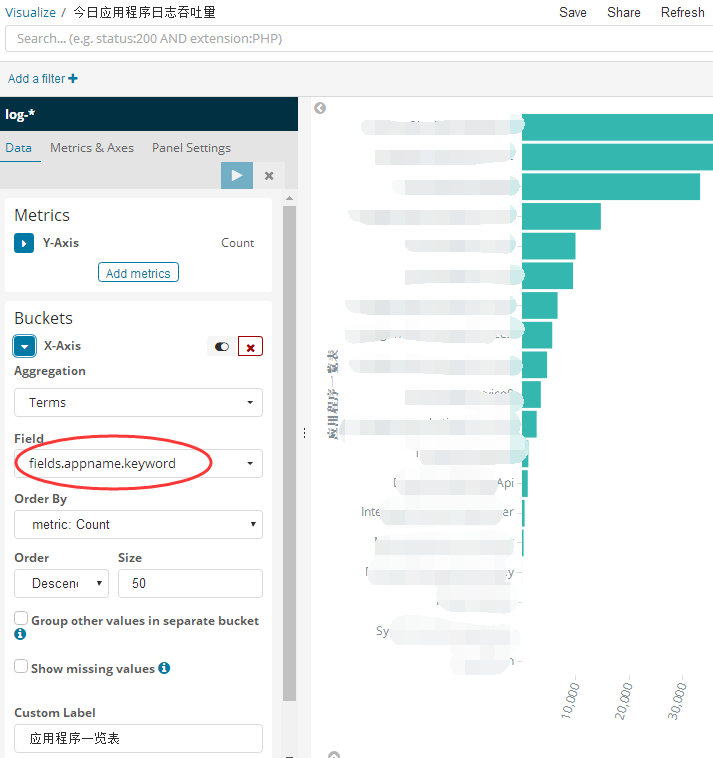
这个不想上面那三张图按照时间聚合,而是按照appname 聚合就可以了,还记得我在filebeat的fileld中添加的appname字段吗?
四:使用nginx给kibana做权限验证
为了避开x-pack 的复杂性,大家可以使用nginx给kibana做权限验证。
1. 安装 yum install -y httpd-tools。
2. 设置用户名和密码:admin abcdefg
htpasswd -bc /data/myapp/nginx/conf/htpasswd.users damin abcdefg
3. 修改nginx的配置。
server {
listen 80;
server_name localhost;
#charset koi8-r;
#access_log logs/host.access.log main;
auth_basic "Restricted Access";
auth_basic_user_file /data/myapp/nginx/conf/htpasswd.users; #登录验证
location / {
proxy_pass http://10.122.166.225:5601; #转发到kibana
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
allow 222.68.71.185; #允许的IP
allow 118.133.47.76; #允许的IP
deny all;
}
4. 重启nginx
[root@localhost conf]# /data/myapp/nginx/sbin/nginx -s reload
然后绑定域名到你的ip之后,登陆就会有用户名密码验证了。
好了,本篇就说这么多,希望对你有帮助。
使用kibana可视化报表实时监控你的应用程序,从日志中找出问题,解决问题的更多相关文章
- Nginx系列4:用GoAccess实现可视化并实时监控access日志
1.ubuntu16.04安装GoAccess GoAccess下载地址:https://goaccess.io/download 安装步骤: $ wget https://tar.goaccess. ...
- 用goaccess实现可视化并实时监控access日志
goaccess access.log -o ../html/report.html --real-time-html time-format='%H:%M:%S' --date-format=‘%d ...
- 数据可视化之powerBI技巧(五)在Power BI中写出优雅的度量值是什么体验?
之前的文章(采悟:连接表的几个DAX函数,一次全掌握)介绍了产品A的客户与产品B的客户的各种交叉关系,其中最常用的应该是找出A和B的共同客户,以便进行产品关联分析. 之前的思路是计算出两个产品的共同客 ...
