【论文阅读】CVPR2022: Learning from all vehicles
Column: March 23, 2022 1:08 PM
Last edited time: March 23, 2022 11:13 PM
Sensor/组织: 现leaderboard第一名,RC上总分94分 前无古人后无来者
Status: Reading
Summary: IL; 输出 中间层 map再去学
Type: CVPR
Year: 2022
参考与前言
代码地址:https://github.com/dotchen/LAV
论文地址:
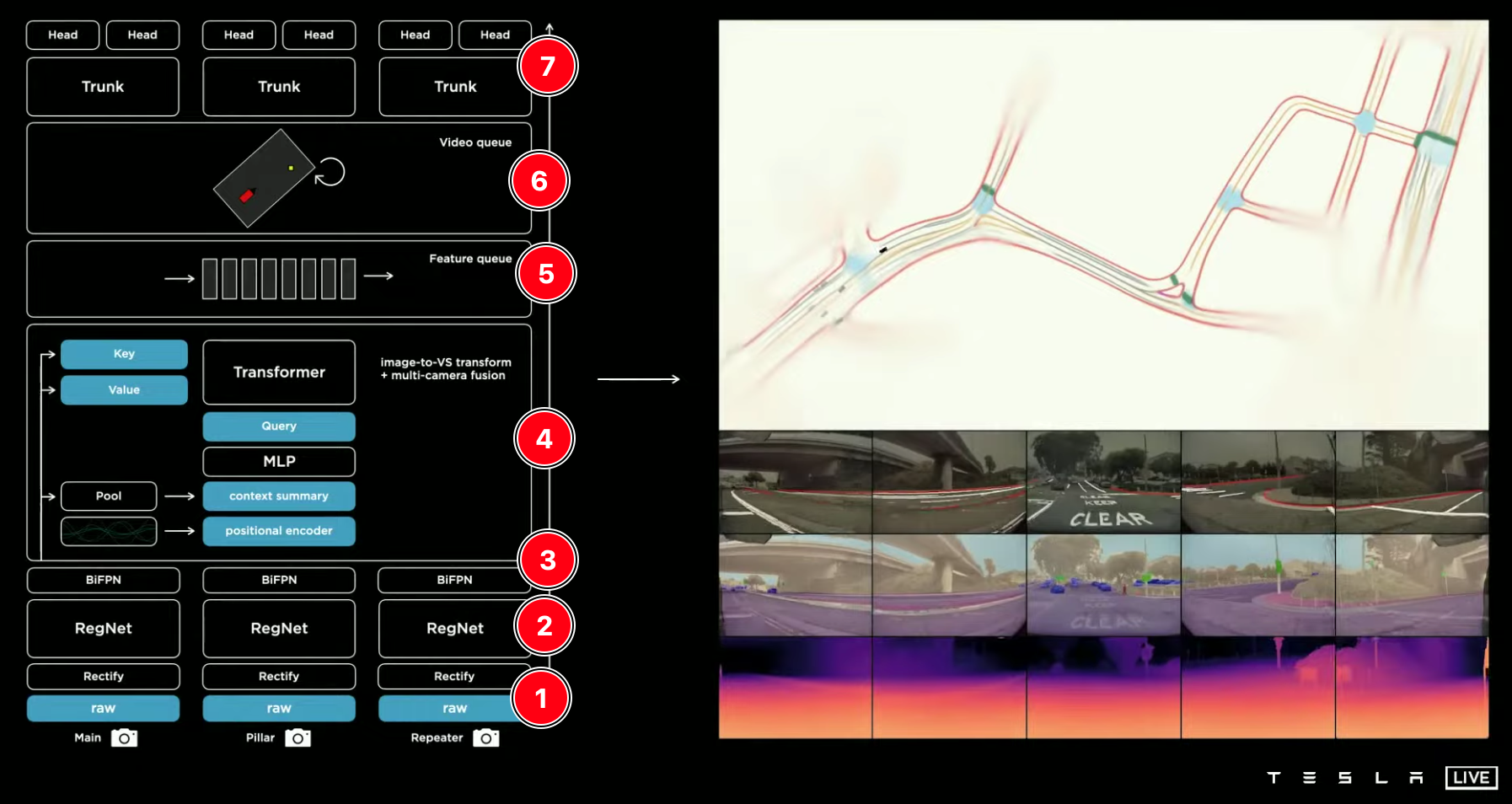
碎碎念: 第一眼看上去真的好像特斯拉AI day介绍的方案,提取相关照片,特斯拉AI day记录后面发吧 b站有中文字幕版

1. Motivation
来源于 carla leaderboard 自动驾驶排行榜,主要任务:就是通过得到的传感器信息来操控车辆的运行,可 端到端学习 也可以 传统方案
问题场景
现实生活中,可能大家开车10000个小时 都不会遇到一次事故,但是我们一定见到过事故现场,由此启发:learning-based 也可以从log中的其他车辆行为学习到经验 (故事能力 max)
学习其他车辆的轨迹(也可以说是预测其他车辆轨迹)有助于我们自车的sample efficiency 而且也可以帮助我们see more interesting scenarios,同时也可以帮助我们避免碰撞
但是问题是:对于其他车辆来说 是不像本身一样有所有传感器数据的,对于我们来说是一种 partial observation 所以需要一种 中间的表达态 来表示周围信息以代替传感器数据,然后所有可观测的车输出这样的数据 到网络中
Contribution
文章里没有总结contribution... 以下为简述方法
LAV 就是用来解决上述问题的,通过对perception and motion的部分观测 设计一个能用于识别、预测和规划的整体框架。(类似于特斯拉AI day介绍的:先进行解耦 multi-task,然后合起来 输出中间的vector map,然后只把vector map输入到规划中去)
主要部分类似于 lbc 里 privileged distillation approach 来解耦 perception 和 action 两个部分,也就是先做感知的模块然后再action
先用 3D detection 和 分割任务学习出 感知模块,输出a viewpoint invariant representation
在这个模块中 并不区分场景中自车和其他车(应该是指viewpoint上有自车信息)
与前一步同时进行的还有motion planner,不同于之前 action的输出,这里仅输出future waypoints 来表示motion plan,整个planner预测周围所有车的轨迹和他们的high-level commands(label形式 后面有详细介绍)
