理解Golang哈希表Map的元素
在上一节中我们介绍了 数组和切片的实现原理,这一节会介绍 Golang 中的另一个集合元素 — 哈希,也就是 Map 的实现原理;哈希表是除了数组之外,最常见的数据结构,几乎所有的语言都会有数组和哈希表这两种集合元素,有的语言将数组实现成列表,有的语言将哈希表称作结构体或者字典,但是它们其实就是两种设计集合元素的思路,数组用于表示一个元素的序列,而哈希表示的是键值对之间映射关系,只是不同语言的叫法和实现稍微有些不同。
概述
哈希表 是一种古老的数据结构,在 1953 年就有人使用拉链法实现了哈希表,它能够根据键(Key)直接访问内存中的存储位置,也就是说我们能够直接通过键找到该键对应的一个值,哈希表名称的来源是因为它使用了哈希函数将一个键映射到一个桶中,这个桶中就可能包含该键对应的值。
哈希函数
哈希表的实现关键在于如何选择哈希函数,哈希函数的选择和在很大程度上能够决定哈希表的读写性能,在理想情况下,哈希函数应该能够将不同键映射到唯一的索引上,但是键集合的数量会远远大于映射的范围,不同的键经过哈希函数的处理应该会返回唯一的值,这要求哈希函数的输出范围大于输入范围,所以在实际使用时,这个理想状态是不可能实现的。

比较实际的方式是让哈希函数的结果能够均匀分布,这样虽然哈希会发生碰撞和冲突,但是我们只需要解决哈希碰撞的问题就可以在工程上去使用这种更实际的方案,结果不均匀的哈希函数会造成更多的冲并带来更差的性能。
在一个使用结果较为均匀的哈希函数中,哈希的增删改查都需要 O(1) 的时间复杂度,但是非常不均匀的哈希函数会导致所有的操作都会占用最差 O(n) 的复杂度,所以在哈希表中使用好的哈希函数是至关重要的。
冲突解决
就像我们之前所提到的,在通常情况下,哈希函数输入的范围一定会远远大于输出的范围,所以我们一定会在使用哈希表的过程中遇到冲突,如果有一个不会出现冲突的完美哈希函数,那么我们其实只需要将所有的值都存储在一个一维的数组中就可以了。
就像上面提到的,这种场景在现实中基本上是不会存在的,我们的哈希函数往往都是不完美的并且输出的范围也都是有限的,这也一定会发生哈希的碰撞,我们就需要使用一些方法解决哈希的碰撞问题,常见的就是开放寻址法和拉链法两种。
开放寻址法
开放寻址法 是一种在哈希表中解决哈希碰撞的方法,这种方法的核心思想是在一维数组对元素进行探测和比较以判断待查找的目标键是否存在于当前的哈希表中,如果我们使用开放寻址法来实现哈希表,那么在初始化哈希表时就会创建一个新的数组,如果当我们向当前『哈希表』写入新的数据时发生了冲突,就会将键值对写入到下一个不为空的位置:
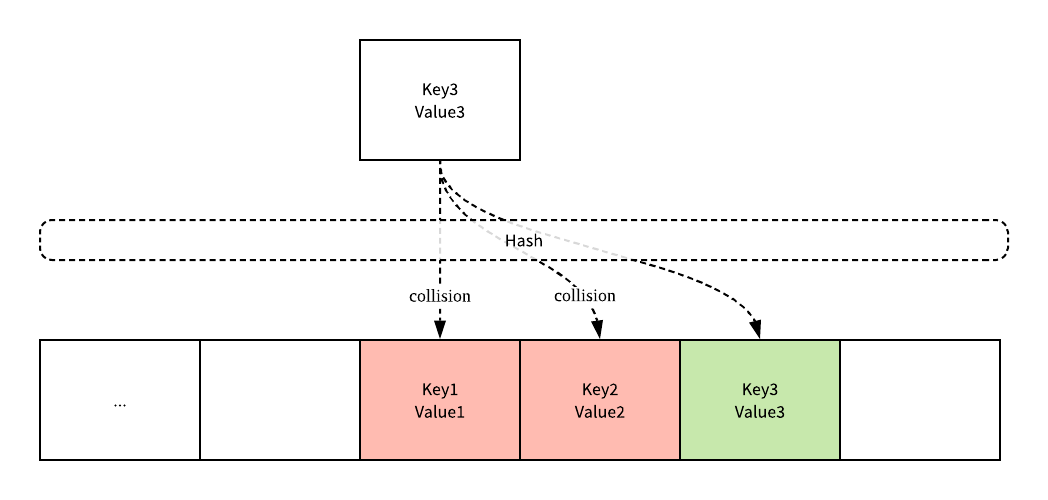
上图展示了键 Key3 与已经存入『哈希表』中的两个键 Key1 和 Key2 发生冲突时,Key3 会被自动写入到 Key2 后面的空闲内存上,在这时我们再去读取 Key3 对应的值时就会先对键进行哈希并所索引到 Key1 上,对比了目标键与 Key1 发现不匹配就会读取后面的元素,直到内存为空或者找到目标元素。
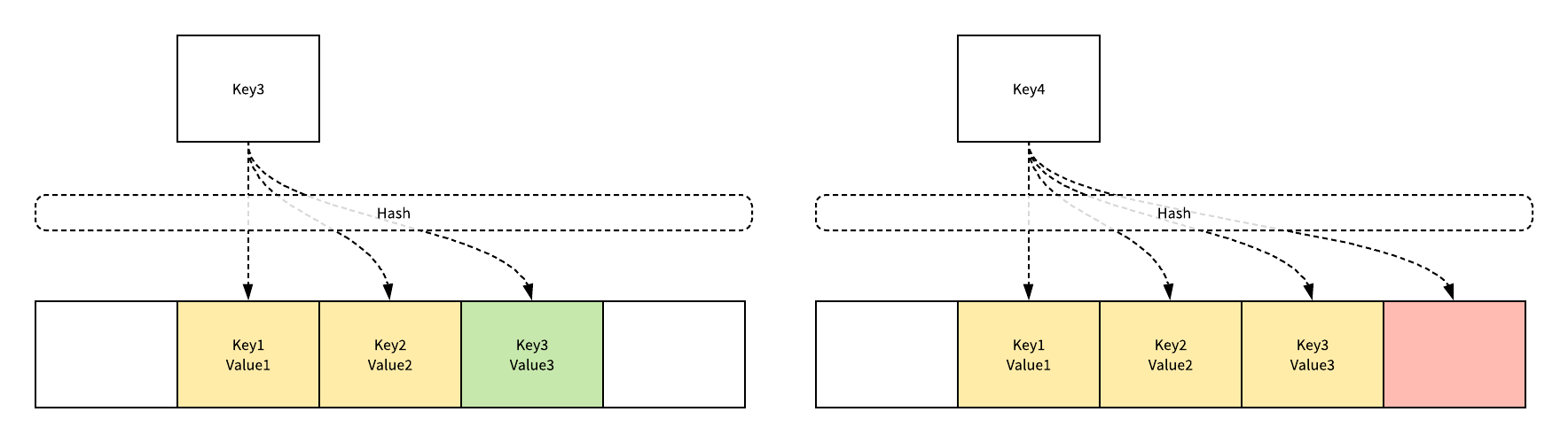
当我们查找某个键对应的数据时,就会对哈希命中的内存进行线性探测,找到目标键值对或者空内存就意味着这一次查询操作的结束。
开放寻址法中对性能影响最大的就是装载因子,它是数组中元素的数量与数组大小的比值,随着装载因子的增加,线性探测的平均用时就会逐渐增加,这会同时影响哈希表的查找和插入性能,当装载率超过 70% 之后,哈希表的性能就会急剧下降,而一旦装载率达到 100%,整个哈希表就会完全失效,所以在实现哈希表时一定要时刻关注装载因子的变化。
拉链法
