NAS数据存储之NFS搭建和使用
NFS是主流异构平台的共享文件系统之一,能够支持在不同类型的系统之间通过网络进行文件共享,允许一个系统在网络上与他人共享目录和文件。NFS传输协议用于服务器和客户机之间的文件访问和共享通信,从而使客户机进程访问保存在存储设备上的数据,挂载成功的情况下,在客户机挂载的目录中操作,如增删改文件或目录,服务器也同样生效。以下就是NFS的搭建方式和遇到的问题分享。
一,环境准备
VMware创建两台虚拟机,我选择的是centos7,如果需要新创建虚拟机,按照网上的教程,编辑/etc/sysconfig/network-scripts/ifcfg-ens33文件,设置虚拟机的ip固定。我主备的环境是服务器端:192.168.229.129,客户机端:192.168.229.130。尽量让两个版本一致,不一致的,比如服务器端是centos8,就出现了奇奇怪怪的问题,后面再详细说一下。
二,分别在两台机器安装rpcbind、nfs-utils
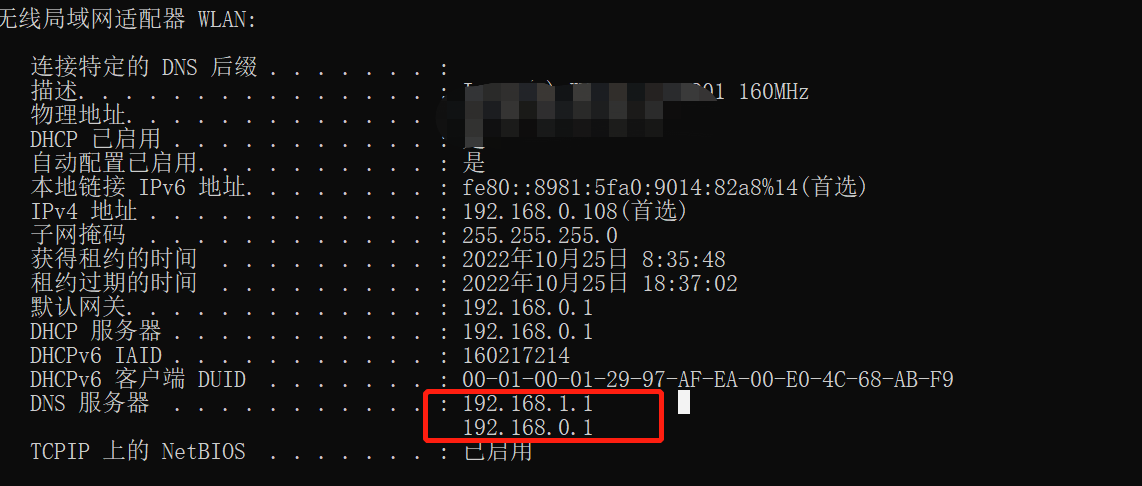
因为centos7也算是比较老的版本了,而且我选择的镜像也比较简单,这两个服务都没有安装,通过yum命令来做,即 yum -y install rpcbind nfs-utils。如果新环境yum有问题,ping www.baidu.com 等不行,也许是dns的解析文件没有配置,我做了如下配置,修改/etc/resolv.conf,两个地址是windows命令行使用ipconfig -all查询的本地电脑的dns解析地址。
三,服务器端创建要共享的目录,并设置权限为777
mkdir /data/share/
chmod 755 -R /data/share/
四,配置NFS配置
nfs的配置文件是 /etc/exports ,vi /etc/exports后,在配置文件中加入一行:
/data/share/ *(rw,no_root_squash,no_all_squash,sync)
配置可以以ip/端口或者通配为*,ip和端口是客户端的,意思是允许共享的客户端,我为了避免更多的坑,就通配了*,()中的几个参数分别是:
rw 表示设置目录可读写。
no_root_squash NFS客户端连接服务端时如果使用的是root的话,那么对服务端分享的目录来说,也拥有root权限。
no_all_squash 不论NFS客户端连接服务端时使用什么用户,对服务端分享的目录来说都不会拥有匿名用户权限。
sync 表示数据会同步写入到内存和硬盘中,相反 rsync 表示数据会先暂存于内存中,而非直接写入到硬盘中。
如果有多个共享目录配置,则使用多行,一行一个配置。保存好配置文件后,需要执行 exportfs -r 使配置立即生效.
