MongoDB 3.6.9 集群搭建 - 切片+副本集
1. 环境准备
在Mongo的官网下载Linux版本安装包,然后解压到对应的目录下;由于资源有限,我们采用Replica Sets + Sharding方式来配置高可用。结构图如下所示:
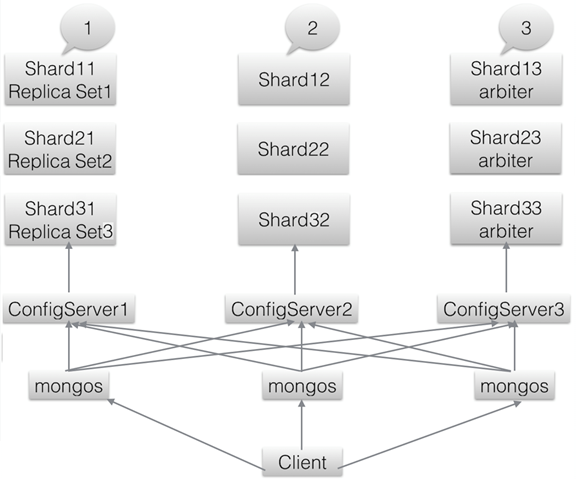
这里我说明下这个图所表达的意思:
Shard服务器:使用Replica Sets确保每个数据节点都具有备份、自动容错转移、自动恢复的能力。
- 配置服务器:使用3个配置服务器确保元数据完整性。
- 路由进程:使用3个路由进程实现平衡,提高客户端接入性能
- 副本集1:Shard11,Shard12,Shard13组成一个副本集,提供Sharding中shard1的功能;
- 副本集2:Shard21,Shard22,Shard23组成一个副本集,提供Sharding中shard2的功能;
- 副本集3:Shard31,Shard32,Shard33组成一个副本集,提供Sharding中shard3的功能;
- 3个配置服务器进程和3个路由器进程。
- Arbiter仲裁者,是副本集中的一个MongoDB实例, 它并不保存数据。仲裁节点使用最小的资源并且不要求硬件设备。为了确保复制集中有奇数的投票成员(包括primary),需要添加仲裁节点作为投票,否则primary不能运行时不会自动切换primary。
构建一个mongoDB Sharding Cluster需要三种角色:shard服务器(ShardServer)、配置服务器(config Server)、路由进程(Route Process)
Shard 服务器
Shard服务器即存储实际数据的分片,每个shard可以是一个mongod实例,也可以是一组mongod实例构成的Replica Sets。为了实现每个Shard内部的故障自动转换,MongoDB官方建议每个shard为一组Replica Sets。
配置服务器
为了将一个特定的collection存储在多个shard中,需要为该collection指定一个shard key,决定该条记录属于哪个chunk,配置服务器可以存储以下信息,每个shard节点的配置信息,每个chunk的shard key范围,chunk在各shard的分布情况,集群中所有DB和collection的sharding配置信息。
路由进程
它是一个前段路由,客户端由此接入,首先询问配置服务器需要到哪个shard上查询或保存记录,然后连接相应的shard执行操作,最后将结果返回给客户端,客户端只需要将原本发给mongod的查询或更新请求原封不动地发给路由进程,而不必关心所操作的记录存储在哪个shard上。
按照架构图,理论上是需要15台机器的,由于资源有限,用目录来替代物理机,下面给出配置表格:
|
192.168.187.201 |
192.168.187.202 |
192.168.187.203 |
|
Shard11:10011 主节点 |
Shard12:10012 副节点 |
Shard13:10013 仲裁点 |
|
Shard21:10021 仲裁点 |
Shard22:10022 主节点 |
Shard32:10023 副节点 |
|
Shard31:10031 副节点 |
Shard32:10032 仲裁点 |
Shard33:10033 主节点 |
|
ConfigSvr:10041 |
ConfigSvr:10042 |
ConfigSvr:10043 |
|
Mongos:10051 |
Mongos:10052 |
Mongos:10053 |
2. 配置Shard + Replica Sets
2.1系统配置
Linux操作系统参数
系统全局允许分配的最大文件句柄数:
sysctl -w fs.file-max=2097152
sysctl -w fs.nr_open=2097152
echo 2097152 > /proc/sys/fs/nr_open
允许当前会话/进程打开文件句柄数:
ulimit -n 1048576
修改 ‘fs.file-max’ 设置到 /etc/sysctl.conf 文件:
fs.file-max = 1048576
修改/etc/security/limits.conf 持久化设置允许用户/进程打开文件句柄数
* soft nofile 1048576
* hard nofile 1048576
* soft nproc 524288
* hard nproc 524288
TCP 协议栈网络参数
并发连接 backlog 设置:
sysctl -w net.core.somaxconn=32768
sysctl -w net.ipv4.tcp_max_syn_backlog=16384
sysctl -w net.core.netdev_max_backlog=16384
可用知名端口范围:
sysctl -w net.ipv4.ip_local_port_range=80 65535'
TCP Socket 读写 Buffer 设置:
sysctl -w net.core.rmem_default=262144
sysctl -w net.core.wmem_default=262144
sysctl -w net.core.rmem_max=16777216
sysctl -w net.core.wmem_max=16777216
sysctl -w net.core.optmem_max=16777216
sysctl -w net.ipv4.tcp_rmem='1024 4096 16777216'
sysctl -w net.ipv4.tcp_wmem='1024 4096 16777216'
TCP 连接追踪设置(Centos7以下才有,以上版本则不用):
sysctl -w net.nf_conntrack_max=1000000
sysctl -w net.netfilter.nf_conntrack_max=1000000
sysctl -w net.netfilter.nf_conntrack_tcp_timeout_time_wait=30
2.2 安装
统一分别在三台机器的/opt/app/mongoCluster369部署mongodb集群。
在linux官网下载mongodb的安装包,目前所用安装包为:mongodb-linux-x86_64-rhel70-3.6.9.tgz
现在以192.168.31.231机器上操作为例:
使用命令tar -zxvf mongodb-linux-x86_64-rhel70-3.6.9.tgz 解压mongodb