与开放地址法相比,拉链法是哈希表中最常见的实现方法,大多数的编程语言都是用拉链法实现哈希表,它的实现相对比较简单,平均查找的长度也比较短,而且各个用于存储节点的内存都是动态申请的,可以节省比较多的存储空间。
拉链法的实现其实就是使用数组加上链表组合起来实现哈希表,数组中的每一个元素其实都是一个链表,我们可以将它看成一个可以扩展的二维数组:
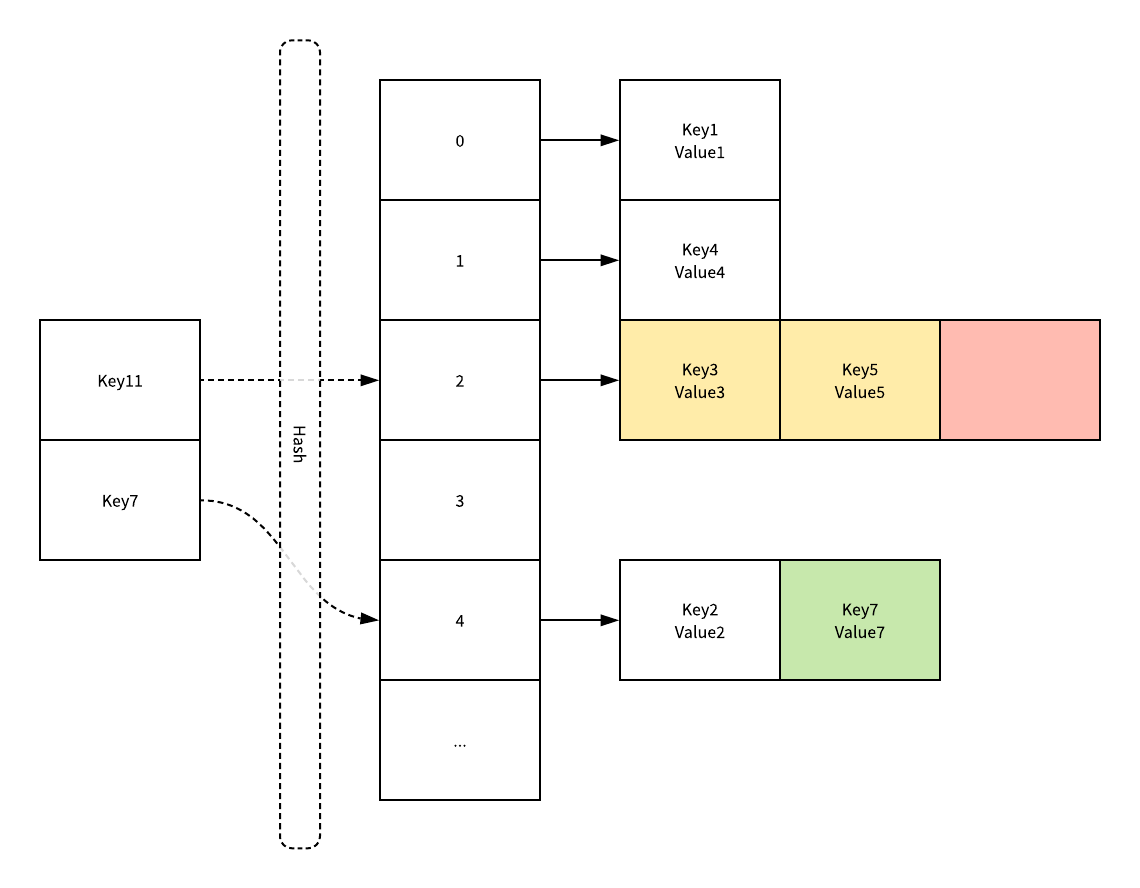
当我们需要将一个键值对加入一个哈希表时,键值对中的键都会先经过一个哈希函数,哈希函数返回的哈希会帮助我们『选择』一个桶,然后遍历当前桶中持有的链表,找到键相同的键值对执行更新操作或者遍历到链表的末尾追加一个新的键值对。
如果要通过某个键在哈希表中获取对应的值,就会经历如下的过程:
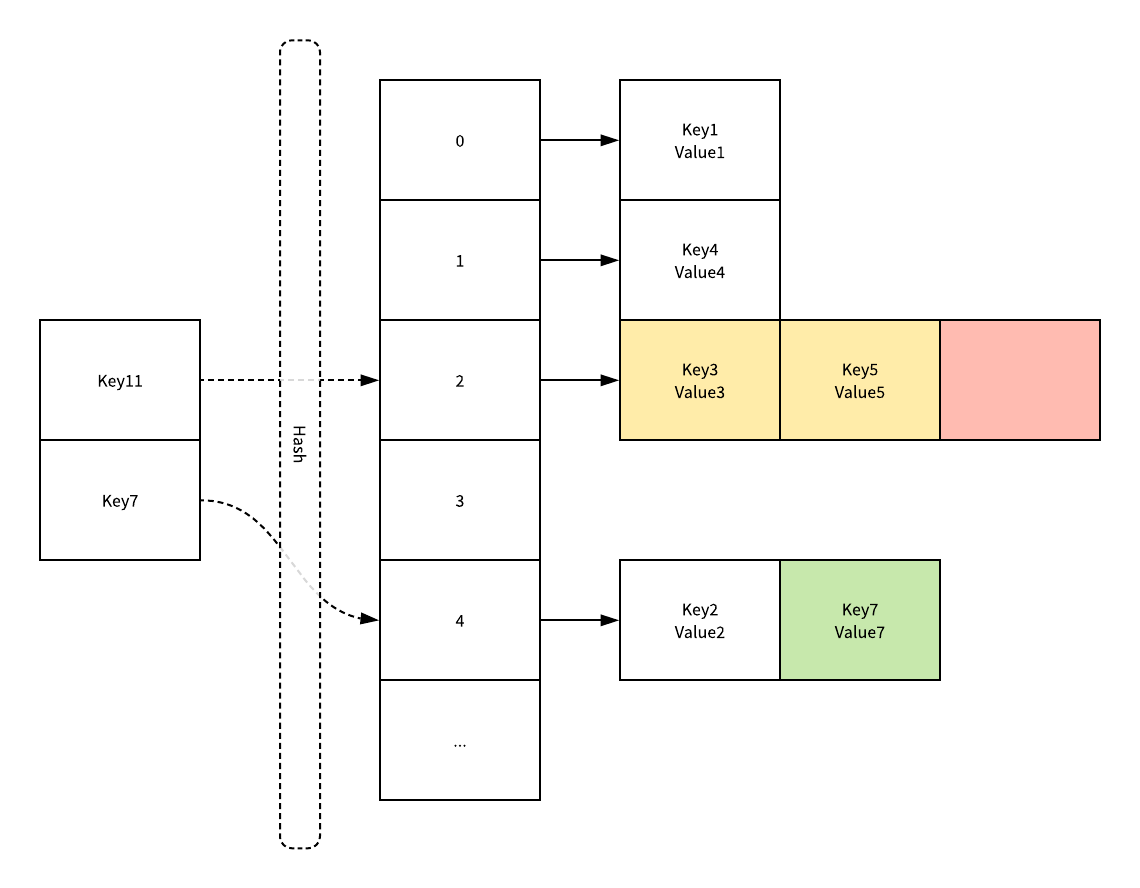
Key11 就是展示了一个键在哈希表中不存在的例子,当哈希表发现它命中 2 号桶时,它会依次遍历桶中的链表,解决遍历到链表的末尾也没有找到期望的键,所以该键对应的值就是空。
在一个性能比较好的哈希表中,每一个桶中都应该有 0 或者 1 个元素,有时会有 2~3 个元素,很少会发生遇到超过这个数量的情况,每一次读写哈希表的时间基本上都花在了定位桶和遍历链表这两个过程,有 1000 个桶的哈希表如果保存了 10000 个键值对,它的性能是保存 1000 个键值对的 1/10,但是仍然比一个链表的性能好 1000 倍。
初始化
我们既然已经介绍了常见哈希表的一些基本原理和实现方法,那么可以开始介绍文章正题,也就是 Go 语言中哈希表的实现原理,首先要讲的就是哈希在 Go 中的表示以及初始化哈希的两种方法 — 通过字面量和运行时。
结构体
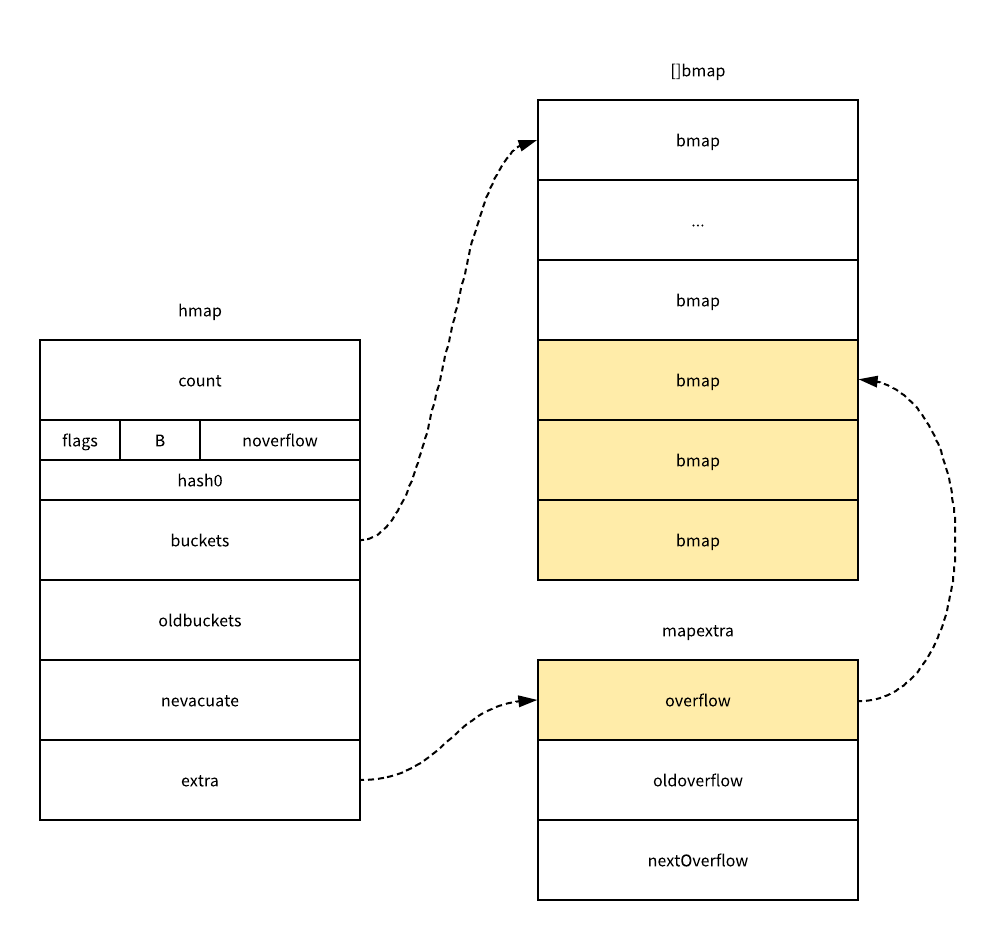
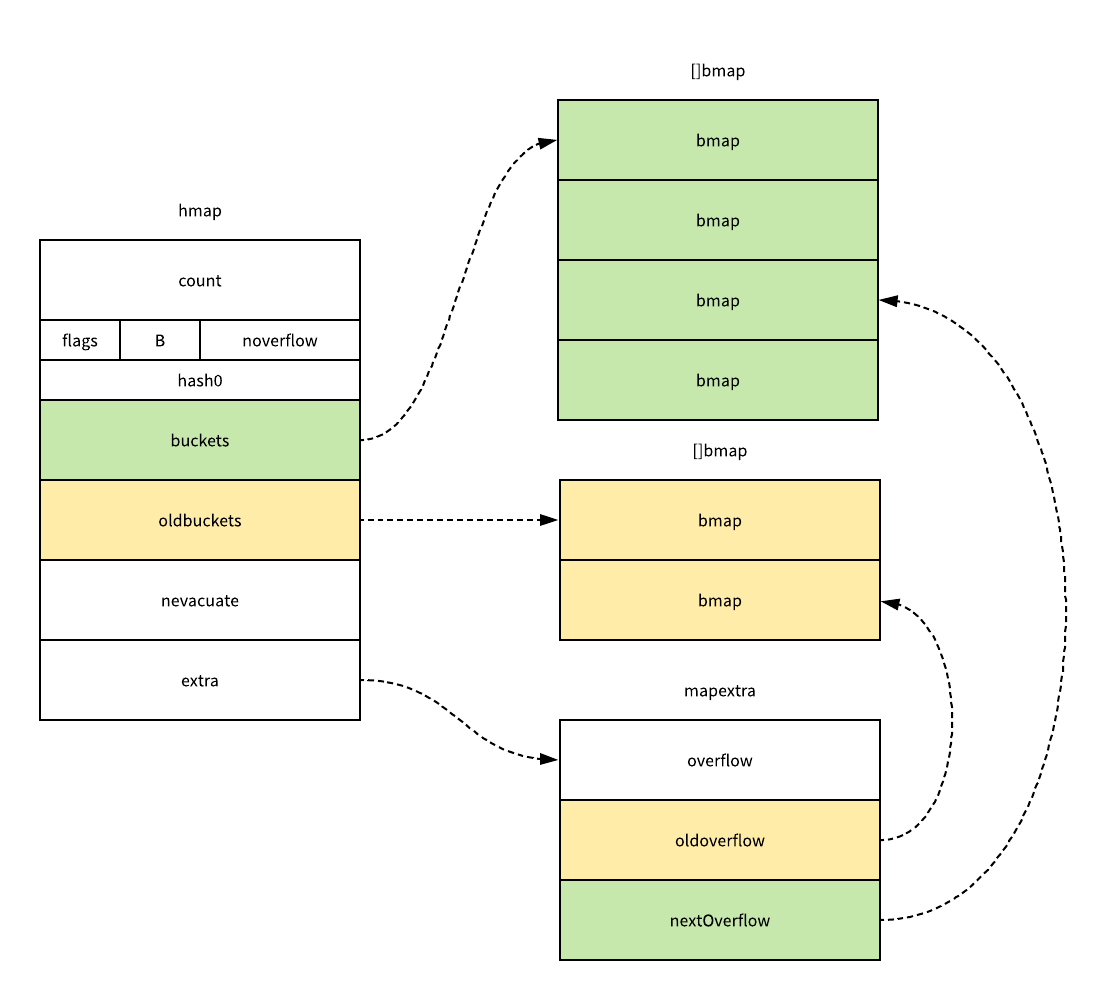
Golang 中哈希表是在 src/runtime/map.go 文件中定义的,哈希的结构体 hmap 是这样的,其中有几个比较关键的参数:
type hmap struct {
count int
flags uint8
B uint8
noverflow uint16
hash0 uint32
buckets unsafe.Pointer
oldbuckets unsafe.Pointer
nevacuate uintptr
extra *mapextra
}
count用于记录当前哈希表元素数量,这个字段让我们不再需要去遍历整个哈希表来获取长度;B表示了当前哈希表持有的buckets数量,但是因为哈希表的扩容是以 2 倍数进行的,所以这里会使用对数来存储,我们可以简单理解成len(buckets) == 2^B;hash0是哈希的种子,这个值会在调用哈希函数的时候作为参数传进去,它的主要作用就是为哈希函数的结果引入一定的随机性;oldbuckets是哈希在扩容时用于保存之前buckets的字段,它的大小都是当前buckets的一半;
这份 hmap 的结构体其实会同时在编译期间和运行时存在,编译期间会使用 hmap 函数构建一个完全相同结构体:
func hmap(t *types.Type) *types.Type {
bmap := bmap(t)
fields := []*types.Field{
makefield("count", types.Types[TINT]),
makefield("flags", types.Types[TUINT8]),
makefield("B", types.Types[TUINT8]),