五,防火墙相关配置
配置文件是 /etc/sysconfig/nfs,编辑的话把以下几个插入,实际使用时,不用配置这几个,防火墙等等的关闭了或者放开的比较宽,也能正常互访。
RQUOTAD_PORT=1001
LOCKD_TCPPORT=30001
LOCKD_UDPPORT=30002
MOUNTD_PORT=1002
配置防火墙使用以下几个命令
添加nfs相关端口:
firewall-cmd --zone=public --add-port=111/tcp --add-port=111/udp --add-port=2049/tcp --add-port=2049/udp --add-port=1001/tcp --add-port=1001/udp --add-port=1002/tcp --add-port=1002/udp --add-port=30001/tcp --add-port=30002/udp --permanent
重新加载防火墙配置:
firewall-cmd --reload
六,启动服务
按顺序启动rpcbind和nfs服务,(此顺序不能颠倒,否则后续可能会报错):
systemctl start rpcbind
systemctl start nfs(centos7)
systemctl start nfs-server(centos8)
加入开机启动:
systemctl enable rpcbind
systemctl enable nfs(centos7)
systemctl enable nfs-server(centos8)
nfs服务启动后,可以使用命令 rpcinfo -p 查看端口是否生效。
服务器启动后,我们可以使用 showmount 命令来查看服务端(本机)是否可连接:
服务器端执行 showmount -e localhost

客户机端执行showmount -e 192.168.229.129
如果showmount 命令不可用,则可能是客户端忘记装nfs-utils了,用yum安装即可。
七,客户机执行挂载命令
客户机创建需要挂载的本地目录,并赋权777
mkdir /mnt/share
chmod -R 777 /mnt/share
mount -t nfs 192.168.229.129:/data/share /mnt/share/ -o nolock,nfsvers=3,vers=3
如果没有报错提示的话,执行df -h命令查看,如果显示文件系统是服务端ip:/目录 ,容量也对应上了服务器的用量,则表示挂载成功了,在本地目录/mnt/share执行ls -l 可以看到服务的/data/share中的目录和文件,前提是/data/share在挂载前已经有数据。再用touch命令创建几个文件,服务器创建的,客户机会有,客户机创建的,服务器也有,表示一切顺利。也可能出现挂载显示成功,数据不同步的情况,后面再详细分析可能性。
八,可能出现的问题分析
1,按照以上顺序操作,基本上不会有问题,因为什么都是从头开始的,包括服务器的/data/share和客户机的/mnt/share都没有数据。而且挂载前不cd到/mnt/share目录。但是,若是挂载前cd到客户机的/mnt/share目录了,即使挂载成功,在当前终端的/mnt/share目录操作还是本地的,不同步到服务器端,服务器端创建的,当下也看不到。解决方法也简单,就是cd ..,然后在cd到share目录,或者打开一个新的终端窗口,ls查看是否更新,如果还不行,就是先卸载挂载,本地的什么都清空,重启服务器端的nfs,然后客户端再进行挂载操作。在操作中,还有一种不同步的情况,属于是我瞎操作了,给大家简单说下。就是我还有一台centos8的云服务器,也想设置NFS,当作服务端。按照上面配置,虚拟机的客户端,挂载虚拟机服务端,虚拟机的服务端的/data/share目录又作为本地挂载点挂载到云服务器,这就出现,虚拟机的服务端又是客户端,与云服务器共享了,我以为虚拟机那个纯客户端的,也会共享到云服务器端,但是没有,正如上所述的,/data/share也是作为一个本地文件系统的存在的,在纯客户端那个机器上操作,只会到虚拟机服务端的本地/data/share目录,在虚拟机服务端机器上卸载云服务器挂载,进到/data/share目录,发现了纯客户端创建的新文件。如果想三台机器共享,只要都挂载云服务就可以了,这种一传一的,着实摸不清楚套路。