解压后查看如下:

把mongodb-linux-x86_64-rhel70-3.6.9移动到指定目录,当前指定目录为/opt/app/,并改名为mongodb

在该台机器上mongodbCluster369目录中建立conf(配置文件)、mongos(路由)、config(配置)、shard1、shard2、shard3(三个切片)六个目录,因为mongos不存储数据,只需要建立日志文件即可。
mkdir -p /opt/app/mongodbCluster369/conf
mkdir -p /opt/app/mongodbCluster369/mongos/log
mkdir -p /opt/app/mongodbCluster369/mongos/pid
mkdir -p /opt/app/mongodbCluster369/config/data
mkdir -p /opt/app/mongodbCluster369/config/log
mkdir -p /opt/app/mongodbCluster369/config/pid
mkdir -p /opt/app/mongodbCluster369/shard1/data
mkdir -p /opt/app/mongodbCluster369/shard1/log
mkdir -p /opt/app/mongodbCluster369/shard1/pid
mkdir -p /opt/app/mongodbCluster369/shard2/data
mkdir -p /opt/app/mongodbCluster369/shard2/log
mkdir -p /opt/app/mongodbCluster369/shard2/pid
mkdir -p /opt/app/mongodbCluster369/shard3/data
mkdir -p /opt/app/mongodbCluster369/shard3/log
mkdir -p /opt/app/mongodbCluster369/shard3/pid
配置环境变量
vi /etc/profile
并添加如下内容:
export MONGODB_HOME=/opt/app/mongodb
export PATH=$PATH:$MONGODB_HOME/bin
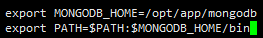
source /etc/profile
使立即生效
2.3 配置分片副本集
设置第一个分片副本集
配置文件
vi /opt/app/mongodbCluster369/conf/shard1.conf