makefield("noverflow", types.Types[TUINT16]),
makefield("hash0", types.Types[TUINT32]),
makefield("buckets", types.NewPtr(bmap)),
makefield("oldbuckets", types.NewPtr(bmap)),
makefield("nevacuate", types.Types[TUINTPTR]),
makefield("extra", types.Types[TUNSAFEPTR]),
}
hmap := types.New(TSTRUCT)
hmap.SetNoalg(true)
hmap.SetFields(fields)
dowidth(hmap)
t.MapType().Hmap = hmap
hmap.StructType().Map = t
return hmap
}
因为在编译期间运行时的很多代码还不能执行,所以我们需要模拟一个 hmap 结构体为一些哈希表在编译期间的初始化提供『容器』,所以虽然说哈希表是一种比较特殊的数据结构,但是底层在实现时还是需要使用结构体来存储一些用于管理和记录的变量。
字面量
如果我们在 Go 语言中使用字面量的方式初始化哈希表,与其他的语言非常类似,一般都会使用如下所示的格式:
hash := map[string]int{
"1": 2,
"3": 4,
"5": 6,
}
我们需要在使用哈希时标记其中键值的类型信息,这种使用字面量初始化的方式最终都会通过 maplit 函数对该变量进行初始化,接下来我们就开始分析一下上述的代码是如何在编译期间通过 maplit 函数初始化的:
func maplit(n *Node, m *Node, init *Nodes) {
a := nod(OMAKE, nil, nil)
a.Esc = n.Esc
a.List.Set2(typenod(n.Type), nodintconst(int64(n.List.Len())))
litas(m, a, init)
var stat, dyn []*Node
for _, r := range n.List.Slice() {
stat = append(stat, r)
}
if len(stat) > 25 {
// ...
} else {
addMapEntries(m, stat, init)
}
}
当哈希表中的元素数量少于或者等于 25 个时,编译器会直接调用 addMapEntries 将字面量初始化的结构体转换成以下的代码,单独将所有的键值对加入到哈希表中:
hash := make(map[string]int, 3)
hash["1"] = 2
hash["3"] = 4
hash["5"] = 6
而如果哈希表中元素的数量超过了 25 个,就会在编译期间创建两个数组分别存储键和值的信息,这些键值对会通过一个如下所示的 for 循环加入目标的哈希:
hash := make(map[string]int, 26)
vstatk := []string{"1", "2", "3", ... , "26"}
vstatv := []int{1, 2, 3, ... , 26}
for i := 0; i < len(vstak); i++ {
hash[vstatk[i]] = vstatv[i]
}
但是无论使用哪种方法,使用字面量初始化的过程都会使用 Go 语言中的关键字来初始化一个新的哈希并通过 [] 语法设置哈希中的键值,当然这里生成的用于初始化数组的字面量也会被编译器展开,具体的展开和实现方式可以阅读上一节 数组和切片 了解相关内容。
运行时
