Scrapy-redis 组件
分布式爬虫
概念
所谓分布式, 多个程序同时对一个任务进行操作
一分多的高效率的任务进行方式
简单说明
一个 10GB 的爬虫任务, 交给10台服务器进行同时爬取
对比单服务器无论怎么优化都是 10倍的效率, 但是成本高
需要硬件环境支持 ( 带宽, 服务器设备等 )
多态主机共享一个爬取队列即为分布式爬虫
物理拓扑
/ -------------服务器 2
| / ------------------服务器3
服务器1 ----------- 服务器 4
| \-------------------服务器5
\-------------服务器6
服务器 1 负责 url队列的分发 ( 本质上是个 redis 数据库 )
其他服务器可能分布在全国各地, 分别和服务器1 建立联系,
通过 服务器 1 的共享队列进行爬取任务的获取
为什么使用 redis
redis 速度快
redis 非关系型数据库, redis 中的集合, 存储每个 request 的指纹
Scrapy 实现分布式
Scrapy 原生是不支持分布式爬虫
Scrapy 的爬取队列是放在调度器中的
因此只要能够实现调度器的共享即可完成爬虫任务的共享
即重写 scrapy 的调度器, ( 别人造的轮子又大又圆 scrapy_redis )
scrapy-redis
简介
scrapy-redis是scrapy框架基于redis数据库的组件,用于scrapy项目的分布式开发和部署。
特征
分布式爬取
可以启动多个spider工程,相互之间共享单个redis的requests队列。最适合广泛的多个域名网站的内容爬取。
分布式数据处理
爬取到的scrapy的item数据可以推入到redis队列中
这意味着你可以根据需求启动尽可能多的处理程序来共享item的队列,进行item数据持久化处理
Scrapy即插即用组件
Scheduler调度器 + Duplication复制 过滤器,Item Pipeline,基本spider
三大作用
去重规则的校验
实现调度器对请求的调配
定制起始URL
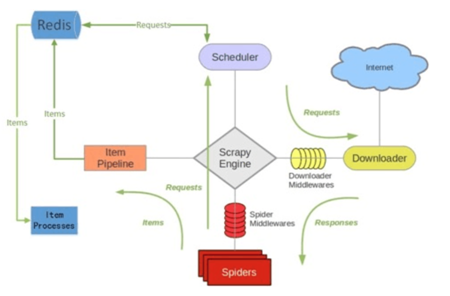
scrapy-redis架构
安装
pip install scrapy-redis
使用
所有可选的配置, 未注释表示必选设置
# 替换调度器, 启用 redis 中存储的请求调度队列
SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 替换过滤器, 所有的通向 redis 的爬虫都需要使用此过滤器 ( 去重机制 )
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 默认的 序列化方式为 pickle, 可以更改为 json 或者 msgpack
# SCHEDULER_SERIALIZER = "scrapy_redis.picklecompat" # 是否云讯断点续爬 ( 爬取完成后是否清楚指纹 )
# SCHEDULER_PERSIST = True # 默认使用优先级队列(默认),其他:PriorityQueue(有序集合),FifoQueue(列表)、LifoQueue(列表)
# SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue'
# SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.FifoQueue' # 广度优先 基于队列 先进先出
# SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.LifoQueue' # 深度优先 基于栈 后进先出 # SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue' 的时候才有用
# DEPTH_PRIORITY = 1 # 广度优先
# DEPTH_PRIORITY = -1 # 深度优先 后进先出 # 初次启动的时候的阻塞时间 ( 仅适用于队列类为SpiderQueue或SpiderStack时 )
# SCHEDULER_IDLE_BEFORE_CLOSE = 10 # 替换持久化工具为 scrapy-redis 的
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 300
} # The item pipeline serializes and stores the items in this redis key.
