【转】深入分析 Parquet 列式存储格式
Parquet 是面向分析型业务的列式存储格式,由 Twitter 和 Cloudera 合作开发,2015 年 5 月从 Apache 的孵化器里毕业成为 Apache 顶级项目,最新的版本是 1.8.0。
列式存储
列式存储和行式存储相比有哪些优势呢?
- 可以跳过不符合条件的数据,只读取需要的数据,降低 IO 数据量。
- 压缩编码可以降低磁盘存储空间。由于同一列的数据类型是一样的,可以使用更高效的压缩编码(例如 Run Length Encoding 和 Delta Encoding)进一步节约存储空间。
- 只读取需要的列,支持向量运算,能够获取更好的扫描性能。
当时 Twitter 的日增数据量达到压缩之后的 100TB+,存储在 HDFS 上,工程师会使用多种计算框架(例如 MapReduce, Hive, Pig 等)对这些数据做分析和挖掘;日志结构是复杂的嵌套数据类型,例如一个典型的日志的 schema 有 87 列,嵌套了 7 层。所以需要设计一种列式存储格式,既能支持关系型数据(简单数据类型),又能支持复杂的嵌套类型的数据,同时能够适配多种数据处理框架。
关系型数据的列式存储,可以将每一列的值直接排列下来,不用引入其他的概念,也不会丢失数据。关系型数据的列式存储比较好理解,而嵌套类型数据的列存储则会遇到一些麻烦。如图 1 所示,我们把嵌套数据类型的一行叫做一个记录(record),嵌套数据类型的特点是一个 record 中的 column 除了可以是 Int, Long, String 这样的原语(primitive)类型以外,还可以是 List, Map, Set 这样的复杂类型。在行式存储中一行的多列是连续的写在一起的,在列式存储中数据按列分开存储,例如可以只读取 A.B.C 这一列的数据而不去读 A.E 和 A.B.D,那么如何根据读取出来的各个列的数据重构出一行记录呢?
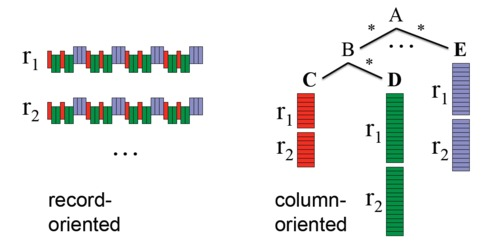
图 1 行式存储和列式存储
Google 的Dremel系统解决了这个问题,核心思想是使用“record shredding and assembly algorithm”来表示复杂的嵌套数据类型,同时辅以按列的高效压缩和编码技术,实现降低存储空间,提高 IO 效率,降低上层应用延迟。Parquet 就是基于 Dremel 的数据模型和算法实现的。
Parquet 适配多种计算框架
Parquet 是语言无关的,而且不与任何一种数据处理框架绑定在一起,适配多种语言和组件,能够与 Parquet 配合的组件有:
查询引擎: Hive, Impala, Pig, Presto, Drill, Tajo, HAWQ, IBM Big SQL
计算框架: MapReduce, Spark, Cascading, Crunch, Scalding, Kite
数据模型: Avro, Thrift, Protocol Buffers, POJOs
那么 Parquet 是如何与这些组件协作的呢?这个可以通过图 2 来说明。数据从内存到 Parquet 文件或者反过来的过程主要由以下三个部分组成:
1, 存储格式 (storage format)
parquet-format项目定义了 Parquet 内部的数据类型、存储格式等。
2, 对象模型转换器 (object model converters)
这部分功能由parquet-mr项目来实现,主要完成外部对象模型与 Parquet 内部数据类型的映射。
3, 对象模型 (object models)
对象模型可以简单理解为内存中的数据表示,Avro, Thrift, Protocol Buffers, Hive SerDe, Pig Tuple, Spark SQL InternalRow 等这些都是对象模型。Parquet 也提供了一个example object model帮助大家理解。
例如parquet-mr项目里的 parquet-pig 项目就是负责把内存中的 Pig Tuple 序列化并按列存储成 Parquet 格式,以及反过来把 Parquet 文件的数据反序列化成 Pig Tuple。
这里需要注意的是 Avro, Thrift, Protocol Buffers 都有他们自己的存储格式,但是 Parquet 并没有使用他们,而是使用了自己在parquet-format项目里定义的存储格式。所以如果你的应用使用了 Avro 等对象模型,这些数据序列化到磁盘还是使用的parquet-mr定义的转换器把他们转换成 Parquet 自己的存储格式。
