hashmap的一些性能测试
0.前言
本文主要讨论哈希冲突下的一些性能测试。
为什么要写这篇文章,不是为了KPI不是为了水字数。
hashmap是广大JAVA程序员最为耳熟能详,使用最广泛的集合框架。它是大厂面试必问,著名八股经必备。在小公司呢?这些年也面过不少人,对于3,5年以上的程序员,问到hashmap也仅限于要求知道底层是数组+链表,知道怎么放进去,知道有哈希冲突这么一回事即可,可依然免不了装备的嫌疑。
可hashmap背后的思想,在缓存,在数据倾斜,在负载均衡等分布式大数据领域都能广泛看到其身影。了解其背后的思想不仅仅只是为了一个hashmap.
更重要的是,hashmap不像jvm底层原理那么遥远,不像并发编程那么宏大,它只需要通勤路上十分钟就可搞定基本原理,有什么理由不呢?
所以本文试着从相对少见的一个微小角度来重新审视一下hashmap.
1.准备工作。
1.1模拟哈希冲突
新建两个class,一个正常重写equals和hashcode方法,一个故意在hashcode方法里返回一定范围内的随机数,模拟哈希冲突,以及控制哈希冲突的程序。
不冲突的类
@Setter
public class KeyTest2 {
private String name;
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
KeyTest2 keyTest = (KeyTest2) o;
return name != null ? name.equals(keyTest.name) : keyTest.name == null;
}
@Override
public int hashCode() {
return name != null ? name.hashCode() : 0;
}
}
冲突的类
@Setter
@NoArgsConstructor
public class KeyTest {
private String name;
private Random random;
public KeyTest(Random random){
this.random = random;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
KeyTest keyTest = (KeyTest) o;
return name != null ? name.equals(keyTest.name) : keyTest.name == null;
}
@Override
public int hashCode() {
// return name != null ? name.hashCode() : 0;
return random.nextInt(1000);
}
}
