迁移学习(MixMatch)《MixMatch: A Holistic Approach to Semi-Supervised Learning》
论文信息
论文标题:MixMatch: A Holistic Approach to Semi-Supervised Learning
论文作者:David Berthelot, Nicholas Carlini, Ian Goodfellow, Nicolas Papernot, Avital Oliver, Colin Raffel
论文来源:NeurIPS 2019
论文地址:download
论文代码:download
引用次数:1898
1 Introduction
半监督学习[6](SSL)试图通过允许模型利用未标记数据,减轻对标记数据的需求。最近的半监督学习方法在未标记的数据上增加一个损失项,鼓励模型推广到不可见的数据。该损失项大致可分:
- 熵最小化(entropy minimization)[18,28]——鼓励模型对未标记数据产生高质信度的预测;
- 一致性正则化(consistency regularization)——鼓励模型在输入受到扰动时产生相同的输出分布;
- 通用正则化(generic regularization)——鼓励模型很好地泛化,避免过拟合;
2 Related Work
2.1 Consistency Regularization
监督学习中一种常见的正则化技术是数据增强,它被假定为使类语义不受影响的输入转换。例如,在图像分类中,通常会对输入图像进行变形或添加噪声,这在不改变其标签的情况下改变图像的像素内容。即:通过生成一个接近的、无限新的、修改过的数据流来人为地扩大训练集的大小。
一致性正则化将数据增强用于半监督学习,基于利用一个分类器应该对一个未标记的例子输出相同的类分布的想法。正式地说,一致性正则化强制执行一个未标记的样本 $x$ 应与 $\text{Augment(x)}$ 分类相同。
在最简单的情况下,对于未标记的样本 $x$,先前工作[25,40]添加如下损失项:
$\| \mathrm{p}_{\text {model }}(y \mid \operatorname{Augment}(x) ; \theta)-\mathrm{p}_{\text {model }}(y \mid \text { Augment }(x) ; \theta) \|_{2}^{2}\quad\quad(1)$
注意,$\text{Augment(x)}$ 是一个随机变换,所以 $\text{Eq.1}$ 中的两项 $\text{Augment(x)}$ 是不完全相同的。
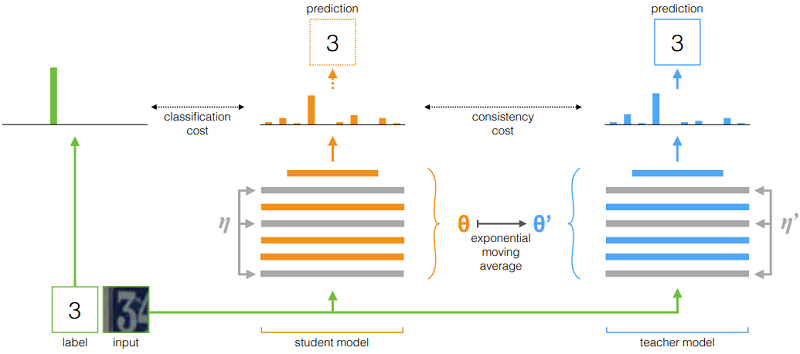
类似的操作 [44](基于模型参数扰动):
$\begin{array}{l} J(\theta)=\mathbb{E}_{x, \eta^{\prime}, \eta}\left[\left\|f\left(x, \theta^{\prime}, \eta^{\prime}\right)-f(x, \theta, \eta)\right\|^{2}\right]\\\theta_{t}^{\prime}=\alpha \theta_{t-1}^{\prime}+(1-\alpha) \theta_{t}\end{array}$
图示:
2.2 Entropy Minimization
许多半监督学习方法中,一个基本假设是:分类器的决策边界不应该通过边缘数据分布的高密度区域。实现的一种方法是要求分类器对未标记的数据输出低熵预测,[18]中其损失项使未标记数据 $x$ 的 $\operatorname{p}_{\text {model}}(y \mid x ; \theta)$ 的熵最小化。$\text{MixMatch}$ 通过对未标记数据的分布使用 $\text{sharpening}$ 函数,隐式地实现了熵的最小化。
2.3 Traditional Regularization
正则化是指对模型施加约束的一般方法,希望使其更好地推广到不可见的数据[19]。本文使用权值衰减来惩罚模型参数[30,46]的 $\text{L2}$范数。本文还在 $\text{MixMatch}$ 中使用 $\text{MixUp}$ [47]来鼓励样本之间的凸行为。
