第3章---数据探索(python数据挖掘)
1.缺失值分析及箱型图
数据:catering_sale.xls(餐饮日销额数)
缺失值使用函数:describe()函数,能算出数据集的八个统计量
import pandas as pd
catering_sale = r'.\catering_sale.xls' #餐饮数据
data = pd.read_excel(catering_sale, index_col=u'日期') # 读取数据,指定“日期”列为索引
describe = data.describe() #describe()函数能算出数据集的八个统计量
print(describe)
count = describe.loc['count'] #loc统计对应的数值
print("缺失值为:% d" % (len(data) - int(count))) # 记录有201条,但count只有200,说明缺失值数为1
结果: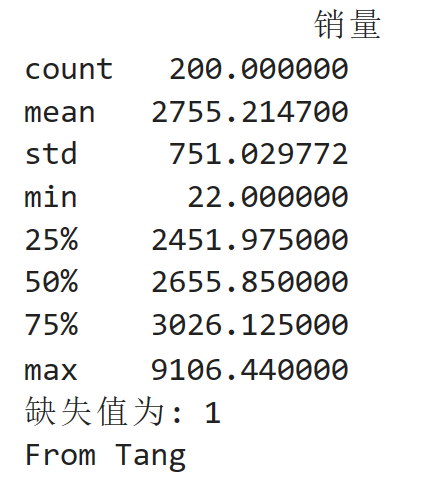 分析:该数据表有一个缺失值,其中共有200个数据,最大值为2755.2147,最小值为22.00
分析:该数据表有一个缺失值,其中共有200个数据,最大值为2755.2147,最小值为22.00
极差-变异系数-四分位数间距:
data = pd.read_excel(catering_sale, index_col = u'日期') #读取数据,指定“日期”列为索引列
data = data[(data[u'销量'] > 400)&(data[u'销量'] < 5000)] #过滤异常数据
statistics = data.describe() #保存基本统计量 statistics.loc['range'] = statistics.loc['max']-statistics.loc['min'] #极差
statistics.loc['var'] = statistics.loc['std']/statistics.loc['mean'] #变异系数
statistics.loc['dis'] = statistics.loc['75%']-statistics.loc['25%'] #四分位数间距 print(statistics)
结果: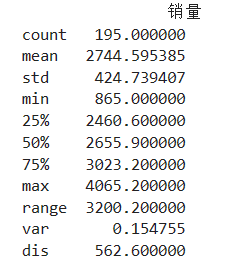
箱型图:
# 画出数据的箱线图
import matplotlib.pyplot as plt # 导入图像库 plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签,plt.reParams是一个配置表
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 plt.figure()
p = data.boxplot(return_type='dict') # 画箱线图,处理异常值
x = p['fliers'][0].get_xdata() # 'flies'即为异常值的标签
y = p['fliers'][0].get_ydata()
y.sort() for i in range(len(x)):
if i>0:
plt.annotate(y[i], xy = (x[i],y[i]), xytext=(x[i]+0.05 -0.8/(y[i]-y[i-1]),y[i]))
else:
plt.annotate(y[i], xy = (x[i],y[i]), xytext=(x[i]+0.08,y[i])) plt.title('3148Tang-箱型图',fontsize=15)
plt.show()

分析:由图看出有一个离群点,大部分数据集中在2000-4000之间,也有少部分数据位于下界,箱型图提供了一个异常值标准
2.频率分布直方图
数据:catering_fish_congee.xls (“捞起生鱼片”每日销售额)
频率直方图:
# 代码3-3 捞起生鱼片的季度销售情况
import pandas as pd
import numpy as np
