动力节点——day08
- 什么是集合,有什么用?
- 数组其实就是一个集合,集合实际上就是一个容器,可以用来容纳其他数据类型
- 集合为什么说在开发中使用最多?
- 集合是一个容器,是一个载体,可以一次容纳多个对象,在实际开发中,假设连接数据库,数据库当中有10条数据,那么假设把这10条数据查询处来,在Java程序中会将10条数据封装成10个Java对象,然后将这10个Java对象放到某一个集合当中,将集合传到前端,然后遍历集合,让数据一个个展现出来。
- 集合不能直接存储基本数据类型,另外集合也不能存储Java对象,集合当中存储的都是Java对象的内存地址(或者说集合当中存储的都是引用)
- 补:list.add(100);//是因为自动装箱
- 在Java中每一个不同的集合,底层会对应不同的数据结构,往不同的集合中存储元素,等于将数据放到了不同的数据结构中,什么是数据结构?数据存储的结构就是数据结构,不同的数据结构,存储方式不同,例如:数组、链表、二叉树、哈希表都是不同的数据结构。(在Java中已经写好了这些常用的集合类,不必精通数据结构)
- new ArrayList();创建一个集合对象,底层是数组
- new LinkedList();创建一个集合对象,底层是链表
- new TreeSet();创建一个集合对象,底层是二叉树
- 集合在Java JDK中哪个包下?java.util.*;所有的集合类和集合接口都在java.util包下
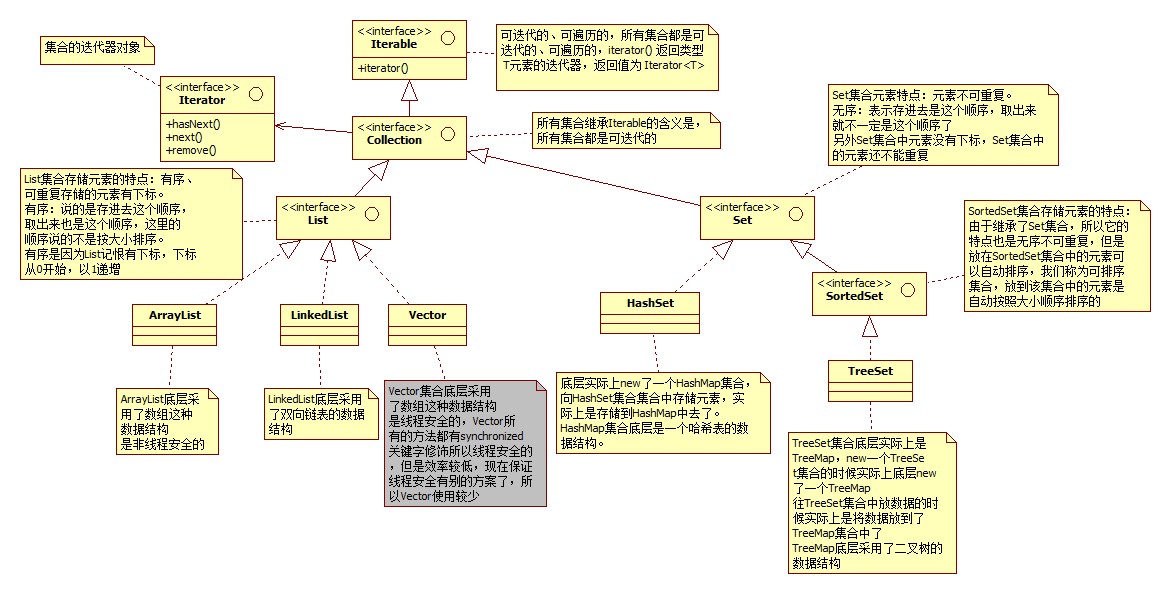
- 在java中集合分为两大类:
- 一类是单个方式存储元素,这类集合中超级父接口是:java.util.Collection
- 一类是以键值对的方式存储元素,这类集合中超级父接口是:java.util.Map
- 集合的继承结构
- 总结(所有的实现类)
- ArrayList:底层是数组
- LinkedList:底层是双向链表
- Vector:底层是数组,线程安全
- HashSet:底层是HashMap,放到HashSet集合中的元素等同于放到HashMap集合key部分了
- TreeSet:底层是TreeMap,放到TreeSet集合中的元素等同于放到TreeMap集合key部分了
