caffe 根据txt生成多标签LMDB数据
1. 前提:
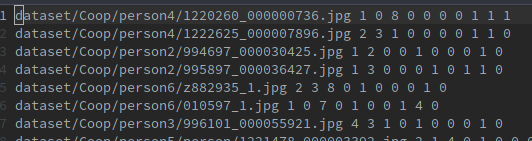
- 已经准备好train.txt, test.txt文件, 格式如下
此处有坑, 如果是windows下生成txt, 换行符为\r\n, 需要替换成 \n才能在linux运行.
可以使用sed -i "s/\s*$//g" filename统一去掉, 具体参考除去文件中显示的^M符号
- 已经编译好了支持多标签的caffe, 具体见多标签caffe重新编译

2. 编辑生成lmdb用的txt2lmdb.sh
以下是我的sh文件:
#!/usr/bin/env sh
# Create the imagenet lmdb inputs
####################################################
# 配置
####################################################
EXAMPLE=/home/zhuoshi/ZSZT/Geoffrey/Person-resnet18/lmdb_data # lmdb存储位置
DATA=/home/zhuoshi/ZSZT/Geoffrey/Person-resnet18/data # txt文件所在文件夹 - 同时也是.txt相对路径的起始点(图片绝对路径=$DATA+txt中相对路径)
CAFFE_HOME=/home/zhuoshi/ZSZT/Geoffrey/caffe/caffe-master # caffe的工具库
HEIGHT=256
WIDTH=256
####################################################
# 处理train
####################################################
echo "Creating train lmdb..."
TRAIN_PATH=$EXAMPLE/img_train_lmdb
# 如果存在,删除原数据
if [ ! -d "$TRAIN_PATH/" ];then
echo "文件不存在"
mkdir -p $TRAIN_PATH/
else
echo "$TRAIN_PATH文件夹已存在"
rm -rf $TRAIN_PATH/
# mkdir -p $TRAIN_PATH/
fi
# 生成lmdb
$CAFFE_HOME/build/tools/convert_imageset --shuffle --resize_height=$HEIGHT --resize_width=$WIDTH $DATA/ $DATA/train.txt $TRAIN_PATH #
echo "Creating train lmdb Done!, Create mean.binaryproto..."
# # 计算图片均值
$CAFFE_HOME/build/tools/compute_image_mean $TRAIN_PATH/ $TRAIN_PATH/mean.binaryproto
echo "train Done!"
####################################################
# 处理test
####################################################
echo "Creating test lmdb ..."
TEST_PATH=$EXAMPLE/img_test_lmdb
# 如果存在,删除原数据
if [ ! -d "$TEST_PATH/" ];then
echo "文件不存在"
mkdir $TEST_PATH
else
echo "$TEST_PATH文件夹已存在"
rm -rf $TEST_PATH/
# mkdir $TEST_PATH/
fi
# 生成lmdb
$CAFFE_HOME/build/tools/convert_imageset --shuffle --resize_height=256 --resize_width=256 $DATA/ $DATA/test.txt $TEST_PATH #
echo "Creating test lmdb Done!, Create mean.binaryproto..."
# # 计算图片均值
$CAFFE_HOME/build/tools/compute_image_mean $TEST_PATH/ $TEST_PATH/mean.binaryproto
echo "test Done!"
####################################################
echo "Done."
其中:
- EXAMPLE, 把生成的lmdb存储到什么位置
- DATA .txt存放绝对路径, 同时也是父目录, 即图片绝对路径=$DATA+txt中相对路径:
我的txt路径:
txt图片相对路径:
3. 运行
执行`sh txt2lmdb.sh`, (txt2lmdb.sh为脚本所在路径)
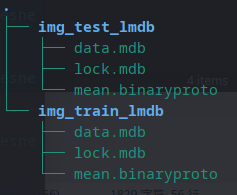
脚本会在$EXAMPLE下生成如下结果:
下面记录一下caffe自带的均值转换工具compute_image_mean.cpp参数:
$CAFFE_HOME/build/tools/compute_image_mean $TEST_PATH/ $TEST_PATH/mean.binaryproto
带两个参数:
- 第一个参数:$TEST_PATH/, 表示需要计算均值的数据,格式为lmdb的训练数据。
- 第二个参数:$TEST_PATH/mean.binaryproto, 计算出来的结果保存文件。
( 图片减去均值后,再进行训练和测试,会提高速度和精度。)
caffe 根据txt生成多标签LMDB数据的更多相关文章
- python 操作txt 生成新的文本数据
name: Jack ; salary: 12000 name :Mike ; salary: 12300 name: Luk ; salary: 10030 name :Tim ; salary: ...
