K-means算法性能评估及其优化
1、 SSE误差平方和(Sum of Square due to Error):
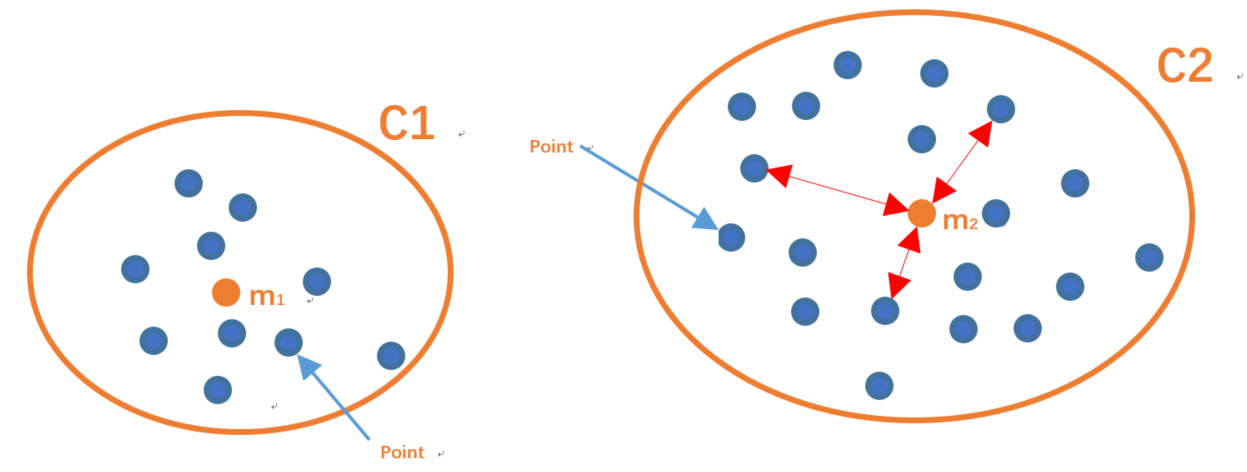
聚类情况:
计算公式:
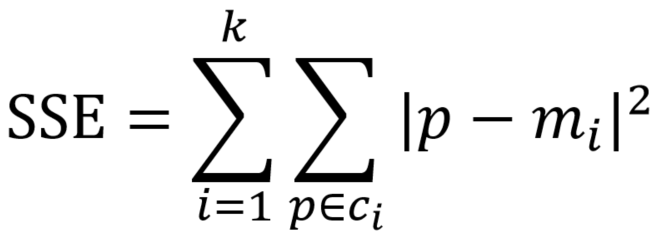
注:SSE参数计算的内容为当前迭代得到的中心位置到各自中心点簇的欧式距离总和,这个值越小表示当前的分类效果越好!
参数描述:
- P表示点位置(x,y)。
- Mi为中心点的位置。
- SSE表示了,当前的分类情况的中心点到自身分类簇的点的位置的总和。
使用方法:
在聚类算法迭代的过程中,我们通过计算当前得到的中心点情况下的SSE值来评估现在的分类效果,如果SSE值在某次迭代之后大大减小就说明聚类过程基本完成,不需要太多次的迭代了,
Code:
# K-means Algorithm processing the point
Point_Total = 100 # 某一种类型的总点数
Error_Threshold = 0.1 Point_A = (4, 3) # 高斯二维分布中心点
Point_S_A = (np.random.normal(Point_A[0], 1, Point_Total),np.random.normal(Point_A[1], 1, Point_Total)) # 构造高斯二维分布散点 Point_B = (-3,2) # 高斯二维分布中心点
Point_S_B = (np.random.normal(Point_B[0], 1, Point_Total),np.random.normal(Point_B[1], 1, Point_Total)) # 构造高斯二维分布散点 Point_O = np.hstack((Point_S_A,Point_S_B)) # 所有的点合并在一起 Origin_A = [Point_O[0][0],Point_O[1][0]] # 取得K-means算法的起始分类点
Origin_B = [Point_O[0][20],Point_O[1][20]] # 设置K-means算法的起始分类点 plt.figure("实时分类") # 创建新得显示窗口
plt.ion() # 持续刷新当前窗口的内容,不需要使用plt.show()函数
plt.scatter(Point_O[0],Point_O[1],c='k') # 所有的初始数据显示为黑色
plt.scatter(Origin_A[0],Origin_A[1],c='b',marker='D') # 显示第一类分类点的位置
plt.scatter(Origin_B[0],Origin_B[1],c='r',marker='*') # 显示第二类分类点的位置 Status_A = False # 设置A类别分类未完成False
Status_B = False # 设置B类别分类未完成False CiSum_List = []
while not Status_A and not Status_B: # 开始分类
Class_A = [] # 分类结果保存空间
Class_B = [] # 分类结果保存空间
print("Seperating the point...")
