MySQL 基础知识梳理学习(五)----详解MySQL两次写的设计及实现
一 . 两次写提出的背景或要解决的问题
两次写(InnoDB Double Write)是Innodb中很独特的一个功能点。因为Innodb中的日志是逻辑的,所谓逻辑就是比如插入一条记录时,它可能会在某一个页面(这条记录最终被插入的位置)的多个偏移位置写入某个长度的值,例如页头的记录数、槽数、页尾槽数据、页中的记录值等。这些本是一些物理操作,而Innodb为了节省日志量及其它原因,设计为逻辑处理的方式,即在一个页面上插入一条记录时,对应的日志内容包括表空间号、页面号、将被记录的各个列的值等内容,在真正物理插入的时候,才会将日志逻辑操作转换为前面的物理操作。
先有逻辑日志,再有物理操作,但是这样需要有一个前提,就是物理操作的页面是正确的。如果那个数据页面本身是错误的,这种错误可能是上次的操作导致的写断裂(1个页面为16KB,分多次写入,后面的可能没有写成功,导致这个页面不完整)或者其它原因,那么这个逻辑操作就没办法完成了。因为如果这个页面不正确的话,里面的数据是无效的,就可能会产生各种不可预料的问题。
因此首先要保证这个页面是正确的,方法就是两次写。
二 . 单一页面刷盘
两次写包括两种方法,一种是对单独一个页面刷盘时的两次写,另一种是批量刷盘时的两次写。单一页面刷盘实际上是MySQL5.5版本的实现方式。
2.1 结构设计及原理
MySQL在系统页面上记录关于两次写的信息如要如下:
| 参数变量 | 信息描述 | 说明 |
| TRX_SYS_DOUBLEWRITE_FSEG | 两次写页面所在段的地址信息。 | 存储两次写页面所在段的地址信息,每次使用两次写机制写数据时,都会从这个位置读取到段的位置,找到段的首地址。 |
| TRX_SYS_DOUBLEWRITE_MAGIC | 用来判断是不是已经初始化过两次写页面。 | 存储的是用来验证当前两次写是不是正常或是不是已经申请的标志。 |
| TRX_SYS_DOUBLEWRITE_BLOCK1 | 两次写页面第一个簇的首地址,两次写页面总共两个簇,一个簇为64个页面。 |
存储的是两次写空间的位置,他们在ibdata文件中属于同一个段,在初始化数据库时会确定具体问题,是用来真正存储两次写页面数据的空间,它们对应的空间大小都是一个簇,占用磁盘空间分别为1M。(一个簇为64*16KB=1M;2个簇,就是2M) |
| TRX_SYS_DOUBLEWRITE_BLOCK2 | 第二个簇的首地址。 | |
| TRX_SYS_DOUBLEWRITE_REPEAT | 将上面的MAGIC、BLOCK1、BLOCK2重复存储,防止页面自己的不完整。 |
2.2 刷盘的过程
每次刷盘前,都会将要刷盘的页面信息临时保存到内存的数组中,这个空间大小也是128个页面,这个缓存称为两次写缓存数组。有了这些信息,单个页面刷盘的两次写就可以正常运转了。
step 1 先在两次写缓存数组中,找到一个空闲位置,并将这个位置标记为已使用,然后,再把要刷新的页面数据复制到标记的缓存空间中。
step 2 将页面的数据刷到两次写文件中,即ibdata文件中。此时页面是持久化。
复制的数据量是一个页面的大小,偏移位置是这个页面在两次写缓存空间中的位置,对应着TRX_SYS_DOUBLEWRITE_BLOCK1或TRX_SYS_DOUBLEWRITE_BLOCK2的位置。因为内存中的两次写缓存数组是128个元素,而对应的TRX_SYS_DOUBLEWRITE_BLOCK1及TRX_SYS_DOUBLEWRITE_BLOCK2也是128个页面,它们是一一对应的,所以具体刷到什么位置,可以计算出来。
step 3 页面刷盘,即数据刷到真实的位置,也许刷到的是ibdata文件,也许是某一个表的ibd文件中的某一个位置。