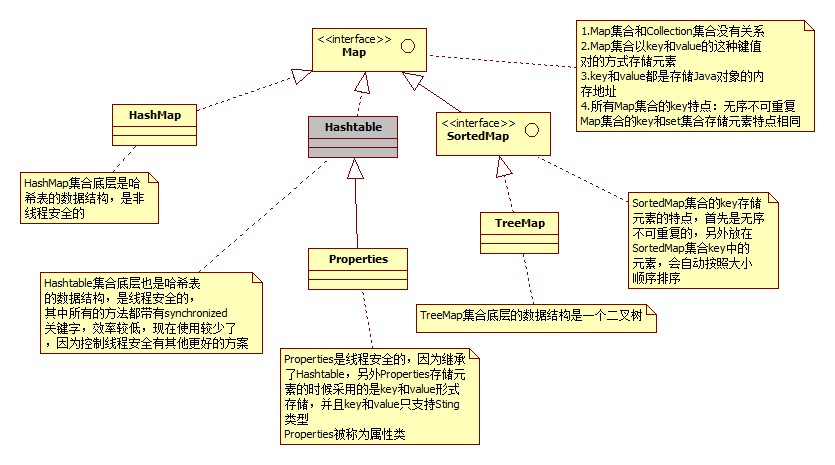
- HashMap:底层是哈希表的数据结构
- Hashtable:底层是哈希表的数据结构,只不过是线程安全的,效率较低,使用较少
- Properties:是线程安全的,并且key和value只能存储字符串
- TreeMap:底层是二叉树数据结构,TreeMap的key底层可以直接按照大小顺序排序、
- List集合存储元素的特点:
- 有序、可重复
- 有序:存进去顺序和取出的顺序相同,每一个元素都有下标
- 可重复:存进去1,可以再存储一个1
- Set(对应Map)集合存储元素的特点
- 无序、不可重复
- 无序:存进去顺序和取出的顺序不一定相同,另外Set集合中的元素没有下标
- 不可重复:存进去1,不能再存储1了
- SortedSet(对应SortedMap)集合存储元素的特点:
- 无序、不可重复,但是SortedSet集合中的元素是可排序的
- 无序:存进去顺序和取出的顺序不一定相同,另外SortedSet集合中的元素没有下标
- 不可重复:存进去1,不能再存储1了
- 可排序:可以按照大小顺序排序
- Map集合的key,就是一个Set集合:在Set集合中放数据,实际放到了Map集合的key部分
- Collection能存放什么元素:
- 没有使用泛型之前,Collection可以存放所有Object 的子类型
- 使用了泛型之后,Collection中只能存放某个具体的类型
- 集合中不能直接存储基本数据类型,也不能存储Java对象,只能存储Java对象的内存地址
- Collection中的常用方法
- boolean add(Object e);向集合中添加元素
- int size();获取集合中元素的个数
- void clear() 清空集合
- boolean contains(Object o)判断当前集合中是否包含元素o,不包含返回false
- contains方法是用来判断集合中是否包含了某个元素的方法,那么底层是如何判断集合中是否包含了这个元素呢?
- 调用了equals方法进行对比,equal方法返回true,就表示包含这个元素
- contains方法是用来判断集合中是否包含了某个元素的方法,那么底层是如何判断集合中是否包含了这个元素呢?