# REDIS_ITEMS_KEY = '%(spider)s:items' # The items serializer is by default ScrapyJSONEncoder. You can use any
# importable path to a callable object.
# REDIS_ITEMS_SERIALIZER = 'json.dumps' # 指定连接 redis 的主机和端口号
# REDIS_HOST = 'localhost'
# REDIS_PORT = 6379 # Specify the full Redis URL for connecting (optional).
# If set, this takes precedence over the REDIS_HOST and REDIS_PORT settings.
# REDIS_URL = 'redis://user:pass@hostname:9001' # Custom redis client parameters (i.e.: socket timeout, etc.)
# REDIS_PARAMS = {}
# Use custom redis client class.
# REDIS_PARAMS['redis_cls'] = 'myproject.RedisClient' # If True, it uses redis' ``SPOP`` operation. You have to use the ``SADD``
# command to add URLs to the redis queue. This could be useful if you
# want to avoid duplicates in your start urls list and the order of
# processing does not matter.
# REDIS_START_URLS_AS_SET = False # Default start urls key for RedisSpider and RedisCrawlSpider.
# REDIS_START_URLS_KEY = '%(name)s:start_urls' # Use other encoding than utf-8 for redis.
# REDIS_ENCODING = 'latin1'
去重
scrapy-redis 去重原理
redis的集合有去重属性,在保存重复的值的时候返回值会是 0
完全自定义实现去重
from scrapy.dupefilter import BaseDupeFilter
import redis
from scrapy.utils.request import request_fingerprint class DupFilter(BaseDupeFilter):
def __init__(self):
self.conn = redis.Redis(host='140.143.227.206',port=8888,password='beta') def request_seen(self, request):
"""
检测当前请求是否已经被访问过
:param request:
:return: True表示已经访问过;False表示未访问过
"""
fid = request_fingerprint(request)
result = self.conn.sadd('visited_urls', fid)
if result == 1:
return False
return True
使用 scrapy-redis 去重
# 直接加了配置就生效。但是是基于时间戳的,时间戳变了就会失效很不实用
################ scrapy redis连接 #################### REDIS_HOST = '127.0.0.1' # 主机名
REDIS_PORT = 6379 # 端口
REDIS_PARAMS = {'password':'yangtuo'} # Redis连接参数,比如密码
# 默认:REDIS_PARAMS = {'socket_timeout': 30,'socket_connect_timeout': 30,'retry_on_timeout': True,'encoding': REDIS_ENCODING,})
REDIS_ENCODING = "utf-8" # redis编码类型 默认:'utf-8' # REDIS_URL = 'redis://user:pass@hostname:9001' # 连接URL(优先于以上配置)
################ scrapy redis去重 #################### DUPEFILTER_KEY = 'dupefilter:%(timestamp)s'
# 默认的是按照时间戳的。结果每次请求的时候是会进行去重
# 但是下一次请求时间戳不一致就会清空导致无法去重 因此这里存在优化空间 最好定死 # DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter' # 如果使用 scrapy-redis 的默认去重是会使用这个类来处理去重
DUPEFILTER_CLASS = 'dbd.xxx.RedisDupeFilter' # 这样使用自己自定义的去重规则
优化
from scrapy_redis.dupefilter import RFPDupeFilter
from scrapy_redis.connection import get_redis_from_settings
from scrapy_redis import defaults class RedisDupeFilter(RFPDupeFilter):
@classmethod
def from_settings(cls, settings):
server = get_redis_from_settings(settings)
# key = defaults.DUPEFILTER_KEY % {'timestamp': int(time.time())} # 源码这里是用的时间戳 不断变换导致每次重置
key = defaults.DUPEFILTER_KEY % {'timestamp': 'yangtuo'} # 不要时间戳了,我定死一个固定值
debug = settings.getbool('DUPEFILTER_DEBUG')
return cls(server, key=key, debug=debug)
调度器
在 settings.py 中进行配置
SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 默认使用优先级队列(默认),其他:PriorityQueue(有序集合),FifoQueue(列表)、LifoQueue(列表)
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue'
# SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.FifoQueue' # 广度优先 基于队列 先进先出
# SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.LifoQueue' # 深度优先 基于栈 后进先出 # SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue' 的时候才有用
DEPTH_PRIORITY = 1 # 广度优先