需要注意的是,因为Buffer Pool中的页面,刷到真实文件时是异步IO的,那么只有当刷到自己表空间的刷盘操作完成后,两次写缓存数组的数据才可以被覆盖,或者说,这个页面对应的两次写文件中的页面才可以被覆盖,不然有可能造成这个两次写位置的页面被新的页面覆盖的问题。如果此时上次的真实表空间的刷盘没有完成,同时产生了页面断裂的问题,这样就出现了该页面不可恢复的问题,两次写的意义也就没有了。
三 . 批量页面刷盘
很明显,单一刷盘情况下开启了两次写,IO次数的增加会导致性能差很多,在新版本MySQL 5.7中,新增加入了针对Buffer Pool 批量刷盘的两次写实现方式。
3.1 实现原理
MySQL 5.7的实现方式新增了一个文件,文件路径及名称可以通过参数innodb_parallel_doublewrite_path来控制。启动数据库时,如果两次写文件不存在,那么这个参数可以指定绝对路径的两次写文件,也可以只指定文件名使文件被默认创建到datadir目录下。
批量刷盘包括两种方式,分别是LRU(Least Recently Used,最近最少使用)方式和LIST方式。当Buffer Pool空间不足时,再载入新的页面就必须要将一些不怎么用到的、旧的页面淘汰出去,此时系统就会从LRU链表中找到最老的页面,进行批量刷盘,将释放的空间加入到空闲空间中去,这种情况就是LRU刷盘。当日志空间不足,或者是后台MASTER线程在定时刷盘时,不需要区分页面的新旧状态,只需要选择LSN最小的那些页面,从前到后刷一批页面到文件中,此时所用的策略就是LIST方式。
在批量刷盘的两次写中,这两种刷盘方法对应的两次写空间互不干涉。
InnoDB自身的整个Buffer Pool分为多个Instance,每个Instance管理自身的一套两次写空间,而针对每一个Instance的每一个刷盘方法的批量缓存空间大小,是通过参数innodb_doublewrite_batch_size来控制的,默认值为120。这样算下来,innodb_parallel_doublewrite_path所指的文件大小的计算方法如下:
两次写文件页面个数=innodb_buffer_pool_instances*2(LIST+LRU)*innodb_doublewrite_batch_size.
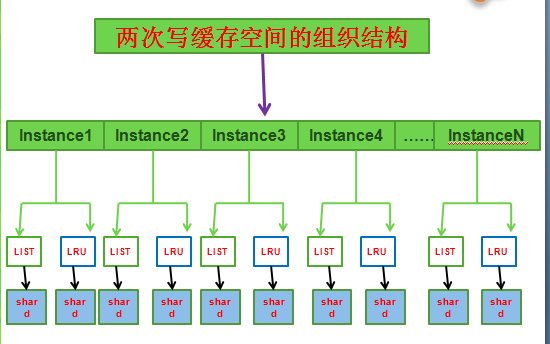
从图中可以看出落到最终的每一个shard,其实就是一个batch,对应的参数就是innodb_doublewrite_batch_size。一个shard,有一个数组,长度为innodb_doublewrite_batch_size,与单一页面刷盘的两次写是一样的,只是这个数组只属于一个shard而已。
3.2 批量刷盘的过程
假设由于页面淘汰,系统要做一次批量刷盘,这次就是LRU方式的,那么此时系统就需要将当前页面加入到两次写缓存中,首先根据当前页面所在的Instance号及刷盘类型就可以找到对应的shard缓存,找到缓存后,判断当前shard是否已经满了,即是否已经达到innodb_doublewrite_batch_size的大小,如果没有达到,则将当前页面内容追加复制到当前的shard缓存中,这样当前页面的刷盘操作就完成了。这里并不像单一页面那样,先写入缓存空间中,然后写入ibdata文件的两次写空间,最后还需要立即将页面的真实内容刷入表空间,对于批量刷盘来说,只需要写入到shard缓存即可。
