基于yum安装CDH集群
一、环境准备
准备至少3台设备;CentOS7系统;
如果是在实验环境下,给虚拟机的内存至少4G,根建议1T,数据盘1T,由于是虚拟机,所以根分区和数据盘放心大胆的给;如果是在生产环境则多多益善;我这次的实验环境是三台2G内存,50G硬盘的腾讯云主机(CentOS7.5),不知是否能搭建成功,试试吧;
二、数据库安装
注意:以下数据库的配置方式是错误的,一定不要yum安装数据库,yum安装在CentOS7上是mariadb5.5版本的;在最后初始化的时候会遇到各种古怪问题,我的CDH版本明明是5版本的,但是错误提示是识别到我的CDH版本是3的,需要我升级到4,再到5;然后我直接在CentOS7上二进制安装了mysql5.7完美解决各种古怪问题;所以以下数据库的安装都是错误示范;我之所以保留也是为各位有缘人不要犯跟我一样的错误;
如果想参考正确的数据库配置方式,请参考:https://www.cnblogs.com/zhangzhide/p/11124064.html我的这篇博文中的mysql安装部分就好;
这篇笔记除了数据库安装部分有问题之外其他的都是亲测正确的;希望这篇博文能够帮助到有缘人;
既然是yum安装那就一键yum到底;
1、yum install mariadb mariadb-server -y

2、启动mariadb服务,并开机自启
systemctl start mariadb 确认3306端口已经启动
systemctl enable mariadb
3、修改密码并配置授权用户
MariaDB [mysql]> SET PASSWORD FOR 'root'@'localhost'=PASSWORD('123.com');
MariaDB [(none)]> CREATE DATABASE scm DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci; ##创建scm数据库并指定字符集为utf8mb4,排序规则为utf8mb4_unicode_ci,ci表示不区分字母大小写;
MariaDB [(none)]> CREATE USER 'scm'@'172.21.0.%' IDENTIFIED BY '123.com'; ##创建'scm'@'172.21.0.%'用户
MariaDB [(none)]> GRANT ALL PRIVILEGES ON scm.* TO 'scm'@'172.21.0.%'; 将scm库下的表的所有权授权给scm用户;
MariaDB [(none)]> FLUSH PRIVILEGES; ##让配置立即生效;
4、用新创建的用户登陆测试是否能正常使用;
(vir-3.5.2) [root@master ~]# mysql -uscm -h172.21.0.3 -p
Enter password:
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 8
Server version: 5.5.60-MariaDB MariaDB Server
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB [(none)]> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| scm |