# DEPTH_PRIORITY = -1 # 深度优先 后进先出 SCHEDULER_QUEUE_KEY = '%(spider)s:requests' # 调度器中请求存放在redis中的key SCHEDULER_SERIALIZER = "scrapy_redis.picklecompat" # 对保存到redis中的数据进行序列化,默认使用pickle SCHEDULER_PERSIST = False # 是否在关闭时候保留原来的调度器和去重记录,True=保留,False=清空
SCHEDULER_FLUSH_ON_START = True # 是否在开始之前清空 调度器和去重记录,True=清空,False=不清空
# SCHEDULER_IDLE_BEFORE_CLOSE = 10 # 去调度器中获取数据时,如果为空,最多等待时间(最后没数据,未获取到)。 SCHEDULER_DUPEFILTER_KEY = '%(spider)s:dupefilter' # 去重规则,在redis中保存时对应的key # 优先使用 DUPEFILTER_CLASS,如果没有就是用 SCHEDULER_DUPEFILTER_CLASS
SCHEDULER_DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter' # 去重规则对应处理的类
起始url
爬虫文件
import scrapy
from scrapy.http import Request
import scrapy_redis
from scrapy_redis.spiders import RedisSpider class ChoutiSpider(RedisSpider): # 继承改为 用 RedisSpider
name = 'chouti'
allowed_domains = ['chouti.com'] # def start_requests(self): # 不再需要写 start_requests 了
# yield Request(url='https://dig.chouti.com',callback=self.parse) def parse(self, response):
print(response)
另写一个脚本文件
import redis conn = redis.Redis(host='127.0.0.1',port=6379,password='yangtuo') # 通过往 redis 里面加数据从而控制爬虫的执行
# 如果没有数据就会夯住。一旦有数据就爬取,可以
conn.lpush('chouti:start_urls','https://dig.chouti.com/r/pic/hot/1')
代码流程
1.启动
scrapy crawl chouti --nolog
2.实例化调度器对象
找到 SCHEDULER = "scrapy_redis.scheduler.Scheduler" 配置并实例化调度器对象
- 执行Scheduler.from_crawler
- 执行Scheduler.from_settings
- 读取配置文件:
SCHEDULER_PERSIST # 是否在关闭时候保留原来的调度器和去重记录,True=保留,False=清空
SCHEDULER_FLUSH_ON_START # 是否在开始之前清空 调度器和去重记录,True=清空,False=不清空
SCHEDULER_IDLE_BEFORE_CLOSE # 去调度器中获取数据时,如果为空,最多等待时间(最后没数据,未获取到)
- 读取配置文件:
SCHEDULER_QUEUE_KEY # %(spider)s:requests # 读取保存在 redis 中存放爬虫名字的 name 的值
SCHEDULER_QUEUE_CLASS # scrapy_redis.queue.FifoQueue # 读取要使用的队列方式
SCHEDULER_DUPEFILTER_KEY # '%(spider)s:dupefilter' # 读取保存在 redis 中存放爬虫去重规则名字的 key 的值
DUPEFILTER_CLASS # 'scrapy_redis.dupefilter.RFPDupeFilter' # 读取去重的配置的类
SCHEDULER_SERIALIZER # "scrapy_redis.picklecompat" # 读取保存在 redis 的时候用的序列化方式
- 读取配置文件:
REDIS_HOST = '140.143.227.206' # 主机名
REDIS_PORT = 8888 # 端口
REDIS_PARAMS = {'password':'beta'} # Redis连接参数 默认:REDIS_PARAMS = {'socket_timeout': 30,'socket_connect_timeout': 30,'retry_on_timeout': True,'encoding': REDIS_ENCODING,})
REDIS_ENCODING = "utf-8"
- 实例Scheduler对象
3. 爬虫开始执行起始URL
- 调用 scheduler.enqueue_requests()
def enqueue_request(self, request):
# 请求是否需要过滤? dont_filter = False 表示过滤
# 去重规则中是否已经有?(是否已经访问过,如果未访问添加到去重记录中。)
# 要求过滤,且去重记录里面有就变表示访问过了
if not request.dont_filter and self.df.request_seen(request):
self.df.log(request, self.spider)
return False # 已经访问过就不要再访问了 if self.stats:
self.stats.inc_value('scheduler/enqueued/redis', spider=self.spider)
# print('未访问过,添加到调度器', request)
self.queue.push(request)
return True
4. 下载器去调度器中获取任务,去下载
- 调用 scheduler.next_requests()
def next_request(self):
block_pop_timeout = self.idle_before_close
request = self.queue.pop(block_pop_timeout)
if request and self.stats:
self.stats.inc_value('scheduler/dequeued/redis', spider=self.spider)
return request
总结几个问题
1. 什么是深度优先?什么是广度优先?
深度优先 :基于层级先进入到最深层级进行处理全部后再往上层级处理
广度优先 :基于从第一层级开始,每次层级处理之后进入下一层及处理
2. scrapy中如何实现深度和广度优先?
先进先出,广度优先 FifoQueue
后进先出,深度优先 LifoQueue
优先级队列:
DEPTH_PRIORITY = 1 # 广度优先
DEPTH_PRIORITY = -1 # 深度优先
3. scrapy中 调度器 和 队列 和 dupefilter 的关系?
调度器,调配添加或获取那个request.