- boolean remove(Object o)删除集合中的某个元素
- 调用了equals方法进行对比,equal方法返回true,就表示包含这个元素
- boolean isEmpty()判断集合是否为空
- Object[] toArray()调用这个方法可以把集合转换成数组
- 对Collection集合进行遍历:(Collection c=new ArrayList();c.add("abd");c.add("def");c.add(100);c.add(new Object());)
- 第一步:获取集合对象的迭代器对象Iterator
- Iterator it=c.iterator();
- 第二步:通过以上获得的迭代器对象开始迭代/遍历
- 以下两个方法是迭代器对象Iterator中的方法:
- boolean hasNext();如果仍有元素可以迭代,则返回true
- Object next() 返回迭代器的下一个元素
- 以下两个方法是迭代器对象Iterator中的方法:
- 第一步:获取集合对象的迭代器对象Iterator
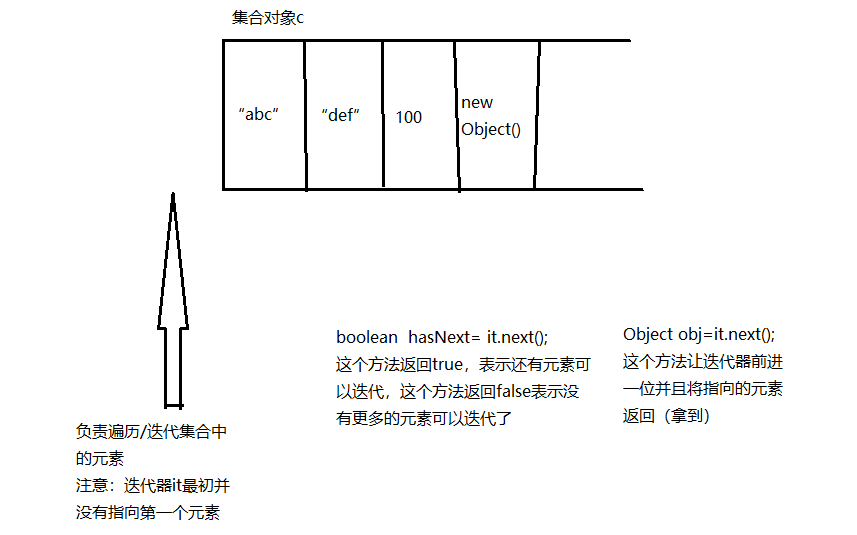
- 一定要注意:集合结构只要发生改变,迭代器必须重新获取
- 当集合结构发生了改变,迭代器没有重新获取时,调用next()方法时,会出现java.util.ConcurrentModificationException
- 集合元素的remove(add)
- 重点:当集合结构发生改变时,迭代器必须重新获取,如果还是以前老的迭代器,会出现异常java.util.ConcurrentModificationException
- 在迭代集合元素的过程中,不能调用集合对象的remove方法,删除元素:c.remove(o);迭代过程中不能这样,会出现异常java.util.ConcurrentModificationException,但是使用迭代器来删除是可以的
- 出异常的根本原因是:集合中的元素删除了,但是没有更新迭代器(迭代器不知道集合变化了)
- List集合存储元素的特点:
- 有序、可重复
- 有序:List集合中的元素有下标。从0开始,以1递增
- 可重复:存储一个1,还可以再存一个1
- List集合既然是Collection接口的子接口,那么肯定List集合有自己特有的方法(以下列出常用方法)
- void add(int index,E element) 在列表的指定位置插入指定元素
- E get(int index)返回列表中指定位置的元素
- int indexOf(Object) 返回列表中第一次出现的指定位置的索引,如果列表中不包含该元素,则返回-1
- int lastIndexOf(Object o) 返回列表中最后出现的指定位置的索引,如果列表中不包含该元素,则返回-1
- E set(int index,E element)用指定元素替换列表中指定位置的元素
- Object remove(int index,Object element)删除指定下标的元素
- 计算机英语要知道的几个单词
- 增:add、save、new
- 删:delete、drop、remove
- 改:update、set、modify
- 查:find、get、query、select
- ArrayList集合初始化容量及扩容(ArrayList集合是非线程安全的)
- ArrayList集合默认初始化容量是10(底层创建了一个长度为0的数组,当添加第一个元素的时候,初始化为10)
- ArrayList集合底层是Object类型的数组Object[]
- List list1=new ArrayList(); 默认初始化容量是10 list1.size(); 值为0
- List list2=new ArrayList(20); 指定初始化容量是20 list2.size(); 值为0
- 集合的size()方法获取的是当前集合中元素的个数,不是获取集合容量
- ArrayList的扩容,是原容量的1.5倍
- ArrayList集合底层是数组,怎么优化?