catering_sale = './catering_fish_congee.xls' # 餐饮数据
data = pd.read_excel(catering_sale,names=['date','sale']) # 读取数据,指定“日期”列为索引 bins = [0,500,1000,1500,2000,2500,3000,3500,4000]
labels = ['[0,500)','[500,1000)','[1000,1500)','[1500,2000)',
'[2000,2500)','[2500,3000)','[3000,3500)','[3500,4000)'] data['sale分层'] = pd.cut(data.sale, bins, labels=labels)
# aggResult = data.groupby(by=['sale分层'])['sale'].agg({'sale',np.size})
aggResult = data.groupby(by=['sale分层'])['sale'].agg(np.size)
print(aggResult) pAggResult = round(aggResult/aggResult.sum(), 2, ) * 100
print(pAggResult) import matplotlib.pyplot as plt
plt.figure(figsize=(10,6)) # 设置图框大小尺寸
pAggResult.plot(kind='bar',width=0.8,fontsize=10) # 绘制频率直方图
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.title('3148-Tang季度销售额频率分布直方图',fontsize=20)
plt.show()
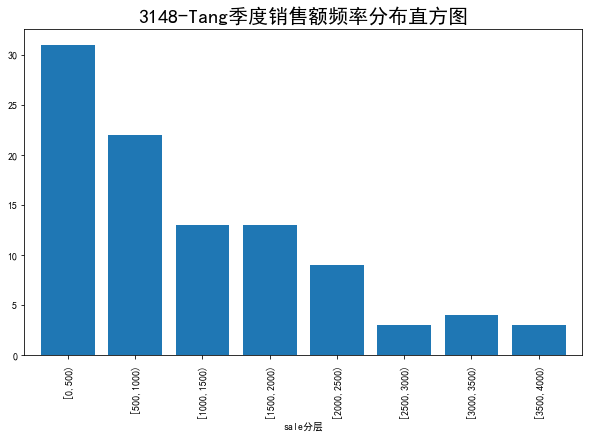
3.绘制饼图
数据:catering_dish_profit.xls (不同菜品在某段时间的销售分布)
import pandas as pd
import matplotlib.pyplot as plt
catering_dish_profit = './catering_dish_profit.xls' # 餐饮数据
data = pd.read_excel(catering_dish_profit) # 读取数据 #绘制饼图
x = data['盈利']
labels = data['菜品名']
plt.figure(figsize=(10,6)) # 设置图框大小尺寸
plt.pie(x,labels=labels)# 绘制饼图
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.title('3148-Tang菜品销售量分布(饼图)',fontsize=15)
plt.axis('equal')
plt.show()
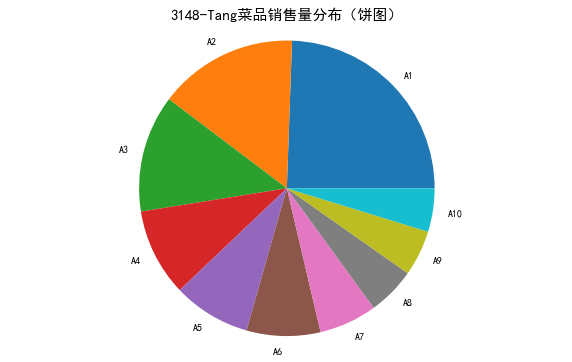
4.条形图:
#绘制条形图
x = data['菜品名']
y = data['盈利']
plt.figure(figsize=(10,6)) # 设置图框大小尺寸
plt.bar(x,y,color='g')# 绘制饼图
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.xlabel('菜品')
plt.ylabel('销量')
plt.title('3148-Tang菜品销售量分布(条形图)',fontsize=15)
plt.show()

5.用于比较数据--折线图
数据:dish_sale.xls,不同部门各月份的销售额
折线图:
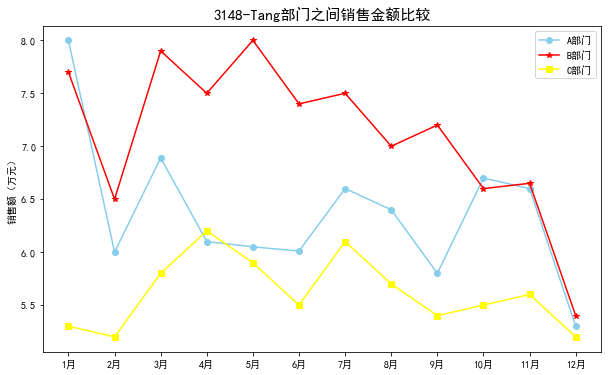
#部门之间销售金额比较
data = pd.read_excel("./dish_sale.xls") # 读取数据 plt.figure(figsize=(10,6)) # 设置图框大小尺寸 plt.plot(data['月份'],data['A部门'],color='skyblue',label='A部门',marker='o')