- caffe读取多标签的lmdb数据
问题描述: lmdb文件支持数据+标签的形式,但是却只能写入一个标签,引入多标签的解决方法有很多,这儿详细说一下我的办法:制作多个data数据,分别加入一个标签.我的方法只适用于标签数量较少的情况,标 ...
- Caffe系列2——Windows10制作LMDB数据详细过程(手把手教你制作LMDB)
Windows10制作LMDB详细教程 原创不易,转载请注明出处:https://www.cnblogs.com/xiaoboge/p/10678658.html 摘要: 当我们在使用Caffe做深度 ...
- 【应用】:shell crontab定时生成oracle表的数据到txt文件,并上传到ftp
一.本人环境描述 1.oracle服务端装在win7 32位上,oracle版本为10.2.0.1.0 2.Linux为centos6.5 32位,安装在Oracle VM Vir ...
- Java-读取txt生成excel
本段代码的目的是从txt文本中读取相应格式的数据,然后写入到对应格式的excel文档中 在敲本段代码的时候,也学习了一些其它知识点,如下: 1.byte[] b_charset= String.get ...
- struts2标签库----数据标签详解
上篇文章我们介绍struts2标签库中的控制标签的基本使用和部分原理,本篇文章接着了解下标签库中有关数据标签的使用和原理.主要涉及以下数据标签: action标签:用于在视图页面跳转到一个Action ...
- caffe 用faster rcnn 训练自己的数据 遇到的问题
1 . 怎么处理那些pyx和.c .h文件 在lib下有一些文件为.pyx文件,遇到不能import可以cython 那个文件,然后把lib文件夹重新make一下. 遇到.c 和 .h一样的操作. 2 ...
- Djanog|requirements.txt生成
Django | requirement.txt 生成 pip django 1 pip 通常我们熟悉使用的都是 pip, 这个工具确实方便项目管理依赖包.当想把当前项目依赖的包的名称和版本导入指 ...
- 动态生成li标签,并设置点击事件
今天要解释的是如下界面 主要实现了: 1.模拟后台的json数据,动态生成li标签 2.导航栏的下划线 3.给li标签右边设置图片 4.动态生成的li标签,设置选中的li的点 ...
随机推荐
- GIT-windows系统下Gitblit的使用方式
GIT-windows系统下Gitblit的正确打开方式 1. 打开页面. 在配置好Gitblit后,打开可视化界面. 2. 创建用户 点击右上角添加用户,进入明细页面,填写常规信息. 创建用户(账号 ...
- 如何设置Maven代理
1.公司的网络走的是代理,那么如何设置maven下载jar包时也走代理呢. 根据百度出来的两篇文章 设置了一下,但是还是报错. Plugin org.apache.maven.plugins:mave ...
- 【转】TEA、XTEA、XXTEA加密解密算法(C语言实现)
ref : https://blog.csdn.net/gsls200808/article/details/48243019 在密码学中,微型加密算法(Tiny Encryption Algorit ...
- centos6.5 配置静态IP
1.修改网卡配置 编辑:vi /etc/sysconfig/network-scripts/ifcfg-eth0 DEVICE=eth0 BOOTPROTO=static HWADDR=08:00:2 ...
- js较深入的知识点
浏览器渲染过程是怎样的?重绘重排是什么?如何避免过多的重绘重排? 将html解析为dom树; 将css解析为cssom; 结合DOM树和CSSOM树,生成一棵渲染树(Render Tree); 生成布 ...
- 有效使用django的queset
转载自https://www.oschina.net/translate/django-querysets 对象关系映射 (ORM) 使得与SQL数据库交互更为简单,不过也被认为效率不高,比原始的SQ ...
- [笔记]猿计划(WEB安全工程师养成之路系列教程):03HTML基础标签
1.<!DOCTYPE>声明 <!DOCTYPE> 不是 HTML 标签.它为浏览器提供一项信息(声明),即 HTML 是用什么版本编写的. 2.HTML不区分大小写 3.标签 ...
- 20175333曹雅坤 实验二 Java面向对象程序设计
实验二 Java面向对象程序设计 实验内容 1. 初步掌握单元测试和TDD 2. 理解并掌握面向对象三要素:封装.继承.多态 3. 初步掌握UML建模 4. 熟悉S.O.L.I.D原则 5. 了解设计 ...
- UGUI打字机效果文本组件
using System.Collections; using System.Collections.Generic; using UnityEngine; using UnityEngine.UI; ...
- [SDOI2009]HH的项链-树状数组/线段树
树状数组: #include<bits/stdc++.h> using namespace std; ; int id[maxn],tree[maxn],vis[maxn],num[max ...