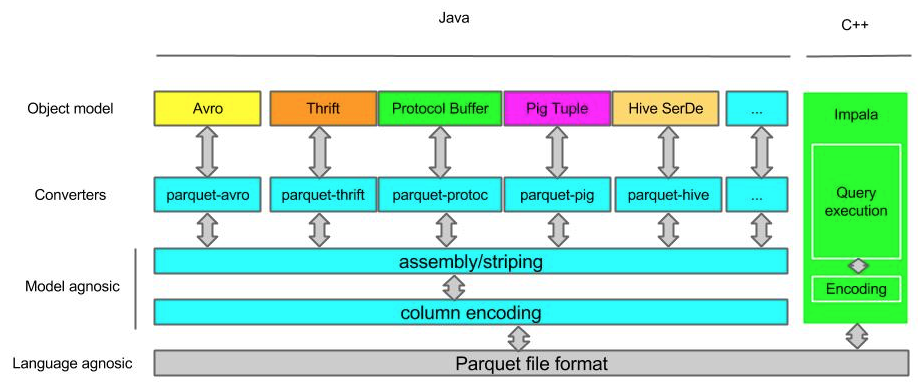
图 2 Parquet 项目的结构
Parquet 数据模型
理解 Parquet 首先要理解这个列存储格式的数据模型。我们以一个下面这样的 schema 和数据为例来说明这个问题。
message AddressBook {
required string owner;
repeated string ownerPhoneNumbers;
repeated group contacts {
required string name;
optional string phoneNumber;
}
}
这个 schema 中每条记录表示一个人的 AddressBook。有且只有一个 owner,owner 可以有 0 个或者多个 ownerPhoneNumbers,owner 可以有 0 个或者多个 contacts。每个 contact 有且只有一个 name,这个 contact 的 phoneNumber 可有可无。这个 schema 可以用图 3 的树结构来表示。
每个 schema 的结构是这样的:根叫做 message,message 包含多个 fields。每个 field 包含三个属性:repetition, type, name。repetition 可以是以下三种:required(出现 1 次),optional(出现 0 次或者 1 次),repeated(出现 0 次或者多次)。type 可以是一个 group 或者一个 primitive 类型。
Parquet 格式的数据类型没有复杂的 Map, List, Set 等,而是使用 repeated fields 和 groups 来表示。例如 List 和 Set 可以被表示成一个 repeated field,Map 可以表示成一个包含有 key-value 对的 repeated field,而且 key 是 required 的。
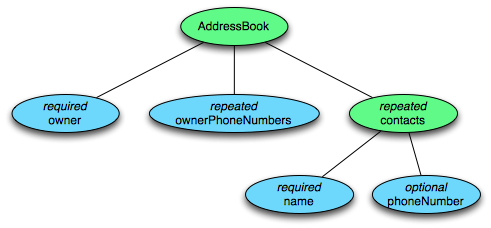
图 3 AddressBook 的树结构表示
Parquet 文件的存储格式
那么如何把内存中每个 AddressBook 对象按照列式存储格式存储下来呢?
在 Parquet 格式的存储中,一个 schema 的树结构有几个叶子节点,实际的存储中就会有多少 column。例如上面这个 schema 的数据存储实际上有四个 column,如图 4 所示。
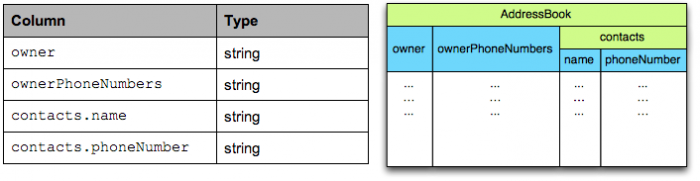
图 4 AddressBook 实际存储的列
Parquet 文件在磁盘上的分布情况如图 5 所示。所有的数据被水平切分成 Row group,一个 Row group 包含这个 Row group 对应的区间内的所有列的 column chunk。一个 column chunk 负责存储某一列的数据,这些数据是这一列的 Repetition levels, Definition levels 和 values(详见后文)。一个 column chunk 是由 Page 组成的,Page 是压缩和编码的单元,对数据模型来说是透明的。一个 Parquet 文件最后是 Footer,存储了文件的元数据信息和统计信息。Row group 是数据读写时候的缓存单元,所以推荐设置较大的 Row group 从而带来较大的并行度,当然也需要较大的内存空间作为代价。一般情况下推荐配置一个 Row group 大小 1G,一个 HDFS 块大小 1G,一个 HDFS 文件只含有一个块。
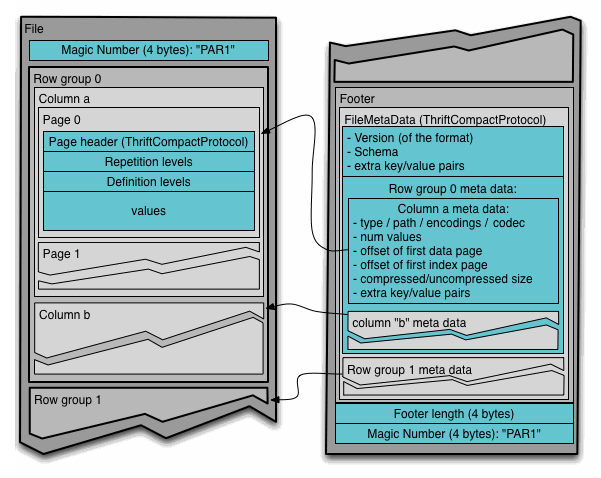
图 5 Parquet 文件格式在磁盘的分布
拿我们的这个 schema 为例,在任何一个 Row group 内,会顺序存储四个 column chunk。这四个 column 都是 string 类型。这个时候 Parquet 就需要把内存中的 AddressBook 对象映射到四个 string 类型的 column 中。如果读取磁盘上的 4 个 column 要能够恢复出 AddressBook 对象。这就用到了我们前面提到的 “record shredding and assembly algorithm”。
Striping/Assembly 算法
对于嵌套数据类型,我们除了存储数据的 value 之外还需要两个变量 Repetition Level(R), Definition Level(D) 才能存储其完整的信息用于序列化和反序列化嵌套数据类型。Repetition Level 和 Definition Level 可以说是为了支持嵌套类型而设计的,但是它同样适用于简单数据类型。在 Parquet 中我们只需定义和存储 schema 的叶子节点所在列的 Repetition Level 和 Definition Level。