plt.plot(data['月份'],data['B部门'],color='red',label='B部门',marker='*')
plt.plot(data['月份'],data['C部门'],color='yellow',label='C部门',marker='s') plt.legend()#显示图例
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.title('3148-Tang部门之间销售金额比较',fontsize=15)
plt.ylabel('销售额(万元)')
plt.show()
数据:dish_sale_b'.xls,B部门各年份之间销售金额比较
折线图:
#B部门各年份之间销售金额比较
data = pd.read_excel("./dish_sale_b.xls") # 读取数据 plt.figure(figsize=(10,6)) # 设置图框大小尺寸 plt.plot(data['月份'],data['2012年'],color='green',label='2012年',marker='o')
plt.plot(data['月份'],data['2013年'],color='yellow',label='2013年',marker='*')
plt.plot(data['月份'],data['2014年'],color='purple',label='2014年',marker='s') plt.legend()#显示图例
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.title('3148-TangB部门各年份之间销售金额比较',fontsize=15)
plt.ylabel('销售额(万元)')
plt.show()
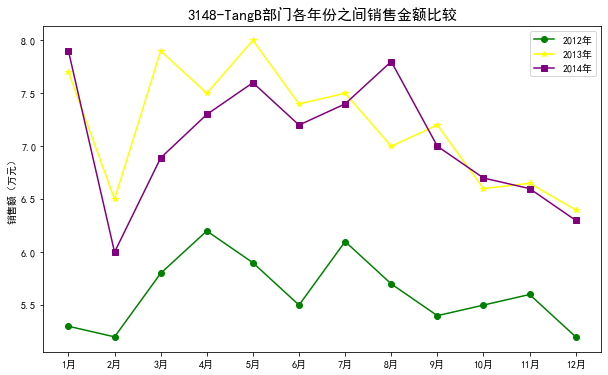
分析:总体来看,3个部门的销售额呈递减趋势,A部门与C部门的递减趋势比较平稳;B部门的销售额下降趋势比较明显,进一步分析造成这种现象的原因,可能是原材料不足
6.周期性分析
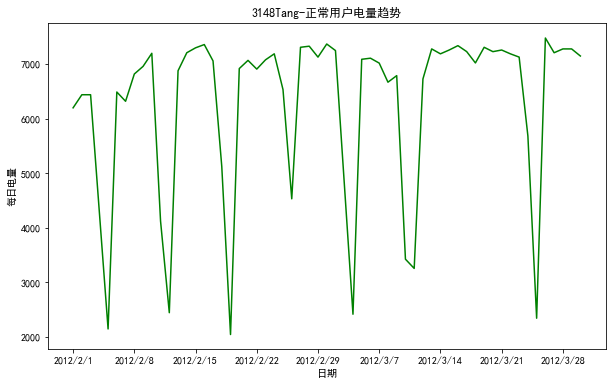
数据:user.csv(某单位日用电量)
import pandas as pd
import matplotlib.pyplot as plt df_normal = pd.read_csv("./user.csv") #读入数据
plt.figure(figsize=(10,6))
plt.plot(df_normal["Date"],df_normal["Eletricity"],color='green')
plt.xlabel("日期")
plt.ylabel("每日电量") # 设置x轴刻度间隔
x_major_locator = plt.MultipleLocator(7)
ax = plt.gca()
ax.xaxis.set_major_locator(x_major_locator)
plt.title("3148Tang-正常用户电量趋势")
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.show() # 展示图片
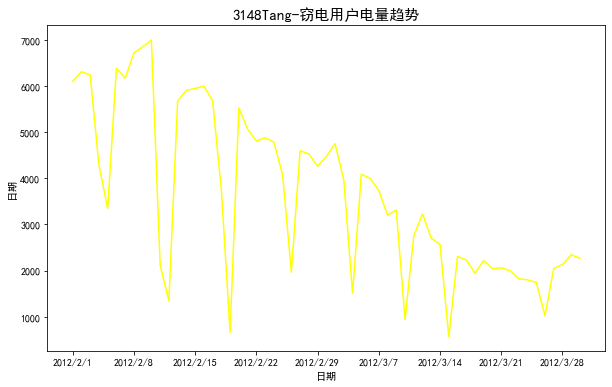
数据:Steal user.csv(窃电用户数据)
# 窃电用户用电趋势分析
df_steal = pd.read_csv("./Steal user.csv")
plt.figure(figsize=(10, 6))
plt.plot(df_steal["Date"],df_steal["Eletricity"],color='yellow')
plt.xlabel("日期")
plt.ylabel("日期") # 设置x轴刻度间隔
x_major_locator = plt.MultipleLocator(7)
ax = plt.gca()
