MapReduce-FileInputFormat
在运行 MapReduce 程序时,输入的文件格式包括:基于行的日志文件、二进制格式文件、数据库表等。那么,针对不同的数据类型,MapReduce 是如何读取这些数据?
FileInputFormat 用来读取数据,其本身为一个抽象类,继承自 InputFormat 抽象类,针对不同的类型的数据有不同的子类来处理。
FileInputFormat 常见的接口实现类包括:TextInputFormat、KeyValueTextInputFormat、NLinelnputFormat、CombineTextInputFormat 和自定义 ImputFormat 等。
1.TextInputFormat 与 CombineTextInputFormat 类似,都是按行读取,键为偏移量,值为当前行的类容,只是切片机制不同。
2.KeyValueTextInputFormat 也是按行读取,当前行内容被分隔符分为 key 和 value。默认分隔符为 tab(\t),可设置。
测试数据

按照空格分割,控制台日志(会取第一个匹配字符进行分割)

测试代码,统计重复 key 的次数
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.KeyValueLineRecordReader;
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.log4j.BasicConfigurator; import java.io.IOException; public class KVDriver { static {
try {
// 设置 HADOOP_HOME 环境变量
System.setProperty("hadoop.home.dir", "D://DevelopTools/hadoop-2.9.2/");
// 日志初始化
BasicConfigurator.configure();
// 加载库文件
System.load("D://DevelopTools/hadoop-2.9.2/bin/hadoop.dll");
} catch (UnsatisfiedLinkError e) {
System.err.println("Native code library failed to load.\n" + e);
System.exit(1);
}
} public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { args = new String[]{"D:\\tmp\\input2", "D:\\tmp\\456"};
Configuration conf = new Configuration(); // 设置分隔符
conf.set(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR, " "); Job job = Job.getInstance(conf);
job.setJarByClass(KVDriver.class); job.setMapperClass(KVMapper.class);
job.setReducerClass(KVReducer.class); job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); // 设置 FileInputFormat
job.setInputFormatClass(KeyValueTextInputFormat.class); FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
} class KVMapper extends Mapper<Text, Text, Text, IntWritable> { IntWritable v = new IntWritable(1); @Override
protected void map(Text key, Text value, Context context) throws IOException, InterruptedException {
// 查看 k-v
System.out.println(key + "===" + value);
context.write(key, v);
}
} class KVReducer extends Reducer<Text, IntWritable, Text, IntWritable> { IntWritable v = new IntWritable(); @Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
v.set(sum);
context.write(key, v);
}
}
3.NLinelnputFormat 与 TextInputFormat 和 CombineTextInputFormat 类似,但切片机制不同。
每个 map 进程处理的 InputSplit 不再按 Blok 块去划分,而是按 NlinelnputFormat 指定的行数 N 来划分。即(输入文件的总行数/N=切片数),如果不整除,切片数=商+1。
同样的测试数据,设置一行为一个切片
k-v 值
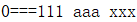
切片数