Definition Level
嵌套数据类型的特点是有些 field 可以是空的,也就是没有定义。如果一个 field 是定义的,那么它的所有的父节点都是被定义的。从根节点开始遍历,当某一个 field 的路径上的节点开始是空的时候我们记录下当前的深度作为这个 field 的 Definition Level。如果一个 field 的 Definition Level 等于这个 field 的最大 Definition Level 就说明这个 field 是有数据的。对于 required 类型的 field 必须是有定义的,所以这个 Definition Level 是不需要的。在关系型数据中,optional 类型的 field 被编码成 0 表示空和 1 表示非空(或者反之)。
Repetition Level
记录该 field 的值是在哪一个深度上重复的。只有 repeated 类型的 field 需要 Repetition Level,optional 和 required 类型的不需要。Repetition Level = 0 表示开始一个新的 record。在关系型数据中,repetion level 总是 0。
下面用 AddressBook 的例子来说明 Striping 和 assembly 的过程。
对于每个 column 的最大的 Repetion Level 和 Definition Level 如图 6 所示。
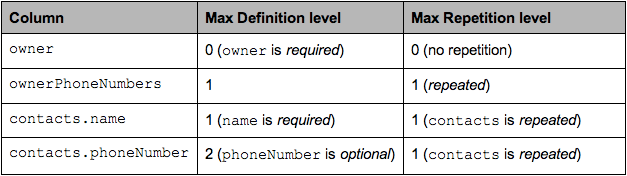
图 6 AddressBook 的 Max Definition Level 和 Max Repetition Level
下面这样两条 record:
AddressBook {
owner: "Julien Le Dem",
ownerPhoneNumbers: "555 123 4567",
ownerPhoneNumbers: "555 666 1337",
contacts: {
name: "Dmitriy Ryaboy",
phoneNumber: "555 987 6543",
},
contacts: {
name: "Chris Aniszczyk"
}
}
AddressBook {
owner: "A. Nonymous"
}
以 contacts.phoneNumber 这一列为例,"555 987 6543"这个 contacts.phoneNumber 的 Definition Level 是最大 Definition Level=2。而如果一个 contact 没有 phoneNumber,那么它的 Definition Level 就是 1。如果连 contact 都没有,那么它的 Definition Level 就是 0。
下面我们拿掉其他三个 column 只看 contacts.phoneNumber 这个 column,把上面的两条 record 简化成下面的样子:
AddressBook {
contacts: {
phoneNumber: "555 987 6543"
}
contacts: {
}
}
AddressBook {
}
这两条记录的序列化过程如图 7 所示:
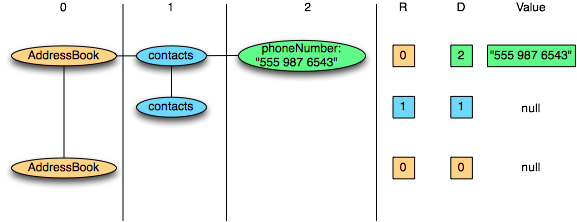
图 7 一条记录的序列化过程
如果我们要把这个 column 写到磁盘上,磁盘上会写入这样的数据(图 8):
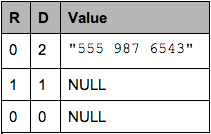
图 8 一条记录的磁盘存储
注意:NULL 实际上不会被存储,如果一个 column value 的 Definition Level 小于该 column 最大 Definition Level 的话,那么就表示这是一个空值。
下面是从磁盘上读取数据并反序列化成 AddressBook 对象的过程:
1,读取第一个三元组 R=0, D=2, Value=”555 987 6543”
R=0 表示是一个新的 record,要根据 schema 创建一个新的 nested record 直到 Definition Level=2。
D=2 说明 Definition Level=Max Definition Level,那么这个 Value 就是 contacts.phoneNumber 这一列的值,赋值操作 contacts.phoneNumber=”555 987 6543”。
