go-zero微服务实战系列(七、请求量这么高该如何优化)
前两篇文章我们介绍了缓存使用的各种最佳实践,首先介绍了缓存使用的基本姿势,分别是如何利用go-zero自动生成的缓存和逻辑代码中缓存代码如何写,接着讲解了在面对缓存的穿透、击穿、雪崩等常见问题时的解决方案,最后还重点讲解了如何保证缓存的一致性。因为缓存对于高并发服务来说实在是太重要了,所以这篇文章我们还会继续一起学习下缓存相关的知识。
本地缓存
当我们遇到极端热点数据查询的时候,这个时候就要考虑本地缓存了。热点本地缓存主要部署在应用服务器的代码中,用于阻挡热点查询对于Redis等分布式缓存或者数据库的压力。
在我们的商城中,首页Banner中会放一些广告商品或者推荐商品,这些商品的信息由运营在管理后台录入和变更。这些商品的请求量非常大,即使是Redis也很难扛住,所以这里我们可以使用本地缓存来进行优化。
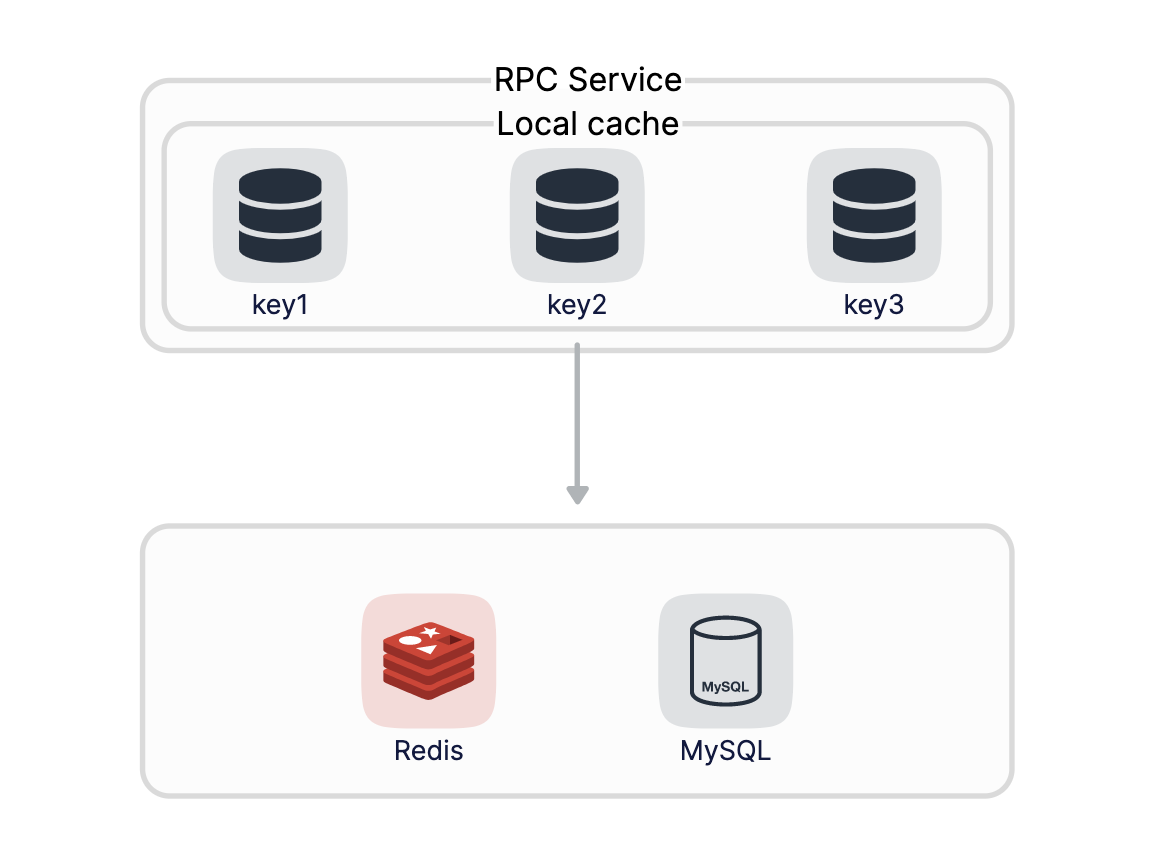
在product库中先建一张商品运营表product_operation,为了简化只保留必要字段,product_id为推广运营的商品id,status为运营商品的状态,status为1的时候会在首页Banner中展示该商品。
CREATE TABLE `product_operation` (
`id` bigint unsigned NOT NULL AUTO_INCREMENT,
`product_id` bigint unsigned NOT NULL DEFAULT 0 COMMENT '商品id',
`status` int NOT NULL DEFAULT '1' COMMENT '运营商品状态 0-下线 1-上线',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`),
KEY `ix_update_time` (`update_time`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='商品运营表';
本地缓存的实现比较简单,我们可以使用map来自己实现,在go-zero的collection中提供了Cache来实现本地缓存的功能,我们直接拿来用,重复造轮子从来不是一个明智的选择,localCacheExpire为本地缓存过期时间,Cache提供了Get和Set方法,使用非常简单
localCache, err := collection.NewCache(localCacheExpire)
先从本地缓存中查找,如果命中缓存则直接返回。没有命中缓存的话需要先从数据库中查询运营位商品id,然后再聚合商品信息,最后回塞到本地缓存中。详细代码逻辑如下:
func (l *OperationProductsLogic) OperationProducts(in *product.OperationProductsRequest) (*product.OperationProductsResponse, error) {
opProducts, ok := l.svcCtx.LocalCache.Get(operationProductsKey)
if ok {