| test |
+--------------------+
3 rows in set (0.00 sec)
MariaDB [(none)]> use scm;
Database changed
MariaDB [scm]> show tables;
Empty set (0.00 sec)
三、自建镜像安装地址
官方镜像安装地址(https://archive.cloudera.com/cm5/redhat/7/x86_64/cm/5.16.1/RPMS/x86_64/) 由于源在国外,访问会很慢,所以就自建源能快速安装;
1、安装nginx作为web服务并启动
yum install nginx -y
2、创建配置文件
[root@master conf.d]# cat /etc/nginx/conf.d/yum.conf
server {
listen 80;
server_name www.zhide666.com;
root /data/yum; #指定gen路径
autoindex on; #开启目录浏览功能
autoindex_exact_size off; #关闭详细文件大小统计,让文件大小显示MB,GB单位,默认为b
autoindex_localtime on; #开启以服务器本地时区显示文件修改日期
}
3、制作本地CM源,安装yum源制作工具
yum install yum-utils createrepo yum-plugin-priorities -y

访问效果图:
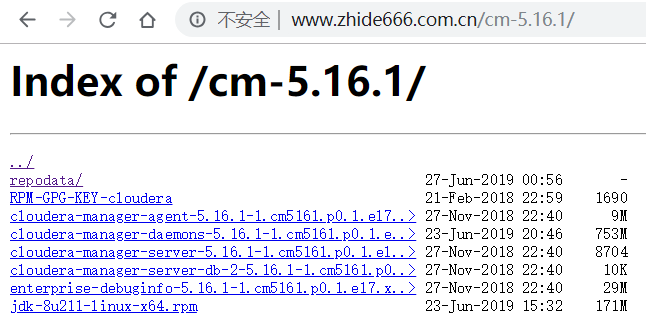
4、下载CDH版本存放到指定的路径下

四、配置自己创建的yum源
官方yum源:https://archive.cloudera.com/cm5/redhat/7/x86_64/cm/cloudera-manager.repo
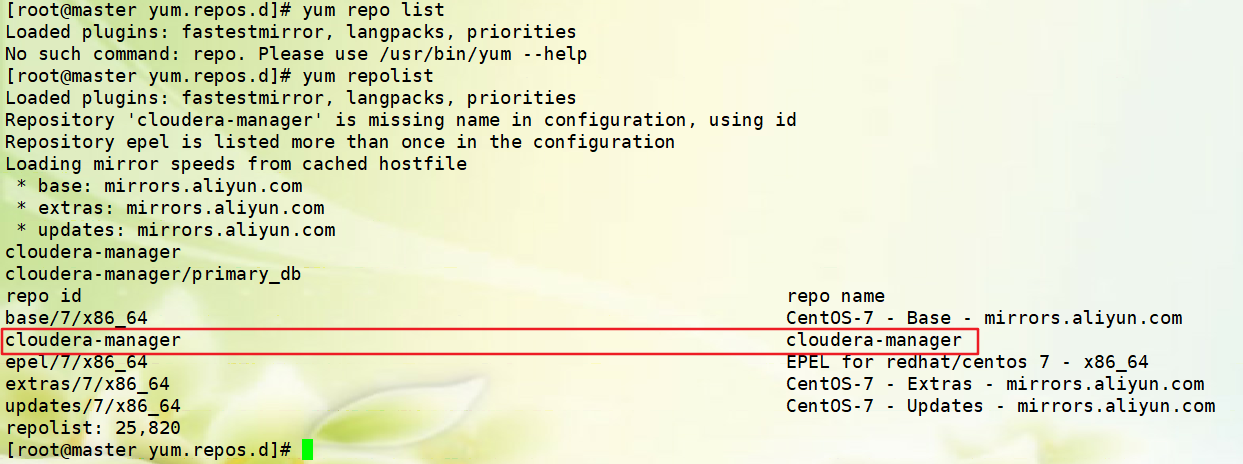
配置自己的cm yum源,不单单配置在自身,而且需要将自建的cm yum源配置到其他两台主机上;
[root@master yum.repos.d]# cat /etc/yum.repos.d/cloudera-manager.repo
[cloudera-manager]
baseurl=http://www.zhide666.com.cn/cm-5.16.1/
gpgkey=http://www.zhide666.com.cn/cm-5.16.1/RPM-GPG-KEY-cloudera
enable = 1
gpgcheck = 1
验证:
五、安装Cloudera Manager Server端
[root@master yum.repos.d]# yum install cloudera-manager-daemons cloudera-manager-server -y

六、各节点安装各个节点安装Cloudera Manager Agent端
[root@master yum.repos.d]# yum install cloudera-manager-agent -y
[root@node1 yum.repos.d]# yum install cloudera-manager-agent -y
[root@node2 yum.repos.d]# yum install cloudera-manager-agent -y