众所周知,hashmap在做put的时候,先根据key求hashcode,找到数组下标位置,如果该位置有元素,再比较equals,如果返回true,则替换该元素并返回被替换的元素;否则就是哈希冲突了,即hashcode相同但equals返回false。
哈希冲突的时候在冲突的数组处形成数组,长度达到8以后变成红黑树。
1.2 java的基准测试。
这里使用JMH进行基准测试.
JMH是Java Microbenchmark Harness的简称,一般用于代码的性能调优,精度甚至可以达到纳秒级别,适用于 java 以及其他基于 JVM 的语言。和 Apache JMeter 不同,JMH 测试的对象可以是任一方法,颗粒度更小,而不仅限于rest api.
jdk9以上的版本自带了JMH,如果是jdk8可以使用maven引入依赖。
点击查看JMH依赖
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-core</artifactId>
<version>${jmh.version}</version>
</dependency>
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-generator-annprocess</artifactId>
<version>${jmh.version}</version>
</dependency>
2.测试初始化长度
点击查看初始化长度基本测试代码
/使用模式 默认是Mode.Throughput
@BenchmarkMode(Mode.AverageTime)
// 配置预热次数,默认是每次运行1秒,运行10次,这里设置为3次
@Warmup(iterations = 3, time = 1)
// 本例是一次运行4秒,总共运行3次,在性能对比时候,采用默认1秒即可
@Measurement(iterations = 3, time = 4)
// 配置同时起多少个线程执行
@Threads(1)
//代表启动多个单独的进程分别测试每个方法,这里指定为每个方法启动一个进程
@Fork(1)
// 定义类实例的生命周期,Scope.Benchmark:所有测试线程共享一个实例,用于测试有状态实例在多线程共享下的性能
@State(value = Scope.Benchmark)
// 统计结果的时间单元
@OutputTimeUnit(TimeUnit.NANOSECONDS)
public class HashMapPutResizeBenchmark {
@Param(value = {"1000000"})
int value;
/**
* 初始化长度
*/
@Benchmark
public void testInitLen(){
HashMap map = new HashMap(1000000);
Random random = new Random();
for (int i = 0; i < value; i++) {