无论我们是在 Go 语言中直接使用 make 还是由编译器生成 make 其实都会在 类型检查 期间被转换成 makemap函数来创建哈希表:
func makemap(t *maptype, hint int, h *hmap) *hmap {
mem, overflow := math.MulUintptr(uintptr(hint), t.bucket.size)
if overflow || mem > maxAlloc {
hint = 0
}
if h == nil {
h = new(hmap)
}
h.hash0 = fastrand()
B := uint8(0)
for overLoadFactor(hint, B) {
B++
}
h.B = B
if h.B != 0 {
var nextOverflow *bmap
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}
return h
}
这个函数会通过 fastrand 创建一个随机的哈希种子,然后根据传入的 hint 计算出需要的最小需要的桶的数量,最后再使用 makeBucketArray创建用于保存桶的数组,这个方法其实就是根据传入的 B 计算出的需要创建的桶数量在内存中分配一片连续的空间用于存储数据,在创建桶的过程中还会额外创建一些用于保存溢出数据的桶,数量是 2^(B-4) 个。
哈希表的类型其实都存储在每一个桶中,这个桶的结构体 bmap 其实在 Go 语言源代码中的定义只包含一个简单的 tophash 字段:
type bmap struct {
tophash [bucketCnt]uint8
}
哈希表中桶的真正结构其实是在编译期间运行的函数 bmap 中被『动态』创建的:
func bmap(t *types.Type) *types.Type {
bucket := types.New(TSTRUCT)
keytype := t.Key()
valtype := t.Elem()
dowidth(keytype)
dowidth(valtype)
field := make([]*types.Field, 0, 5)
arr := types.NewArray(types.Types[TUINT8], BUCKETSIZE)
field = append(field, makefield("topbits", arr))
arr = types.NewArray(keytype, BUCKETSIZE)
keys := makefield("keys", arr)
field = append(field, keys)
arr = types.NewArray(valtype, BUCKETSIZE)
values := makefield("values", arr)
field = append(field, values)
if int(valtype.Align) > Widthptr || int(keytype.Align) > Widthptr {
field = append(field, makefield("pad", types.Types[TUINTPTR]))
}
otyp := types.NewPtr(bucket)
if !types.Haspointers(valtype) && !types.Haspointers(keytype) {
otyp = types.Types[TUINTPTR]
}
overflow := makefield("overflow", otyp)
field = append(field, overflow)
// ...