七、配置Cloudera Manager Server的默认堆内存大小
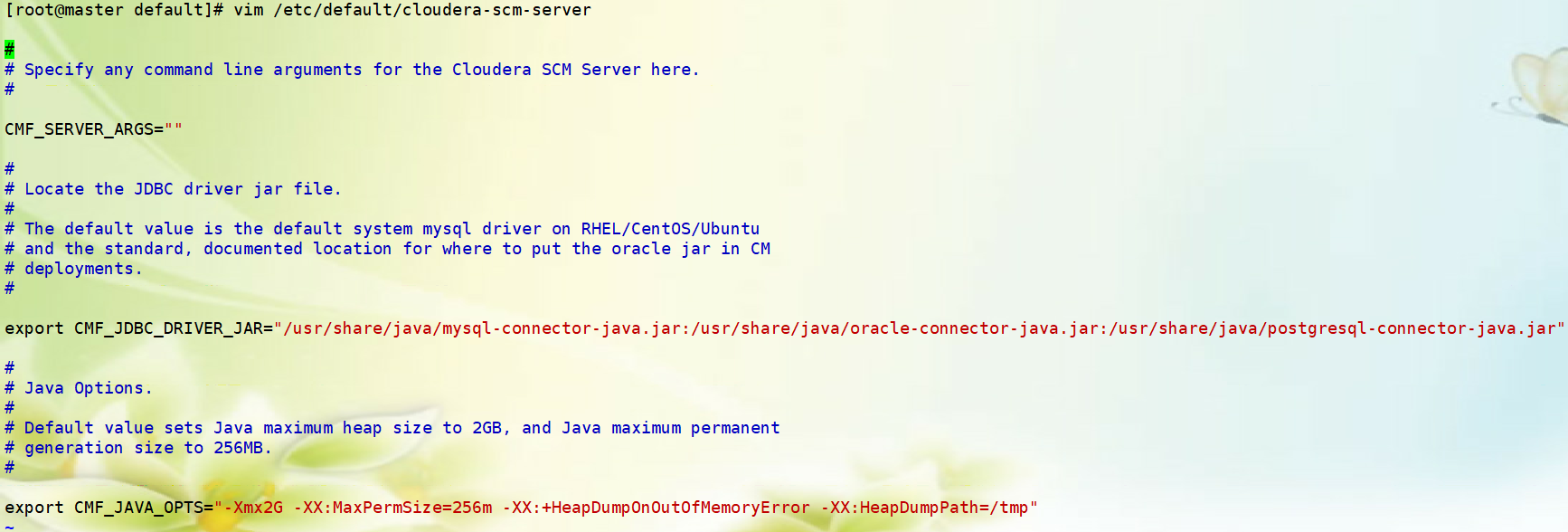
堆内存至少2G,否则服务无法启动,我这里就默认不调了,云主机总共才2G;
八、初始化CM Server数据库

在初始化时遇到的错误:提示说该路径下找不到该jar文件,下载个jar文件并放到该路径下即可

九、修改Cloudera Manager Agent各节点的配置文件
(vir-3.5.2) [root@master ~]# grep server_port /etc/cloudera-scm-agent/config.ini
server_port=7182 #server端服务端口
CM服务器默认是默认是localhost;所以需要将server端和agent端都改为server端的主机名;
(vir-3.5.2) [root@master ~]# ansible -i cdh-host all -m shell -a "sed -i 's/server_host=localhost/server_host=master/g' /etc/cloudera-scm-agent/config.ini"
master | CHANGED | rc=0 >>
node2 | CHANGED | rc=0 >>
node1 | CHANGED | rc=0 >>
(vir-3.5.2) [root@master ~]# ansible -i cdh-host all -m shell -a "grep server_host /etc/cloudera-scm-agent/config.ini"
node2 | CHANGED | rc=0 >>
server_host=master
master | CHANGED | rc=0 >>
server_host=master
node1 | CHANGED | rc=0 >>
server_host=master
十、启动CM Server端
(vir-3.5.2) [root@master ~]# systemctl start cloudera-scm-server
(vir-3.5.2) [root@master ~]# systemctl status cloudera-scm-server
● cloudera-scm-server.service - LSB: Cloudera SCM Server
Loaded: loaded (/etc/rc.d/init.d/cloudera-scm-server; bad; vendor preset: disabled)
Active: active (exited) since Sun 2019-06-30 00:52:45 CST; 1h 4min ago
Docs: man:systemd-sysv-generator(8)
Process: 933 ExecStart=/etc/rc.d/init.d/cloudera-scm-server start (code=exited, status=0/SUCCESS)
Tasks: 0
Memory: 0B
Jun 30 00:52:39 master systemd[1]: Starting LSB: Cloudera SCM Server...