return &product.OperationProductsResponse{Products: opProducts.([]*product.ProductItem)}, nil
}
pos, err := l.svcCtx.OperationModel.OperationProducts(l.ctx, validStatus)
if err != nil {
return nil, err
}
var pids []int64
for _, p := range pos {
pids = append(pids, p.ProductId)
}
products, err := l.productListLogic.productsByIds(l.ctx, pids)
if err != nil {
return nil, err
}
var pItems []*product.ProductItem
for _, p := range products {
pItems = append(pItems, &product.ProductItem{
ProductId: p.Id,
Name: p.Name,
})
}
l.svcCtx.LocalCache.Set(operationProductsKey, pItems)
return &product.OperationProductsResponse{Products: pItems}, nil
}
使用grpurl调试工具请求接口,第一次请求cache miss后,后面的请求都会命中本地缓存,等到本地缓存过期后又会重新回源db加载数据到本地缓存中
~ grpcurl -plaintext -d '{}' 127.0.0.1:8081 product.Product.OperationProducts
{
"products": [
{
"productId": "32",
"name": "电风扇6"
},
{
"productId": "31",
"name": "电风扇5"
},
{
"productId": "33",
"name": "电风扇7"
}
]
}
注意,并不是所有信息都适用于本地缓存,本地缓存的特点是请求量超高,同时业务上能够允许一定的不一致,因为本地缓存一般不会主动做更新操作,需要等到过期后重新回源db后再更新。所以在业务中要视情况而定看是否需要使用本地缓存。
自动识别热点数据
首页Banner场景是由运营人员来配置的,也就是我们能提前知道可能产生的热点数据,但有些情况我们是不能提前预知数据会成为热点的。所以就需要我们能自适应地自动的识别这些热点数据,然后把这些数据提升为本地缓存。
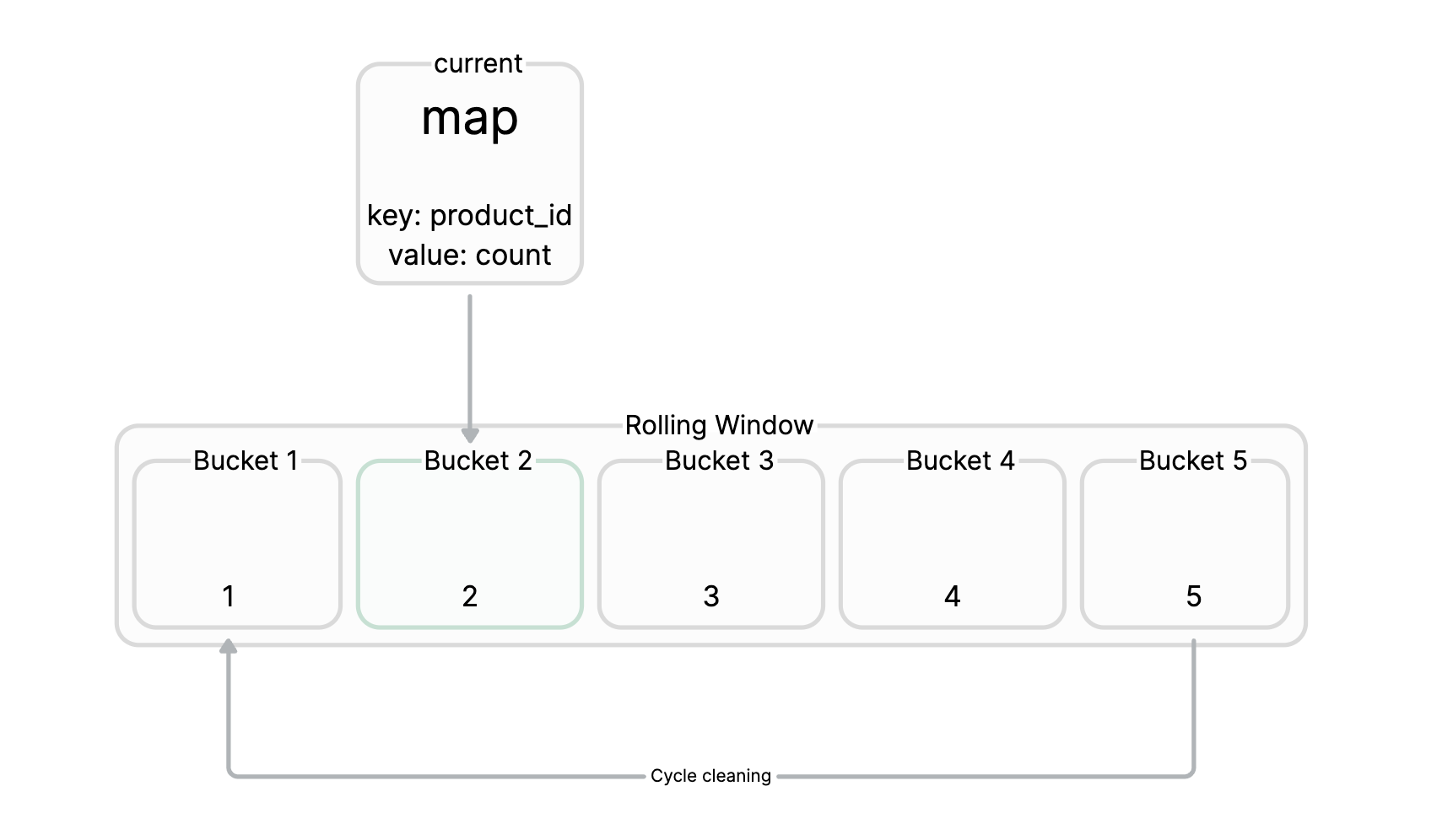
我们维护一个滑动窗口,比如滑动窗口设置为10s,就是要统计这10s内有哪些key被高频访问,一个滑动窗口中对应多个Bucket,每个Bucket中对应一个map,map的key为商品的id,value为商品对应的请求次数。接着我们可以定时的(比如10s)去统计当前所有Buckets中的key的数据,然后把这些数据导入到大顶堆中,轻而易举的可以从大顶堆中获取topK的key,我们可以设置一个阈值,比如在一个滑动窗口时间内某一个key访问频次超过500次,就认为该key为热点key,从而自动地把该key升级为本地缓存。