2,读取第二个三元组 R=1, D=1
R=1 表示不是一个新的 record,是上一个 record 中一个新的 contacts。
D=1 表示 contacts 定义了,但是 contacts 的下一个级别也就是 phoneNumber 没有被定义,所以创建一个空的 contacts。
3,读取第三个三元组 R=0, D=0
R=0 表示一个新的 record,根据 schema 创建一个新的 nested record 直到 Definition Level=0,也就是创建一个 AddressBook 根节点。
可以看出在 Parquet 列式存储中,对于一个 schema 的所有叶子节点会被当成 column 存储,而且叶子节点一定是 primitive 类型的数据。对于这样一个 primitive 类型的数据会衍生出三个 sub columns (R, D, Value),也就是从逻辑上看除了数据本身以外会存储大量的 Definition Level 和 Repetition Level。那么这些 Definition Level 和 Repetition Level 是否会带来额外的存储开销呢?实际上这部分额外的存储开销是可以忽略的。因为对于一个 schema 来说 level 都是有上限的,而且非 repeated 类型的 field 不需要 Repetition Level,required 类型的 field 不需要 Definition Level,也可以缩短这个上限。例如对于 Twitter 的 7 层嵌套的 schema 来说,只需要 3 个 bits 就可以表示这两个 Level 了。
对于存储关系型的 record,record 中的元素都是非空的(NOT NULL in SQL)。Repetion Level 和 Definition Level 都是 0,所以这两个 sub column 就完全不需要存储了。所以在存储非嵌套类型的时候,Parquet 格式也是一样高效的。
上面演示了一个 column 的写入和重构,那么在不同 column 之间是怎么跳转的呢,这里用到了有限状态机的知识,详细介绍可以参考Dremel。
数据压缩算法
列式存储给数据压缩也提供了更大的发挥空间,除了我们常见的 snappy, gzip 等压缩方法以外,由于列式存储同一列的数据类型是一致的,所以可以使用更多的压缩算法。
|
压缩算法 |
使用场景 |
|
Run Length Encoding |
重复数据 |
|
Delta Encoding |
有序数据集,例如 timestamp,自动生成的 ID,以及监控的各种 metrics |
|
Dictionary Encoding |
小规模的数据集合,例如 IP 地址 |
|
Prefix Encoding |
Delta Encoding for strings |
性能
Parquet 列式存储带来的性能上的提高在业内已经得到了充分的认可,特别是当你们的表非常宽(column 非常多)的时候,Parquet 无论在资源利用率还是性能上都优势明显。具体的性能指标详见参考文档。
Spark 已经将 Parquet 设为默认的文件存储格式,Cloudera 投入了很多工程师到 Impala+Parquet 相关开发中,Hive/Pig 都原生支持 Parquet。Parquet 现在为 Twitter 至少节省了 1/3 的存储空间,同时节省了大量的表扫描和反序列化的时间。这两方面直接反应就是节约成本和提高性能。
如果说 HDFS 是大数据时代文件系统的事实标准的话,Parquet 就是大数据时代存储格式的事实标准。
参考文档
- http://parquet.apache.org/
- https://blog.twitter.com/2013/dremel-made-simple-with-parquet
- http://blog.cloudera.com/blog/2015/04/using-apache-parquet-at-appnexus/
- http://blog.cloudera.com/blog/2014/05/using-impala-at-scale-at-allstate/
【转】深入分析 Parquet 列式存储格式的更多相关文章
- 深入分析Parquet列式存储格式【转】
Parquet是面向分析型业务的列式存储格式,由Twitter和Cloudera合作开发,2015年5月从Apache的孵化器里毕业成为Apache顶级项目,最新的版本是1.8.0. 列式存储 列式存 ...