配置文件内容为:
#配置文件内容
systemLog:
destination: file
path: /opt/app/mongodbCluster369/shard1/log/shard1.log
logAppend: true
processManagement:
fork: true
pidFilePath: /opt/app/mongodbCluster369/shard1/pid/shard1.pid
net:
bindIp: 192.168.187.201
port:
maxIncomingConnections:
storage:
dbPath: /opt/app/mongodbCluster369/shard1/data
journal:
enabled: true
commitIntervalMs:
directoryPerDB: true
syncPeriodSecs:
engine: wiredTiger
wiredTiger:
engineConfig:
cacheSizeGB:
statisticsLogDelaySecs:
journalCompressor: snappy
directoryForIndexes: false
collectionConfig:
blockCompressor: snappy
indexConfig:
prefixCompression: true
replication:
oplogSizeMB:
replSetName: shard1
sharding:
clusterRole: shardsvr
设置第二个分片副本集
vi /opt/app/mongodbCluster369/conf/shard2.conf

# 配置文件内容
systemLog:
destination: file
path: /opt/app/mongodbCluster369/shard2/log/shard2.log
logAppend: true
processManagement:
fork: true
pidFilePath: /opt/app/mongodbCluster369/shard2/pid/shard2.pid
net:
bindIp: 192.168.187.201
port:
maxIncomingConnections:
storage:
dbPath: /opt/app/mongodbCluster369/shard2/data
journal:
enabled: true
commitIntervalMs:
directoryPerDB: true
syncPeriodSecs:
engine: wiredTiger
wiredTiger:
engineConfig:
cacheSizeGB:
statisticsLogDelaySecs:
journalCompressor: snappy
directoryForIndexes: false
collectionConfig:
blockCompressor: snappy
indexConfig:
prefixCompression: true
replication:
oplogSizeMB:
replSetName: shard2
sharding:
clusterRole: shardsvr
设置第三个分片副本集
vi /opt/app/mongodbCluster369/conf/shard3.conf

# 配置文件内容
systemLog:
destination: file
path: /opt/app/mongodbCluster369/shard3/log/shard3.log
logAppend: true
processManagement:
fork: true
pidFilePath: /opt/app/mongodbCluster369/shard3/pid/shard3.pid
net:
bindIp: 192.168.187.201
port:
maxIncomingConnections:
storage:
dbPath: /opt/app/mongodbCluster369/shard3/data
journal:
enabled: true
commitIntervalMs:
directoryPerDB: true
syncPeriodSecs:
engine: wiredTiger
wiredTiger:
engineConfig:
cacheSizeGB:
statisticsLogDelaySecs:
journalCompressor: snappy
directoryForIndexes: false
collectionConfig:
blockCompressor: snappy
indexConfig:
prefixCompression: true
replication:
oplogSizeMB:
replSetName: shard3
sharding:
clusterRole: shardsvr
2.4 config server配置服务器
vi /opt/app/mongodbCluster369/conf/config.conf

# 配置文件内容
systemLog:
destination: file
path: /opt/app/mongodbCluster369/config/log/config.log
logAppend: true
processManagement:
fork: true
pidFilePath: /opt/app/mongodbCluster369/config/pid/config.pid
net:
bindIp: 192.168.187.201
port:
maxIncomingConnections:
storage:
dbPath: /opt/app/mongodbCluster369/config/data
journal:
enabled: true
commitIntervalMs:
directoryPerDB: true
syncPeriodSecs:
engine: wiredTiger
replication:
oplogSizeMB:
replSetName: configs
sharding:
clusterRole: configsvr
2.5 配置路由服务器mongos
vi /opt/app/mongodbCluster369/conf/mongos.conf