Jun 30 00:52:40 master su[1071]: (to cloudera-scm) root on none
Jun 30 00:52:45 master cloudera-scm-server[933]: Starting cloudera-scm-server: [ OK ]
Jun 30 00:52:45 master systemd[1]: Started LSB: Cloudera SCM Server.
查看日志:
tailf /var/log/cloudera-scm-server/cloudera-scm-server.log
2019-06-30 13:56:39,149 INFO WebServerImpl:org.mortbay.log: jetty-6.1.26.cloudera.4
2019-06-30 13:56:39,165 INFO WebServerImpl:org.mortbay.log: Started SelectChannelConnector@0.0.0.0:7180 #如果能在日志种看到这个端口出现则表示成功了;
2019-06-30 13:56:39,165 INFO WebServerImpl:com.cloudera.server.cmf.WebServerImpl: Started Jetty server.
2019-06-30 13:56:39,319 INFO SearchRepositoryManager-0:com.cloudera.server.web.cmf.search.components.SearchRepositoryManager: Finished constructing repo:2019-06-30T05:56:39.319Z
遇到的问题:
"alter table SETTINGS
add column LDAP_USER_SEARCH_BASE varchar(1024),
add column LDAP_USER_SEARCH_FILTER varchar(1024),
add column LDAP_GROUP_SEARCH_BASE varchar(1024),
add column LDAP_GROUP_SEARCH_FILTER varchar(1024)"
Row size too large. The maximum row size for the used table type, not counting BLOBs, is 65535. This includes storage overhead, check the manual. You have to change some columns to TEXT or BLOBs
2019-06-30 13:47:46,021 FATAL main:org.hsqldb.cmdline.SqlFile: Rolling back SQL transaction.
2019-06-30 13:47:46,022 ERROR main:com.cloudera.enterprise.dbutil.SqlFileRunner: Exception while executing ddl scripts.