队列,存放request。
dupefilter,访问记录。
调度器拿到一个 request 要先去 dupefilter 里面看下有没有存在
如果存在就直接丢了
如果不存在才可以放在队列中
然后队列要基于自己的类型来进行相应规则的存放
打比方来说:
调度器 货车司机
dupefilter 仓库门卫
队列 仓库
司机要往仓库放货。先问门卫
门卫说里面有货了不让就没法放
门卫说可以才可以放
放货的时候仓库要按照自己的规则放货
司机要拉货 仓库就基于自己的规则直接给司机就行了
示例 - 腾讯招聘分布式爬虫
流程剖析
使用 scrapy-redis 配合 mongoDB 的分布式爬虫
代码
items.py
import scrapy class TencentItem(scrapy.Item):
# define the fields for your item here like:
zh_name = scrapy.Field()
zh_type = scrapy.Field()
post_id = scrapy.Field()
duty = scrapy.Field()
require = scrapy.Field()
settings.py
BOT_NAME = 'Tencent' SPIDER_MODULES = ['Tencent.spiders']
NEWSPIDER_MODULE = 'Tencent.spiders' # Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0' # Obey robots.txt rules
ROBOTSTXT_OBEY = False
# 使用scrapy_redis的调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 使用scrapy_redis的去重机制
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 爬取完成后是否清除请求指纹
SCHEDULER_PERSIST = True
# 'scrapy_redis.pipelines.RedisPipeline': 200
REDIS_HOST = '172.40.91.129'
REDIS_PORT = 6379 ITEM_PIPELINES = {
'Tencent.pipelines.TencentPipeline': 300,
# 'scrapy_redis.pipelines.RedisPipeline': 200 # redis 的开启这个
'Tencent.pipelines.TencentMongoPipeline': 200,
}
pipline.py
import pymongo class TencentPipeline(object):
def process_item(self, item, spider):
print(dict(item))
return item class TencentMongoPipeline(object):
def open_spider(self, spider):
conn = pymongo.MongoClient('localhost',27017)
db = conn['tencent']
self.myset = db['job'] def process_item(self, item, spider):
self.myset.insert_one(dict(item))
spider.py
# -*- coding: utf-8 -*-
import scrapy
import json
from ..items import TencentItem class TencentSpider(scrapy.Spider):
name = 'tencent'
allowed_domains = ['tencent.com']
start_urls = [
'https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1557114143837&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex=1&pageSize=10&language=zh-cn&area=cn'] def parse(self, response):
for page_index in range(1, 200):
url = 'https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1557114143837&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex=%s&pageSize=10&language=zh-cn&area=cn' % str(
page_index)
yield scrapy.Request(
url=url,
callback=self.parse_one_page
) # 一级页面解析
def parse_one_page(self, response):
html = json.loads(response.text) for h in html['Data']['Posts']:
item = TencentItem() item['zh_name'] = h['RecruitPostName']
item['zh_type'] = h['LocationName']
# 一级页面获取PostId,详情页URL需要此参数
item['post_id'] = h['PostId']
# 想办法获取到职位要求和职责,F12抓包,抓到地址
two_url = 'https://careers.tencent.com/tencentcareer/api/post/ByPostId?timestamp=1557122746678&postId=%s&language=zh-cn' % \
item['post_id'] yield scrapy.Request(
url=two_url,
meta={'item': item},
callback=self.parse_two_page
) def parse_two_page(self, response):
item = response.meta['item']
html = json.loads(response.text)
# 职责
item['duty'] = html['Data']['Responsibility']
# 要求
item['require'] = html['Data']['Requirement'] yield item
Scrapy-redis 组件的更多相关文章
- Scrapy+redis实现分布式爬虫
概述 什么是分布式爬虫 需要搭建一个由n台电脑组成的机群,然后在每一台电脑中执行同一组程序,让其对同一网络资源进行联合且分布的数据爬取. 原生Scrapy无法实现分布式的原因 原生Scrapy中调度器 ...
- scrapy 基础组件专题(八):scrapy-redis 框架分析
scrapy-redis简介 scrapy-redis是scrapy框架基于redis数据库的组件,用于scrapy项目的分布式开发和部署. 有如下特征: 分布式爬取 您可以启动多个spider工 ...
- 基于async/non-blocking高性能redis组件库BeetleX.Redis
BeetleX.Redis是基于async/non-blocking模式实现的高性能redis组件库,组件支持redis基础指令集,并封装更简便的List,Hashset和Subscribe操作.除了 ...