# 配置文件内容
systemLog:
destination: file
path: /opt/app/mongodbCluster369/mongos/log/mongos.log
logAppend: true
processManagement:
fork: true
pidFilePath: /opt/app/mongodbCluster369/mongos/pid/mongos.pid
net:
bindIp: 192.168.187.201
port:
maxIncomingConnections:
sharding:
configDB: configs/192.168.187.201:,192.168.187.202:,192.168.187.203:
参数说明:
dbpath:数据存放目录
logpath:日志存放路径
pidfilepath:进程文件,方便停止mongodb
logappend:以追加的方式记录日志
directoryperdb:为每一个数据库按照数据库名建立文件夹
replSet:replica set的名字
bindIp:mongodb所绑定的ip地址
port:mongodb进程所使用的端口号,默认为27017
fork:以后台方式运行进程
oplogSize:mongodb操作日志文件的最大大小。单位为Mb,默认为硬盘剩余空间的5%
shardsvr:分片节点
configsvr:配置服务节点
configdb:配置config节点到route节点
journal:写日志
smallfiles:当提示空间不够时添加此参数
noprealloc:预分配方式,使用预分配方式来保证写入性能的稳定,预分配在后台运行,并且每个预分配的文件都用0进行填充。这会让MongoDB始终保持额外的空间和空余的数据文件,从而避免了数据增长过快而带来的分配磁盘空间引起的阻塞。设置noprealloc=true来禁用预分配的数据文件,会缩短启动时间,但在正常操作过程中,可能会导致性能显著下降。
2.6 分别把/opt/app/mongodb安装包和/opt/app/mongodbCluster369配置信息复制到其他两台机器上
使用命令scp -r /opt/app/mongodb root@192.168.187.202:/opt/app 复制mongodb到第二节点:

使用命令scp -r /opt/app/mongodbCluster369 root@192.168.187.202:/opt/app复制mongodbCluster369集群信息到第二节点:

使用root用户登录192.168.187.202第二节点,
然后配置环境变量
vi /etc/profile
并添加如下内容:
export MONGODB_HOME=/opt/app/mongodb
export PATH=$PATH:$MONGODB_HOME/bin

source /etc/profile
使立即生效
cd /opt/app/mongodbCluster369/conf修改切片、副本集、配置、路由5个配置文件里面的IP和端口:
Shard1.conf修改ip:

Shard2.conf修改ip:
Shard3.conf修改ip:

Config.conf修改ip:

Mongos.conf修改ip:
使用命令scp -r /opt/app/mongodb root@192.168.187.203:/opt/app 复制mongodb到第三节点:

使用命令scp -r /opt/app/mongodbCluster369 root@192.168.187.203:/opt/app复制mongodbCluster369集群信息到第三节点:

使用root用户登录192.168.187.203第三节点,
然后配置环境变量
vi /etc/profile
并添加如下内容:
export MONGODB_HOME=/opt/app/mongodb
export PATH=$PATH:$MONGODB_HOME/bin
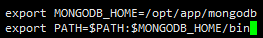
source /etc/profile
使立即生效
cd /opt/app/mongodbCluster369/conf中修改切片、副本集、配置、路由5个配置文件里面的IP和端口:
Shard1.conf修改ip:
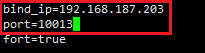
Shard2.conf修改ip:
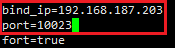
Shard3.conf修改ip:
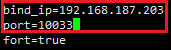
Config.conf修改ip:
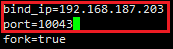
Mongos.conf修改ip:

2.7 启动mongodb集群
先启动配置服务器和分片服务器,后启动路由实例(三台服务器)。
2.7.1启动配置服务器
启动三台服务器的config server
进入mongodb的安装包目录/opt/app/mongodb,使用如下命令启动:
cd /opt/app/mongodb/bin
./mongod -f /opt/app/mongodbCluster369/conf/config.conf