测试代码,统计单词数量
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.NLineInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.log4j.BasicConfigurator; import java.io.IOException; public class NLineDriver { static {
try {
// 设置 HADOOP_HOME 环境变量
System.setProperty("hadoop.home.dir", "D://DevelopTools/hadoop-2.9.2/");
// 日志初始化
BasicConfigurator.configure();
// 加载库文件
System.load("D://DevelopTools/hadoop-2.9.2/bin/hadoop.dll");
} catch (UnsatisfiedLinkError e) {
System.err.println("Native code library failed to load.\n" + e);
System.exit(1);
}
} public static void main(String[] args) throws IllegalArgumentException, IOException, ClassNotFoundException, InterruptedException {
args = new String[]{"D:\\tmp\\input2", "D:\\tmp\\456"}; Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration); job.setJarByClass(NLineDriver.class);
job.setMapperClass(NLineMapper.class);
job.setReducerClass(NLineReducer.class); job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); // 使用 NLineInputFormat 处理记录数
job.setInputFormatClass(NLineInputFormat.class);
// 设置每个切片 InputSplit 中划分一条记录
NLineInputFormat.setNumLinesPerSplit(job, 1); FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
} class NLineMapper extends Mapper<LongWritable, Text, Text, IntWritable> { Text k = new Text();
IntWritable v = new IntWritable(1); @Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 查看 k-v
System.out.println(key + "===" + value);
// 获取一行
String line = value.toString();
// 切割
String[] words = line.split(" ");
// 循环写出
for (String word : words) {
k.set(word);
context.write(k, v);
}
}
} class NLineReducer extends Reducer<Text, IntWritable, Text, IntWritable> { IntWritable v = new IntWritable(); @Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
v.set(sum);
context.write(key, v);
}
}
MapReduce-FileInputFormat的更多相关文章
- MapReduce :基于 FileInputFormat 的 mapper 数量控制
本篇分两部分,第一部分分析使用 java 提交 mapreduce 任务时对 mapper 数量的控制,第二部分分析使用 streaming 形式提交 mapreduce 任务时对 mapper 数量 ...
- MapReduce的map个数调节 与 Hadoop的FileInputFormat的任务切分原理
在对日志等大表数据进行处理的时候需要人为地设置任务的map数,防止因map数过小导致集群资源被耗光.可根据大表的数据量大小设置每个split的大小. 例如设置每个split为500M: set map ...
- Hadoop(16)-MapReduce框架原理-自定义FileInputFormat
1. 需求 将多个小文件合并成一个SequenceFile文件(SequenceFile文件是Hadoop用来存储二进制形式的key-value对的文件格式),SequenceFile里面存储着多个文 ...
- MapReduce之提交job源码分析 FileInputFormat源码解析
MapReduce之提交job源码分析 job 提交流程源码详解 //runner 类中提交job waitForCompletion() submit(); // 1 建立连接 connect(); ...
- Hadoop Mapreduce 中的FileInputFormat类的文件切分算法和host选择算法
文件切分算法 文件切分算法主要用于确定InputSplit的个数以及每个InputSplit对应的数据段. FileInputFormat以文件为单位切分成InputSplit.对于每个文件,由以下三 ...
- Hadoop(15)-MapReduce框架原理-FileInputFormat的实现类
1. TextInputFormat 2.KeyValueTextInputFormat 3. NLineInputFormat
- mapreduce多文件输出的两方法
mapreduce多文件输出的两方法 package duogemap; import java.io.IOException; import org.apache.hadoop.conf ...
- mapreduce中一个map多个输入路径
package duogemap; import java.io.IOException; import java.util.ArrayList; import java.util.List; imp ...
- [Hadoop in Action] 第5章 高阶MapReduce
链接多个MapReduce作业 执行多个数据集的联结 生成Bloom filter 1.链接MapReduce作业 [顺序链接MapReduce作业] mapreduce-1 | mapr ...
- MapReduce
2016-12-21 16:53:49 mapred-default.xml mapreduce.input.fileinputformat.split.minsize 0 The minimum ...
随机推荐
- 浅谈TCP IP协议栈(二)IP地址
上一节大致了解TCP/IP协议栈是个啥东西,依旧是雾里看花的状态,有很多时候学一门新知识时,开头总是很急躁,无从下手,刚学会一点儿,却发现连点皮毛都不算,成就感太低,所以任何时候学习最重要的是要在合适 ...
- IIS 反向代理到 Apache、Tomcat
将请求的网址重写重定向到其它网址.当80端口被占用无法同时使用两个Web服务的解决方案,使得IIS和Apache Tomcat 共存 环境 WindowServer 2008 IIS7 Apache ...
- (笔记)CTF入门指南
[考项分类] Web: 网页安全 Crypto: 密码学(凯撒密码等) PWN: 对程序逻辑分析 系统漏洞利用 Misc: 杂项 图片隐写 数据还原 脑洞类 信息安全有关的 Reverse: 逆向工程 ...
- Python进程池Pool
''' 进程池,启动一个进程就要克隆一份数据,假设父进程1G,那么启动进程开销很大 避免启动太多造成系统瘫痪,就有进程池,即同一时间允许的进程数量 ps:线程没有池,因为线程启动开销小,线程有类似信号 ...
- SQL CHECK 约束
SQL CHECK 约束 CHECK 约束用于限制列中的值的范围. 如果对单个列定义 CHECK 约束,那么该列只允许特定的值. 如果对一个表定义 CHECK 约束,那么此约束会在特定的列中对值进行限 ...
- Nodejs OracleDB详细解读
//导入oracledb模块 //基于版本@3.0.1 安装指令npm install oracledb //node访问oracleDB需要搭建访问环境,否则无法正常访问 //创建Oracle对象 ...
- SQL学习 DECODE
from 百度百科: DECODE有什么用途呢? 先构造一个例子,假设我们想给这些职员加工资,其标准是:工资在8000元以下的加20%:工资在8000元或以上的加15%,通常的做法是,先选出记录中的工 ...
- Educational Codeforces Round 62 (Rated for Div. 2) Solution
最近省队前联考被杭二成七南外什么的吊锤得布星,拿一场Div. 2恢复信心 然后Div.2 Rk3.Div. 1+Div. 2 Rk9,rating大涨200引起舒适 现在的Div. 2都怎么了,最难题 ...
- 《Java2 实用教程(第五版)》教学进程
目录 <Java2 实用教程(第五版)>教学进程 预备作业1:你期望的师生关系是什么? 预备作业2 :学习基础和C语言基础调查 预备作业3:Linux安装及命令入门 第一周作业 第二周作业 ...
- iOS开发基础篇-手写控件
一.手写控件的步骤 1)使用相应的控件类创建控件对象: 2)设置该控件的各种属性: 3)添加空间到视图中: 4)如果是 UIButton 等控件,还需考虑控件的单击事件等: 二.添加 UIButton ...