- 深入分析Parquet列式存储格式
Parquet是面向分析型业务的列式存储格式,由Twitter和Cloudera合作开发,2015年5月从Apache的孵化器里毕业成为Apache顶级项目,最新的版本是1.8.0. 列式存储 列式存 ...
- Parquet 列式存储格式
Parquet 列式存储格式 参考文章: https://blog.csdn.net/kangkangwanwan/article/details/78656940 http://parquet.ap ...
- Parquet列式存储格式
Parquet是面向分析型业务的列式存储格式,由Twitter和Cloudera合作开发,2015年5月从Apache的孵化器里毕业成为Apache顶级项目,最新的版本是1.8.0. 列式存储 列式存 ...
- parquet列式文件实战(未完,待续)
parquet列式文件实战 parquet code demo http://www.programcreek.com/java-api-examples/index.php?source_dir=h ...
- Parquet与ORC:高性能列式存储格式(收藏)
背景 随着大数据时代的到来,越来越多的数据流向了Hadoop生态圈,同时对于能够快速的从TB甚至PB级别的数据中获取有价值的数据对于一个产品和公司来说更加重要,在Hadoop生态圈的快速发展过程中,涌 ...
- Hadoop-No.4之列式存储格式
列式系统可提供的优势 对于查询内容之外的列,不必执行I/O和解压(若适用)操作 非常适合仅访问小部分列的查询.如果访问的列很多,则行存格式更为合适 相比由多行构成的数据块,列内的信息熵更低,所以从压缩 ...
- parquet列式文件实战
前言 列式文件,顾名思义就是按列存储到文件,和行式存储文件对应.保证了一列在一个文件中是连续的.下面从parquet常见术语,核心schema和文件结构来深入理解.最后通过java api完成writ ...
- Hadoop IO基于文件的数据结构详解【列式和行式数据结构的存储策略】
Charles所有关于hadoop的文章参考自hadoop权威指南第四版预览版 大家可以去safari免费阅读其英文预览版.本人也上传了PDF版本在我的资源中可以免费下载,不需要C币,点击这里下载. ...
随机推荐
- Dynamics 365使用代码发送邮件给指定邮箱地址
摘要: 微软动态CRM专家罗勇 ,回复303或者20190213可方便获取本文,同时可以在第一间得到我发布的最新博文信息,follow me!我的网站是 www.luoyong.me . 当然,首先要 ...
- 德国慕尼黑.NET俱乐部VS2019发布活动
就在广州.NET俱乐部紧锣密鼓的准备配合VS2019发布搞一场大Party的时候,德国慕尼黑.NET俱乐部早就已经对外宣布他们将会配合VS2019发布搞两场活动,注意,是两场哦,不是一场哦. 第一场是 ...
- iOS----------随机色
#define KColorRandomColor [UIColor colorWithRed:arc4random()%255/255.0 green:arc4random()%255/255.0 ...
- 南京邮电大学java程序设计作业在线编程第七次作业
王利国的"Java语言程序设计第7次作业(2018)"详细 主页 我的作业列表 作业结果详细 总分:100 选择题得分:60 1. 下列叙述中,错误的是( ). A.Java中, ...
- JHipster生成微服务架构的应用栈(一)- 准备工作
本系列文章演示如何用JHipster生成一个微服务架构风格的应用栈. 环境需求:安装好JHipster开发环境的CentOS 7.4(参考这里) 应用栈名称:appstack 认证微服务: uaa 业 ...
- OV摄像头图像采集基础知识总结
目前FPGA用于图像采集 传输 处理 显示应用越来越多,主要原因是图像处理领域的火热以及FPGA强大的并行处理能力.本文以OV7725为例,对摄像头使用方面的基础知识做个小的总结,为后续做个铺垫. 下 ...
- Java中console类的简单用法
Java.io.Console 只能用在标准输入.输出流未被重定向的原始控制台中使用,在 Eclipse 或者其他 IDE 的控制台是用不了的. import java.io.Console; pub ...
- 第三节 pandas续集
import pandas as pd from pandas import Series from pandas import DataFrame import numpy as np 一 创建多层 ...
- SQL MAX() 函数
MAX() 函数 MAX 函数返回一列中的最大值.NULL 值不包括在计算中. SQL MAX() 语法 SELECT MAX(column_name) FROM table_name 注释:MIN ...
- SQL LCASE() 函数
LCASE() 函数 LCASE 函数把字段的值转换为小写. SQL LCASE() 语法 SELECT LCASE(column_name) FROM table_name SQL LCASE() ...