KeyTestConflict test = new KeyTestConflict(random, 10000);
test.setName(i+"");
map.put(test, test);
}
}
/**
* 不初始化长度
*/
@Benchmark
public void testNoInitLen(){
HashMap map = new HashMap();
for (int i = 0; i < value; i++) {
Random random = new Random();
KeyTestConflict test = new KeyTestConflict(random, 10000);
test.setName(i+"");
map.put(test, test);
}
}
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder()
.include(HashMapPutResizeBenchmark.class.getSimpleName())
.mode(Mode.All)
// 指定结果以json结尾,生成后复制可去:http://deepoove.com/jmh-visual-chart/ 或https://jmh.morethan.io/ 得到可视化界面
.result("hashmap_result_put_resize.json")
.resultFormat(ResultFormatType.JSON).build();
new Runner(opt).run();
}
}
测试结果图
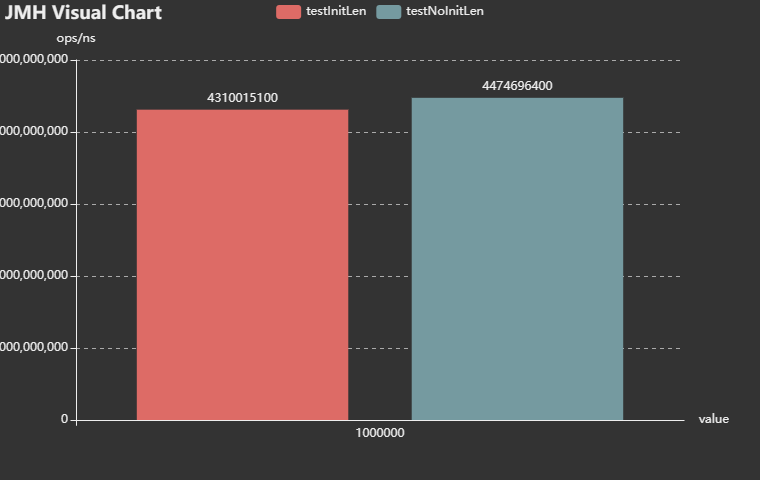
对测试结果图例做一个简单的说明:
以上基准测试,会得到一个json格式的结果。然后将该结果上传到官方网站,会得到一个上述图片的结果。
横坐标,红色驻图代表有冲突,浅蓝色驻图无冲突。
众坐标,ops/ns代表平均每次操作花费的时间,单位为纳秒,1秒=1000000000纳秒,这样更精准。
下同。
简单说,驻图越高代表性能越低。
我测了两次,分别是无哈希冲突和有哈希冲突的,这里只贴一种结果。
测试结果表明,hashmap定义时有初始化对比无初始化,有大约4%到12%的性能损耗。
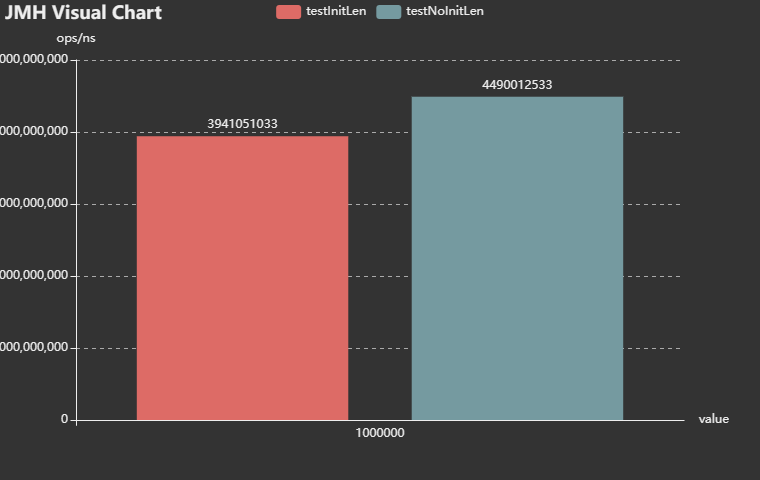
足够的初始化长度下,有哈希冲突的测试结果:
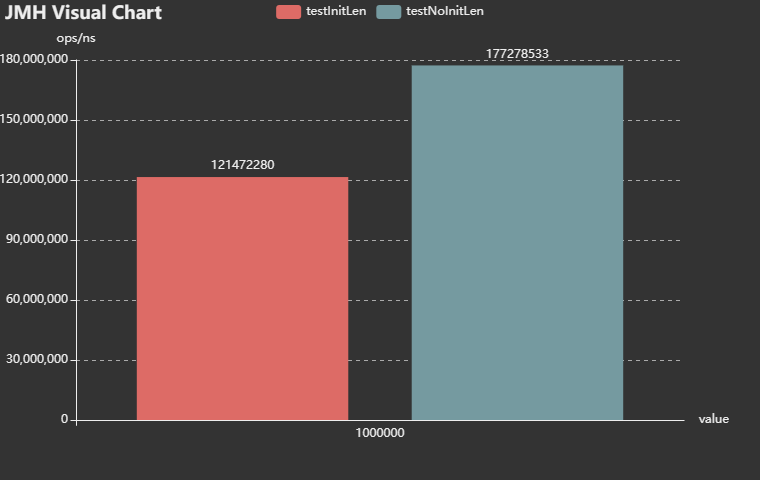
足够的初始化长度下,没有哈希冲突的测试结果:
3.模拟一百万个元素put,get的差异。
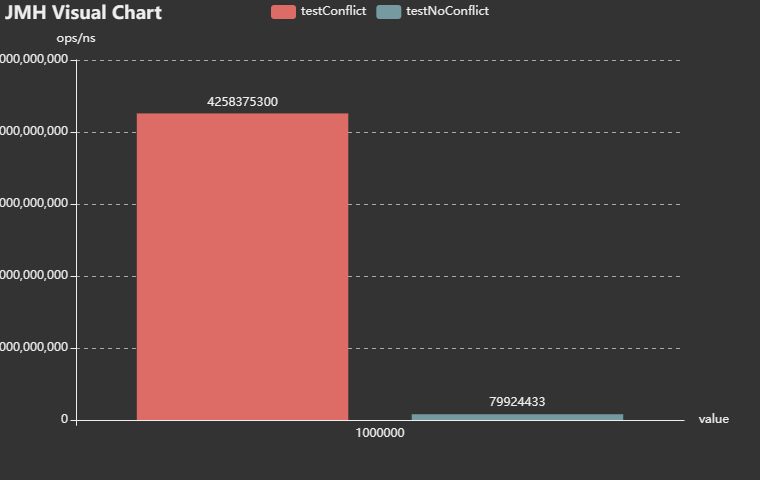
众所周知,hashmap在频繁做resize时,性能损耗非常严重。以上是没初始化长度,无冲突和有冲突的情况下,前者性能是后者性能的53倍。
那么在初始化长度的情况下呢?