ax.xaxis.set_major_locator(x_major_locator)
plt.title("3148Tang-窃电用户电量趋势",fontsize=15)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.show() # 展示图片
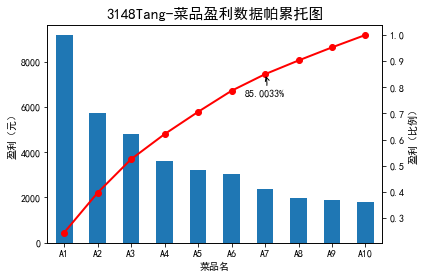
7.帕累托图
import pandas as pd #初始化参数
dish_profit = './catering_dish_profit.xls' #餐饮菜品盈利数据
data = pd.read_excel(dish_profit, index_col = u'菜品名')
data = data[u'盈利'].copy()
data.sort_values(ascending = False)
#降序排列
import matplotlib.pyplot as plt #导入图像库
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号 plt.figure()
data.plot(kind='bar')
plt.ylabel(u'盈利(元)')#左侧y轴,右侧y轴
p = 1.0*data.cumsum()/data.sum()
p.plot(color = 'r', secondary_y = True, style = '-o',linewidth = 2)
plt.annotate(format(p[6], '.4%'), xy = (6, p[6]), xytext=(6*0.9, p[6]*0.9), arrowprops=dict(arrowstyle="->", connectionstyle="arc3,rad=.2")) #添加注释,即85%处的标记。这里包括了指定箭头样式。
#注释格式规定,点的位置,注释内容,箭头样式
plt.ylabel(u'盈利(比例)')
plt.title("3148Tang-菜品盈利数据帕累托图",fontsize=15)
plt.show()
8.相关性分析
import pandas as pd
catering_sale = './catering_sale_all.xls' #餐饮数据,含有其他属性
data = pd.read_excel(catering_sale, index_col = u'日期') #读取数据,指定“日期”列为索引列
#相关系数矩阵,即给出了任意两款菜式之间的相关系数
data.corr()
pd.options.display.float_format = '{:,.2f}'.format ## 指定小数位数
data.corr()
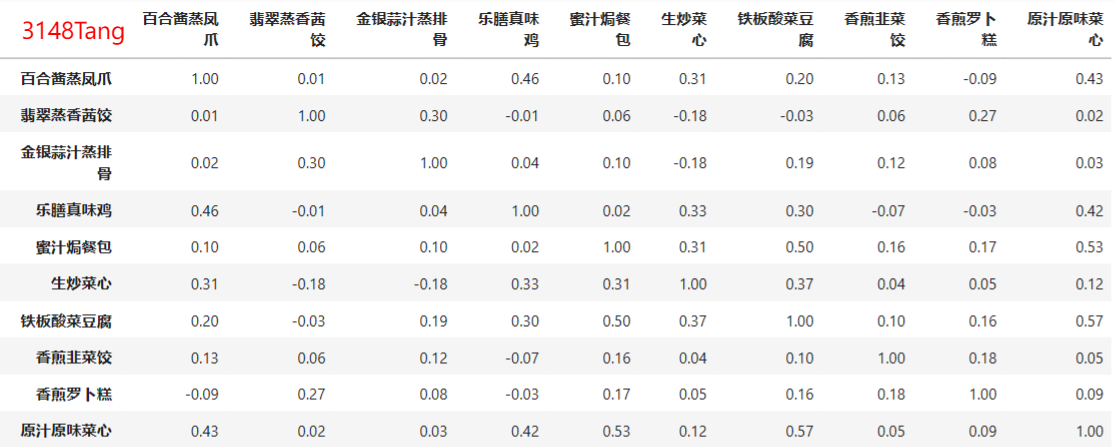
#只显示“百合酱蒸凤爪”与其他菜式的相关系数
print(data.corr()[u'百合酱蒸凤爪'])
data[u'百合酱蒸凤爪'].corr(data[u'翡翠蒸香茜饺']) #计算“百合酱蒸凤爪”与“翡翠蒸香茜饺”的相关系数
结果:
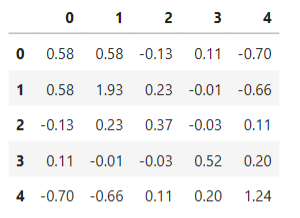
9.python主要数据探索函数
(1)计算协方差矩阵 cov()
# 计算6x5随机矩阵的协方差矩阵
import pandas as pd
import numpy as np
D = pd.DataFrame (np.random. randn (6, 5) ) #产生6X5随机矩阵
D.cov() #计算协方差矩阵
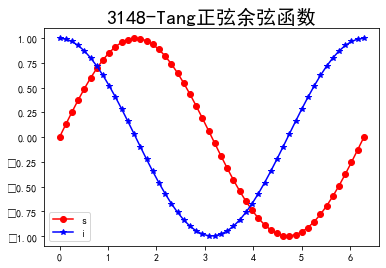
(2)绘制正弦与余弦虚线
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(0,2*(np.pi))
y1 = np.sin(x)
y2 = np.cos(x)
plt.figure()
plt.plot(x,y1,'r-o')
plt.plot(x,y2,'b-*')
plt.legend("sin(x)")
(3)饼图 hist()