最后把他们合起来成joint framework 然后用privileged distillation来提取出
整个网络最后输出的是一层蒸馏后的用perception module对所有车进行预测输出view point invariant vsion features,然后给到motion prediction module进行轨迹输出
2. Method
整个训练完成后,方法步骤是三层:
- perception 将 sensor data 转为 map-view feature
- 使用perception输出的features,对所有车执行motion planner,输出轨迹和high-level command
- 使用两个PID对自车输出的轨迹进行跟随
2.1 框架
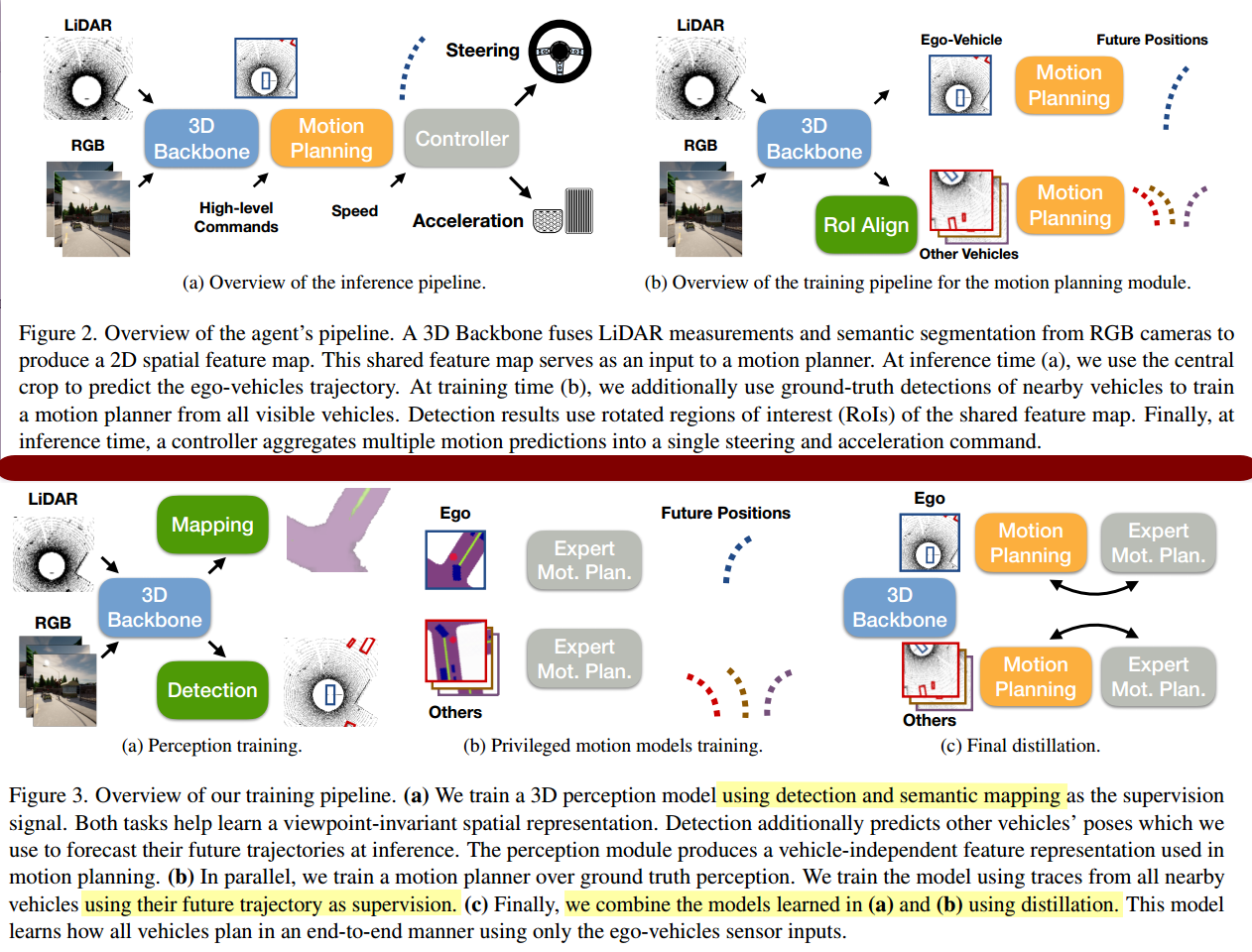
2.2 Perception Model
使用三个相机 合起来,和wor里的操作是一样的,为了获得更广的视角(但是这样红绿灯也会更小不好识别)

照片示意图(右侧为Telephoto 在2.3 c会用到)
\(\mathbf{I}_{t}=\left\{I_{t}^{1}, I_{t}^{2}, I_{t}^{3}\right\}\) 分别代表三个相机,\(L_t\) 代表激光雷达点云,两个的combine方法来自 point-painting [46] 将 RGB 和 a light-weight center-point [47] with pointpillars[27] 处理后的点云进行融合
经过处理后这层框架输出的是map-view feature representation \(f \in \mathbb{R}^{W \times H \times C}\) 其中 W宽,H高,C为通道数
网络框架细节
使用pointpillars with pointpainting进行多模态 3D perception backbone \(P_B\)
使用ERFNet 对每个相机输出的图片进行计算semantic segmentation scores的计算,分割的label包含:背景、车辆、road 道路、lane markings和行人
pointpillars 方面,先用FC-32-32 with batch norm作为point net层,然后对激光雷达点云在:\(x \in [-10m,70m],y\in [-40m,40m]\) 进行create pillars,每个pillars表示 \(0.25m \times 0.25m\)的空间范围,使用默认的2D CNN multi-scale features去获取spatical features \(\phi_{t} \in \mathbb{R}^{192 \times 160 \times 160}\) with 0.5x resolution of the original pillars