2,执行卸载挂载的umount命令,出现umount.nfs: /mnt/share: device is busy ,这种情况可能是在当前终端在共享目录里,或者有其它终端在共享目录中,比如在/mnt/share下,等一会执行也没啥用。解决方法就是cd ..出去,也操作其它当前ip的终端窗口,cd ..出去。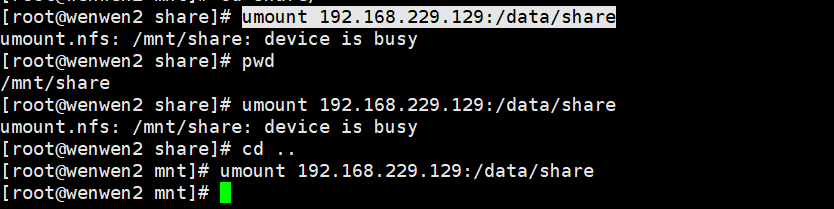
3,挂载出现 access denied by server while mounting 192.168.229.129:/data/share ,这种是129的目录已经挂载到云服务器了,先在129卸载云服务器的挂载后再执行。
4,挂载没反应,一直卡着,过会返回mount.nfs: Connection refused,则是我在关闭虚拟机服务端的nfs服务时,出现的,包括已经挂载后,创建文件时卡着了,则都可能时服务端的nfs服务未启动。解决方法就是去nfs服务端执行systemctl start nfs来启动。
5,服务端的nfs服务未启动,在客户机用showmount -e 192.168.229.123命令,出现以下错误
6,服务端停掉rpcbind服务
7,服务端停掉rpcbind服务,也停掉nfs服务时
8,还有 mount.nfs: Stale file handle ,不太晓得什么原因,解决方法就是重启服务端的两个服务。
9,客户机show -e 云服务器ip,卡了一会,然后返回clnt_create: RPC: Port mapper failure - Timed out,这种不太清楚哪里不对,只知道我的云服务器是centos8,yum安装的nfs-utils不是一个版本。但是我在客户端挂载是能成功的,数据也能共享。不知道问题在哪里,不影响使用,就没去钻研这个问题。
NAS数据存储之NFS搭建和使用的更多相关文章
- Nfs+Drdb+Heartbeat 数据存储高可用服务架构方案
一.方案的应用场景 适用于2千万-3千万PV架构的网站,Nfs数据存储高可用服务方案 备注:互联网排名前30左右公司常用的架构 二.生产环境方案部署原理图 三.生产环境服务器硬件配置: 生产环境中采用 ...
- 环境搭建 Hadoop+Hive(orcfile格式)+Presto实现大数据存储查询一
一.前言 Hadoop简介 Hadoop就是一个实现了Google云计算系统的开源系统,包括并行计算模型Map/Reduce,分布式文件系统HDFS,以及分布式数据库Hbase,同时Hadoop的相关 ...
- Elasticsearch集群搭建及使用Java客户端对数据存储和查询
本次博文发两块,前部分是怎样搭建一个Elastic集群,后半部分是基于Java对数据进行写入和聚合统计. 一.Elastic集群搭建 1. 环境准备. 该集群环境基于VMware虚拟机.CentOS ...
- java调用Linux执行Python爬虫,并将数据存储到elasticsearch--(环境脚本搭建)
java调用Linux执行Python爬虫,并将数据存储到elasticsearch中 一.以下博客代码使用的开发工具及环境如下: 1.idea: 2.jdk:1.8 3.elasticsearch: ...