3 MixMatch
给定一批具有 $\text{one-hot}$ 标签的样本集 $\mathcal{X}$ 和一个同等大小的未标记的样本集 $U$,$\text{MixMatch}$ 生成一批经过处理的增强标记样本 $\mathcal{X}^{\prime}$ 和一批带“猜测”标签的增强未标记样本 $\mathcal{U}^{\prime}$,然后使用 $\mathcal{U}^{\prime}$ 和 $\mathcal{X}^{\prime}$ 计算损失项:
$\begin{array}{l}\mathcal{X}^{\prime}, \mathcal{U}^{\prime} & =&\operatorname{MixMatch}(\mathcal{X}, \mathcal{U}, T, K, \alpha) \quad \quad \quad\quad\quad(2)\\\mathcal{L}_{\mathcal{X}} & =&\frac{1}{\left|\mathcal{X}^{\prime}\right|} \sum\limits_{x, p \in \mathcal{X}^{\prime}} \mathrm{H}\left(p, \text { p }_{\text {model }}(y \mid x ; \theta)\right) \quad \quad\quad(3)\\\mathcal{L}_{\mathcal{U}} & =&\frac{1}{L\left|\mathcal{U}^{\prime}\right|} \sum\limits _{u, q \in \mathcal{U}^{\prime}}\|q-\operatorname{p}_{\text{model}}(y \mid u ; \theta)\|_{2}^{2} \quad \quad(4) \\\mathcal{L} & =&\mathcal{L}_{\mathcal{X}}+\lambda_{\mathcal{U}} \mathcal{L}_{\mathcal{U}} \quad \quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad(5)\end{array}$
其中,$\text{H(p, q)}$ 代表着交叉熵损失。
3.1 Data Augmentation
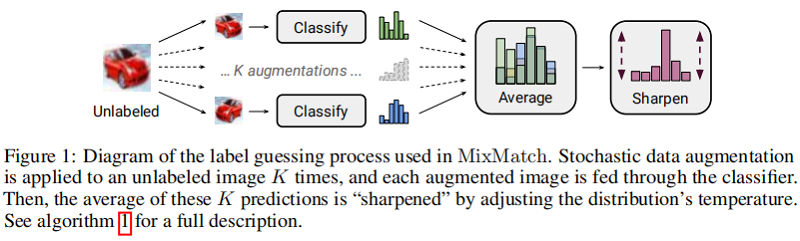
如许多 SSL 方法中的那样,对标记和未标记数据使用数据增强。对于一批带标记数据 $\mathcal{X}$ 中的每个 $x_{b}$ 生成一个数据增强样本 $\hat{x}_{b}=\operatorname{Augment}\left(x_{b}\right)$;对未带标记的数据集 $\mathcal{U}$ 中的样本 $u_{b}$,生成 $K$ 个数据增强样本 $\hat{u}_{b, k}= \operatorname{Augment} \left(u_{b}\right)$,$k \in(1, \ldots, K)$,下文为每个 $u_{b}$ 生成一个“猜测标签” $q_{b}$。
3.2 Label Guessing
对于 $\mathcal{U}$ 中的每个未标记的样本,$\text{MixMatch}$ 使用模型预测为该样本生成一个“猜测标签”,通过计算模型对 $u_b$ 的预测类分布的平均值:
$\bar{q}_{b}=\frac{1}{K} \sum\limits _{k=1}^{K} \operatorname{p}_{\text{model}}\left(y \mid \hat{u}_{b, k} ; \theta\right)\quad\quad(6)$
接着使用 锐化函数($\text{Sharpen}$) 来调整这个分类分布:
$\operatorname{Sharpen}(p, T)_{i}:=p_{i}^{\frac{1}{T}} / \sum\limits _{j=1}^{L} p_{j}^{\frac{1}{T}}\quad\quad(7)$