其中和pointpillars本身直接使用超参数build dense pillars,本文选择sparesly represent,使用一个spare PointNet去梳理sparese pillar features
对于融合图片分割和点云检测输出BEV feature则是使用简单版的one-stage centerpoint。预测两个centerness maps,一个为车,一个为行人
具体这里的细节估计在后面看代码环节补上把
温馨链接:
[27] pointpillars很不错的一篇 工业界也常用的点云检测框架,博客园不错的解释博客:
2.3 plan motion
首先需要注意的是只有ego car有明确的GNSS的目标点 \(g\in \mathbb R^2\),其他npc没有目标点的,其次 high level command也是只有ego car有,所以其他车辆预测时是需要单独infer的
整个这个motion planner 内部也有两步:
a. 标准的RNN \(M(\hat f,c)\)
预测未来 \(n=10\) 的路径点 waypoints,使用的是:high level commnd \(c\) (包含:左转,右转,直行,跟随,换左道,换右道)
根据前情提要,我们就得分为两个部分loss,然后训练这个网络时 是两部分loss相加:一个ego 有真值的 \(\hat c\),一个其他npc 需要infer的 \(c\)
\]
\]
b. refine RNN \(M'(\hat f, g, \tilde y)\)
在a输出后,使用a输出的 \(\tilde y\) 作为输入,然后结合 map-view feature \(\hat f\) 和 GNSS给出的goal 来为ego car输出相对目标点
\]
这一部分的loss backpropagating 同样也会传回到perception backbone内,所以此时perception model也可以attend to the low-level details
网络框架细节
首先得到了ego car和其他车的detection,然后针对每辆车的位置和yaw角度,截取ROI 感兴趣的区域输入到一个CNN 对于车辆 \(i\) 输出一个embedding \(z^i\),这个\(z^i\) 是在 \(M,M'\)间共享的
- \(M\) 对于每个High-level command 都使用了一个GRU,the GRU rolled out n次去输出连续路径点之间的offset
- \(M'\) 使用了两个种类的recursions和rollouts,针对waypoints的rollouts,针对refinement iterations的rollouts
这里对GRU输出相对位置有点像transfuser NEAT里的那样,看来是预测那边迁移task过来的
问题区:
对于其他车辆的预测轨迹 [对于其他车辆的预测轨迹](https://www.notion.so/CVPR2022-Learning-from-all-vehicles-93f35b3c1f284bb79b8042460b608956),因为这个是实时仿真,难道是时间错开吗?就比如收集到的数据 预测t=1的后10帧时,拿的是后面10帧的实际运行轨迹进行的预测?看文字的意思好像是,可能得瞅瞅数据集和训练代码
we observe their future trajectory to obtain supervision for future waypoints y
其他车辆的high command没看到是怎样推断出来的
原文写的是:We instead allow the model to infer the high-level command directly and optimize the plan for the most fitting high-level command.
然而... 咋fitting出来的呢 emmm 后面看代码把
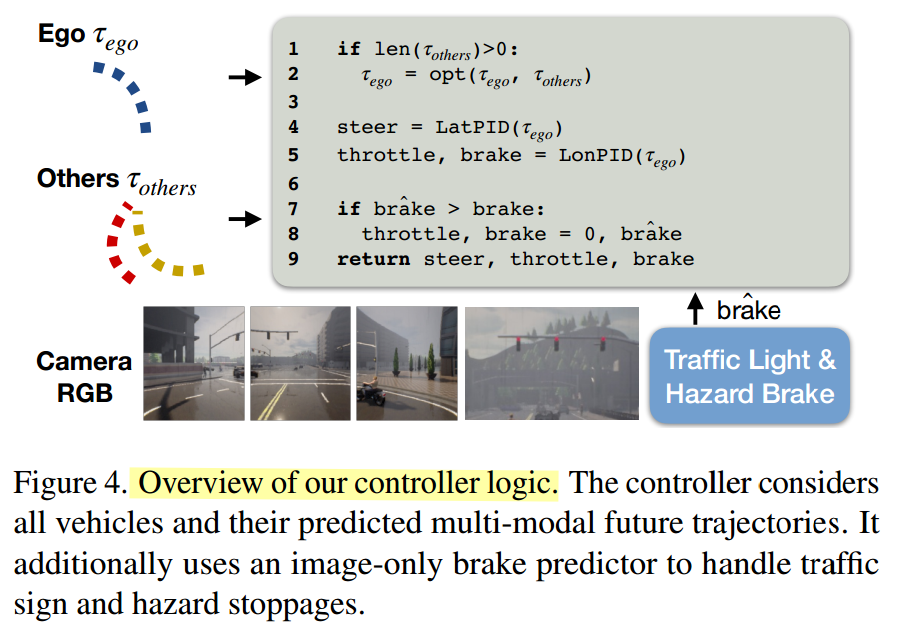
c. controller
当输出了相对目标点,还需要进行一层控制,因为目标点并不能直接给车,CARLA内 车接受的是油门,方向盘和刹车指令。这里作者和其他的transfuser NEAT 之类的用的是一样的 两个PID 控制。有意思的是(和我 前几天和同学讨论的brake最好外加一个network只做brake响应 这样应该能降低事故率)没想到想一块了 简直了 hhhh
也就是虽然PID会根据motion plan的相对坐标输出油门、方向盘,但是这里多加了对刹车的neural network calssifier专门对交通灯和危险场景进行刹停
这个分类器的输入是前面的三个相机外加一个远距相机 类似于前面说面的照片 右边那张,也就说整体系统是四个相机,只是前面用了三个,这里用的四个
网络框架细节
网络使用的是Resnet18输出fixed sized embedding然后concatenate到一起 放入一个线性层去预测binary brake(也就是刹车还是不刹车 二值)
然后对于输出的轨迹 进行一层判断,如下图逻辑,如果该轨迹会导致碰撞就调整一下
总结
所以我们先用3D detection和分割任务学习了perception model,然后plan motion进行轨迹预测再往回传到perception进行loss,最后这两者输出map-view feature带motion plan预测的轨迹,然后用high-level command likelihodd thereshold 来检查是否碰撞
- 这里的检查碰撞没看懂? [这里的检查碰撞没看懂?](https://www.notion.so/CVPR2022-Learning-from-all-vehicles-93f35b3c1f284bb79b8042460b608956)是设了阈值吗?但是细节实现里并没有指出这点?TBD at code
3. 实验部分
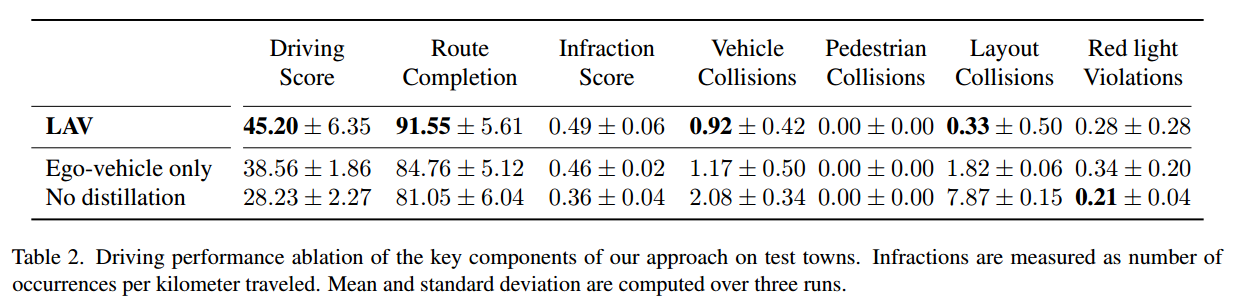