- 虎牙数万主播同时在线直播的秘密,CDN推流日志上行实时监控
6 月 10 日,又拍云 Open Talk | 2018 音视频技术沙龙·深圳站 顺利落幕,来自虎牙的直播运维研发架构师张波在沙龙上做了<基于CDN推流日志的主播上行实时监控及其自动化解密&g ...
- 性能工具之JMeter+InfluxDB+Grafana打造压测可视化实时监控【转】
概述 本文我们将介绍如何使用JMeter+InfluxDB+Grafana打造压测可视化实时监控. 引言 我们很多时候在使用JMeter做性能测试,我们很难及时察看压测过程中应用的性能状况,总是需要等 ...
- 转: 透过CAT,来看分布式实时监控系统的设计与实现
评注: 开源的分布式监控系统 转:http://www.infoq.com/cn/articles/distributed-real-time-monitoring-and-control-syste ...
- 透过CAT,来看分布式实时监控系统的设计与实现
2011年底,我加入大众点评网,出于很偶然的机会,决定开发CAT,为各个业务线打造分布式实时监控系统,CAT的核心概念源自eBay闭源系统CAL----eBay的几大法宝之一. 在当今互联网时代,业务 ...
- fluentd结合kibana、elasticsearch实时搜索分析hadoop集群日志<转>
转自 http://blog.csdn.net/jiedushi/article/details/12003171 Fluentd是一个开源收集事件和日志系统,它目前提供150+扩展插件让你存储大数据 ...
- 如何做实时监控?—— 参考 Spring Boot 实现
随着 微服务 的流行,相比较以前一个大型应用程序搞定所有需求,我们现在更倾向于把大型应用程序切分成多个微服务,服务之间通过 RPC 调用.微服务架构的好处非常多,例如稳定的服务变化较少,不会被非稳定服 ...
随机推荐
- svn部署项目
svn部署项目 在svn服务器上文件夹拷入项目文件~然后直接检出文件夹~即可
- NetCore版RPC框架NewLife.ApiServer
微服务和消息队列的基础都是RPC框架,比较有名的有WCF.gRPC.Dubbo等,我们的NewLife.ApiServer建立在网络库NewLife.Net之上,支持.Net Core,追求轻量级和高 ...
- JVM GC-----垃圾回收算法
说到Java,一定绕不开GC,尽管不是Java首创的,但Java一定是使用GC的代表.GC就是垃圾回收,更直接点说就是内存回收.是对内存进行整理,从而使内存的使用尽可能大的被复用. 一直想好好写一篇关 ...
- 一些常用的linux命令(2)
参考:http://www.cnblogs.com/laov/p/3541414.html 系统管理命令 stat 显示指定文件的详细信息,比ls更详细 who ...
- jmeter接口测试报java.net.SocketException: Socket closed错误。
如题,jmeter报出java.net.SocketException: Socket closed,我查询了下,服务器是正常的,可以返回数据,基本确定问题出在我这边jmeter.查询原因,看到有人说 ...
- struct和union的区别
1)union是几个不同类型的变量共占一段内存(相互覆盖):struct是把不同类型的数据组合成一个整体 2)对齐方式略有区别:union不需要+,只需要拿出对齐后的最长 structure unio ...
- PAT1083:List Grades
1083. List Grades (25) 时间限制 400 ms 内存限制 65536 kB 代码长度限制 16000 B 判题程序 Standard 作者 CHEN, Yue Given a l ...
- Python实现批量新建SecureCRT Session
最近因为工作需要,我需要在ssh的时候保存几千台网关的session,工作量相当大(也就是ssh的时候需要记住用户名和密码,然后还要再session选项中录入enable密码,相当繁琐),而且设备的用 ...
- spring boot -Properties & configuration
72. Properties & configuration72.1 Automatically expand properties at build timeRather than hard ...
- HTTPS加密原理
http(超文本传输协议) 一种属于应用层的协议 缺点: 通信使用明文(不加密),内容可能会被窃听 不验证通信方的身份,因此有可能遭遇伪装 无法证明报文的完整性,所以有可能已遭篡改 优点: 传输速度快 ...