import matplotlib.pyplot as plt #导入作图库
%matplotlib inline
# The slices will be ordered and plotted counter-clockwise.
labels = ' Frogs', 'Hogs', ' Dogs', 'Logs' , #定义标签
sizes = [15, 30, 45, 10] # 每一块的比例
colors = [ 'yellowgreen', 'gold', 'lightskyblue', 'lightcoral' ] #每一块的颜色
explode = (0, 0.1, 0, 0) #突出显示,这里仅仅突出显示第二块(即'Hogs')
plt.pie(sizes, explode=explode, labels=labels, colors=colors, autopct='%1.1f%%',shadow=True, startangle=90)
plt .axis ('equal') #显示为圆(避免比例压缩为椭圆)
plt.show()
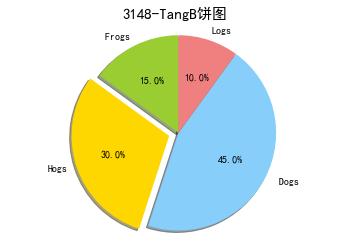
(4)函数图
import matplotlib.pyplot as plt # 导入作图库
import numpy as np
import pandas as pd %matplotlib inline
plt. rcParams ['font.sans-serif' ] = [ 'SimHei' ] #用来正常显示中文标签
plt. rcParams [ 'axes.unicode_minus'] = False #用来正常显示负号
x = pd. Series (np.exp (np. arange (20) ) ) #原始数据
x.plot (label = u'原始数据图',legend = True,color='lightskyblue')
plt.title('3148-Tang',fontsize=15)
plt.show()
x.plot (logy = True,label = u'原始数据图',legend = True,color='lightcoral')
plt.show()
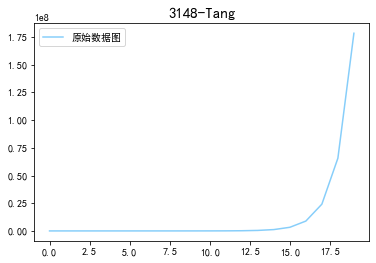

(5)误差棒图
import matplotlib.pyplot as plt # 导入作图库
import numpy as np
import pandas as pd
%matplotlib inline
error = np. random. randn (10) #定义误差列
y = pd.Series (np. sin (np. arange (10) ) ) #均值数据列
y .plot (yerr = error) #绘制误差图
plt.title('3148-Tang误差棒图',fontsize=15)
plt.show()
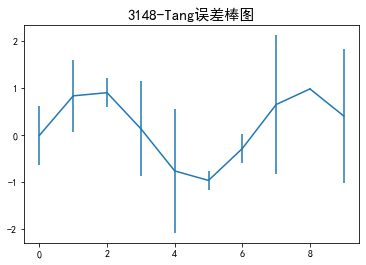
第3章---数据探索(python数据挖掘)的更多相关文章
- Python数据挖掘课程
[Python数据挖掘课程]一.安装Python及爬虫入门介绍[Python数据挖掘课程]二.Kmeans聚类数据分析及Anaconda介绍[Python数据挖掘课程]三.Kmeans聚类代码实现.作 ...
- 数据挖掘(二)用python实现数据探索:汇总统计和可视化
今天我们来讲一讲有关数据探索的问题.其实这个概念还蛮容易理解的,就是我们刚拿到数据之后对数据进行的一个探索的过程,旨在了解数据的属性与分布,发现数据一些明显的规律,这样的话一方面有助于我们进行数据预处 ...
- python数据挖掘之数据探索第一篇
目录 数据质量分析 当我们得到数据后,接下来就是要考虑样本数据集的数据和质量是否满足建模的要求?是否出现不想要的数据?能不能直接看出一些规律或趋势?每个因素之间的关系是什么? 通过检验数据集的 ...