CASum = 0
CBSum = 0
for i in range(Point_Total*2): # 开始计算分类点到所有点的欧式距离(注意只需要使用平方和即可,不需要sqrt浪费时间)
d_A = np.power(Origin_A[0]-Point_O[0][i], 2) + np.power(Origin_A[1]-Point_O[1][i], 2) # 计算距离
d_B = np.power(Origin_B[0]-Point_O[0][i], 2) + np.power(Origin_B[1]-Point_O[1][i], 2) # 计算距离
if d_A > d_B:
Class_B.append((Point_O[0][i],Point_O[1][i])) # 将距离当前点较近的数据点包含在自己的空间中
plt.scatter(Point_O[0][i],Point_O[1][i],c='r') # 更新新的点的颜色
CBSum += d_B
else:
Class_A.append((Point_O[0][i],Point_O[1][i])) # 将距离当前点较近的数据点包含在自己的空间中
plt.scatter(Point_O[0][i],Point_O[1][i],c='b') # 更新新的点的颜色
CASum =+ d_A
plt.pause(0.08) # 显示暂停0.08s CiSum = CASum + CBSum
CiSum_List.append(CiSum) # 统计计算SSE的值 A_Shape = np.shape(Class_A)[0] # 取得当前分类为A集合的点的总数
B_Shape = np.shape(Class_B)[0] # 取得当前分类为B集合的点的总数
Temp_x = 0
Temp_y = 0
for p in Class_A: # 计算A集合的质心
Temp_x += p[0]
Temp_y += p[1]
error_x = np.abs(Origin_A[0] - Temp_x/A_Shape) # 求平均得到重心-质心
error_y = np.abs(Origin_A[1] - Temp_y/A_Shape)
print("The error Of A:(",error_x,",",error_y,")") # 显示当前位置和质心的误差
if error_x < Error_Threshold and error_y < Error_Threshold:
Status_A = True # 误差满足设定的误差阈值范围,将A集合的状态设置为OK-True
else:
Origin_A[0] = Temp_x/A_Shape # 求平均得到重心-质心
Origin_A[1] = Temp_y/A_Shape
plt.scatter(Origin_A[0],Origin_A[1],c='g',marker='*') # the Map-A
print("Get New Center Of A:(",Origin_A[0],",",Origin_A[1],")") # 显示中心坐标点 Temp_x = 0
Temp_y = 0
for p in Class_B: # 计算B集合的质心
Temp_x += p[0]
Temp_y += p[1]
error_x = np.abs(Origin_B[0] - Temp_x/B_Shape) # 求平均得到重心-质心
error_y = np.abs(Origin_B[1] - Temp_y/B_Shape)
print("The error Of B:(",error_x,",",error_y,")")
if error_x < Error_Threshold and error_y < Error_Threshold:
Status_B = True # 误差满足设定的误差阈值范围,将B集合的状态设置为OK-True
else:
Origin_B[0] = Temp_x/B_Shape # 求平均得到重心-质心
Origin_B[1] = Temp_y/B_Shape
plt.scatter(Origin_B[0],Origin_B[1],c='y',marker='x') # the Map-B
print("Get New Center Of B:(",Origin_B[0],",",Origin_B[1],")") # 显示中心坐标点 print("Finished the divide!")