这一部分 看下在线排行榜 RC方面达到了惊人的94分 真的是令人敬佩,做过这个任务的就知道 RC打到80分以上已经算是突破了,然后扣完分也有61分,甩现在的 March 23, 2022 第二名十分了,词穷只能再说一句 牛掰!
这里就贴一下表格,因为我做过这个任务... 所以基本不用看文字 我都知道这些指标是些啥 好坏与否hhh,主要就贴消融实验里的部分了

之所以开头说和特斯拉 AI day说的很像是因为下面这幅效果图 hhh 真的太像了,果然这个作者的效果图都超酷hhh WOR也是

4. Conclusion
没啥好conclusion了,一句话 牛掰,这个作者我着实佩服,按着每年一篇的速度(还基本上是一个人在做)引领 CARLA 这个自动驾驶任务的方向!【从lbc, wor 再到现在的lav】佩服!
就贴一下原文的讨论把,虽然我觉得这已经是到头了 真的是厉害

碎碎念
前段时间赶完论文后,又看了一遍WOR的代码和评估,当时和这个作者在github 交流了好久 发现我竟然没follow,随手一个follow 第二天看的时候发现啊,大佬回follow我了 这就像你偶像关注你一样 hhh 太奇妙了
另外 有意思的是,我做的这个任务的时候 到后面 我一直以为瓶颈在专家数据,LAV这篇丝毫没提这个,而... 代码也没po 他是如何收集数据的,比如transfuser, lbc 和mmfn 都会进行说明数据如果进行收集,不过从开出来的数据集400多G 再瞅瞅我的 100G hhh 知道了 差距,此点的相关issue
代码运行相关,好像代码没po全还有些小问题,
PS 相关包的下载可能会出现的问题,请通过以下命令
conda install pytorch-scatter -c pyg
记得下载 git-lfs
【论文阅读】CVPR2022: Learning from all vehicles的更多相关文章
- 【论文阅读】Learning Dual Convolutional Neural Networks for Low-Level Vision
论文阅读([CVPR2018]Jinshan Pan - Learning Dual Convolutional Neural Networks for Low-Level Vision) 本文针对低 ...
- 论文阅读 DyREP:Learning Representations Over Dynamic Graphs
5 DyREP:Learning Representations Over Dynamic Graphs link:https://scholar.google.com/scholar_url?url ...
- 论文阅读:Learning Visual Question Answering by Bootstrapping Hard Attention
Learning Visual Question Answering by Bootstrapping Hard Attention Google DeepMind ECCV-2018 2018 ...