- 利用python进行泰坦尼克生存预测——数据探索分析
最近一直断断续续的做这个泰坦尼克生存预测模型的练习,这个kaggle的竞赛题,网上有很多人都分享过,而且都很成熟,也有些写的非常详细,我主要是在牛人们的基础上,按照数据挖掘流程梳理思路,然后通过练习每 ...
- Python数据挖掘——数据预处理
Python数据挖掘——数据预处理 数据预处理 数据质量 准确性.完整性.一致性.时效性.可信性.可解释性 数据预处理的主要任务 数据清理 数据集成 数据归约 维归约 数值归约 数据变换 规范化 数据 ...
- Python数据挖掘——数据概述
Python数据挖掘——数据概述 数据集由数据对象组成: 数据的基本统计描述 中心趋势度量 均值 中位数 众数 中列数 数据集的最大值和最小值的平均 度量数据分布 极差 最大值与最小值的差 四分位数 ...
- Python机器学习之数据探索可视化库yellowbrick
# 背景介绍 从学sklearn时,除了算法的坎要过,还得学习matplotlib可视化,对我的实践应用而言,可视化更重要一些,然而matplotlib的易用性和美观性确实不敢恭维.陆续使用过plot ...
- python数据探索
数据质量分析 脏数据包括:缺失值:异常值:不一致的值:重复数据及含有特殊符号的数据: 1.缺失值处理 统计缺失率,缺失数 2.异常值处理 (1)简单统计量分析 (2)3Q原则 正态分布情况下,小概率事 ...
- Python 数据分析—第九章 数据聚合与分组运算
打算从后往前来做笔记 第九章 数据聚合与分组运算 分组 #生成数据,五行四列 df = pd.DataFrame({'key1':['a','a','b','b','a'], 'key2':['one ...
- Python机器学习之数据探索可视化库yellowbrick-tutorial
背景介绍 从学sklearn时,除了算法的坎要过,还得学习matplotlib可视化,对我的实践应用而言,可视化更重要一些,然而matplotlib的易用性和美观性确实不敢恭维.陆续使用过plotly ...
随机推荐
- 暴雪、迪士尼大佬用什么画画?RayLink远控软件助力解锁远程创作
CG绘画从业者,如原画师.插画师.漫画家.设计师等,一定对数位板\数位屏不陌生,数位板\数位屏是完成CG绘画作品的重要绘图工具之一. 从画画小白到数字绘画大神,从0基础插画培训班学生到国际知名游戏.动 ...
- 记录:安装nginx
练习的项目,数据都是跨域获取,上线后就不能再获取到数据,就用到nginx来做代理 注意点: 我用的是阿里云轻量服务器,防火墙在默认情况下是把80端口占据了,然而,安装nginx后,ngi ...
- 有关箭头函数的this知识
总结: 结果: 2,箭头函数正确的使用方法. 结果: 总结: 箭头函数不要直接在对象的属性上用.比如上面的函数3.
- .NET 7介绍及环境准备
环境要求 VS2022 17.4+
- Flink 同时按照计数和时间触发窗口计算
自定义trigger 继承 抽象类 Trigger<T, TimeWindow> 主要实现 Trigger类的四个方法(onElement.onEventTime.onProcessin ...
- js 获取标签属性值
有时候需要获取标签里属性里的值,可以采用以下方法: demo: <a href="/admin/article/${id}" onclick="return del ...
- Js文章内容监听复制代码
若别人在你的网站复制内容将会提示,请把监听提示添加到文章内容div或者直接将代码复制粘贴到所需要的文件中! <script> //监听ctrl+v 复制 document.addEvent ...
- 部署及配置Mycat数据库中间件
Mycat关键特性关键特性支持SQL92标准支持MySQL.Oracle.DB2.SQL Server.PostgreSQL等DB的常见SQL语法遵守Mysql原生协议,跨语言,跨平台,跨数据库的通用 ...
- trzcopy
@echo offcd /d %~dp0setlocal enabledelayedexpansionset aa=伟大的中国!我为你自豪echo 替换前:%aa%echo 替换后:%aa:中国=中华 ...
- jenkins +docker+python接口自动化之jenkins拉取gitee上的代码(四)
1.背景 1.经过我们前面几轮的安装测试,我们已经安装了jenkins容器,python3,以及运行我们python代码所需要的第三方库在requirements.txt文件下统一安装. 2.需求 我 ...