- Kooboo CMS技术文档之三:切换数据存储方式
切换数据存储方式包括以下几种: 将文本内容存储在SqlServer.MySQL.MongoDB等数据库中 将站点配置信息存储在数据库中 将后台用户信息存储在数据库中 将会员信息存储在数据库中 将图片. ...
- iOS本地数据存储(转载)
看到一篇不错的文章,推荐给大家!!! 应用沙盒 1)每个iOS应用都有自己的应用沙盒(应用沙盒就是文件系统目录),与其他文件系统隔离.应用必须待在自己的沙盒里,其他应用不能访问该沙盒 2)应用沙盒的文 ...
- [转载]存储基础:DAS/NAS/SAN存储类型及应用
这篇文章转自博客教主的一篇博客存储基础:DAS/NAS/SAN存储类型及应用, 他是在张骞的这篇博客DAS,NAS,SAN在数据库存储上的应用上做了部分修改和补充. 一. 硬盘接口类型 1. 并行 ...
- linux高级数据存储
linux内此存储模式由5部分组成,自低向上的顺序: 物理卷,内核块设备驱动,内核文件系统驱动,虚拟文件系统,应用程序数据结构; 系统中所有的文件仅按此模式存储,无论是数据还是元数据,均在此模式下统一 ...
- Microsoft IoT Starter Kit 开发初体验-反馈控制与数据存储
在上一篇文章<Microsoft IoT Starter Kit 开发初体验>中,讲述了微软中国发布的Microsoft IoT Starter Kit所包含的硬件介绍.开发环境搭建.硬件 ...
随机推荐
- Spring 02 控制反转
简介 IOC IOC(Inversion of Control),即控制反转. 这不是一项技术,而是一种思想. 其根本就是对象创建的控制权由使用它的对象转变为第三方的容器,即控制权的反转. DI DI ...
- 微服务性能分析|Pyroscope 在 Rainbond 上的实践分享
随着微服务体系在生产环境落地,也会伴随着一些问题出现,比如流量过大造成某个微服务应用程序的性能瓶颈.CPU利用率高.或内存泄漏等问题.要找到问题的根本原因,我们通常都会通过日志.进程再结合代码去判断根 ...
- Apache DolphinScheduler 简单任务定义及复杂的跨节点传参
点亮 ️ Star · 照亮开源之路 GitHub:https://github.com/apache/dolphinscheduler Apache DolphinScheduler是一款非常不 ...
- SpringBoot使用自定义注解+AOP+Redis实现接口限流
为什么要限流 系统在设计的时候,我们会有一个系统的预估容量,长时间超过系统能承受的TPS/QPS阈值,系统有可能会被压垮,最终导致整个服务不可用.为了避免这种情况,我们就需要对接口请求进行限流. 所以 ...
- LIMIT和OFFSET分页性能差!今天来介绍如何高性能分页
GreatSQL社区原创内容未经授权不得随意使用,转载请联系小编并注明来源. GreatSQL是MySQL的国产分支版本,使用上与MySQL一致. 前言 之前的大多数人分页采用的都是这样: SELEC ...
- IDEA 修改注释的颜色
- [Python]-string-字符串
字符串是Python中很常用的数据类型,此处记录一些典型用法并随时更新. split()方法 通过指定分隔符对字符串进行切片,如果参数 num 有指定值,则分隔 num+1 个子字符串. 两个参数st ...
- Java 快速开发几 MB 独立 EXE,写图形界面很方便
Java 写的桌面软件带上运行时只有 6 MB,而且还是独立 EXE 文 件,是不是难以置信? 想一想 Electron 没写多少功能就可能超过百 MB 的体积,Java 写的桌面软件算不算得上小.轻 ...
- @EqualsAndHashCode(callSuper = false) 解释
当我们的pojo使用@Data注解时,@Data默认包含的是:@EqualsAndHashCode(callSuper = false),但是我们的pojo有继承父类,我们可能需要重新定义这个注解为: ...
- Elastic:菜鸟上手指南
文章链接:https://elasticstack.blog.csdn.net/article/details/102728604