登录任意一台服务器,初始化配置副本集
登录连接命令:./mongo 192.168.187.201:10041/admin

配置如下内容:
> config = {
... _id : "configs",
... members : [
... {_id : 0, host : "192.168.187.201:10041"},
... {_id : 1, host : "192.168.187.202:10042"},
... {_id : 2, host : "192.168.187.203:10043"}
... ]
... }
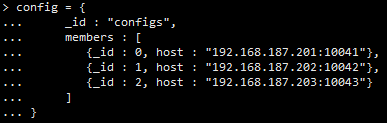
初始化副本集
> rs.initiate(config)
其中,“_id” : “configs” 应与配置文件中配置的replSet一致,“members”中的“host”为三个节点的ip和port
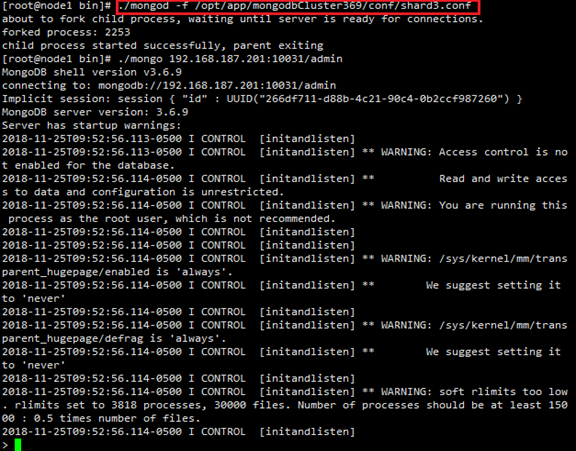
2.7.2 启动分片服务器
l 启动三台服务器的shard1 server
进入mongodb的安装包目录/opt/app/mongodb,使用如下命令启动:
cd /opt/app/mongodb/bin
./mongod -f /opt/app/mongodbCluster369/conf/shard1.conf

登录192.168.187.201一台服务器(192.168.187.203设置为仲裁节点,不能使用该节点登录),初始化分片副本集
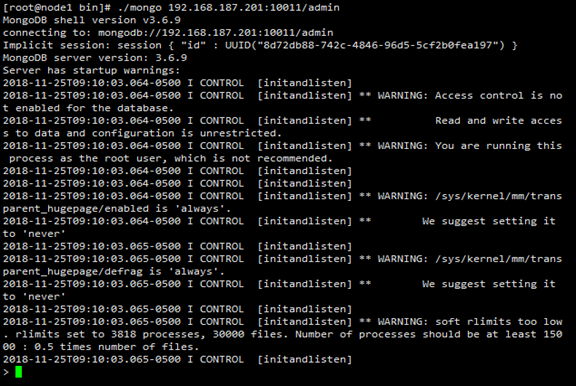
登录连接命令:./mongo 192.168.187.201:10011/admin
配置如下内容:
> config = {
... _id : "shard1",
... members : [
... {_id : 0, host : "192.168.187.201:10011",priority:2},
... {_id : 1, host : "192.168.187.202:10012",priority:1},
... {_id : 2, host : "192.168.187.203:10013", arbiterOnly : true}
... ]
... }
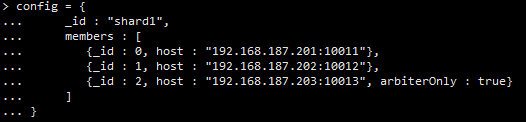
初始化副本集
> rs.initiate(config)

第三个节点的“arbiterOnly”:true代表其为仲裁节点。
使用exit命令退出mongo的shell操作界面
l 启动三台服务器的shard2 server
进入mongodb的安装包目录/opt/app/mongodb,使用如下命令启动:
cd /opt/app/mongodb/bin
./mongod -f /opt/app/mongodbCluster369/conf/shard2.conf

登录192.168.187.202一台服务器(因为192.168.187.201设置为仲裁节点,不能使用该节点登录),初始化分片副本集
登录连接命令:./mongo 192.168.187.202:10022/admin
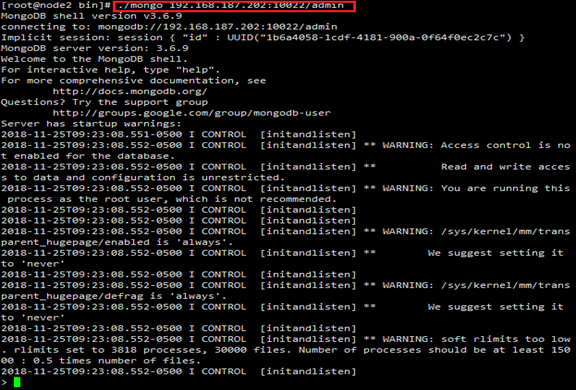
配置如下内容:
> config = {
... _id : "shard2",
... members : [
... {_id : 0, host : "192.168.187.201:10021", arbiterOnly : true },
... {_id : 1, host : "192.168.187.202:10022",priority:2},
... {_id : 2, host : "192.168.187.203:10023",priority:1}
... ]
... }
初始化副本集
> rs.initiate(config)