print(CiSum_List) # 统计结果
plt.figure("真实分类")
plt.scatter(Point_S_A[0],Point_S_A[1]) # The Map-A
plt.scatter(Point_S_B[0],Point_S_B[1]) # The Map-A
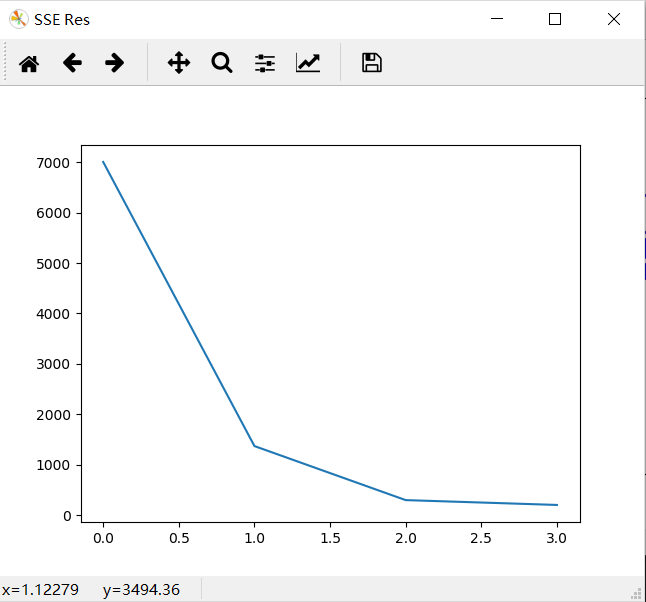
plt.show() plt.figure("SSE Res")
plt.plot(CiSum_List) # 绘制SSE结果图 plt.pause(15)
plt.show()
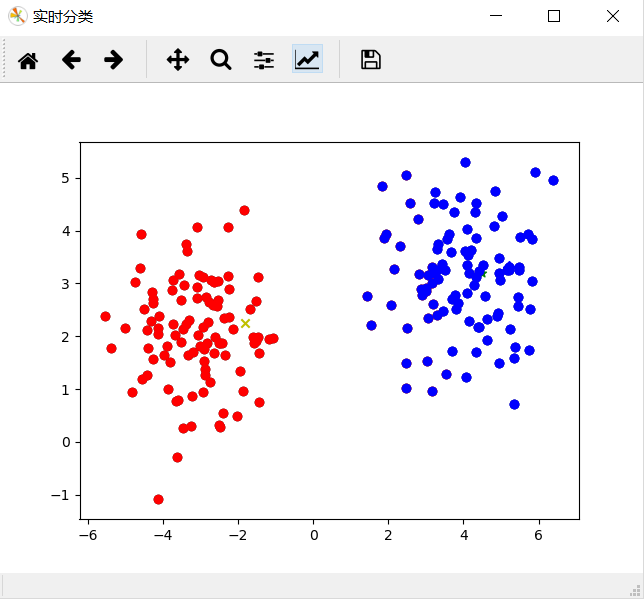
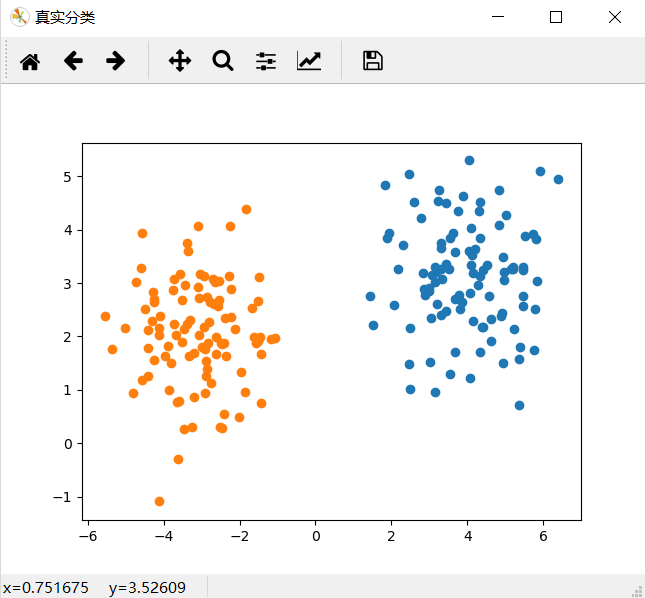
结果:
2、 SC系数(Silhouette Cofficient)轮廓系数法:
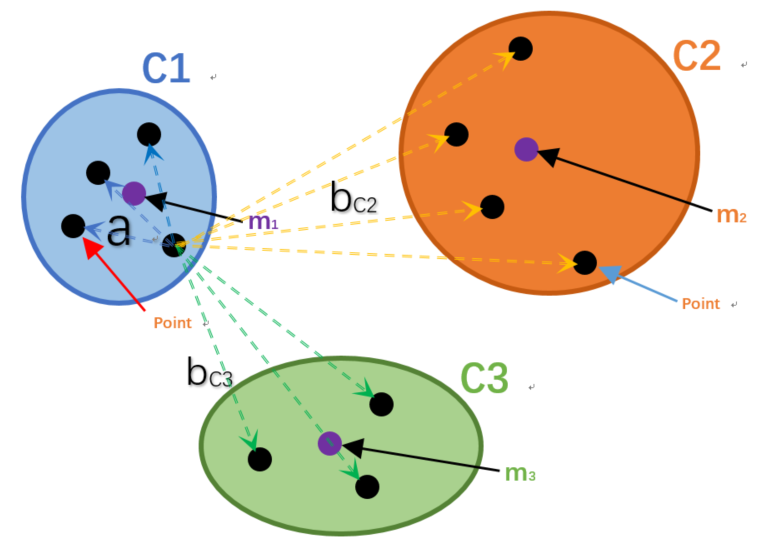
评估标准描述:结合了聚类的凝聚度(Cohesion)和分离度(Separation),用于评估聚类算法的效果。
参数描述:
- a表示C1簇中的某一个样本点Xi到自身簇中其他样本点的距离总和的平均值。
- bC2表示样本点Xi 到C2簇中所有样本点的距离总和的平均值。
- bC3表示样本点Xi 到C3簇中所有样本点的距离总和的平均值。
- 我们定义b = min(bC2 ,bC3)
计算公式:
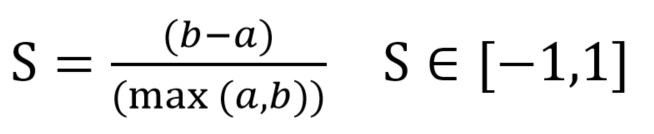
- a:样本Xi到同一簇内其他点不相似程度的平均值
- b:样本Xi到其他簇的平均不相似程度的最小值
使用方法:
每次聚类之后,每一个样本点都会得到一个轮廓系数,当S的取值越靠近1,当前点与周围簇距离较远,结果非常好。
当S的取值为0,说明当前点可能处在两个簇的边界上。
当S的取值为负数时,可能这个点呗误分了。
求出所有样本点的轮廓系数之后再求平均值就得到了平均轮廓系数,平均轮廓系数越大,簇内样本距离越近,簇间样本距离越远,聚类效果越好。
Code:
3、CH系数(Calinski Harabasz Index)轮廓系数法:
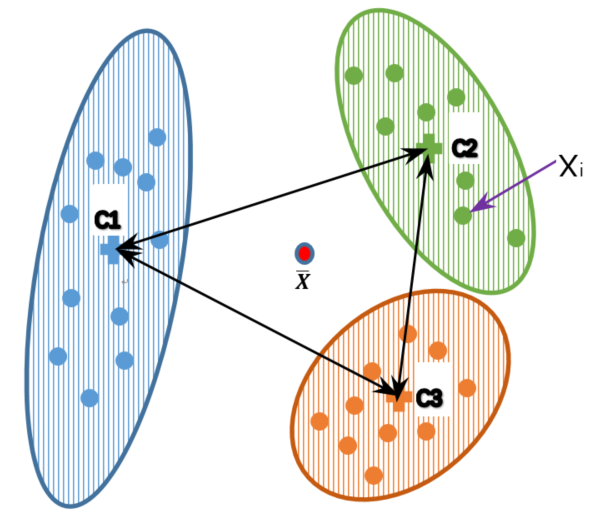
参数描述:
- C1:簇1的中心位置
- C2:簇2的中心位置
- C3:簇3的中心位置
- Xi:簇当中的某一个样本点
- X平均:所有簇当中的样本点的中心位置
计算公式:
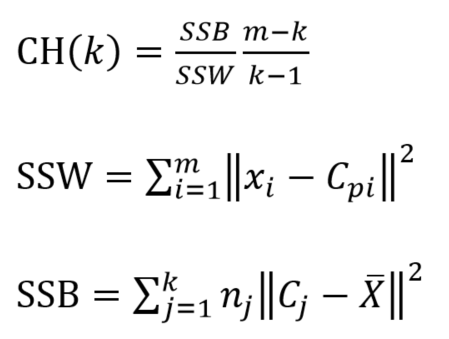

使用方法:
Code:
4、总结:
在我们考量当前的聚类算法的K值选择的问题是,我们会总和汇总上述三种衡量系数来共同确定K值的选择,使得我们选择最好的K值。
如下实例过程,我们来选择合适的K值:
Code:
Result:
分析:
K-means算法性能评估及其优化的更多相关文章
- [转载]Linux服务器性能评估与优化
转载自:Linux服务器性能评估与优化 一.影响Linux服务器性能的因素 1. 操作系统级 CPU 内存 磁盘I/O带宽 网络I/O带宽 2. 程序应用级 二.系统性能评估标准 影响性 ...
- Linux服务器性能评估与优化--转
http://www.itlearner.com/article/4553 一.影响Linux服务器性能的因素 1. 操作系统级 Ø CPU Ø 内存 Ø 磁盘I/ ...
