MySQL 中一条 sql 的执行过程
一条 SQL 的执行过程
前言
在开始学习 MySQL 中知识点的时候,首先来看下 SQL 在 MySQL 中的执行过程。
查询
查询语句是我们经常用到的,那么一个简单的查询 sql,在 MySQL 中的执行过程是怎么样的呢?
SELECT * FROM user WHERE id =1
栗如上面的这个简单的查询语句,来看下具体的查询逻辑。
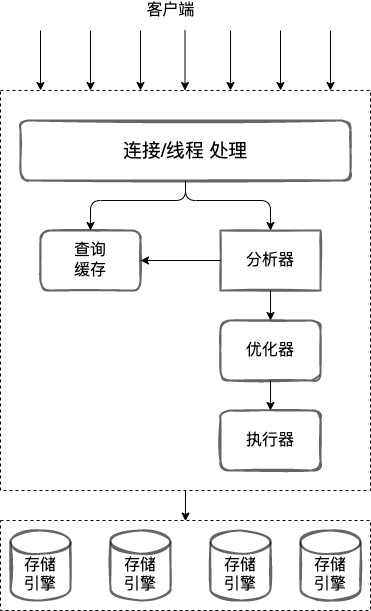
MySQL 主要分为 Server 层和存储引擎层两部分。
Server 层包括连接器、查询缓存。分析器、执行器等。MySQL 中大多数的核心功能,所有的内置函数,所有跨存储引擎的功能都在这一层实现。栗如:存储过程,触发器,视图等。。。
存储引擎层负责数据的存储和提取。其架构是插件式的,支持 InnoDB、MyISAM、Memory 等多个存储引擎。MySQL 5.5.5 InnoDB 成为了默认的存储引擎。
连接器
大多数基于网络的客户端/服务器的工具或者服务都有类似的架构。
这里主要的工作就是管理和客户端的连接,同时进行连接的权限认证。
如果用户名密码不对,就会有一个 "Access denied for user" 的错误提示。
如果用户名密码认证通过,连接器中会在权限表中查询改账号拥有的权限,之后所有的权限判断逻辑,都依赖于此时读到的权限。
这就意味着,一旦一个用户建立连接后,即使对这个账号进行了权限的修改,对已经建立的连接也不会产生影响。只有新建连接,才能使用新的权限。
客户端如何太长时间没有动静,连接器会断开连接,这个时间由参数 wait_timeout 控制默认 8 小时。
数据库的连接分成两种类型短连接和短链接:
长连接:长连接在连接成功之后,后面客户端的请求,可以复用这个连接;
短连接:短连接每次执行完几次查询就断开连接,每次客户端的请求都会新建一个。
因为建立连接的过程是很复杂,并且是有一定开销的,应该尽量减少连接的建立,长连接更加推荐使用。
为了避免线程被频繁的创建和销毁,影响性能,MySQL5.5 版本引入了线程池,会缓存创建的线程,不需要为每一个新建的连接,创建或销毁线程。可以使用线程池中少量的线程服务大量的连接。
查询缓存
MySQL 查询缓存,为了提高相同 Query 语句的响应速度,会缓存特定 Query 的整个结果集信息,当后面有相同的查询语句,直接查询缓存,返回查询的结果。当命中的时候不需要执行后面复杂的操作,就可以直接返回结果,查询效率是很高的。
不过当一个表有更新的时候,和这个表有关的查询缓存都会被删除,造成查询缓存的失效。所以更新较频繁的数据库不建议使用查询缓存,命中率会非常的低。所以,长时间不更新的静态表,这种适合使用查询缓存。
在 MySQL 5.6 开始,就已经默认禁用查询缓存了。在 MySQL 8.0,就已经删除查询缓存功能了。
分析器
当 SQL 需要执行时候,首先分析器会做一个词法分析和语法分析,一条 SQL 语句由字符串和空格组成,MySQL 需要识别出里面的字符串分别是什么,代表什么。根据词法分析的结果,语法分析器会根据语法规则,判断你输入的这个SQL语句是否满足MySQL语法。
优化器
优化执行:利用数据库的统计信息决定 SQL 语句的最佳执行方式,选择合适的索引,找出最优的查询方案,
优化器是在表里面有多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联(join)的时候,决定各个表的连接顺序。
执行器
开始执行的时候,要先判断一下你对这个表T有没有执行查询的权限,如果没有,就会返回没有权限的错误。
有权限,会根据优化后的 SQL,向存储引擎发起查询操作,并且返回查询的结果。
执行与优化
总体来说就是