com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: Row size too large. The maximum row size for the used table type, not counting BLOBs, is 65535. This includes storage overhead, check the manual. You have to change some columns to TEXT or BLOBs
解决方式:
(vir-3.5.2) [root@master ~]# cat /etc/my.cnf
[mysqld]
basedir=/usr/local/mysql-5.7.25
datadir=/usr/local/mysql-5.7.25/data
max_allowed_packet = 1G #加这一行配置即可;
十一、启动个cloudera manager agent端
(vir-3.5.2) [root@master ~]# ansible -i cdh-host all -m shell -a "systemctl start cloudera-scm-agent"
十二、访问cloudera manager server 端的web UI;
由于域名未备案,只能ip访问了;

十三、安装CDH集群
 ·
·
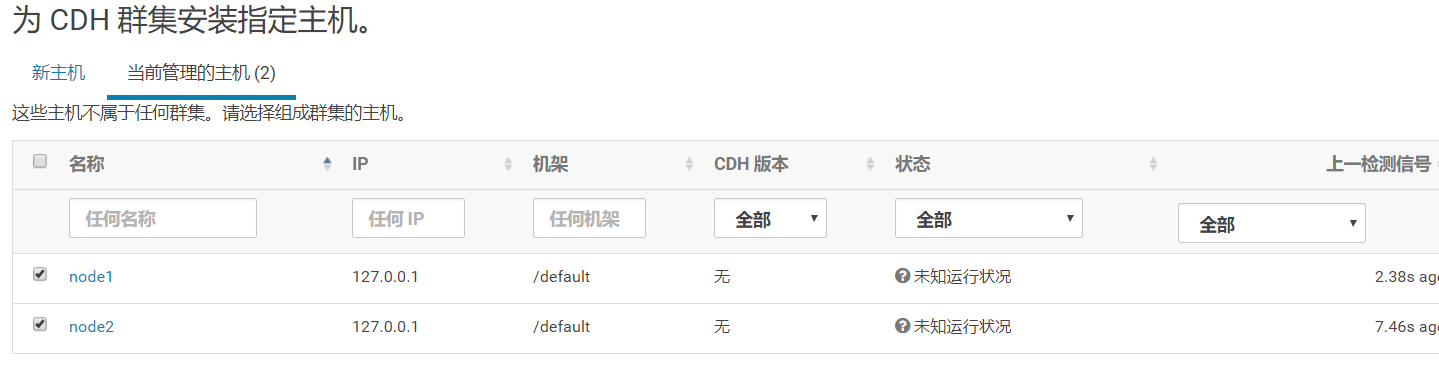
这个地方选择当前管理的主机只有2台设备,其实是有3台的,一台没识别出来,这个时候就要用到新主机选项的搜索功能;
由于是在云主机上搭建的,不知为何会认到127.0.0.1;

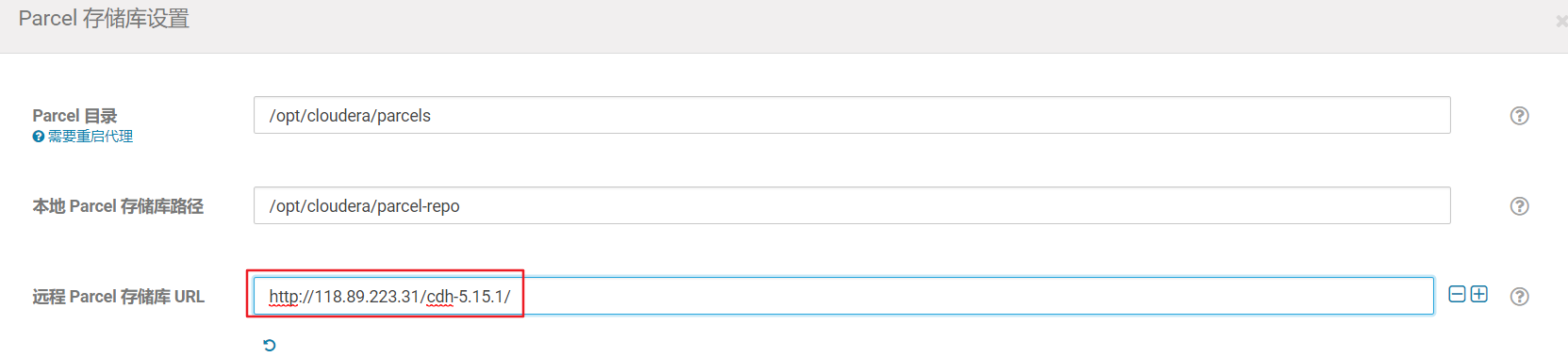
选择更多选项,将里面的官方源删掉,并加入自己的源;


基于yum安装CDH集群的更多相关文章
- yum安装k8s集群
k8s的安装有多种方式,如yum安装,kubeadm安装,二进制安装等.本文是入门系列,只是为了快速了解k8s的原理和工作过程,对k8s有一个快速的了解,这里直接采用yum安装 的1.5.2为案例进行 ...
- 基于docker安装pxc集群
基于docker安装pxc集群 一.PXC 集群的安装 PXC集群比较特殊,需要安装在 linux 或 Docker 之上.这里使用 Docker进行安装! Docker的镜像仓库中包含了 PXC数据 ...
- CentOS 7.5 使用 yum 安装 Kubernetes 集群(二)
一.安装方式介绍 1.yum 安装 目前CentOS官方已经把Kubernetes源放入到自己的默认 extras 仓库里面,使用 yum 安装,好处是简单,坏处也很明显,需要官方更新 yum 源才能 ...
- Blazor+Dapr+K8s微服务之基于WSL安装K8s集群并部署微服务
前面文章已经演示过,将我们的示例微服务程序DaprTest1部署到k8s上并运行.当时用的k8s是Docker for desktop 自带的k8s,只要在Docker for deskto ...
- yum安装etcd集群
前一篇文章介绍了如何yum安装简单的kubernetes集群,其中etcd是单点部署.本篇我们来搭建etcd集群,方便日后搭建kubernetes HA集群架构. 1,环境配置说明 etcd1 ...