- Linux服务器性能评估与优化(一)
网络内容总结(感谢原创) 1.前言简介 一.影响Linux服务器性能的因素 1. 操作系统级 性能调优是找出系统瓶颈并消除这些瓶颈的过程. 很多系统管理员认为性能调优仅仅是调整一下 ...
- Linux服务器性能评估与优化
一.影响务器性能因素 影响企业生产环境Linux服务器性能的因素有很多,一般分为两大类,分别为操作系统层级和应用程序级别.如下为各级别影响性能的具体项及性能评估的标准: (1)操作系统级别 内存: C ...
- Linux转发性能评估与优化-转发瓶颈分析与解决方式(补遗)
补遗 关于网络接收的软中断负载均衡,已经有了成熟的方案,可是该方案并不特别适合数据包转发,它对server的小包处理非常好.这就是RPS.我针对RPS做了一个patch.提升了其转发效率. 下面是我转 ...
- Linux转发性能评估与优化(转发瓶颈分析与解决方式)
线速问题 非常多人对这个线速概念存在误解. 觉得所谓线速能力就是路由器/交换机就像一根网线一样. 而这,是不可能的.应该考虑到的一个概念就是延迟. 数据包进入路由器或者交换机,存在一个核心延迟操作,这 ...
- KNN 与 K - Means 算法比较
KNN K-Means 1.分类算法 聚类算法 2.监督学习 非监督学习 3.数据类型:喂给它的数据集是带label的数据,已经是完全正确的数据 喂给它的数据集是无label的数据,是杂乱无章的,经过 ...
- Linux服务器性能评估与优化(二)
网络内容总结(感谢原创) 1.Linux内核参数优化 内核参数是用户和系统内核之间交互的一个接口,通过这个接口,用户可以在系统运行的同时动态更新内核配置,而这些内核参数是通过Linux Proc文件系 ...
- Linux服务器性能评估
一.影响Linux服务器性能的因素 1. 操作系统级 CPU 内存 磁盘I/O带宽 网络I/O带宽 2. 程序应用级 二.系统性能评估标准 影响性能因素 影响性能因素 评判标准 好 坏 糟糕 CPU ...
随机推荐
- Springboot集成Spring Batch
Spring官网 (https://spring.io/projects/spring-batch#overview)对Spring Batch的解释: 一个轻量级的.全面的批处理框架,用于开发对企 ...
- BootstrapTable-加载数据
要加载的数据:https://examples.wenzhixin.net.cn/examples/bootstrap_table/data?search=&order=asc&off ...
- ModBus-RTU详解
Modbus 一个工业上常用的通讯协议.一种通讯约定.Modbus协议包括RTU.ASCII.TCP.其中MODBUS-RTU最常用,比较简单,在单片机上很容易实现.虽然RTU比较简单,但是看协议 ...
- Servlet学习笔记(1)
Servlet:Sun公司制订的一种用来扩展Web服务功能的组间规范. 第1部分 C/S和B/S介绍 1 C/S Client Server 客户端 服务器程序: 客户端需要单独开发,用户需要下载并安 ...
- 工作经验-Oracle定时数据备份
Oracle database 11g express edition http://www.oracle.com/technetwork/cn/products/express-edition/do ...
- Python:正则表达式(二):如何使用re.search()返回的匹配对象中的具体内容呢??
在上一篇中讲述了re.seach()会返回一个对象格式的数据,如下:<_sre.SRE_Match object; span=(16, 24), match='${phone}'> 那么问 ...
- 动态渲染页面爬取-Selenium & Splash
模拟浏览器的动机 JS动态渲染的页面不止Ajax一种 很多网页的Ajax接口含有加密参数,分析其规律的成本过高 通过对浏览器运行方式的模拟,我们将做到:可见即可爬 Python中常用的模拟浏览器运行的 ...
- 2018-2019-2 20165234 《网络对抗技术》 Exp4 恶意代码分析
实验四 恶意代码分析 实验目的 1.监控自己系统的运行状态,看有没有可疑的程序在运行. 2.分析一个恶意软件,就分析Exp2或Exp3中生成后门软件:分析工具尽量使用原生指令或sysinternals ...
- Java 多线程 - Java对象头, Monitor
详见: http://www.cnblogs.com/pureEve/p/6421273.html
- 关于 git 本地创建 SSH Key 遇到的一点问题(①file to save the key & ②the authenticity of host...)
背景 由于想测试一下 SSH Key 创建的路径(.ssh 目录路径)对于不同位置 git 项目是否有效. 比如,.ssh 默认在 C:\[users]\[username] 目录下,而项目 proj ...