MySQL 会解析查询,并创建内部的数据结构(解析树),然后对其进行各种优化,包括重写查询,决定表的读取顺序,以及选择合适的索引。
数据更新
在了解数据的更新,需要先来了解下,MySQL 中几种常用的日志。
日志模块
先来看下 InnoDB 中的存储
InnoDB 存储引擎是基于磁盘存储的,并将其中的记录按照页的方式进行管理。因此可以将其视为基于磁盘的数据库系统,由于 CPU 速度与磁盘速度之间的鸿沟,基于
磁盘的数据库系统通常使用缓存池技术来提供数据库整体性能。
缓存池简单来说就是一块内存区域,通过内存速度来弥补磁盘速度较慢对数据库性能的影响。
数据库读取页的操作,会将从磁盘读出的页存放到缓存池中,下次读相同的页就可以在缓存池中查询了,查询不到还是会从磁盘中读取。
数据库中页的修改操作,首先修改缓存池中的页,然后一定频率刷新到新的磁盘上。页从缓存池中刷新到磁盘中的操作并不是在每次页发生更新时触发,而是通过一种称为 Checkpoint 的机制刷新回磁盘。
如果每一个页发生变化,就将新页的版本刷新到磁盘,那么这个开销是很大的,如果数据都集中在某几个页,那么数据库的性能将变的很差。
同时,如果在从缓存中将页的新版本刷新到磁盘时发生了宕机,那么数据就不能恢复了,为了避免发生数据丢失的问题,当前事务数据系统都采用了 Write Ahead Log 策略,当事务提交的时候,先写重做日志,再修改页。通过重做日志来处理宕机时候的数据丢失问题。
redo log (重做日志)
InnoDB 中的重做日志,由两部分组成,redo log 和 undo log。
redo log用来从保证事务的持久性;undo log用来实现事务回滚以及 MVCC 的功能。
redo log 简单点讲就是 MySQL 异常宕机后,将没来得及提交的事物数据重做出来。
redo log 包括两部分:一个是内存中的日志缓冲( redo log buffer ),另一个是磁盘上的日志文件( redo log file )。
MySQL 每执行一条 DML 语句,先将记录写入 redo log buffer,后续某个时间点再一次性将多个操作记录写到 redo log file 。这种 先写日志,再写磁盘 的技术就是 MySQL 里经常说到的 WAL(Write-Ahead Logging) 技术。
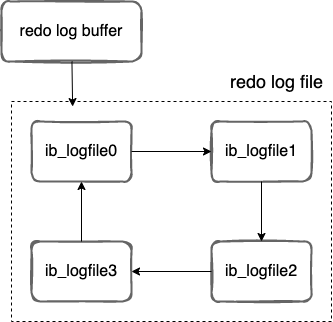
MySQL 支持三种将 redo log buffer 写入 redo log file 的时机,可以通过 innodb_flush_log_at_trx_commit 参数配置,各参数值含义如下:
| 参数值 | 含义 |
|---|---|
| 0(延迟写) | 事务提交时不会将 redo log buffer 中日志写入到 os buffer ,而是每秒写入 os buffer 并调用 fsync() 写入到 redo log file 中。也就是说设置为0时是(大约)每秒刷新写入到磁盘中的,当系统崩溃,会丢失1秒钟的数据。 |
| 1(实时写,实时刷) | 事务每次提交都会将 redo log buffer 中的日志写入 os buffer 并调用 fsync() 刷到 redo log file 中。这种方式即使系统崩溃也不会丢失任何数据,但是因为每次提交都写入磁盘,IO的性能较差。 |
| 2(实时写,延迟刷) | 2(实时写,延迟刷) 每次提交都仅写入到 os buffer ,然后是每秒调用 fsync() 将 os buffer 中的日志写入到 redo log file 。 |
参数 innodb_flush_log_at_trx_commit 建议设置成 1 ,这样可以保证MySQL异常重启之后数据不丢失。
redo log 的日志文件会一直追加吗?