HashMap map = new HashMap(1000000);
同样的代码下,得到的测试结果

以上是有初始化长度,无冲突和有冲突的情况下,前者性能是后者性能的58倍。
大差不差,不管有无初始化长度,无冲突的效率都是有冲突效率的50倍以上。说明,这是哈希冲突带来的性能损耗。
4.模拟无红黑树情况下get效率
4.1 将random扩大,哈希冲突严重性大大减小,模拟大多数哈希冲突导致的哈希链长度均小于8,无法扩展为红黑树,只能遍历数组。
将KeyTest的hashcode方法改为:
@Override
public int hashCode() {
// return name != null ? name.hashCode() : 0;
return random.nextInt(130000);
}
这样1000000/130000 < 8,这样大多数的哈希链将不会扩展为红黑树。
测试结果为:

测试结果说明,**有冲突的效率反而比无冲突的效率要高**,差不多高出80%左右。
这其实有点违反常识,我们通常讲,hashmap要尽量避免哈希冲突,哈希冲突的情况下写入和读取性能都会受到很大的影响。
但是上面的测试结果表明,大数据量相对比较大的时候,适当的哈希冲突(<8)反而读取效率更高。
个人猜测是,适当的哈希冲突,数组长度大为减少。
为了证明以上猜想,直接对ArrayList进行基准测试。
4.1.1 ArrayList不同长度下get效率的基准测试
模拟一个哈希冲突非常严重下,底层数组长度较小的list,和哈希冲突不严重情况下,底层数组较大的list,再随机测试Get的效率如何。
点击查看测试代码
//使用模式 默认是Mode.Throughput
@BenchmarkMode(Mode.AverageTime)
// 配置预热次数,默认是每次运行1秒,运行10次,这里设置为3次
@Warmup(iterations = 3, time = 1)
// 本例是一次运行4秒,总共运行3次,在性能对比时候,采用默认1秒即可
@Measurement(iterations = 3, time = 4)
// 配置同时起多少个线程执行
@Threads(1)
//代表启动多个单独的进程分别测试每个方法,这里指定为每个方法启动一个进程
@Fork(1)
// 定义类实例的生命周期,Scope.Benchmark:所有测试线程共享一个实例,用于测试有状态实例在多线程共享下的性能
@State(value = Scope.Benchmark)
// 统计结果的时间单元
@OutputTimeUnit(TimeUnit.NANOSECONDS)
public class ArrayListGetBenchmark {
// @Param(value = {"1000","100000","1000000"})
@Param(value = {"1000000"})
int value;
@Benchmark
public void testConflict(){
int len = 10000;
Random random = new Random(len);
for (int i = 0; i < 100; i++) {
int index = random.nextInt(len);
System.out.println("有冲突,index = " + index);
ConflictHashMapOfList.list.get(index);
}
}
@Benchmark
public void testNoConflict(){
int len = 1000000;
Random random = new Random(len);
for (int i = 0; i < 100; i++) {
int index = random.nextInt(len);
System.out.println("无冲突,index = " + index);
NoConflictHashMapOfList.list.get(index);
}
}
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder()
.include(HashMapGetBenchmark.class.getSimpleName())
.mode(Mode.All)
// 指定结果以json结尾,生成后复制可去:http://deepoove.com/jmh-visual-chart/ 或https://jmh.morethan.io/ 得到可视化界面
.result("arraylist_result_get_all.json")
.resultFormat(ResultFormatType.JSON).build();
new Runner(opt).run();
}
@State(Scope.Thread)
public static class ConflictHashMapOfList {
volatile static ArrayList list = new ArrayList();
static int randomMax = 10000;
static {
// 模拟哈希冲突严重,数组长度较小
for (int i = 0; i < randomMax; i++) {
list.add(i);
}
}
}
@State(Scope.Thread)
public static class NoConflictHashMapOfList {
volatile static ArrayList list = new ArrayList();
static int randomMax = 1000000;
static {
// 模拟没有哈希冲突,数组长度较大
for (int i = 0; i < randomMax; i++) {
list.add(i);
}
}
}
}
测试结果如下:
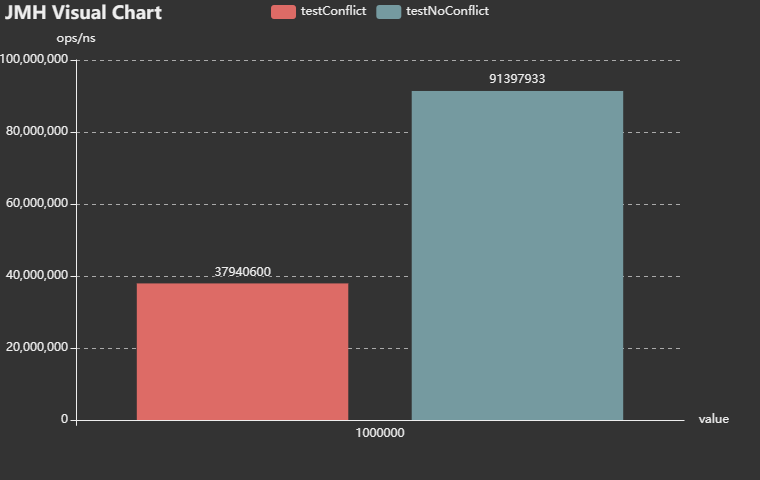
可以看到,间接证实了以上的猜想。
当然这里的代码可能并不严谨,也欢迎大家一起讨论。
4.2 jdk1.8版本,哈希冲突严重下的get效率测试

测试结果说明:在jdk8,无冲突效率是有有冲突的3倍左右。
4.3 将jdk版本降为1.7,在哈希冲突依然严重的情况下,get效率如何?
