Elasticsearch-Kibana-学习笔记
1.背景

1.1 简介
Elasticsearch 具有以下特征
- Elasticsearch 很快。 由于 Elasticsearch 是在 Lucene 基础上构建而成的,所以在全文本搜索方面表现十分出色。Elasticsearch 同时还是一个近实时的搜索平台,这意味着从文档索引操作到文档变为可搜索状态之间的延时很短,一般只有一秒。因此,Elasticsearch 非常适用于对时间有严苛要求的用例,例如安全分析和基础设施监测。
- Elasticsearch 具有分布式的本质特征。 Elasticsearch 中存储的文档分布在不同的容器中,这些容器称为分片,可以进行复制以提供数据冗余副本,以防发生硬件故障。Elasticsearch 的分布式特性使得它可以扩展至数百台(甚至数千台)服务器,并处理 PB 量级的数据。
- Elasticsearch 包含一系列广泛的功能。 除了速度、可扩展性和弹性等优势以外,Elasticsearch 还有大量强大的内置功能(例如数据汇总和索引生命周期管理),可以方便用户更加高效地存储和搜索数据。
- Elastic Stack 简化了数据采集、可视化和报告过程。 人们通常将 Elastic Stack 称为 ELK Stack(代指Elasticsearch、Logstash 和 Kibana),目前 Elastic Stack 包括一系列丰富的轻量型数据采集代理,这些代理统称为 Beats,可用来向 Elasticsearch 发送数据。通过与 Beats 和 Logstash 进行集成,用户能够在向 Elasticsearch 中索引数据之前轻松地处理数据。同时,Kibana 不仅可针对 Elasticsearch 数据提供实时可视化,同时还提供 UI 以便用户快速访问应用程序性能监测 (APM)、日志和基础设施指标等数据。
1.2 学习参考
- Elasticsearch官方文档:《Elasticsearch权威指南》
- Elasticsearch各版本区别:《Elasticsearch各个版本重要特性》
- 中国社区官方博客:《Elastic 中国社区官方博客》,《知识导航页》
- 其他参考技术博客:《系统学习Elastic》
- 常规知识点:《Elasticsearch面试问题》
1.3 本例测试版本

{
"name" : "xxx.168.xx.4",
"cluster_name" : "my-application",
"cluster_uuid" : "xxxxxxxxx",
"version" : {
"number" : "7.12.1",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "xxxxxxxxxxxx",
"build_date" : "2021-04-20T20:56:39.040728659Z",
"build_snapshot" : false,
"lucene_version" : "8.8.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
2.DSL语法学习
2.1基础知识
数据类型
String字符串的两种数据格式 keyworld,text的区别
- text:会分词,然后进行索引,用于全文搜索。支持模糊、精确查询,不支持聚合。
- keyword:不进行分词,直接索引,keyword用于关键词搜索,支持模糊、精确查询,支持聚合。
"mappings" : {
"properties" : {
"color" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
日期/时间自定义格式
- yyyy-MM-dd HH:mm:ss
- yyyy-MM-dd
- epoch_millis(毫秒值)
PUT my_index
{
"mappings": {
"_doc": {
"properties": {
"date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
}
}
- 数组(数组类型直接声明为text,传入的数组初始化数据类型需一致),object,nested复杂类型;
- 聚合/排序时,哪些数类型的字段支持:
- text常见分词器
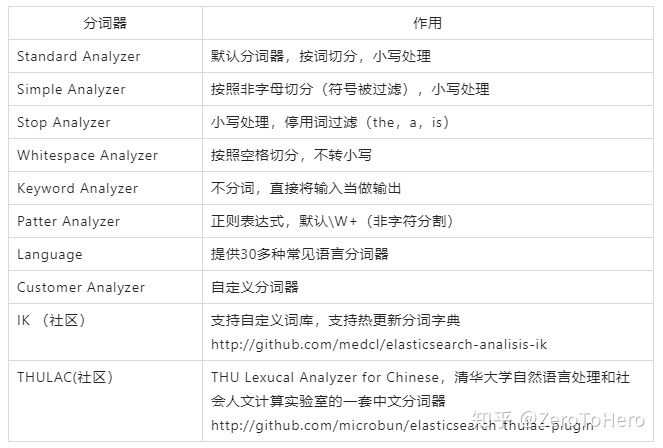
type类型
2.2构建index
PUT /study_index
{
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}, "mappings": {
"properties": {
"study_id": {
"type": "integer"
},
"price": {
"type": "double"
},
"content": {
"type": "text"
},
"title": {
"type": "keyword"
},
"study_name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"study_date": {
"type": "date",
"format": "yyyy-MM-dd"
},
"study_time": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
},
"study_millis": {
"type": "date",
"format": "epoch_millis"
},
"study_array": {
"type": "text"
},
"study_object": {
"type": "object"
},
"study_nested": {
"type": "nested"
},
"location": {
"type": "geo_point"
}
}
}
}
初始化数据
PUT /study_index/_bulk
{ "index": {}}
{ "study_id" : 2, "price" : 188.55, "content" : "养乐多1 test","title":"养乐多哇哈哈","study_name":"测试,中国人都爱喝", "study_date" : "2022-06-28","study_time" : "2022-10-28 12:22:32","study_millis":"1657626972000","study_array":["养乐多","哇哈哈","饮料"],"study_object":[ { "name":"wang", "age":18 }, { "name":"ling", "age":21 } ],"study_nested":[ { "name":"ma", "sex":1 }, { "name":"zhang", "sex":2 } ],"location":[ -72.34, 41.12 ] }
2.3基础DSL查询语句
filter查询
组合(bool)查询
- must : 多个查询条件的完全匹配,相当于 and。
- must_not ::多个查询条件的相反匹配,相当于 not。
- should : 至少有一个查询条件匹配, 相当于 or。
match
- 查询的是日期或者是数值的话,他会将你基于的字符串查询内容转换为日期或者数值对待。
- 查询的内容是一个不能被分词的内容(keyword),match查询不会对你指定的查询关键字进行分词。
- 查询的内容是一个可以被分词的内容(text),match会将你指定的查询内容根据一定的方式去分词,去分词库中匹配指定的内容。
- match_phrase查询分析文本,并从分析文本中创建短语查询
- match_phrase_prefix 做匹配
term
- term代表完全匹配,不进行分词器分析
- term 查询的字段需要在mapping的时候定义好,否则可能词被分词。传入指定的字符串,查不到数据
wildcard
- ? : 支持模糊匹配单个字符。举例:Ma?s 仅能匹配:Mars, Mass, 和 Maps。
- *: 支持模糊匹配零个或者多个字符。举例:Ma*s 能匹配:Mars, Matches 和 Massachusetts等。
GET /study_index/_search
{
"query": {
"wildcard": {
"study_name.keyword": "*中??都*"
}
}
}
wildcard 字段类型,该字段类型经过优化,可在字符串值中快速查找模式。wildcard 类型出现的目的:一方面避免了某些场景下分词查询不准确的问题,另一方面也解决了通配符和正则检索的效率问题。PUT my-study_index