InnoDB 中的 redo log 是固定大小的,比如可以配置为一组 4 个文件,每个文件的大小为 1GB 那么 redo log 中就可以记录 4GB 的数据操作。redo log 中日志的写入是循环写入的,当写到结尾时,会回到开头循环写日志。
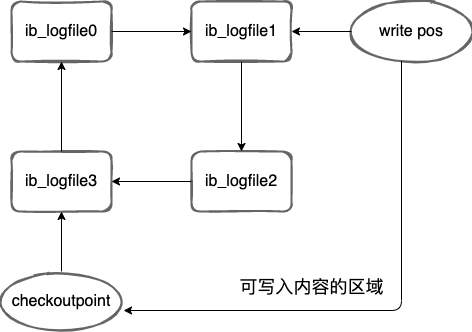
write pos 表示当前记录的位置,一边写一边后移,checkpoint 表示当前要擦除的位置,checkpoint 之前的页被会刷新到磁盘中。
write pos 和 checkpoint 之间的区域就是还能写入到 redo log 中的日志文件。
有了 redo log,InnoDB 就可以保证即使数据库发生异常重启,之前提交的记录都不会丢失,这个能力称为 crash-safe。
binlog (归档日志)
binlog 记录了 MySQL 数据执行更改的所有操作,以二进制的形式保存在磁盘中,binlog 是 MySQL 中的逻辑日志,由 server 层进行记录,使用任何引擎的 MySQL 都会记录 binlog 日志。
binlog 是通过追加的方式进行写入的,可以通过 max_binlog_size 参数设置每个 binlog 文件的大小,当文件大小达到给定值之后,会生成新的文件来保存日志。
使用场景
binlog 主要有下面几种作用:
主从复制:在主从复制中,从库利用主库上的binlog进行重播,实现主从同步;
数据恢复:用户数据库基于时间点的数据还原;
审计:用户通过二进制日志中的信息来进行审计,判断是否有对数据库进行注入的攻击。
binlog 刷盘时机
在默认情况下,二进制文件并不是每次写的时候同步到磁盘,因此当数据库所在的操作系统宕机的时候,可能会存在一部分数据没有写入到二进制文件中。
具体的刷盘时机可以通过 sync_binlog 参数来控制
| 参数值 | 含义 |
|---|---|
| 0 | 不去强制要求,由系统自行判断何时写入到磁盘中 |
| 1 | 每次 commit 的时候都要将 binlog 写入磁盘 |
| N | 每N个事务,才会将 binlog 写入磁盘 |
在 MySQL 5.7.7 之后的版本 sync_binlog 的默认值都是1。
undo log (回滚日志)
是 InnoDB 存储引擎层生成的日志,实现了事务中的原子性,主要用于事务回滚和 MVCC。
在对数据库进行修改的时候,就会记录 undo log ,这样当事务执行失败的时候,就能使用这些 undo log 恢复到修改之前的样子。
不过需要注意的是 undo log 记录的是逻辑日志,只是将数据库逻辑的恢复到之前的样子,所有的修改逻辑都被取消了,但是数据结构和页本身在回滚之后可能会不一样。听起来有点难理解,下面举个栗子分析下。
比如用户执行了一个 INSERT 10W 条记录的事务,这个事务会导致分配一个新的段,表空间会增大。事务执行失败,回滚的时候,只是将插入的数据进行了回滚,表的空间大小并不会进行收缩。所以说,undo log 记录的是逻辑日志,只是将数据库逻辑的恢复到之前的样子。
InnoDB 通过 undo log 进行事务的回滚,实际上做的是和之前相反的工作,对于每个 INSERT ,InnoDB 会生成一个 DELETE ;对于 DELETE 操作,InnoDB 会生成一个 INSERT。。。通过反向的操作来实现事务数据的回滚操作。
除了回滚操作,还有一个作用就是 MVCC,InnoDB 中对 MVCC 的实现需要借助于 undo log。
InnoDB 通过 undo log 保存每条数据的多个版本,并且能够找回数据历史版本提供给用户读,每个事务读到的数据版本可能是不一样的。
当用户读取一行记录的时候,若该记录已经被其他的事务占用,当前事务可以从 undo log 中读取之前的行版本信息,以此实现非锁定读取。
两阶段提交
这里来看下一条 Update 语句的执行过程
UPDATE user SET username = '小张-001' WHERE id = 2;
1、执行器先找引擎取 id = 2 这一行;
如果
id = 2这一行的数据页、本来就在buffer pool中,就直接返回给执行器更新;如果记录不在
buffer pool中,将数据从磁盘读入到buffer pool,返回记录给执行器。
2、执行器得到数据之后吗,首先看下更新前的记录和更新后的记录时候一样;
如果一样,不执行后面的更新流程;
如果不一样,就把更新前的数据和更新后的数据都传给 InnoDB 引擎,让 InnoDB 来执行更新操作;
