NLP自然语言处理原理及名词介绍
1. 自然语言概念
自然语言,即我们人类日常所使用的语言,是人类交际的重要方式,也是人类区别其他动物的本质特征。
但是我们只能通过自然语言与人交流,无法与计算机进行交流。
2. 自然语言处理
自然语言处理,是人工智能的一部分,实现了人与计算机之间的有效通信。自然语言处理属于计算机科学领域与人工智能领域,其研究使用计算机编程来处理和理解人类的语言。
3. 应用场景
- 情感分析(从一段文本中提取该文本的感情色彩,是褒义、中性还是贬义)
- 机器翻译
- 文本相似度匹配(从多段文本中,分析两段文本内容的相似度)
- 智能客服(就是聊天机器人)
4. 自然语言处理通用技术
(1) 分词
概念:将连续的文本,分割成语义合理的若干词汇序列。
例如:阿里云自然语言处理,通过分词器,转变为 阿里云/自然/语言/处理
(2) 停用词过滤
概念:在文本中大量存在,但对语义分析没有帮助的词。
例如:呢、啊、吗。。。
(3) 词干提取
概念:对单词去掉后缀,还原词本身。词干提取主要用在英文等西方语言中。
例如:being —> be
(4) 词形还原
概念:对同一单词不同形式的识别,将单词还原为标准形式。主要用在英文等西方语言中。
例如:is, am, are —> be
比较:词干提取与词形还原
相同点:都是对同一单词的不同格式进行处理
不同点:词干提取是去掉单词的后缀;词形还原是以词元为依据,根据语义进行分析,获取单词的标准形式。
例如:ate =>at(词干提取)
ate =>eat(词形还原)
(5) 词袋模型
概念:是用来将文本转换成特征向量的表示形式。将每个文档构建一个特征向量,其中包含每个单词在文档中出现次数。
缺点:
- 忽略了大众词(在文档中也经常出现)
- 特征向量特别多
(6) TF-IDF
概念:指词频-逆文档频率。针对词语重要性的一种加权统计方式。全称:Term Frequency-Inverse Document Frequency。
场合:常用在信息检索、文本挖掘等技术中,作为加权因子。
TF-IDF的核心思想为词条的重要性随着该词条在当前文档中出现的次数成正比增加,但同时会随着它在语料库(所有文档)中出现的频率成反比下降。
公式:TF-IDF = TF(词频) * IDF(逆文档频率)
含义解释:
TF:词频统计,对文章中词语出现的频率进行计数统计
TF = (当前的文档单词出现的次数)/(当前的文档中包含的单词总数)
IDF:逆文档频率,指语料库中文档总数与语料库中包含该词的文档数,二者比值的对数。
IDF = log((语料库中文档总数)/(语料库中包含该词的文档数+1))
例子:
昨夜星辰昨夜风
我们一起学习自然语言处理
昨夜下了一场大雨
星期二是晴天
计算第一个文档"昨夜"的TF-IDF值?
TF(昨夜) = 2/4
IDF(昨夜) = log(4/(2+1))
TF-IDF = TF * IDF = 1/2*log(4/3)
(7) Word2Vec
概念:是google2013年提出的一个开源算法,使用神经网络技术,可以将词表转换成向量表示。确切的说,将词映射成n维空间向量,特征纬度n视具体情况与需求而定。
核心思想:通过将词条转换成向量,从而根据余弦相似度来计算文本之间的相似度。
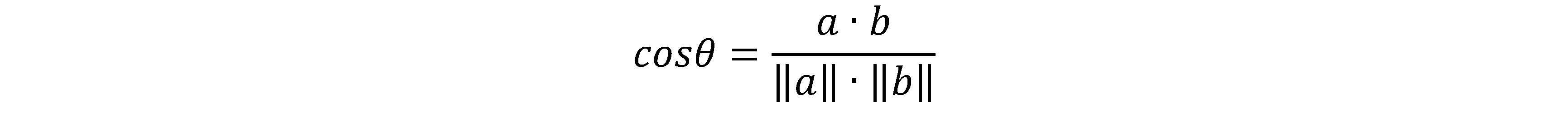
cosθ=a∙ba∙b
NLP自然语言处理原理及名词介绍的更多相关文章
- 郑捷2017年电子工业出版社出版的图书《NLP汉语自然语言处理原理与实践》
郑捷2017年电子工业出版社出版的图书<NLP汉语自然语言处理原理与实践> 第1章 中文语言的机器处理 1 1.1 历史回顾 2 1.1.1 从科幻到现实 2 1.1.2 早期的探索 3 ...