如果当前shard中缓存的页面个数已经达到了innodb_doublewrite_batch_size,则说明当前缓存空间已经满了,此时不得不将当前shard缓存的页面写入两次写文件中,写完之后再将两次写文件FLUSH到磁盘,最后将对应的真实页面刷盘,此时可能是随机写入了,因为对应的两次写缓存中虽然是连续的,但对应的真实页面就不会这样了。这里需要注意的一点就是,表空间页面的刷盘,是异步IO操作,此时需要等待异步IO完成,且整个shard中的页面都刷盘后,刷盘操作才可以继续向后执行,而这个shard也可以再次重新使用了,缓存中的数据也都会被清空。
需要注意的是,上面过程中写入是连续innodb_doublewrite_batch_size 个页面,所以性能会比写入多次而每次写入一个页面的情况好很多。批量刷盘的情况下,有可能每隔innodb_doublewrite_batch_size个页面的刷盘操作,就会出现一次等待操作,且等待时间长短不一定,但这也是在单一页面刷盘的基础上优化过的,做了改进。
四 . 两次写的作用
在数据库启动时(异常关闭的情况下),都会做数据库恢复(redo)操作。在恢复的过程中,数据库会检查页面是否合法(校验),如果发现一个页面的校验结果不一致,则此时就会用到两次写机制,用两次写空间中的数据来恢复异常页面的数据,这也正是为处理这样的错误而设计的。此时的处理机制就是,将两次写的两个簇都读出来,再将innodb_parallel_doublewrite_path文件的内容读出来,然后将所有这些页面写回到对应的页面中去,这样就可以保证这些页面是正确的,并且是在写入前已经更新过的(最新数据)。在写回对应页面中去之后,就可以在此基础上继续做数据库恢复了,且不会遇到这样的问题了,因为最后有可能产生写断裂的数据页面都恢复了。
上面所讲的都是数据页面有问题的情况下可以通过两次写页面来恢复,但是如果两次写页面本身发生写断裂怎么办呢? 对于这个问题,大家不必担心。因为如果两次写有问题,则数据页面本身就不会做写操作(一定是先逻辑后物理嘛,逻辑挂了,就没有后面的物理了。),此时系统挂了,发生错误的是两次写页面,而数据页面在挂之前都是在Buffer里面,文件中依然是当前事务操作前的值,并没有变化,还是一致状态,这意味着两次写页面根本就不会被使用到。
-----主要内容参考梳理于网络知识,此短文仅为学习笔记,在此原创作者感谢!
MySQL 基础知识梳理学习(五)----详解MySQL两次写的设计及实现的更多相关文章
- MySQL 基础知识梳理学习(四)----GTID
在日常运维中,GTID带来的最方便的作用就是搭建和维护主从复制.GTID的主从模式代替了MySQL早期版本中利用二进制日志文件的名称和日志位置的做法,使用GTID使操作和维护都变得更加简洁和可高. 1 ...
- MySQL 基础知识梳理学习(五)----半同步复制
1.半同步复制的特征 (1)从库会在连接到主库时告诉主库,它是不是配置了半同步. (2)如果半同步复制在主库端是开启了的,并且至少有一个半同步复制的从节点,那么此时主库的事务线程在提交时会被阻塞并等待 ...
- MySQL 基础知识梳理学习(七)----sync_binlog
一般在生产环境中,很少用MySQL单实例来支撑业务,大部分的MySQL应用都是采用搭建集群的方法.搭建MySQL集群,可以进行数据库层面的读写分离.负载均衡或数据备份.基于MySQL原生的Replic ...
- MySQL 基础知识梳理学习(三)----InnoDB日志相关的几个要点
1.InnoDB的特点 :(1)Fully ACID (InnoDB默认的Repeat Read隔离级别支持):(2)Row-level Locking(支持行锁):(3)Multi-version ...
- MySQL 基础知识梳理学习(二)----记录在页面层级的组织管理
1.InnoDB的数据存储结构 InnoDB中数据是通过段.簇.页面构成的. (1)段是表空间文件中的主要组织结构,它是一个逻辑概念,用来管理物理文件,是构成索引.表.回滚段的基本元素.创建一个索引( ...