- 尽可能少的扩容,因为数组扩容效率比较低,建议使用ArrayList集合的时候,预估计元素的个数,给定初始化容量
- 数组优点:检索效率较高(每个元素占用空间大小相同,内存地址是连续的,知道首元素的地址,然后知道下标,通过数学表达式计算出元素的内存地址,所以检索效率最高)
- 数组缺点:随机增删效率比较低,另外数组无法存储大数据量(很难找到一块非常巨大的连续的内存空间)
- 向数组末尾增删元素,效率很高,不受影响
- ArrayList集合底层是数组,怎么优化?
- 链表
- 链表的优点:由于链表上的元素空间存储的内存地址不连续,随机增删效率较高(因为增删元素不涉及到大量的元素位移)
- 链表的缺点:查询效率低,每一次查找某个元素的时候,都需要从头节点开始往下遍历
- 对于链表数据结构来说,任何一个节点都有两个属性:
- 第一:存储的数据
- 第二:下一个节点的内存地址
- ArrayLIst是把检索发挥到极致,LInkedList是把随机增删发挥到极致,加元素都是往末尾添加,所以ArrayList比LinkedList使用多
- LinkedList集合没有初始化容量,最初这个链表没有任何元素,first和last都是null
- Vector
- 底层也是一个数组,初始化容量是10,扩容之后的容量是原容量的2倍,ArrayList集合的特点是:扩容之后的容量是原容量的1.5倍
- Vertor的所有方法都是线程同步的,都带有synchronized关键字,是线程安全的,效率比较低,使用较少
- 将一个线程不安全的ArrayList集合转换成线程安全的,使用集合工具类java.util.Collections;
- java.util.Collection是集合接口
- java.util.Collections是集合的工具类 Collections.synchronizedList(mylist);
- 泛型<JDK5.0之后推出的新特性>
- 泛型这种语法机制,只在程序编译阶段起作用,只是给编译器参考的(运行阶段反省没用)
- List<Animal> myList=new ArrayList<Animal>();
- 使用泛型的好处是什么:
- 第一:集合中存储的元素类型统一了
- 第二:从集合中取出的元素类型是泛型指定的元素类型,不需要进行大量的向下转型
- 泛型的缺点是什么:
- 导致集合中存储的元素缺乏多样性
- 大多数业务中,集合中元素的类型还是统一的,所以这种泛型特性被大家所认可
- JDK1.8之后,引入了自动类型推断机制(又称为钻石表达式)
- List<Animal> myList=new ArrayList<>();
- ArrayList<这里的类型会自动推断>()
- 泛型可以自定义
public class CollectionTest09<eeeeeeeeeeeeeeee> {
public static void main(String[] args) {
CollectionTest09<Integer> interger=new CollectionTest09<>();
interger.method1(123);
}
public void method1(eeeeeeeeeeeeeeee o){
System.out.println(o);
}
}自定义泛型的时候,<>尖括号中的是一个标识符,可以随便写,如果不用泛型就是Object类型