第一个节点的“arbiterOnly”:true代表其为仲裁节点。
使用exit命令退出mongo的shell操作界面
l 启动三台服务器的shard3 server
进入mongodb的安装包目录/opt/app/mongodb,使用如下命令启动:
cd /opt/app/mongodb/bin
./mongod -f /opt/app/mongodbCluster369/conf/shard3.conf

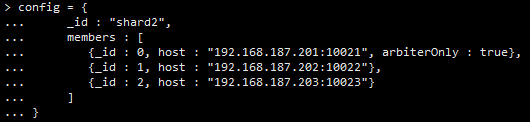
登录192.168.187.201一台服务器(192.168.187.202设置为仲裁节点,不能使用该节点登录),初始化分片副本集
登录连接命令:./mongo 192.168.187.201:10031/admin
配置如下内容:
> config = {
... _id : "shard3",
... members : [
... {_id : 0, host : "192.168.187.201:10031",priority:1},
... {_id : 1, host : "192.168.187.202:10032", arbiterOnly : true },
... {_id : 2, host : "192.168.187.203:10033",priority:2}
... ]
... }

初始化副本集
> rs.initiate(config)

第二个节点的“arbiterOnly”:true代表其为仲裁节点。
使用exit命令退出mongo的shell操作界面
2.7.3启动路由实例
启动三台服务器的mongos server
使用如下命令
进入mongodb的安装包目录/opt/app/mongodb,使用如下命令启动:
cd /opt/app/mongodb/bin
./mongos -f /opt/app/mongodbCluster369/conf/mongos.conf

2.8 启用分片
目前搭建了mongodb配置服务器、路由服务器、各个分片服务器,不过应用程序连接到mongos路由服务器并不能使用分片机制,还需要在程序里设置分片配置,让分片生效。
登录任意一台mongos,这里以192.168.187.201:10051为例:
登录连接命令:./mongo 192.168.187.201:10051/admin

配置如下内容,串联路由服务器与切片副本集:
sh.addShard("shard1/192.168.187.201:10011,192.168.187.202:10012,192.168.187.203:10013")
sh.addShard("shard2/192.168.187.201:10021,192.168.187.202:10022,192.168.187.203:10023")
sh.addShard("shard3/192.168.187.201:10031,192.168.187.202:10032,192.168.187.203:10033")

查看集群状态:
sh.status()
2.9 指定数据库与集合分片生效
目前配置服务、路由服务、分片服务、副本集服务都已经串联起来了,但是我们的目的是希望插入数据、数据能够自动分片。连接在mongos上,准备让指定的数据库、指定的集合分片生效。
接着上面2.6的步骤,不用退出mongos的操作界面
指定数据库分片生效:
db.runCommand({enablesharding : "testdb"})

指定数据库里需要分片的集合collection和片键,一般是_id:
db.runCommand({shardcollection : "testdb.table1", key : {id : "hashed"}})
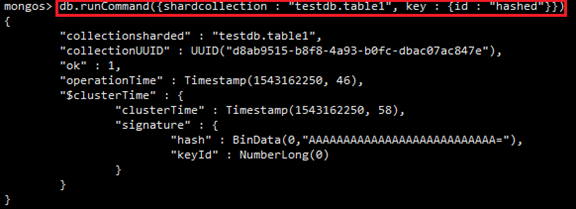
我们设置testdb的table1表需要分片,根据id自动分片到shard1、shard2、shard3上面去。要这样设置是因为不是所有mongodb的数据库和表都需要分片!
2.10 测试分片配置结果
登录任意一台mongos,这里以192.168.187.201:10051为例:
登录连接命令:./mongo 192.168.187.201:10051/admin
切换数据库:
use testdb
输入如下命令:
for (var i = 1; i <= 5000; i++){ db.table1.insert({id:i,text:"hello world"}) }