- Node.js与Sails~redis组件的使用
有段时间没写关于NodeJs的文章了,今天也是为了解决高并发的问题,而想起了这个东西,IIS的站点在并发量达到200时有了一个瓶颈,于是想到了这个对高并发支持比较好的框架,nodeJs在我之前写出一些 ...
- laravel集成workerman,使用异步mysql,redis组件时,报错EventBaseConfig::FEATURE_FDS not supported on Windows
由于laravel项目中集成了workerman,因业务需要,需要使用异步的mysql和redis组件. composer require react/mysql composer require c ...
- 基于Python,scrapy,redis的分布式爬虫实现框架
原文 http://www.xgezhang.com/python_scrapy_redis_crawler.html 爬虫技术,无论是在学术领域,还是在工程领域,都扮演者非常重要的角色.相比于其他 ...
- 新生命Redis组件(.Net Core 开源)
NewLife.Redis 是一个Redis客户端组件,以高性能处理大数据实时计算为目标.Redis协议基础实现Redis/RedisClient位于X组件,本库为扩展实现,主要增加列表结构.哈希结构 ...
- 【分布式架构】--- 基于Redis组件的特性,实现一个分布式限流
分布式---基于Redis进行接口IP限流 场景 为了防止我们的接口被人恶意访问,比如有人通过JMeter工具频繁访问我们的接口,导致接口响应变慢甚至崩溃,所以我们需要对一些特定的接口进行IP限流,即 ...
- scrapy 基础组件专题(九):scrapy-redis 源码分析
下面我们来看看,scrapy-redis的每一个源代码文件都实现了什么功能,最后如何实现分布式的爬虫系统: connection.py 连接得配置文件 defaults.py 默认得配置文件 dupe ...
- scrapy 基础组件专题(七):scrapy 调度器、调度器中间件、自定义调度器
一.调度器 配置 SCHEDULER = 'scrapy.core.scheduler.Scheduler' #表示scrapy包下core文件夹scheduler文件Scheduler类# 可以通过 ...
随机推荐
- Windows Java包环境变量的设置
复制Bin文件所在路径 验证
- 关于MongoDB时间格式转换和时间段聚合统计的用法总结
一 . 背景需求 在日常的业务需求中,我们往往会根据时间段来统计数据.例如,统计每小时的下单量:每天的库存变化,这类信息数据对运营管理很重要. 这类数据统计依赖于各个时间维度,年月日.时分秒都有可能. ...
- Serverless架构
什么是Serverless架构 Servlerless 架构是新兴的架构体系,在Serverless 架构中,开发者无需考虑服务器的问题,计算资源作为服务而不是服务器的概念出现,这样,开发者只需要关注 ...
- Arch Linux安装Firefox 火狐中文版
很多人刚安装好系统之后,刚开始内置的浏览器是火狐的英文版,很多时候因为需要账号同步的原因需要国内版本的火狐浏览器,这个时候我们应该怎么操作呢? 其实也非常的简单 首先我们 输入命令 pacman -S ...
- redis.clients.jedis.exceptions.JedisDataException: ERR invalid DB index
添加redis配置文件, 启动后,调用报错 redis.clients.jedis.exceptions.JedisDataException: ERR invalid DB index ERR i ...
- virtualenvwrapper 虚拟环境的使用 和 python 安装源的更改
virtualenvwrapper 虚拟环境的使用 鉴于virtualenv不便于对虚拟环境集中管理,所以推荐直接使用virtualenvwrapper. virtualenvwrapper提供了一系 ...
- Dockerfile 规范
https://time-track.cn/compile-docker-from-source.html 参考 https://time-track.cn/install-docker-on-ubu ...
- Django-CRM项目学习(一)-admin组件
开始今日份整理 1.admin组件使用 1.1 创建django项目以及开启APP01 略 1.2 创建类 使用django自带的sqlite3的小型文件型的数据库 注:使用sqlite3类型的数据库 ...
- leetcode 5 查找最长的回文子串
给定一个字符串 s,找到 s 中最长的回文子串.你可以假设 s 的最大长度为 1000. 示例 1: 输入: "babad" 输出: "bab" 注意: &qu ...
- [LeetCode] 12,13 整数和罗马数互转
12. 整数转罗马数字 题目链接:https://leetcode-cn.com/problems/integer-to-roman/ 题目描述: 罗马数字包含以下七种字符: I, V, X, L,C ...