其中,$p$ 是输入的类分布,此处 $p= \bar{q}_{b}$;$T$ 是超参数,当 $T \rightarrow 0$ 时,$\text{Sharpen(p,T)}$ 的输出接近 $\text{one-hot}$ 形式;
通过改小节内容为无标签样本 $u_{b}$ 产生预测分布,使用较小的 $T$ 会鼓励模型产生较低熵的预测。
3.3 MixUp
对于一个 Batch 中的样本(包括无标签数据和带标签数据),对于任意两个样本 $\left(x_{1}, p_{1}\right)$,$\left(x_{2}, p_{2}\right) $ 计算 $\left(x^{\prime}, p^{\prime}\right)$ :
$\begin{aligned}\lambda & \sim \operatorname{Beta}(\alpha, \alpha)\quad \quad \quad \quad\quad(8)\\\lambda^{\prime} & =\max (\lambda, 1-\lambda)\quad \quad \quad\quad(9)\\x^{\prime} & =\lambda^{\prime} x_{1}+\left(1-\lambda^{\prime}\right) x_{2} \quad\quad(10)\\p^{\prime} & =\lambda^{\prime} p_{1}+\left(1-\lambda^{\prime}\right) p_{2} \quad\quad(11)\end{aligned}$
其中,$\alpha$ 是一个超参数。
鉴于已标记和未标记的样本在同一批中,需要保留该$\text{Batch}$ 的顺序,以适当地计算单个损失分量。通过 $\text{Eq.9}$ 确保 $x^{\prime}$ 更接近 $x_1$ 而不是 $x_2$。为了应用 $\text{MixUp}$,首先收集所有带有标签的增强标记示例和所有带有猜测标签的未标记示例:
$\begin{array}{l}\hat{\mathcal{X}}=\left(\left(\hat{x}_{b}, p_{b}\right) ; b \in(1, \ldots, B)\right) \quad\quad(12) \\\hat{\mathcal{U}}=\left(\left(\hat{u}_{b, k}, q_{b}\right) ; b \in(1, \ldots, B), k \in(1, \ldots, K)\right) \quad\quad(13) \end{array}$
完整算法如下:

4 Experiment
迁移学习(MixMatch)《MixMatch: A Holistic Approach to Semi-Supervised Learning》的更多相关文章
- 迁移学习、fine-tune和局部参数恢复
参考:迁移学习——Fine-tune 一.迁移学习 就是把已训练好的模型参数迁移到新的模型来帮助新模型训练. 模型的训练与预测: 深度学习的模型可以划分为 训练 和 预测 两个阶段. 训练 分为两种策 ...
- 图像识别 | AI在医学上的应用 | 深度学习 | 迁移学习
参考:登上<Cell>封面的AI医疗影像诊断系统:机器之心专访UCSD张康教授 Identifying Medical Diagnoses and Treatable Diseases b ...
- 迁移学习( Transfer Learning )
在传统的机器学习的框架下,学习的任务就是在给定充分训练数据的基础上来学习一个分类模型:然后利用这个学习到的模型来对测试文档进行分类与预测.然而,我们看到机器学习算法在当前的Web挖掘研究中存在着一个关 ...
- 【迁移学习】2010-A Survey on Transfer Learning
资源:http://www.cse.ust.hk/TL/ 简介: 一个例子: 关于照片的情感分析. 源:比如你之前已经搜集了大量N种类型物品的图片进行了大量的人工标记(label),耗费了巨大的人力物 ...
- 迁移学习(Transfer Learning)(转载)
原文地址:http://blog.csdn.net/miscclp/article/details/6339456 在传统的机器学习的框架下,学习的任务就是在给定充分训练数据的基础上来学习一个分类模型 ...