- Java中源代码中经常出现的是:<E><T>:E是Element单词首字母、T是Type类型的首字母
- JDK5.0新特性:foreach(也叫增强的for循环)
- for(元素类型 变量名:数组或集合){
- System.out.println(变量名);
- }
- foreach有一个缺点是没有下标,在需要使用下标的循环中,不建议使用增强的for循环
- for(元素类型 变量名:数组或集合){
- java.util.Map接口中常用的方法:
- Map和Collection没有继承关系
- Map集合以key和value的方式存储数据,键值对
- key和value都是引用数据类型
- key和value都是存储对象的内存地址
- key起到主导的地位,value是key的附属品
- void clear()从此映射中移除所有的映射关系
- boolean containsKey(Object key)如果此映射包含指定键的映射关系,则返回true,底层调用equals方法,就算new新对象也可以。
- boolean conrainsValue(Object value)如果此映射将一个或多个键映射到指定值,则返回true,则返回true,底层调用equals方法,就算new新对象也可以。
- V get(Object key)返回指定键所映射的值
- boolean isEmpty()如果此映射未包含键值关系,则返回true
- V put(K key,V value)将指定的值与此映射中指定的键关联
- V remove(Object key)如果存在一个键的映射关系,则将其从映射中移除
- int size()返回此映射键—值映射关系数
- Set<Map.Entry<K,V>> entrySet()返回此映射中包含映射关系的Set视图,Map.Entry属于静态内部类 1=zhangsan
- Set<K> keySet();获取Map集合的所有的key(所有的键是一个set集合)
- 哈希表的数据结构(数组和单向链表的结合体)
- 数组:在查询方面效率高,随机增删方面效率很低
- 单线链表:在查询方面效率低,随机增删方面效率很高
- 哈希表将以上两种数据结构融合在一起,充分发挥他们各自的优点
- 哈希表相当于是一个数组,数组中每个元素都可以是一个单链表,单链表中存储数据元素
- 哈希值是key的hashCode()方法执行的结果,hash值通过哈希函数/算法,可以转换成数组的下标
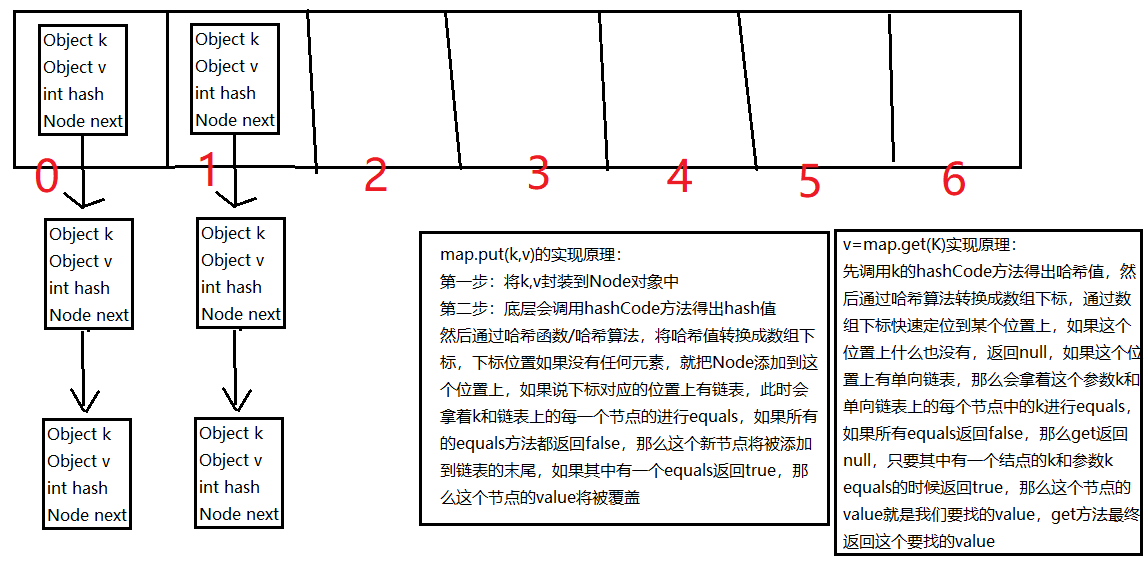
e为什么哈希表的随机增删,以及查询效率都很高?
- 增删是在链表上完成的
- 查询也不需要都扫描,只需要部分扫描即可
- 重点:HashMap的key会先后调用两个方法,一个方法是hashCode方法,一个方法是equals方法,那么这两个方法都需要重写
- HasMap集合key部分的特点:
- 无序、不可重复
- 无序:挂上去的顺序和取下的顺序不一样
- 不可重复:equals方法来保证HashMap集合的key不可重复,如果key重复了,value会覆盖
- 放在HashMap集合的key部分的元素其实就是放到了HashSet集合中了,所以HashSet集合当中的元素也需要同时重写hashCode()+equals()方法
- 哈希表HashMap使用不当无法发挥性能!