查看分配状态:
db.table1.stats()
如下图所示:shard1总数:1664条
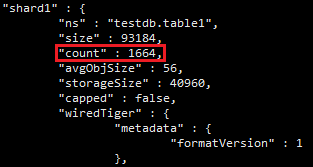
Shard2总数:1684条

Shard3总数:1652条
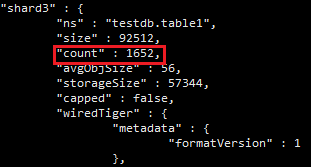
可以看到数据分到3个分片。已经成功了。
3. 后期运维
mongodbd的启动顺序是,先启动配置服务器,再启动分片,最后启动mongos。
mongod -f /opt/app/mongodbCluster369/conf/config.conf
mongod -f /opt/app/mongodbCluster369/conf/shard1.conf
mongod -f /opt/app/mongodbCluster369/conf/shard2.conf
mongod -f /opt/app/mongodbCluster369/conf/shard3.conf
mongos -f /opt/app/mongodbCluster369/conf/mongos.conf
关闭时,直接killall杀掉所有进程
killall mongodkillall mongos4. 问题发现:
问题一:--maxConnx过高

这与linux默认进程能打开最大文件数有关,可以通过ulimit解决.mongodb最大连接是20000
解决:ulimit -n 30000
问题二:报错is not electable under the new configuration version 1
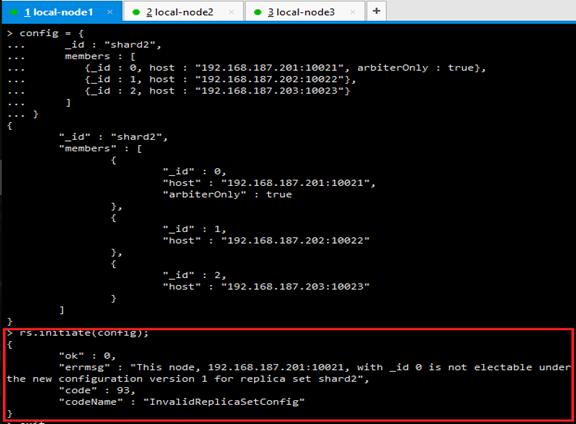
解决:如果你设置的第一个节点是仲裁节点的话,那么设置登录设置节点状态的哪个客户端不能是仲裁节点,简单做法 换一个节点
参考资料:
http://www.ityouknow.com/mongodb/2017/08/05/mongodb-cluster-setup.html
https://www.cnblogs.com/smartloli/p/4305739.html
https://blog.csdn.net/caofeiliju/article/details/80193997
mongodb副本+分片集群添加用户认证密码
https://blog.csdn.net/uncle_david/article/details/78713551
http://www.mongoing.com/docs/tutorial/convert-secondary-into-arbiter.html (从节点切换仲裁节点)
MongoDB 3.6.9 集群搭建 - 切片+副本集的更多相关文章
- mongodb3.6集群搭建:分片+副本集
mongodb是最常用的noSql数据库,在数据库排名中已经上升到了前五.这篇文章介绍如何搭建高可用的mongodb(分片+副本)集群. 在搭建集群之前,需要首先了解几个概念:路由,分片.副本集.配置 ...
- MongoDB集群搭建之副本集模仿主从模式的行为
#模拟主节点异常中断 [root@ba3b27d855f6 bin]# kill -9 199 [root@ba3b27d855f6 bin]# #连接到其中一台备份节点 [root@ba3b27 ...
- mongodb 搭建集群(分片+副本集)
mongodb 搭建集群(分片+副本集) 一.搭建结构图: 二.搭建步骤:
- mongodb 3.4 集群搭建升级版 五台集群
最新版mongodb推荐使用yaml语法来做配置,另外一些旧的配置在最新版本中已经不在生效,所以我们在生产实际搭建mongodb集群的时候做了一些改进.如果大家不熟悉什么是分片.副本集.仲裁者的话请先 ...
- 分布式实时日志系统(一)环境搭建之 Jstorm 集群搭建过程/Jstorm集群一键安装部署
最近公司业务数据量越来越大,以前的基于消息队列的日志系统越来越难以满足目前的业务量,表现为消息积压,日志延迟,日志存储日期过短,所以,我们开始着手要重新设计这块,业界已经有了比较成熟的流程,即基于流式 ...