3、引擎将数据更新到内存中,同时将更新操作记录到 redo log 中,此时的 redo log 处于 prepare 状态,然后告知执行器执行完成了,随时可以提交事务;
4、执行器生成这个操作的 binlog,并把 binlog 写入到磁盘中;
5、执行器调用引擎的提交事务接口,引擎把刚刚写入的 redo log 改成提交(commit)状态,更新完成。

其中在写 binlog 和 redo log 的过程中,为了保证两个文件写入的原子性,这里使用了内部 XA 事务的两阶段提交。
Prepare 阶段:
将(内部事务的id) xid 写入到 redo log 中,InnoDB 将事务状态设置为 prepare 状态,将 redolog 写文件并刷盘;
Commit 阶段:
将 xid 写入到 binlog, binlog 写入文件,binlog 刷盘,然后 InnoDB 提交事务。
两阶段提交保证了事务在多个引擎和 binlog 之间的原子性,binlog 承担内部 XA 事务的协调者,以 binlog 写入成功作为事务提交的标志。
在崩溃恢复中,是以 binlog 中的 xid 和 redo log 中的 xid 进行比较,xid 在 binlog 里存在则提交,不存在则回滚。我们来看崩溃恢复时具体的情况:
在 prepare 阶段崩溃,即已经写入 redolog,在写入 binlog 之前崩溃,则会回滚;
在 commit 阶段,当没有成功写入 binlog 时崩溃,也会回滚;
如果已经写入 binlog,在写入 InnoDB commit 标志时崩溃,则重新写入 commit 标志,完成提交。
为什么需要两阶段提交
如果不使用"两阶段提交",数据库的状态就有可能和它的日志回复出来的库的状态不一致。
不使用"两阶段提交" binlog 和 redo log 先后写,在实际的情况都会出现其中一个写不成功的情况
如果 redo log 没有写成功,那么主库中在宕机之后,通过 redo log 实现事务的一致性,就会损失宕机时候没有写成功的几条数据,而从库通过 binlog 进行同步,数据是没有丢失的,这样和主库就出现了数据不一致的情况。
如果 binlog 没有写成功,这样就更容易理解了,从库通过 binlog 进行同步,就会丢失数据库宕机时候丢失的数据,和主库的主句就不一致了。
所以 binlog 和 redo log 出现半成功的情况,就有可能出现主从环境数据不一致的情况。
逻辑日志和物理日志
逻辑日志:可以简单理解为记录的就是sql语句。
物理日志:因为 MySQL 数据最终是保存在数据页中的,物理日志记录的就是数据页变更。
参考
【高性能MySQL(第3版)】https://book.douban.com/subject/23008813/
【MySQL 实战 45 讲】https://time.geekbang.org/column/100020801
【MySQL技术内幕】https://book.douban.com/subject/24708143/
【MySQL · 源码分析 · 内部 XA 和组提交】http://mysql.taobao.org/monthly/2020/05/07/
【MySQL学习笔记】https://github.com/boilingfrog/Go-POINT/tree/master/mysql
MySQL 中一条 sql 的执行过程的更多相关文章
- Oracle是如何工作的?实例是如何响应用户请求?一条SQL的执行过程~
Oracle 是如何工作的? Select id,name from t order by id ; – SQL 解析(查看语法是否错误,如果没有错误,分析语意,执行此语句的权限) – 执行计划(OR ...
- MySQL中一条SQL的加锁分析
MySQL中一条SQL的加锁分析 id主键 + RC id唯一索引 + RC id非唯一索引 + RC id无索引 + RC id主键 + RR id唯一索引 + RR id非唯一索引 + RR id ...
- 一条 sql 的执行过程详解
写操作执行过程 如果这条sql是写操作(insert.update.delete),那么大致的过程如下,其中引擎层是属于 InnoDB 存储引擎的,因为InnoDB 是默认的存储引擎,也是主流的,所以 ...
- 一条Sql的执行过程
一条sql内部是如何执行的: 学习MySQL实战45专栏 sql中的内部执行图: 可以分为两部分:server和存储引擎 server层包含: 连接器.分析器.优化器.执行器,涵盖了MySQL大多数核 ...