- 学习NLP:《自然语言处理原理与技术实现(罗刚)》PDF+代码
自然语言处理技术已经深入我们的日常生活.我们经常用到的搜索引擎就用到了自然语言理解等自然语言处理技术.自然语言处理是一门交叉学科,涉及计算机.数学.语言学等领域的知识. <自然语言处理原理与技术 ...
- NLP 自然语言处理实战
前言 自然语言处理 ( Natural Language Processing, NLP) 是计算机科学领域与人工智能领域中的一个重要方向.它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和 ...
- Atitit 自然语言处理原理与实现 attilax总结
Atitit 自然语言处理原理与实现 attilax总结 1.1. 中文分词原理与实现 111 1.2. 英文分析 1941 1.3. 第6章 信息提取 2711 1.4. 第7章 自动摘要 3041 ...
- Nmap原理-01选项介绍
Nmap原理-01选项介绍 1.Nmap原理图 Nmap包含四项基本功能:主机发现/端口扫描/版本探测/操作系统探测.这四项功能之间存在大致的依赖关系,比如图片中的先后关系,除此之外,Nmap还提供规 ...
- flask 第六章 人工智能 百度语音合成 识别 NLP自然语言处理+simnet短文本相似度 图灵机器人
百度智能云文档链接 : https://cloud.baidu.com/doc/SPEECH/index.html 1.百度语音合成 概念: 顾名思义,就是将你输入的文字合成语音,例如: from a ...
- JVM垃圾回收器原理及使用介绍
JVM垃圾回收器原理及使用介绍 垃圾收集基础 引用计数法(Reference Counting) 标记-清除算法(Mark-Sweep) 复制算法(Copying) 标记-压缩算法(Mark-Comp ...
- 云小课|MRS基础原理之MapReduce介绍
阅识风云是华为云信息大咖,擅长将复杂信息多元化呈现,其出品的一张图(云图说).深入浅出的博文(云小课)或短视频(云视厅)总有一款能让您快速上手华为云.更多精彩内容请单击此处. 摘要:MapReduce ...
- NLP自然语言处理中英文分词工具集锦与基本使用介绍
一.中文分词工具 (1)Jieba (2)snowNLP分词工具 (3)thulac分词工具 (4)pynlpir 分词工具 (5)StanfordCoreNLP分词工具 1.from stanfor ...
随机推荐
- js中如何向json数组添加元素
//1. var jsonstr="[{'name':'a','value':1},{'name':'b','value':2}]"; var jsonarray = eval(' ...
- HDU1166-ZKW树
单点修改,区间求和 // // Created by helica on 2018/3/18. // //zkw #include <cstdio> #include <cstrin ...
- 关系型数据库管理系统(RDBMS)与非关系型数据库(NoSQL)之间的区别
简介 关系型数据库管理系统(RDBMS)是建立在关系模型基础上的数据库,主要代表有:Microsoft SQL Server,Oracle,MySQL(开源). 非关系型数据库(NoSQL),主要代表 ...
- Codeforces Round #549 (Div. 2) 训练实录 (5/6)
The Doors +0 找出输入的01数列里,0或者1先出完的的下标. Nirvana +3 输入n,求1到n的数字,哪个数逐位相乘的积最大,输出最大积. 思路是按位比较,从低到高,依次把小位换成全 ...
- 关联分析Apriori算法和FP-growth算法初探
1. 关联分析是什么? Apriori和FP-growth算法是一种关联算法,属于无监督算法的一种,它们可以自动从数据中挖掘出潜在的关联关系.例如经典的啤酒与尿布的故事.下面我们用一个例子来切入本文对 ...
- JavaScript 修改 CSS 伪类属性
背景 有时候我们希望通过JS代码控制伪类属性, 确苦于对策 实际上可通过向document.head中添加style子元素来实现 演示 function css(style_text) { var s ...
- css 修改placeholder的颜色
input::-webkit-input-placeholder { color: #ff0000; } input::-moz-input-placeholder { color: #ff0000; ...
- 一道Python面试题:给出d = [True, False, True, False, True],请利用列表d,只用一句话返回列表[0,2,4]
看题:给出d = [True, False, True, False, True],请利用列表d,只用一句话返回列表[0,2,4] 这道题的关键是拿到True的索引值,最初我是用list的index方 ...
- Codeforces Round #541 (Div. 2)题解
不知道该更些什么 随便写点东西吧 https://codeforces.com/contest/1131 ABC 太热了不写了 D 把相等的用并查集缩在一起 如果$ x<y$则从$ x$往$y$ ...
- MySQL中使用group_concat()函数数据字符过长报错的问题解决方法
最近在办公软件项目,在开发权限指标遇到一个问题:我们系统的一些逻辑处理是用存储过程实现的,但是有一天客户反馈说权限指标分配报错,查了分配的权限数据牵扯到的数据权限基础资源,没有问题.权限指标分配的存储 ...