{
"mappings": {
"properties": {
"my_wildcard_test": {
"type": "wildcard"
}
}
}
}
fuzzy
fuzziness参数,可以赋值为0,1,2和AUTO,默认其实是AUTO。- 0..2 完全匹配(就是不允许模糊)
- 3..5 编辑距离是1
- 大于5 编辑距离是2
constant_score 以非评分模式查询
查询price为68.55的记录
GET /study_index/_search
{
"query": {
"term": {
"price": 68.55
}
}
}
查询study_id为[1,2,3,4]的数据,price大于100,study_date在一个时间区间的数据


# 直接查询
GET /study_index/_search
{
"query":{
"bool":{
"must":[
{
"terms":{
"study_id":[1, 2, 3, 4]
}
},
{
"wildcard":{
"content":"*test*"
}
},
{
"range":{
"price":{
"gte":100
}
}
},
{
"range":{
"study_date":{
"gte":"2020-01-01",
"lte":"2022-09-01"
}
}
}
]
}
}
} # 过滤数据查询
GET /study_index/_search
{
"query":{
"bool":{
"must":[
{
"terms":{
"study_id":[1, 2, 3, 4]
}
},
{
"wildcard":{
"content":"*test*"
}
}
],
"filter": [
{
"range":{
"price":{
"gte":100
}
}
},
{
"range":{
"study_date":{
"gte":"2020-01-01",
"lte":"2022-09-01"
}
}
}
]
}
}
} # 查询时不计算关联分数
GET /study_index/_search
{
"query":{
"constant_score": {
"filter": {
"bool":{
"must":[
{
"terms":{
"study_id":[1, 2, 3, 4]
}
}, {
"wildcard":{
"content":"*test*"
}
}
],
"filter": [
{
"range":{
"price":{
"gte":100
}
}
},
{
"range":{
"study_date":{
"gte":"2020-01-01",
"lte":"2022-09-01"
}
}
}
]
}
},
"boost": 1.2
} }
}
查询商户ID为3582,订单号为360102199003072618,按时间范围过滤,按下单时间倒序,每次查询100条
左匹配
{
"match_phrase_prefix":{
"content":"wang"
}
}
{ "query": {
"prefix" : { "author": "方" }
}
}
结果集返回指定字段 (_source)
排序分页查询
GET /study_index/_search
{
"query":{
"bool":{
"must":[
{
"match_phrase_prefix":{
"content":"乳"
}
},
{
"range": {
"price": {
"gte": 10,
"lte": 20000
}
}
}
]
}
}
,
"sort": [
{
"price": {
"order": "desc"
}
},
{
"study_id": {
"order": "desc"
}
}
],
"_source": ["study_millis","price","title","study_array"],
"from":0,
"size": 20
}
分组聚合
GET /study_index/_search
{
"size": 0,
"aggs": {
"title_group": {
"terms": {
"field": "title",
"order": {