- 论文阅读: End-to-end Learning of Action Detection from Frame Glimpses in Videos
End-to-End Learning of Action Detection from Frame Glimpses in Videos CVPR 2016 Motivation: 本 ...
- 【论文阅读】Learning Spatial Regularization with Image-level Supervisions for Multi-label Image Classification
转载请注明出处:https://www.cnblogs.com/White-xzx/ 原文地址:https://arxiv.org/abs/1702.05891 Caffe-code:https:// ...
- 论文阅读:Learning Attention-based Embeddings for Relation Prediction in Knowledge Graphs(2019 ACL)
基于Attention的知识图谱关系预测 论文地址 Abstract 关于知识库完成的研究(也称为关系预测)的任务越来越受关注.多项最新研究表明,基于卷积神经网络(CNN)的模型会生成更丰富,更具表达 ...
- Deep Reinforcement Learning for Dialogue Generation 论文阅读
本文来自李纪为博士的论文 Deep Reinforcement Learning for Dialogue Generation. 1,概述 当前在闲聊机器人中的主要技术框架都是seq2seq模型.但 ...
- 论文阅读笔记 Improved Word Representation Learning with Sememes
论文阅读笔记 Improved Word Representation Learning with Sememes 一句话概括本文工作 使用词汇资源--知网--来提升词嵌入的表征能力,并提出了三种基于 ...
- 论文阅读:Face Recognition: From Traditional to Deep Learning Methods 《人脸识别综述:从传统方法到深度学习》
论文阅读:Face Recognition: From Traditional to Deep Learning Methods <人脸识别综述:从传统方法到深度学习> 一.引 ...
随机推荐
- postman中用当前时间戳做请求的入参
用postman做接口测试的,有些接口需要带上当前时间的时间戳作为请求的入参,postman支持这种功能吗? 答案是肯定的. 文中有使用时间戳的两种方法和postman常用的预定义变量. 例子中接口的 ...
- 3U VPX i7 刀片计算机
产品概述 该产品是一款基于第三代Intel i7双核四线程的高性能3U VPX刀片式计算机.产品提供了多个高速PCIe总线接口,其中3个x4 PCIe 3.0接口,1个x4 PCIe 2.0接口.x4 ...
- Solution -「WF2011」「BZOJ #3963」MachineWorks
\(\mathcal{Description}\) Link. 给定你初始拥有的钱数 \(C\) 以及 \(N\) 台机器的属性,第 \(i\) 台有属性 \((d_i,p_i,r_i,g_i ...
- 新手菜菜之2020Kubernetes详细介绍大全
前文 Kubernetes笔记(一):十分钟布置一套K8s环境 介绍了怎么快速建立一个k8s体系.为了持续运用k8s来布置咱们的应用,需要先对k8s中的一些根本组件与概念有个了解. Kubernete ...
- LEETCODE 之写在前面
不知道能坚持多久,甚至不知道能不能坚持下去. 不知道是先看刷题的笔记好 ,还是直接刷题遇到再说好. 不知道是随机刷的好,还是从头向后这样刷好. 反正,勇敢昌兄,不怕困难.
- [旧][Android] LayoutInflater 工作流程
备注 原发表于2016.06.20,资料已过时,仅作备份,谨慎参考 前言 感觉很长时间没写文章了,这个星期因为回家和处理项目问题,还是花了很多时间的.虽然知道很多东西如果只是看一下用一次,很快就会遗忘 ...
- 商业智能BI必备的特性,BI工具介绍
商业智能BI的本质 对企业来说,商业智能BI不能直接产生决策,而是利用BI工具处理后的数据来支持决策.核心是通过构建数据仓库平台,有效整合数据.组织数据,为分析决策提供支持并实现其价值. 传统的DW/ ...
- 【C# TAP 异步编程】四、SynchronizationContext 同步上下文|ExecutionContext
一.同步上下文(SynchronizationContext)概述 由来 多线程程序在.net框架出现之前就已经存在了.这些程序通常需要一个线程将一个工作单元传递给另一个线程.Windows程序以消息 ...
- Hadoop - HDFS学习笔记(详细)
第1章 HDFS概述 hdfs背景意义 hdfs是一个分布式文件系统 使用场景:适合一次写入,多次读出的场景,且不支持文件的修改. 优缺点 高容错性,适合处理大数据(数据PB级别,百万规模文件),可部 ...
- Qt:QTableWidgetItem
0.说明 QTableWidgetItem指明QTableWidget中的一个Item.Item通常包含文本.图标.checkbox. 最常用的构造Item的方式是:不指定该Item所在的TableW ...