t.MapType().Bucket = bucket
bucket.StructType().Map = t
return bucket
}
这种做法是因为 Go 语言在执行哈希的操作时会直接操作内存空间,与此同时由于键值类型的不同占用的空间大小也不同,也就导致了类型和占用的内存不确定,所以没有办法在 Go 语言的源代码中进行声明。
我们可以根据上面这个函数的实现对结构体 bmap 进行重建:
type bmap struct {
topbits [8]uint8
keys [8]keytype
values [8]valuetype
pad uintptr
overflow uintptr
}
每一个哈希表中的桶最多只能存储 8 个元素,如果桶中存储的元素超过 8 个,那么这个哈希表的执行效率一定会急剧下降,不过在实际使用中如果一个哈希表存储的数据逐渐增多,我们会对哈希表进行扩容或者使用额外的桶存储溢出的数据,不会让单个桶中的数据超过 8 个:
溢出桶只是临时的解决方案,创建过多的溢出桶最终也会导致哈希的扩容。
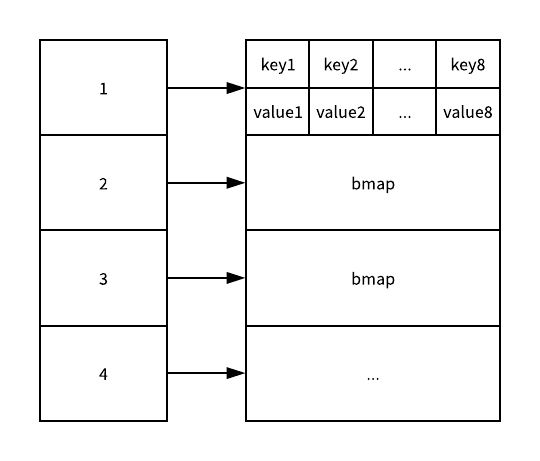
Go 语言的运行时会为哈希表分配内存空间,用于存储哈希表中的键值对,无论是哈希的结构还是桶的结构都是在运行时初始化的,只是后者并在源代码中存在事实的结构,它是一个使用代码生成的『虚拟』结构体。
操作
哈希表作为一种数据结构,我们肯定需要研究它的操作,也就是不同读写操作的实现原理,当我们谈到哈希表的读时,一般都是通过下标和遍历两种方式读取数据结构中存储的数据:
_ = hash[key]
for k, v := range hash {
// k, v
}
这两种方式虽然都是读取哈希表中的数据,但是使用的函数和底层的原理完全不同,前者需要知道哈希的键并且只能一个键对应的值,而后者可以遍历哈希中的全部键值对,访问数据时也不需要预先知道相应的键,我们会在后面的章节中介绍 range 的实现原理。
数据结构的写一般指的都是增加、删除和修改,增加和修改字段都是通过索引和赋值进行的,而删除字典中的数据需要使用关键字 delete:
hash[key] = value
hash[key] = newValue
delete(hash, key)
我们会对这些不同的操作一一讨论并给出它们底层具体的实现原理,这些操作大多都是通过编译期间和运行时共同实现的,介绍的过程中可能会省略一些编译期间的相关知识,具体的可以阅读之前的章节 编译过程概述 了解编译的过程和原理。
访问
在编译的 类型检查 阶段,所有的类似 hash[key] 的 OINDEX 操作都会被转换成 OINDEXMAP 操作,然后在 中间代码生成 之前会在 walkexpr 中将这些 OINDEXMAP 操作转换成如下的代码:
v := hash[key] // => v := *mapaccess1(maptype, hash, &key)
v, ok := hash[key] // => v, ok := mapaccess2(maptype, hash, &key)
赋值语句左侧接受参数的个数也会影响最终调用的运行时参数,当接受参数仅为一个时,会使用 mapaccess1 函数,同时接受键对应的值以及一个指示键是否存在的布尔值时就会使用 mapaccess2 函数,mapaccess1 函数仅会返回一个指向目标值的指针:
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
alg := t.key.alg
hash := alg.hash(key, uintptr(h.hash0))
m := bucketMask(h.B)
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
top := tophash(hash)
bucketloop:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
if alg.equal(key, k) {
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
if t.indirectvalue() {
v = *((*unsafe.Pointer)(v))
}
return v
}
}
}
return unsafe.Pointer(&zeroVal[0])
}
在这个函数中我们首先会通过哈希表设置的哈希函数、种子获取当前键对应的哈希,再通过 bucketMask 和 add函数拿到该键值对所在的桶和哈希最上面的 8 位数字,这 8 位数字最终就会与桶中存储的 tophash 作对比,每一个桶其实都存储了 8 个 tophash,就是编译期间的 topbits 字段,每一次都会与桶中全部的 8 个 uint8 进行比较,这 8 位的 tophash 其实就像是一级缓存,它存储的是哈希最高的 8 位,而选择桶时使用了桶掩码使用的是最低的几位,这种方式能够帮助我们快速判断当前的键值对是否存在并且减少碰撞:
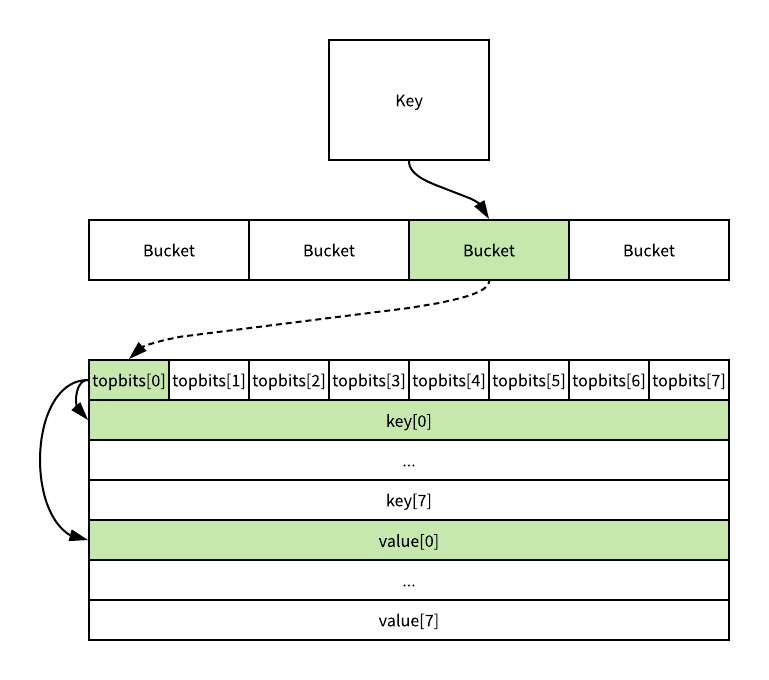
每一个桶都是一整片的内存空间,当我们发现某一个 topbits 与传入键的 tophash 匹配时,通过指针和偏移量获取哈希中存储的键并对两者进行比较,如果相同就会通过相同的方法获取目标值的指针并返回。
另一个同样用于访问哈希表中数据的 mapaccess2 函数其实只是在 mapaccess1 的基础上同时返回了一个标识当前数据是否存在的布尔值:
func mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool) {
// ...
bucketloop:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
// ...
if alg.equal(key, k) {
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
//...