"avg_price": "desc"
}
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
基于区间统计聚合
GET /study_index/_search
{
"size": 0,
"aggs": {
"age_group_price":{
"range": {
"field": "price",
"ranges": [
{
"from": 1,
"to": 100
},
{
"from": 100,
"to":1000
},
{
"from": 1000,
"to":100000
}
]
}
}
}
}
高亮显示
GET /study_index/_search
{
"query": {
"match": {
"content": "test"
}
},
"highlight": {
"pre_tags": [
"<span>"
],
"post_tags": [
"</span>"
],
"fields": {
"content": {} }
}
}
深分页
| 分页方式 | 性能 | 优点 | 缺点 | 场景 |
| from + size | 低 | 灵活性好,实现简单 | 深度分页问题 | 数据量比较小,能容忍深度分页问题 |
| scroll | 中 | 解决了深度分页问题 | 无法反应数据的实时性(快照版本)维护成本高,需要维护一个 scroll_id | 海量数据的导出(比如笔者刚遇到的将es中20w的数据导入到excel)需要查询海量结果集的数据 |
| search_after | 高 | 性能最好不存在深度分页问题能够反映数据的实时变更 | 实现复杂,需要有一个全局唯一的字段连续分页的实现会比较复杂,因为每一次查询都需要上次查询的结果 | 海量数据的分页 |
GET /study_index/_search?scroll=2m
{ "query": {
"fuzzy": {
"content":{
"value":"test"
}
}
},
"size": 3
}
GET /_search/scroll?pretty
{
"scroll" : "1m",
"scroll_id" : "FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFkdzQVVFd29IVEZ5VE13ZEZNV2dUMkEAAAAAAADAgBY4VDlNWHdpN1NTV2JXM20wT0pOdEVn"
}
3.Kibana数据展示
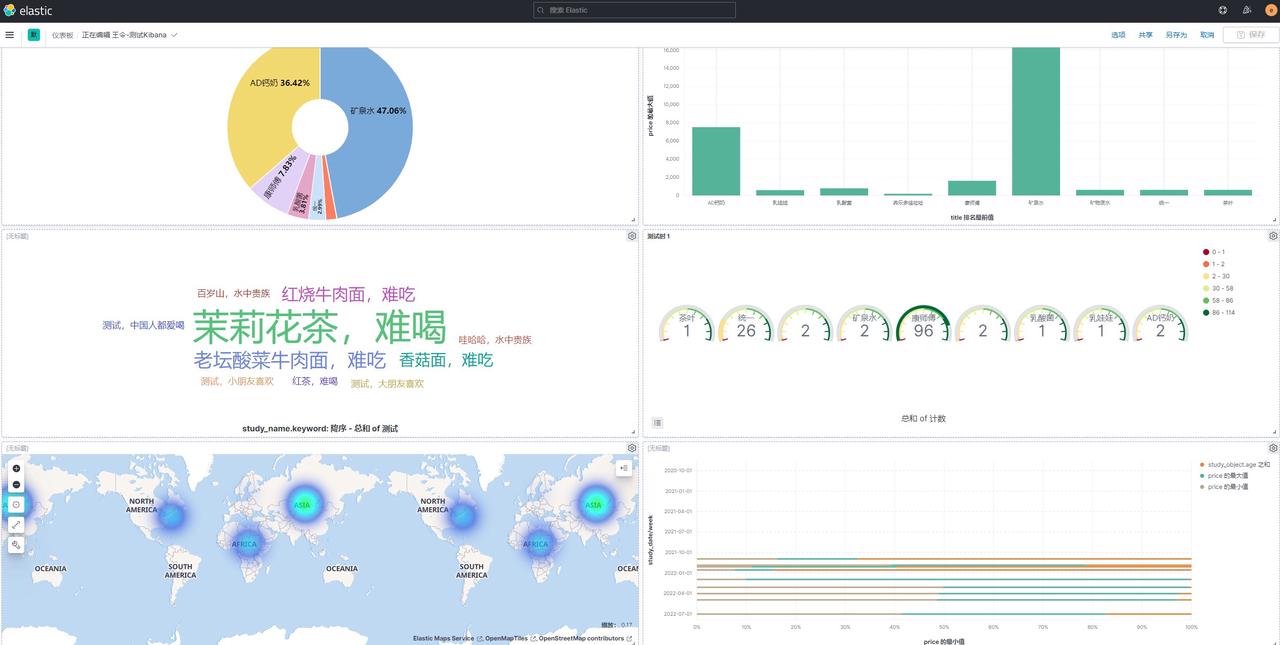
3.1简单分析学习数据
Elasticsearch-Kibana-学习笔记的更多相关文章
- Kibana学习笔记——安装和使用
1.首先下载Kibana https://www.elastic.co/downloads 2.解压 tar -zxvf kibana-6.2.1-linux-x86_64.tar.gz -C ~/s ...
- elasticsearch原理学习笔记
https://mp.weixin.qq.com/s/dn1n2FGwG9BNQuJUMVmo7w 感谢,透彻的讲解 整理笔记 请说出 唐诗中 包含 前 的诗句 ...... 其实你都会,只是想不起 ...
- 初探 Elasticsearch,学习笔记第一讲
1. ES 基础 1.1 ES定义 ES=elaticsearch简写, Elasticsearch是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储.检索数据:本身扩展 ...
- elasticsearch学习笔记——相关插件和使用场景
logstash-input-jdbc学习 ES(elasticsearch缩写)的一大优点就是开源,插件众多.所以扩展起来非常的方便,这也造成了它的生态系统越来越强大.这种开源分享的思想真是与天朝格 ...
- Elasticsearch7.6学习笔记1 Getting start with Elasticsearch
Elasticsearch7.6学习笔记1 Getting start with Elasticsearch 前言 权威指南中文只有2.x, 但现在es已经到7.6. 就安装最新的来学下. 安装 这里 ...