- 迁移学习-Transfer Learning
迁移学习两种类型: ConvNet as fixed feature extractor:利用在大数据集(如ImageNet)上预训练过的ConvNet(如AlexNet,VGGNet),移除最后几层 ...
- [DeeplearningAI笔记]ML strategy_2_3迁移学习/多任务学习
机器学习策略-多任务学习 Learninig from multiple tasks 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.7 迁移学习 Transfer Learninig 神 ...
- Gluon炼丹(Kaggle 120种狗分类,迁移学习加双模型融合)
这是在kaggle上的一个练习比赛,使用的是ImageNet数据集的子集. 注意,mxnet版本要高于0.12.1b2017112. 下载数据集. train.zip test.zip labels ...
- 【深度学习系列】迁移学习Transfer Learning
在前面的文章中,我们通常是拿到一个任务,譬如图像分类.识别等,搜集好数据后就开始直接用模型进行训练,但是现实情况中,由于设备的局限性.时间的紧迫性等导致我们无法从头开始训练,迭代一两百万次来收敛模型, ...
- 迁移学习︱艺术风格转化:Artistic style-transfer+ubuntu14.0+caffe(only CPU)
说起来这门技术大多是秀的成分高于实际,但是呢,其也可以作为图像增强的工具,看到一些比赛拿他作训练集扩充,还是一个比较好的思路.如何在caffe上面实现简单的风格转化呢? 好像网上的博文都没有说清楚,而 ...
随机推荐
- Linux 下搭建 Hadoop 环境
Linux 下搭建 Hadoop 环境 作者:Grey 原文地址: 博客园:Linux 下搭建 Hadoop 环境 CSDN:Linux 下搭建 Hadoop 环境 环境要求 操作系统:CentOS ...
- Sublime Text 修改默认语言为Python
Sublime Text 3 修改默认语言为Python 步骤如下 英文:Tools - Developer - New Plugin 中文:工具 - 插件开发 - 新建插件 清空原来内容,用下面的代 ...
- ajax-Xhr
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Pyside2 开发框架
apps文件夹 tools文件夹 Main.py .ui .json Global.py Main.py 通用 函数及子线程 函数内容
- 最新的ZooKeeper GUI
Zookeeper 是一个分布式的.开源的程序协调服务,是 hadoop 项目下的一个子项目.他提供的主要功 能包括:配置管理.名字服务.分布式锁.集群管理. 平时用zkCli.sh进行管理不免有点不 ...
- 【题解】CF631B Print Check
题面传送门 解决思路: 首先考虑到,一个点最终的情况只有三种可能:不被染色,被行染色,被列染色. 若一个点同时被行.列染色多次,显示出的是最后一次被染色的结果.所以我们可以使用结构体,对每一行.每一列 ...
- day01-Tomcat框架分析
引入课程和Maven 1.Maven maven中央仓库:Maven Repository: Search/Browse/Explore (mvnrepository.com) maven仓库是国外的 ...
- 2022-11-09 Acwing每日一题
本系列所有题目均为Acwing课的内容,发表博客既是为了学习总结,加深自己的印象,同时也是为了以后回过头来看时,不会感叹虚度光阴罢了,因此如果出现错误,欢迎大家能够指出错误,我会认真改正的.同时也希望 ...
- 核磁共振成像学习笔记——从FID信号到K空间
在理想磁场环境下(没有不存在场不均匀性),对于一个没有梯度场的方块. 此时,RF pulse的两路正交信号(相位差为90°)对此方块进行激发,然后收取信号,我们可以得到由此方块产生的FID信号. 设此 ...
- [排序算法] 快速排序 (C++) (含三种写法)
快速排序解释 快速排序 Quick Sort 与归并排序一样,也是典型的分治法的应用. (如果有对 归并排序还不了解的童鞋,可以看看这里哟~ 归并排序) 快速排序的分治模式 1.选取基准值,获取划分位 ...