return v, true
}
}
}
return unsafe.Pointer(&zeroVal[0]), false
}
使用 v, ok := hash[k] 的形式访问哈希表中元素时,我们能够通过这个布尔值更准确地知道当 v == nil 时,该空指针到底是哈希中存储的元素还是表示该键对应的元素不存在,所以在访问哈希时,作者更推荐使用这一种方式先判断元素是否存在。
上面的过程其实是在正常情况下,访问哈希表中元素时的表现,然而与数组一样,哈希表可能会在装载因子过高或者溢出桶过多时进行扩容,扩容时如何保证访问的性能是一个比较有意思的话题,我们在这里其实也省略了相关的代码,不过会在下面的扩容一节中会展开介绍。
写入
当形如 hash[k] 的表达式出现在赋值符号左侧时,与读取时一样会在编译的 类型检查 和 中间代码生成 期间被转换成调用 mapassign 函数调用,我们可以将该函数分成几个部分介绍,首先是函数会根据传入的键拿到对应的哈希和桶:
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
alg := t.key.alg
hash := alg.hash(key, uintptr(h.hash0))
h.flags ^= hashWriting
again:
bucket := hash & bucketMask(h.B)
b := (*bmap)(unsafe.Pointer(uintptr(h.buckets) + bucket*uintptr(t.bucketsize)))
top := tophash(hash)
然后通过遍历比较桶中存储的 tophash 和键的哈希,如果找到了相同结果就会获取目标位置的地址并返回,无论是查找键还是值都会直接通过算术计算进行寻址:
var inserti *uint8
var insertk unsafe.Pointer
var val unsafe.Pointer
bucketloop:
for {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if isEmpty(b.tophash[i]) && inserti == nil {
inserti = &b.tophash[i]
insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
val = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
}
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
if !alg.equal(key, k) {
continue
}
val = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
goto done
}
ovf := b.overflow(t)
if ovf == nil {
break
}
b = ovf
}
当前的哈希表没有处于扩容状态并且装载因子已经超过了 6.5 或者存在了太多溢出的桶时,就会调用 hashGrow对当前的哈希表进行扩容。
装载因子是同时由
loadFactorNum和loadFactDen两个参数决定的,前者在 Go 源代码中的定义是 13 后者是 2,所以装载因子就是 6.5。
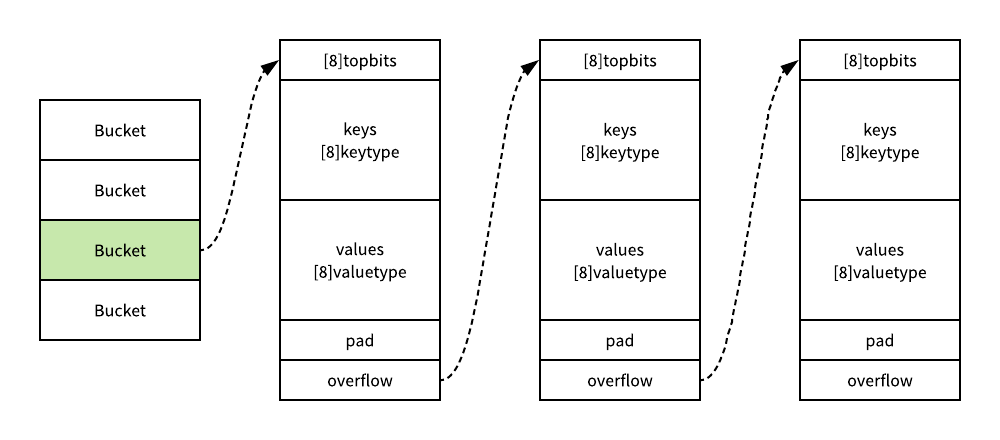
如果当前的桶已经满了,就会调用 newoverflow 创建一个新的桶或者使用 hmap 预先在 noverflow 中创建好的桶来保存数据,新创建桶的指针会被追加到已有桶中,与此同时,溢出桶的创建会增加哈希表的 noverflow计数器。
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again
}
if inserti == nil {
newb := h.newoverflow(t, b)
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
val = add(insertk, bucketCnt*uintptr(t.keysize))
}
if t.indirectkey() {
kmem := newobject(t.key)
*(*unsafe.Pointer)(insertk) = kmem
insertk = kmem
}
if t.indirectvalue() {
vmem := newobject(t.elem)
*(*unsafe.Pointer)(val) = vmem
}
typedmemmove(t.key, insertk, key)
*inserti = top
h.count++
done:
return val
}
如果哈希表存储的键值是指针类型,其实就会为当前的键值对分别申请一块新的内存空间,并在插入的位置通过 eypedmemmove 将键移动到申请的内存空间,最后返回键对应值的地址。
扩容
扩容过程的入口其实就是 hashGrow 函数,这个函数的主要作用就是对哈希表进行扩容,扩容的方式分成两种,如果这次扩容是溢出的桶太多导致的,那么这次扩容就是 sameSizeGrow:
func hashGrow(t *maptype, h *hmap) {
bigger := uint8(1)
if !overLoadFactor(h.count+1, h.B) {
bigger = 0
h.flags |= sameSizeGrow
}
oldbuckets := h.buckets
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
flags := h.flags &^ (iterator | oldIterator)
if h.flags&iterator != 0 {
flags |= oldIterator
}
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
h.nevacuate = 0
h.noverflow = 0
if h.extra != nil && h.extra.overflow != nil {
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
}
if nextOverflow != nil {
if h.extra == nil {
h.extra = new(mapextra)
}
h.extra.nextOverflow = nextOverflow
}
}
在哈希表扩容的过程中,我们会通过 makeBucketArray 创建新的桶数组和一些预创建的溢出桶,随后对将原有的桶数组设置到 oldbuckets 上并将新的空桶设置到 buckets 上,原有的溢出桶也使用了相同的逻辑进行更新。
我们在上面的函数中还看不出来 sameSizeGrow 导致的区别,因为这里其实只是创建了新的桶并没有对数据记性任何的拷贝和转移,哈希表真正的『数据迁移』的执行过程其实是在 evacuate 函数中进行的,evacuate 函数会对传入桶中的元素进行『再分配』。
func evacuate(t *maptype, h *hmap, oldbucket uintptr) {
b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize)))
newbit := h.noldbuckets()
if !evacuated(b) {
var xy [2]evacDst
x := &xy[0]
x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.bucketsize)))
x.k = add(unsafe.Pointer(x.b), dataOffset)
x.v = add(x.k, bucketCnt*uintptr(t.keysize))
if !h.sameSizeGrow() {
y := &xy[1]
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.bucketsize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.v = add(y.k, bucketCnt*uintptr(t.keysize))
}
evacuate 函数在最开始时会创建一个用于保存分配目的 evacDst 结构体数组,其中保存了目标桶的指针、目标桶存储的元素数量以及当前键和值存储的位置。