- ElasticSearch学习笔记(超详细)
文章目录 初识ElasticSearch 什么是ElasticSearch ElasticSearch特点 ElasticSearch用途 ElasticSearch底层实现 ElasticSearc ...
- ElasticSearch 5学习(2)——Kibana+X-Pack介绍使用(全)
Kibana是一个为 ElasticSearch 提供的数据分析的 Web 接口.可使用它对日志进行高效的搜索.可视化.分析等各种操作.Kibana目前最新的版本5.0.2,回顾一下Kibana 3和 ...
- ElasticSearch 5学习(1)——安装Elasticsearch、Kibana和X-Pack
安装准备: 安装Elasticsearch唯一的要求是安装官方新版的Java,包括对应的Jdk. 安装Elasticsearch 首先到官网下载最新版本的Elasticsearch压缩包. 可以使用命 ...
- Elasticsearch学习笔记一
Elasticsearch Elasticsearch(以下简称ES)是一款Java语言开发的基于Lucene的高效全文搜索引擎.它提供了一个分布式多用户能力的基于RESTful web接口的全文搜索 ...
- 利用kibana学习 elasticsearch restful api (DSL)
利用kibana学习 elasticsearch restful api (DSL) 1.了解elasticsearch基本概念Index: databaseType: tableDocument: ...
随机推荐
- java-去除html中的标签或者元素属性(正则表达式/jsoup)
业务场景: 如一篇使用富文本编辑器编辑的新闻稿,需要在列表页面截取前200字作为摘要,此时需要去除html标签,截取真正的文本部分. /** * 删除Html标签 */public static St ...
- MySQL锁(乐观锁、悲观锁、多粒度锁)
锁 并发事务可能出现的情况: 读-读事务并发:此时是没有问题的,读操作不会对记录又任何影响. 写-写事务并发:并发事务相继对相同的记录做出改动,因为写-写并发可能会产生脏写的情况,但是没有一个隔离级别 ...
- Java开发学习(三)----Bean基础配置及其作用范围
一.bean基础配置 对于bean的基础配置如下 <bean id="" class=""/> 其中,bean标签的功能.使用方式以及id和clas ...
- Puppeteer学习笔记 (2)- Puppeteer的安装
本文链接:https://www.cnblogs.com/hchengmx/p/11009849.html 1. node的下载安装 由于puppeteer是nodejs的一个库,所以首先需要安装no ...
- CVPR2022 | 弱监督多标签分类中的损失问题
前言 本文提出了一种新的弱监督多标签分类(WSML)方法,该方法拒绝或纠正大损失样本,以防止模型记忆有噪声的标签.由于没有繁重和复杂的组件,提出的方法在几个部分标签设置(包括Pascal VOC 20 ...
- SAP FPM 相关包 APB_FPM_CORE
related interface: APB_FPM_COREAPB_FPM_CORE_4_EXT_SCAPB_FPM_CORE_INTERNALAPB_FPM_CORE_RESTRICTED
- Kali信息收集
前言 渗透测试最重要的阶段之一就是信息收集,需要收集关于目标主机的基本细腻些.渗透测试人员得到的信息越多,渗透测试成功的概率也就越高. 一.枚举服务 1.1 DNS枚举工具DNSenum DNSenu ...
- uipath 如何利用函数split切割换行符?
uipath 如何利用函数split切割换行符? 答案在这 https://rpazj.com/thread-178-1-1.html
- Excel表函数自动生成SQL
前言 在平常的工作中,多多掌握一点这样的小技巧,能够帮助我们省去很多时间: 1.数据库对应的表如下: 2.excel中需要导入的数据如下: 3.excel中sql的写法: ="insert ...
- 动态树 — Link_Cut_Tree
[模板]动态树(Link Cut Tree) Link-cut-tree是一种维护动态森林的数据结构,在需要动态加边/删边的时候就需要LCT来维护. Link-cut-tree的核心是轻重链划分,每条 ...