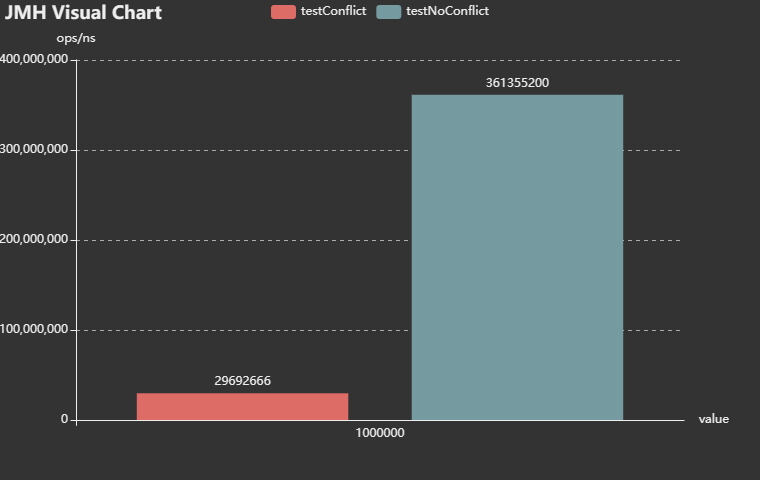
测试结果说明:在jdk7,无冲突效率是有有冲突的12倍左右。
结合4.1和4.2的测试对比,说明jdk1.8红黑树的优化效率确实提升很大。
5.总结
1.初始化的时候指定长度,长度要考虑到负载因子0.75.初始化的影响受到哈希冲突的影响,没有那么大(相对于倍数而言),但也不小。
2.哈希冲突严重时,put性能急剧下降。(几十倍级)
3.相同元素个数的前提下,在哈希冲突时,get效率反而更高。
4.相比之前的版本,哈希冲突严重时,jdk8红黑树对get效率有非常大的提升。
测试代码和测试结果在 这里
hashmap的一些性能测试的更多相关文章
- 数据结构HashMap(Android SparseArray 和ArrayMap)
HashMap也是我们使用非常多的Collection,它是基于哈希表的 Map 接口的实现,以key-value的形式存在.在HashMap中,key-value总是会当做一个整体来处理,系统会根据 ...
- HashMap和布隆过滤器命中性能测试
package datafilter; import com.google.common.base.Stopwatch; import com.google.common.hash.BloomFilt ...
- java——HashMap的实现原理,自己实现简单的HashMap
数据结构中有数组和链表来实现对数据的存储,但是数组存储区间是连续的,寻址容易,插入和删除困难:而链表的空间是离散的,因此寻址困难,插入和删除容易. 因此,综合了二者的优势,我们可以设计一种数据结构-- ...
- HashMap循环遍历方式及其性能对比(zhuan)
http://www.trinea.cn/android/hashmap-loop-performance/ ********************************************* ...
- [Java] 多个Map的性能比较(TreeMap、HashMap、ConcurrentSkipListMap)
比较Java原生的 3种Map的效率. 1. TreeMap 2. HashMap 3. ConcurrentSkipListMap 结果: 模拟150W以内海量数据的插入和查找,通过增加和查找 ...