- 假设将所有的hashCode()方法返回固定的某个值,那么会导致底层的哈希表变成纯单向链表,这种情况下我们称为:散列分布不均匀
- 什么是散列分布均匀?
- 假设100个元素,10个单向链表,那么每个单向链表上有10个节点,这是最好的,是散列分布均匀的
- 假设将所有的hashCode()方法返回值都设定为不一样的值,可以吗,有什么问题?
- 不行,因为这样的话导致底层的哈希表就成为一维数组了,没有链表的概念了,也是散列分布不均匀
- 散列分布均匀需要重写hashCode方法时,有一定的技巧
- HashMap集合的默认初始化容量是16,默认加载因子是0.75,这个默认加载因子是当HashMap集合底层数组的容量达到75%的时候,数组开始扩容。在JDK1.8之后,如果哈希表单项链表中元素超过8个,单向链表这种数据结构会变成红黑树数据结构,当红黑树上的节点数小于6时,会重新把红黑树变成单向链表数据结构,这种方式是为了提高检索效率,二叉树的检索会再次缩小扫描范围,提高效率。
- 重点:记住HashMap集合初始化容量必须是2的倍数,也是官方推荐的,这是因为达到散列均匀,为了提高HashMap集合的存取效率,所必须的。
- 因为两个对象相等,哈希值一定相等,所以equals方法重写时,hashCode方法也必须重写,并且equals方法返回如果是true,hashCode方法返回值必须一样
- 以下是关于hashcode的一些规定:
- 两个对象相等,hashcode一定相等
- 两个对象不等,hashcode不一定不等
- hashcode相等,两个对象不一定相等
- hashcode不等,两个对象一定不等
- 对于哈希表数据结构来说:
- 如果o1和o2的hash值相同,一定放到同一个单链表上,
- 当然如果o1和o1的hash值不同,但由于哈希算法执行结束之后转换的数组下标可能相同,此时会发生“哈希碰撞”
- HashMap和Hashtable的区别:
- HashMap的key和value都可以为null,默认初始化容量是16,默认加载因子是0.75,扩容之后的容量时原容量的2倍,,HashSet的容量和扩容也一样
- Hashtable的key和value都不能为null,默认初始化容量是11,默认加载因子是0.75,扩容之后的容量时原容量的2倍+1
- TreeSet和TreeMap:
- TreeSet集合底层实际上是一个TreeMap
- TreeMap底层是一个二叉树
- 放到TreeSet集合中的元素,等同于放到了TreeMap集合的key部分
- TreeSet集合中的元素,无序、不可重复,但是可以按照元素的大小顺序排序,称为可排序集合
动力节点——day08的更多相关文章
- 分布式技术EJB3_分库架构 - 【动力节点官网】北京Java …
分布式技术EJB3_分库架构 - [动力节点官网]北京Java … http://www.bjpowernode.com/xiazai/2220.html <程序天下--EJB JPA数据库持久 ...
- 001_动力节点_SpringMVC4_SpringMVC简介
1.视频的下载地址是 下载地址:百度云盘 链接:http://pan.baidu.com/s/1ge58XW3 密码:yd5jhttp://www.java1234.com/a/javaziliao/ ...
- 动力节点Java培训告诉你Java线程的多功能用法
现在的java开发可谓是八仙过海各显神通啊!遥想当下各种编程语言萎靡不振,而我Java开发异军突起,以狂风扫落叶之态,作为Java培训行业的黄埔军校,为了守护Java之未来,特意总结了一些不被人所熟知 ...
- [Java语言] 《struts2和spring MVC》的区别_动力节点
1.Struts2是类级别的拦截, 一个类对应一个request上下文,SpringMVC是方法级别的拦截,一个方法对应一个request上下文,而方法同时又跟一个url对应,所以说从架构本身上Spr ...