如果这是一次不改变大小的扩容,这两个 evacDst 结构体只会初始化一个,当哈希表的容量翻倍时,一个桶中的元素会被分流到新创建的两个桶中,这两个桶同时会被 evacDst 数组引用,下面就是元素分流的逻辑:
for ; b != nil; b = b.overflow(t) {
k := add(unsafe.Pointer(b), dataOffset)
v := add(k, bucketCnt*uintptr(t.keysize))
for i := 0; i < bucketCnt; i, k, v = i+1, add(k, uintptr(t.keysize)), add(v, uintptr(t.valuesize)) {
top := b.tophash[i]
k2 := k
var useY uint8
if !h.sameSizeGrow() {
hash := t.key.alg.hash(k2, uintptr(h.hash0))
if hash&newbit != 0 {
useY = 1
}
}
b.tophash[i] = evacuatedX + useY
dst := &xy[useY]
if dst.i == bucketCnt {
dst.b = h.newoverflow(t, dst.b)
dst.i = 0
dst.k = add(unsafe.Pointer(dst.b), dataOffset)
dst.v = add(dst.k, bucketCnt*uintptr(t.keysize))
}
dst.b.tophash[dst.i&(bucketCnt-1)] = top
typedmemmove(t.key, dst.k, k)
typedmemmove(t.elem, dst.v, v)
dst.i++
dst.k = add(dst.k, uintptr(t.keysize))
dst.v = add(dst.v, uintptr(t.valuesize))
}
}
}
if oldbucket == h.nevacuate {
advanceEvacuationMark(h, t, newbit)
}
}
如果新的哈希表中有八个桶,在大多数情况下,原来经过桶掩码结果为一的数据会因为桶掩码增加了一位而被分留到了新的一号桶和五号桶,所有的数据也都会被 typedmemmove 拷贝到目标桶的键和值所在的内存空间:
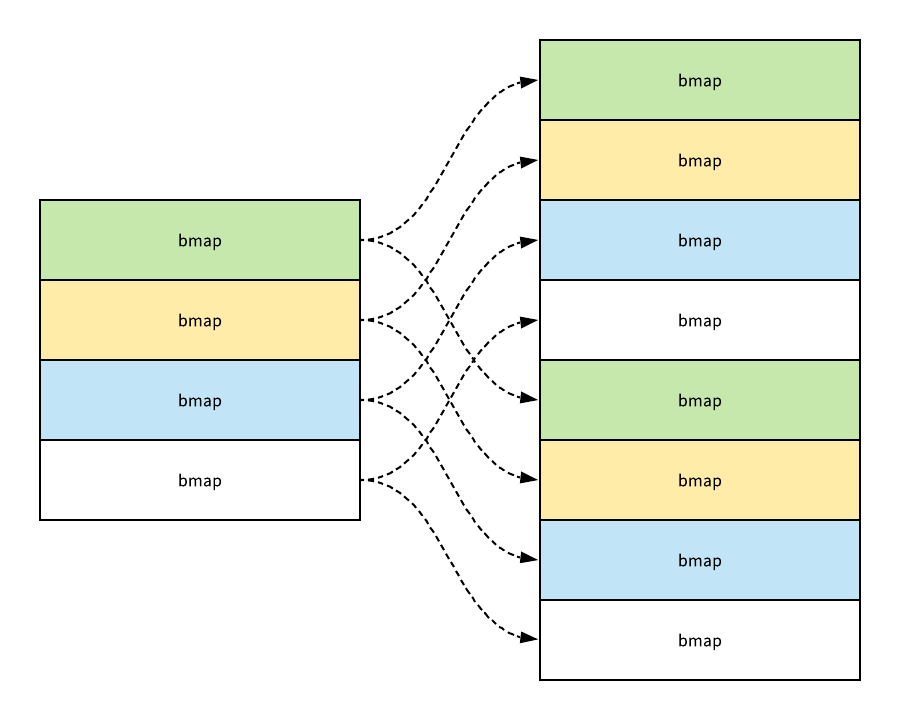
该函数的最后会调用 advanceEvacuationMark 函数,它会增加哈希的 nevacuate 计数器,然后在所有的旧桶都被分流后删除这些无用的数据,然而因为 Go 语言数据的迁移过程不是一次性执行完毕的,它只会在写入或者删除时触发 evacuate 函数增量完成的,所以不会瞬间对性能造成影响。
在之前的哈希表访问接口中其实省略一段从 oldbuckets 中获取桶的代码,这段代码就是扩容期间获取桶的逻辑,当哈希表的 oldbuckets 存在时,就会根据地址定位到以前的桶并且在当前桶未被 evacuate 时使用该桶。
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
// ...
alg := t.key.alg
hash := alg.hash(key, uintptr(h.hash0))
m := bucketMask(h.B)
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
if c := h.oldbuckets; c != nil {
if !h.sameSizeGrow() {
m >>= 1
}
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize)))
if !evacuated(oldb) {
b = oldb
}
}
bucketloop:
// ...
}
上述代码的作用就是在过去的桶没有被 evacuate 时暂时取代新桶接受读请求,因为历史的桶中还没有被处理,还保存着我们需要使用的数据,所以在这里会直接取代新创建的空桶。
另一段代码就在写请求执行的过程中,当哈希表正在处于扩容的状态时,每次设置哈希表的值时都会触发 growWork 对哈希表的内容进行增量拷贝:
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
alg := t.key.alg
hash := alg.hash(key, uintptr(h.hash0))
h.flags ^= hashWriting
again:
bucket := hash & bucketMask(h.B)
if h.growing() {
growWork(t, h, bucket)
}
// ...
}
当然除了除了写入操作之外,所有的删除操作也都会在哈希表扩容期间触发 growWork,触发的方式和代码与这里的逻辑几乎完全相同,都是计算当前值所在的桶,然后对该桶中的元素进行拷贝。
删除
想要删除哈希中的元素,就需要使用 Go 语言中的 delete 关键字,这个关键的唯一作用就是将某一个键对应的元素从哈希表中删除,无论是该键对应的值是否存在,这个内建的函数都不会返回任何的结果。
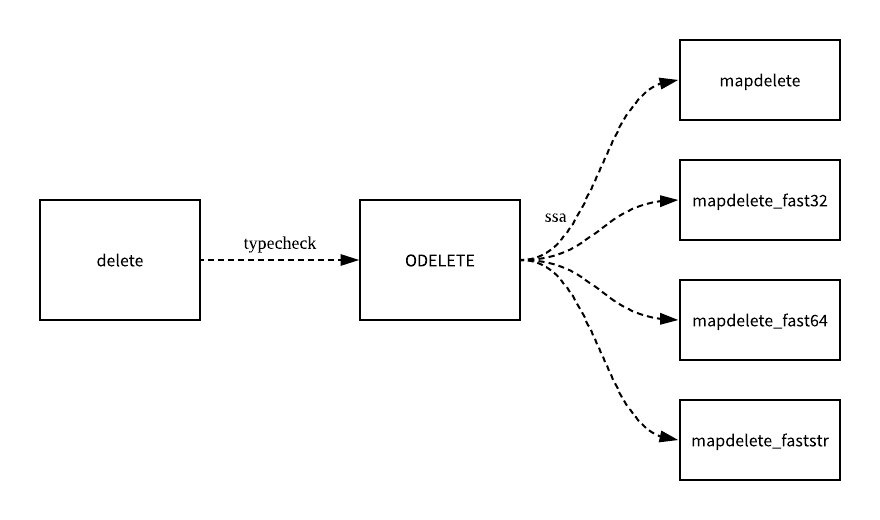
在编译期间,delete 关键字会被转换成操作为 ODELETE 的节点,而这个函数在最后会调用 mapdelete 函数簇中的一个,包括 mapdelete、mapdelete_faststr、mapdelete_fast32 和 mapdelete_fast64:
func walkexpr(n *Node, init *Nodes) *Node {
switch n.Op {
case ODELETE:
init.AppendNodes(&n.Ninit)
map_ := n.List.First()
key := n.List.Second()
map_ = walkexpr(map_, init)
key = walkexpr(key, init)
t := map_.Type
fast := mapfast(t)
if fast == mapslow {
key = nod(OADDR, key, nil)
}
n = mkcall1(mapfndel(mapdelete[fast], t), nil, init, typename(t), map_, key)
}
}
这些函数的实现其实差不多,我们依然选择 mapdelete 作为分析的主要方法,如果在删除期间遇到了哈希表的扩容,就会对即将操作的桶进行分流,随后找到桶中的目标元素并根据数据的类型调用 memclrHasPointers 或者 memclrNoHeapPointers 函数完成键值对的删除。
func mapdelete(t *maptype, h *hmap, key unsafe.Pointer) {
alg := t.key.alg
hash := alg.hash(key, uintptr(h.hash0))
bucket := hash & bucketMask(h.B)
if h.growing() {
growWork(t, h, bucket)
}
b := (*bmap)(add(h.buckets, bucket*uintptr(t.bucketsize)))
bOrig := b
top := tophash(hash)
search:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if b.tophash[i] == emptyRest {
break search
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
k2 := k
if !alg.equal(key, k2) {
continue
}
if t.indirectkey() {
*(*unsafe.Pointer)(k) = nil
} else if t.key.kind&kindNoPointers == 0 {
memclrHasPointers(k, t.key.size)
}
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
if t.indirectvalue() {
*(*unsafe.Pointer)(v) = nil
} else if t.elem.kind&kindNoPointers == 0 {
memclrHasPointers(v, t.elem.size)
} else {
memclrNoHeapPointers(v, t.elem.size)
}
b.tophash[i] = emptyOne
}
// ...