- yum安装k8s集群(kubernetes)
此案例是以一个主,三个node来部署的,当然node可以根据自己情况部署 192.168.1.130 master 192.168.1.131 node1 192.168.1.132 node2 19 ...
- CDH集群安装&测试总结
0.绪论 之前完全没有接触过大数据相关的东西,都是书上啊,媒体上各种吹嘘啊,我对大数据,集群啊,分布式计算等等概念真是高山仰止,充满了仰望之情,觉得这些东西是这样的: 当我搭建的过程中,发现这些东西是 ...
- CentOS7 Cloudera Manager6 完全离线安装 CDH6 集群
本文是在CentOS7.4 下进行CDH6集群的完全离线部署.CDH5集群与CDH6集群的部署区别比较大. 说明:本文内容所有操作都是在root用户下进行的. 文件下载 首先一些安装CDH6集群的必须 ...
- 使用yum安装CDH Hadoop集群
使用yum安装CDH Hadoop集群 2013.04.06 Update: 2014.07.21 添加 lzo 的安装 2014.05.20 修改cdh4为cdh5进行安装. 2014.10.22 ...
随机推荐
- 如何形象简单地理解java中只有值传递,而没有引用传递?
首先,java中只有值传递,没有引用传递.可以说是"传递的引用(地址)",而不能说是"按引用传递". 按值传递意味着当将一个参数传递给一个函数时,函数接收的是原 ...
- Golang:将日志以Json格式输出到Kafka
在上一篇文章中我实现了一个支持Debug.Info.Error等多个级别的日志库,并将日志写到了磁盘文件中,代码比较简单,适合练手.有兴趣的可以通过这个链接前往:https://github.com/ ...
- socket套接字补充、操作系统发展史、进程
目录 socket套接字之UDP协议 操作系统的发展史 手工操作 批处理系统 联机批处理系统 脱机批处理系统 多道技术 进程理论 并发与并行 同步与异步 阻塞与非阻塞 同步异步与阻塞非阻塞总结 soc ...
- MySql笔记Ⅰ
MySql part 1: 数据库概念 数据库:(DataBase, 简称DB):数据库中的数据按一定的数据模型组织.描述和储存,具有较小的冗余度.较高的数据独立性和易扩展性,并可为各种 用户共享 数 ...
- String、StringBuilder、StringBuffer——JavaSE基础
String.StringBuilder.StringBuffer String不可变 StringBuilder与StringBuffer均可变 StringBuilder线程不安全,效率高,常用 ...
- 验证cuda和cudnn是否安装成功(转载)
本人cuda安装目录: 当然cuda安装目录也可默认:此处为方便安装不同cuda版本,所以单独建了文件夹. 转载自:https://zhuanlan.zhihu.com/p/139668028 安装完 ...
- Linux系列之linux访问windows文件
Linux永久挂载windows共享文件 Linux系统必须安装samba-client Linux服务器必须能访问到Windows的共享文件服务的(445端口) 1.Windows共享文件 2.测试 ...
- 喜提JDK的BUG一枚!多线程的情况下请谨慎使用这个类的stream遍历。
你好呀,我是歪歪. 前段时间在 RocketMQ 的 ISSUE 里面冲浪的时候,看到一个 pr,虽说是在 RocketMQ 的地盘上发现的,但是这个玩意吧,其实和 RocketMQ 没有任何关系. ...
- SQL Server 2008~2019版本序列号/密钥/激活码 汇总
SQL Server 2019 Enterprise:HMWJ3-KY3J2-NMVD7-KG4JR-X2G8G Strandard:PMBDC-FXVM3-T777P-N4FY8-PKFF4 SQL ...
- Vue 安装 vue的基本使用 vue的初步使用步骤
1. 资源: https://cn.vuejs.org/v2/guide/#%E8%B5%B7%E6%AD%A5 进入官网学习 2. 点击安装,要把vue下载到本地文件的根目录中,不要选择压缩版的,这 ...