- 动力节点 mysql 郭鑫 34道经典的面试题三
1.第十五题 15.列出受雇日期早于其直接上级的所有员工编号.姓名.部门名称 思路一:第一步将emp a看成员工表,将emp b 看成领导表,员工表的mgr字段应该等于领导表的主键字段 mysql&g ...
- 动力节点 mysql 郭鑫 34道经典的面试题二
13.有3个表S(学生表),C(课程表),SC(学生选课表) S(SNO,SNAME)代表(学号,姓名) C(CNO,CNAME,CTEACHER)代表(课号,课名,教师) SC(SNO,CNO,SC ...
- 动力节点 mysql 郭鑫 34道经典的面试题
DROP TABLE IF EXISTS `dept`; CREATE TABLE `dept` ( `DEPTNO` int(2) NOT NULL COMMENT '部门编号', `DNAME` ...
- 动力节点——day07
什么是异常? 异常是指在程序的运行过程中所发生的不正常的事件,它会中断正在运行的程序 Java中异常的存在形式? 异常在java中以类的形式存在,每一个异常类都可以创建异常对象 异常的继承结构图 编译 ...
- 动力节点—day06
常用类 String String表示字符串类型,属于引用数据类型,不属于基本数据类型 在Java中随便使用双引号括起来的都是String对象,例如"abc"."def& ...
随机推荐
- 4.pygame快速入门-事件监听
事件event:游戏启动后,用户针对游戏的所有操作 监听:在游戏循环中,判断用户的具体操作 pygame中通过pygame.event.get()可以获得当前用户所做动作的事件列表 事件监听 wh ...
- CSS 渐变锯齿消失术
在 CSS 中,渐变(Gradient)可谓是最为强大的一个属性之一. 但是,经常有同学在使用渐变的过程中会遇到渐变图形产生的锯齿问题. 何为渐变锯齿? 那么,什么是渐变图形产生的锯齿呢? 简单的一个 ...
- 沁恒CH32V003F4P6 开发板上手报告和Win10环境配置
CH32V003 沁恒最近推出的低价CH32V003系列, 基于青稞RISC-V2A内核, 48MHz主频, 2KB SRAM, 16KB Flash, 工作电压兼容3.3V和5V. 主要参数如下 S ...
- Python 学习思路 思维导图 Xmind
如果需要,请在评论区留下邮箱,我看到后会一次发送.
- SpringCloud——Eureka Feign Ribbon Hystrix Zuul等关键组件的学习与记录
SpringCloud--Eureka Feign Ribbon Hystrix Zuul等关键组件的学习与记录 前言:本篇是对近日学习狂神SpringCloud教程之后的感想和总结,鉴于对Sprin ...
- hashcat 命令
hashcat --force --stdout -a 6 tmp.txt ?d?d?d?d?d?d?d > result.txt tips:将tmp.txt字典中的内容与7位随机掩码字符组合, ...
- 为什么Linux需要虚拟内存 [转载好文]
操作系统中的 CPU 和主内存(Main memory)都是稀缺资源,所有运行在当前操作系统的进程会共享系统中的 CPU 和内存资源,操作系统会使用 CPU 调度器分配 CPU 时间1并引入虚拟内存系 ...
- pyinstaller打包TVM/RPC相关脚本及DSO文件
0. 创建anaconda env numpy中MKL/BLAS库占用很大空间.使用如下命令创建新环境,并替换numpy. conda create -n extranumpy python=3.8. ...
- JavaEE Day02MySQL
今日内容 数据库的基本概念 MySQL数据库软件 安装 卸载 配置 SQL语句 一.数据库的基本概念 1.数据库DataBase,简称DB 2.什么是数据库? 用于存储和管理数据的仓库 ...
- python 中文分词工具
python 中文分词工具 jieba,https://github.com/fxsjy/jieba jieba_fast,https://github.com/deepcs233/jieba_fas ...