- 介绍4款json的java类库 及 其性能测试
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式. 易于人阅读和编写.同时也易于机器解析和生成. 它基于JavaScript Programming Lan ...
- HashMap循环遍历方式及其性能对比
主要介绍HashMap的四种循环遍历方式,各种方式的性能测试对比,根据HashMap的源码实现分析性能结果,总结结论. 1. Map的四种遍历方式 下面只是简单介绍各种遍历示例(以HashMap为 ...
- Java HashMap工作原理及实现
Java HashMap工作原理及实现 2016/03/20 | 分类: 基础技术 | 0 条评论 | 标签: HASHMAP 分享到:3 原文出处: Yikun 1. 概述 从本文你可以学习到: 什 ...
- 【hashMap】详谈
官方文档地说明 几个关键的信息:基于Map接口实现.允许null键/值.非同步.不保证有序(比如插入的顺序).也不保证序不随时间变化. 一.概述 HashMap 是一个散列表,它存储的内容是键值对(k ...
- 数据库之redis篇(2)—— redis配置文件,常用命令,性能测试工具
redis配置 如果你是找网上的其他教程来完成以上操作的话,相信你见过有的启动命令是这样的: 启动命令带了这个参数:redis.windows.conf,由于我测试环境是windows平台,所以是这个 ...
随机推荐
- 「MySQL高级篇」MySQL锁机制 && 事务
大家好,我是melo,一名大三后台练习生,最近赶在春招前整理整理发过的博客~! 引言 锁锁锁,到哪到离不开这桩琐事,并发琐事,redis琐事,如今是MySQL琐事,这其中琐事,还跟MySQL另一个重要 ...
- mybatis-获取参数值的方式
MyBatis获取参数值的两种方式(重点) MyBatis获取参数值的两种方式:${}和#{} ${}的本质就是字符串拼接,#{}的本质就是占位符赋值 ${}使用字符串拼接的方式拼接sql,若为字符串 ...
- adb 安装与使用
什么是adb adb 是有个通用命令行工具 他允许您与模拟器实例或者链接的Android设备进行通信,他可为各种设备操作提供便利,比如安装和调试应用 启动adb 服务在命令行中输入adb start- ...
- 京东云开发者|经典同态加密算法Paillier解读 - 原理、实现和应用
摘要 随着云计算和人工智能的兴起,如何安全有效地利用数据,对持有大量数字资产的企业来说至关重要.同态加密,是解决云计算和分布式机器学习中数据安全问题的关键技术,也是隐私计算中,横跨多方安全计算,联邦学 ...
- 如何在bat中进入虚拟环境
很多情况下我们希望在项目中建立一个build.bat用于项目的自动构建,避免每次构建时都需要手动在控制台中输入命令. 例如对于 pyinstall 的项目,只需要如下的实现: pyinstaller ...
- SimpleDateFormat线程安全问题排查
一. 问题现象 运营部门反馈使用小程序配置的拉新现金红包活动二维码,在扫码后跳转至404页面. 二. 原因排查 首先,检查扫码后的跳转链接地址不是对应二维码的实际URL,根据代码逻辑推测,可能是acc ...
- 常用Python库整理
记录工作和学习中遇到和使用过的Python库. Target 四个Level 整理 Collect 学习 Learn 练习 Practice 掌握 Master 1. Python原生和功能增强 1. ...
- perl遍历哈希的所有健和值
my %h=("001",{name,"李白",age,"18",height,"185",weight,"6 ...
- Postman使用指导
1. 下载好Postman,不用注册账号,直接离线使用 2. 软件的配置修改: 2.1关闭SSL认证 2.2关闭系统代理 2.3上传证书填写hosthost为服务器地址和端口:crt和key可以通过国 ...
- Springboot 整合 SpringCache 使用 Redis 作为缓存
一直以来对缓存都是一知半解,从没有正经的接触并使用一次,今天腾出时间研究一下缓存技术,开发环境为OpenJDK17与SpringBoot2.7.5 SpringCache基础概念 接口介绍 首先看看S ...