- MySQL 基础知识梳理学习(一)----系统数据库
information_schema 此数据库是MySQL数据库自带的,主要存储数据库的元数据,保存了关于MySQL服务器维护的所有其他数据库的信息,如数据库名.数据库表.表列的数据类型及访问权限等. ...
- MySQL 基础知识梳理学习(六)----锁
1.什么是锁: 对共享资源进行并发访问控制,提供数据的完整性和一致性. 2.锁的区别: 类型 lock latch 对象 事务 线程 保护 数据库内容 内存数据结构 持续时间 整个事务过程 临界资源 ...
- MySQL 基础知识梳理
MySQL 的安装方式有多种,但是对于不同场景,会有最适合该场景的 MySQL 安装方式,下面就介绍一下 MySQL 常见的安装方法,包括 rpm 安装,yum 安装,通用二进制安装以及源码编译安装, ...
- [SQL] SQL 基础知识梳理(五) - 复杂查询
SQL 基础知识梳理(五) - 复杂查询 [博主]反骨仔 [原文]http://www.cnblogs.com/liqingwen/p/5939796.html 序 这是<SQL 基础知识梳理( ...
随机推荐
- [Swift]LeetCode745. 前缀和后缀搜索 | Prefix and Suffix Search
Given many words, words[i] has weight i. Design a class WordFilter that supports one function, WordF ...
- mybatis-generator XML Parser Error on line 38: 必须为元素类型 "table" 声明属性 "enableInsertByPrimaryKey"。
1. 解决方法 在 table 元素中删除属性 enableInsertByPrimaryKey 即可.就是这么神奇... 2. 情景重现 使用 mybatis-generator 插件生成代码时报错 ...
- Ubuntu12.04下安ns-3.29及Ubuntu换源方法
目录 1.下载ns-3.29 2.安装gcc-4.9.2 3.编译.测试ns-3.29 第一种:更新,文章开头说的 第二种,更新源 主机型号:Ubuntu12.04 仿真环境版本:NS-3.29 安装 ...
- Xapian的内存索引
关键字:xapian.内存索引 xapian除了提供用于生产环境的磁盘索引,也提供了内存索引(InMemoryDatabase).内存索引.我们可以通过观察内存索引的设计,来了解xapian的设计思路 ...
- Chapter 4 Invitations——22
"Are you going all by yourself?" he asked, and I couldn't tell if he was suspicious I had ...
- iOS逆向开发(6):微信伪造位置
仍然以微信为例,实战地练习一下使用Reveal.iOSOpenDev等工具注入APP的流程,积累经验.这一系列的文章都是学习过程的总结,不带任何商业目的. 本文解决一个问题:如何伪造一个经纬度,在微信 ...
- Nacos 发布 v0.8.0 Pre-GA版本,安全稳定上生产?
服务注册和服务配置开源项目 Nacos 本周发布了 v0.8.0 Pre-GA 版本,作为开源项目生命周期中的里程碑版本之一,v0.8.0 Pre-GA版本支持登录.命名空间.Metrics监控(对接 ...
- 痞子衡嵌入式:ARM Cortex-M文件那些事(1)- 源文件(.c/.h/.s)
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家讲的是嵌入式开发里的source文件. 众所周知,嵌入式开发属于偏底层的开发,主要编程语言是C和汇编.所以本文要讲的source文件主要指的就是 ...
- plsql的database下拉为空,如何解决?
如何解决plsql的database下拉为空? 为什么plsql的database下拉为空?我在tnsnames.ora中设置了字符串ORCL,疑惑了我好久,在网上找了许久解决方案,终于是解决了!如下 ...
- “/"应用程序中的服务器错误
运行ASP.NET MVC项目时,出现了如下错误: 在网上搜索了很久并没有找到有用的答案,后来请朋友看了一下,最后改了端口号才运行成功,错误应该是之前的端口号被占用导致的.