- 【原创】3. MYSQL++ Query类型与SQL语句执行过程(非template与SSQLS版本)
我们可以通过使用mysqlpp:: Query来进行SQL语句的增删改查. 首先来看一下mysqlpp::Query的一些最简单的调用, conn.connect(mysqlpp::examples: ...
- MySql 学习之 一条更新sql的执行过程
上一篇文章咱们说了一条查询sql的执行过程.如果没有看过上一篇文章的可以去看下上一篇文章,今天咱们说说一条更新sql的执行过程. 上面一条sql是将id为1的分数加上10. 那么它的执行流程是怎样的呢 ...
- MySql 学习之 一条查询sql的执行过程
相信大家都接触过Mysql数据库,而且也肯定都会写sql.我不知道大家有没有这样的感受,反正我是有过这样的想法.就是当我把一条sql语句写完了,并且执行完得到想要的结果.这时我就在想为什么我写这样的一 ...
- mysql体系结构和sql查询执行过程简析
一: mysql体系结构 1)Connectors 不同语言与 SQL 的交互 2)Management Serveices & Utilities 系统管理和控制工具 备份和恢复的安全性,复 ...
- 转:Oracle中SQL语句执行过程中
Oracle中SQL语句执行过程中,Oracle内部解析原理如下: 1.当一用户第一次提交一个SQL表达式时,Oracle会将这SQL进行Hard parse,这过程有点像程序编译,检查语法.表名.字 ...
- 一条SQL语句执行得很慢的原因有哪些?| MySQL高性能优化规范建议
一条SQL语句执行得很慢的原因有哪些 https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485185&idx=1&am ...
随机推荐
- k8s之pod连接被拒排查
k8s之pod连接被拒排查 pod链接被拒 查看pod的时候发现pod的状态为crashloopbackoff 然后看看日志发现报错如下 kubectl -n kf10 logs easydata-r ...
- jQuery+bootstrap实现有省略号的数据分页
1.前言 在前端通过ajax请求数据后,可以通过bootstrap实现分页.由于bootstrap只提供分页的按钮的样式.数据分页我们需要实现页码跳转,上一页下一页,数据过多显示省略号,点击省略号能快 ...
- 使用GitHub Actions实现自动化部署
前言 大家在工作中想必都是通过自动化部署来进行前端项目的部署的,也就是我们在开发完某个需求时,我们只需要将代码推送到某个分支,然后就能自动完成部署,我们一般不用关心项目是如何build以及如何depl ...
- 如何在CentOS7上搭建自己的GitLab仓库
序言 各位好啊,我是会编程的蜗牛,作为java开发者,在团队开发中,一般都是需要使用git及git仓库来管理我们的代码的,这非常方便.我以前在小公司的时候,基本都是一个人开发一个项目,所以也没有怎么接 ...
- 关于li标签的相关css属性
1.让li前面的序号变成空心圆 list-style-type: circle; 2.让li前面的序号在div里面 list-style-position: inside; 3.改变li前面的 ...
- natapp内网穿透
NATAPP 官网地址 https://natapp.cn/ 下载 点击下载,选择符合自己的版本 注册 下载完成后解压是个natapp.exe程序,这里先不用动,回到官网首页 完成注册并登录,选择免费 ...
- go语言单元测试:go语言用gomonkey为测试函数或方法打桩
一,安装用到的库1,gomonkey代码的地址: https://github.com/agiledragon/gomonkey 2,从命令行安装gomonkey go get -u github.c ...
- 【Java并发006】使用层面:Lock锁机制全解析
一.前言 二.synchronized局限性 + Lock锁机制的引入 2.1 synchronized局限性 第一,使用synchronized,其他线程只能等待直到持有锁的线程执行完释放锁(syn ...
- 在 Spring 生态中玩转 RocketMQ
本文作者:饶子昊 - Spring Cloud Alibaba Committer,阿里云智能开发工程师. 01 Spring 生态介绍 根据 JVM EcoSystem Report 2021 最新 ...
- 解决win7设置默认程序打开方式失效
问题描述 我在设置一个文件(.ui)的默认程序打开,总是失效.设置不成功. 原因 正常这个程序应该用 designer.exe 打开,但是我之前设置过(.ui)默认程序打开程序为designer.ex ...