}
}
}
哈希表的删除逻辑与写入逻辑非常相似,只是他的调用方式比较特殊,我们需要使用关键字来『调用』mapdelete 函数。
对于哈希表的删除逻辑,我们其实只需要知道 delete 关键字会先在 类型检查 阶段被转换成 ODELETE 操作,然后在 SSA 中间代码生成 时被转换成 mapdelete 函数簇就可以了。
总结
Go 语言中使用拉链法来解决哈希碰撞的问题实现了哈希表,访问、写入和删除等操作都在编译期间被转换成了对应的运行时函数或者方法。
哈希在每一个桶中存储键对应哈希的前 8 位,当对哈希进行操作时,这些 tophash 就成为了一级缓存帮助哈希快速遍历桶中元素,每一个桶都只能存储 8 个键值对,一旦当前哈希的某个桶超出 8 个,新的键值对就会被存储到哈希的溢出桶中。
随着键值对数量的增加,溢出桶的数量和哈希的装载因子也会逐渐升高,超过一定范围时就会触发扩容操作,扩容时会将桶的数量分配,元素再分配的过程也是在调用写操作时增量进行的,不会造成性能的瞬时巨大波动。
转载自:
理解Golang哈希表Map的元素
理解Golang哈希表Map的元素的更多相关文章
- C++ STL中哈希表Map 与 hash_map 介绍
0 为什么需要hash_map 用过map吧?map提供一个很常用的功能,那就是提供key-value的存储和查找功能.例如,我要记录一个人名和相应的存储,而且随时增加,要快速查找和修改: 岳不群-华 ...
- 【哈希表】CodeVs1230元素查找
一.写在前面 哈希表(Hash Table),又称散列表,是一种可以快速处理插入和查询操作的数据结构.哈希表体现着函数映射的思想,它将数据与其存储位置通过某种函数联系起来,其在查询时的高效性也体现在这 ...
- 【哈希表】CODEVS1230 元素查找
#include<cstdio> #include<vector> using namespace std; typedef vector<int>::iterat ...
- 深入理解PHP内核(六)哈希表以及PHP的哈希表实现
原文链接:http://www.orlion.ga/241/ 一.哈希表(HashTable) 大部分动态语言的实现中都使用了哈希表,哈希表是一种通过哈希函数,将特定的键映射到特定值得一种数据 结构, ...
- [Codevs 1230]元素查找(手写哈希表)
题目连接:http://codevs.cn/problem/1230/ 说白了就是要我们自己手写一个哈希表的数据结构来实现加入和查找功能.map也能直接过(我第一次写就是用map骗AC的) 提一下个人 ...
- 3.10 Go Map哈希表
3.10 Go Map哈希表 map是key-value类型数据结构,读作(哈希表.字典),是一堆未排序的键值对集合. map是引用类型,使用make函数或者初始化表达式创建. map的key必须是支 ...
- libevent中evmap实现(哈希表)
libevent中,需要将大量的监听事件event进行归类存放,比如一个文件描述符fd可能对应多个监听事件,对大量的事件event采用监听的所采用的数据结构是event_io_map,其实现通过哈希表 ...
- 自己动手实现java数据结构(五)哈希表
1.哈希表介绍 前面我们已经介绍了许多类型的数据结构.在想要查询容器内特定元素时,有序向量使得我们能使用二分查找法进行精确的查询((O(logN)对数复杂度,很高效). 可人类总是不知满足,依然在寻求 ...
- 哈希表之bkdrhash算法解析及扩展
BKDRHASH是一种字符哈希算法,像BKDRHash,APHash.DJBHash,JSHash,RSHash.SDBMHash.PJWHash.ELFHash等等,这些都是比較经典的,通过http ...
随机推荐
- C++ STL容器总结
1. STL 容器 1. 按种类划分 顺序容器( sequence containers):是一种各元素之间有顺序关系的线性表,是一种线性结构的可序群集.顺序性容器中的每个元素均有固定的位 ...
- F7里利用DIV 模拟 textarea 显示回行的问题解决
<div class="card-content-inner" style="word-wrap:break-word;word-break:break-all;w ...
- sqlserver 删除表结构
sqlserver-----------删除表结构use IndividualTaxGOdeclare @sql varchar(8000)while (select count(*) from sy ...
- SSH免密登录实现
现在先想要把项目部署到linux系统中 通过使用maven添加tomcat插件可以做到,右击项目 配置这里的url,是部署到哪里的意思(比如我们现在将这个项目部署到以下系统的tomcat中) 此处只有 ...
- Android进阶:五、RxJava2源码解析 2
上一篇文章Android进阶:四.RxJava2 源码解析 1里我们讲到Rxjava2 从创建一个事件到事件被观察的过程原理,这篇文章我们讲Rxjava2中链式调用的原理.本文不讲用法,仍然需要读者熟 ...
- 谷歌浏览器F12基本用法
第一步:打开你想进行调试的页面,并按F12进入到调试模式 此处以百度页面为例进行功能展示 这是关于最右侧“元素选择器”的功能展示 关于第二个功能的使用,这个功能是将页面适应成手机屏幕大小, eleme ...
- idea通过mapper快速定位到xml文件
1.点击File找到设置(Settings) 2.点击Plugins下的 Browse respositories 3.在搜索栏搜索mybatis ,选中 Free Mybatis plugin——i ...
- 元素定位-XPATH定位方法总结
1.Xpath定位方法探讨 xpath是比较常用的一种定位元素的方式,因为它很方便,缺点是,消耗系统性能.如果Xpath使用的比较好,几乎可以定位到任何页面元素,而且受页面变化影响较小. 1.1.什么 ...
- spring 应用
Spring框架本身会托管bean. 1.使用时需要注意对于包本身扫描配置. 2.使用注解本身包需要在扫描路径下.
- 2018-2019-2 网络对抗技术 20162329 Exp6 信息搜集与漏洞扫描
目录 Exp6 信息搜集与漏洞扫描 一.实践原理 1. 间接收集 2. 直接收集 3. 社会工程学 二.间接收集 1. Zoomeye 2. FOFA 3. GHDB 4. whois 5. dig ...