- 基于Dokcer搭建Redis集群搭建(主从集群)
最近陆陆续续有不少园友加我好友咨询 redis 集群搭建的问题,我觉得之前写的这篇 <基于Docker的Redis集群搭建> 文章一定是有问题了,所以我花了几分钟浏览之前的文章总结了下面几 ...
- Kubernetes集群搭建之Etcd集群配置篇
介绍 etcd 是一个分布式一致性k-v存储系统,可用于服务注册发现与共享配置,具有以下优点. 简单 : 相比于晦涩难懂的paxos算法,etcd基于相对简单且易实现的raft算法实现一致性,并通过g ...
- mongodb分片集群(无副本集)搭建
数据分片节点#192.168.114.26#mongo.cnfport=2001dbpath=/data/mongodb/datalogpath=/data/mongodb/log/mongodb.l ...
- mongodb的分布式集群(2、副本集)
概述 副本集是主从复制的一种,是一种自带故障转移功能的主从复制.攻克了上述主从复制的缺点.实现主server发生问题后.不需人为介入.系统自己主动从新选举一个新的主server的功能. ...
随机推荐
- Elixir 分布式平台
概述 分布式平台的核心在于并发,容错. 而 Elixir 的优势正是在于对于并发和容错的处理. 分布式模型 CSP(Communicating Sequential Process) 模型 :: 多个 ...
- web框架。Django--
一,DIY一个web框架 1.1什么是web框架 1.2用socket模拟B-S的服务端 1.3,浏览器端的network查看 1.4,request格式 1.5,response格式 1.6,初识w ...
- vue 首页问题
(现在其实处于不知道自己不知道状态,前端其实很多东东,不信弄个微博试试,还有那些概念的to thi tha) 1.压缩 一般 vue-cli已经压缩了 比如js 的,一般4M多压缩到 1M,还有css ...
- .NET平台下,初步认识AutoMapper
初步认识AutoMapper AutoMapper 初步认识AutoMapper 前言 手动映射 使用AutoMapper 创建映射 Conventions 映射到一个已存在的实例对象 前言 通常 ...
- linux 网卡的混杂模式的取消
1.Linux下网卡常用的几种模式说明: 广播方式:该模式下的网卡能够接收网络中的广播信息. 组播方式:设置在该模式下的网卡能够接收组播数据. 直接方式:在这种模式下,只有目的网卡才能接收该数据. 混 ...
- pytorch Debug —交互式调试工具Pdb (ipdb是增强版的pdb)-1-在pytorch中使用
参考深度学习框架pytorch:入门和实践一书第六章 以深度学习框架PyTorch一书的学习-第六章-实战指南为前提 在pytorch中Debug pytorch作为一个动态图框架,与ipdb结合能为 ...
- 看门狗芯片--SP706SEN--调试记录
一.前因后果 工程中,设备为了稳定可靠,会增加外部看门狗,但是外部看门狗一旦启动,就停不下来,必须在固定的时间范围内进行喂狗,不然看门狗芯片就会产生一个复位信号复位MCU.以前大家都认为看门狗一旦工作 ...
- vue 2.0 + ElementUI构建树形表格
解决: 本来想在网上博客找一找解决方法,奈何百度到的结果都不尽人意,思维逻辑不清,步骤复杂,代码混乱,找了半天也没找到一个满意的,所以干脆就自己动手写一个 思路: table需要的数据是array,所 ...
- 家庭记账本小程序之查(java web基础版六)
实现查询消费账单 1.main_left.jsp中该部分,调用search.jsp 2.search.jsp,提交到Servlet中的search方法 <%@ page language=&qu ...
- Python的各种推导式合集
推导式的套路 之前我们已经学习了最简单的列表推导式和生成器表达式.但是除此之外,其实还有字典推导式.集合推导式等等. 下面是一个以列表推导式为例的推导式详细格式,同样适用于其他推导式. variabl ...