缓存使用技巧
下面介绍一些缓存使用的小技巧
- key的命名要尽量易读,即见名知意,在易读的前提下长度要尽可能的小,以减少资源的占用,对于value来说可以用int就尽量不要用string,对于小于N的value,redis内部有shared_object缓存。
- 在redis使用hash的情况下进行key的拆分,同一个hash key会落到同一个redis节点,hash过大的情况下会导致内存以及请求分布的不均匀,考虑对hash进行拆分为小的hash,使得节点内存均匀避免单节点请求热点。
- 为了避免不存在的数据请求,导致每次请求都缓存miss直接打到数据库中,进行空缓存的设置。
- 缓存中需要存对象的时候,序列化尽量使用protobuf,尽可能减少数据大小。
- 新增数据的时候要保证缓存务必存在的情况下再去操作新增,使用Expire来判断缓存是否存在。
- 对于存储每日登录场景的需求,可以使用BITSET,为了避免单个BITSET过大或者热点,可以进行sharding。
- 在使用sorted set的时候,避免使用zrange或者zrevrange返回过大的集合,复杂度较高。
- 在进行缓存操作的时候尽量使用PIPELINE,但也要注意避免集合过大。
- 避免超大的value。
- 缓存尽量要设置过期时间。
- 慎用全量操作命令,比如Hash类型的HGETALL、Set类型的SMEMBERS等,这些操作会对Hash和Set的底层数据结构进行全量扫描,如果数据量较多的话,会阻塞Redis主线程。
- 获取集合类型的全量数据可以使用SSCAN、HSCAN等命令分批返回集合中的数据,减少对主线程的阻塞。
- 慎用MONITOR命令,MONITOR命令会把监控到的内容持续写入输出缓冲区,如果线上命令操作很多,输出缓冲区很快就会溢出,会对Redis性能造成影响。
- 生产环境禁用KEYS、FLUSHALL、FLUSHDB等命令。
结束语
本篇文章介绍了如何使用本地热点缓存应对超高的请求,热点缓存又分为已知的热点缓存和未知的热点缓存。已知的热点缓存比较简单,从数据库中提前加载到内存中即可,未知的热点缓存我们需要自适应的识别出热点的数据,然后把这些热点的数据升级为本地缓存。最后介绍了一些实际生产中缓存使用的一些小技巧,在生产环境中要活灵活用尽量避免问题的产生。
希望本篇文章对你有所帮助,谢谢。
每周一、周四更新
代码仓库: https://github.com/zhoushuguang/lebron
项目地址
https://github.com/zeromicro/go-zero
欢迎使用 go-zero 并 star 支持我们!
微信交流群
关注『微服务实践』公众号并点击 交流群 获取社区群二维码。
go-zero微服务实战系列(七、请求量这么高该如何优化)的更多相关文章
- 微服务实战系列(十)-网关高可用之中间件Keepalived
1.场景描述 因为要做网关的高可用,用到了keepalived+nginx,来保证nginx的高可用,如下图: 安装了keepavlived,走了一些弯路,记录下吧,nginx的安装就不多说了,博客已 ...
- go-zero微服务实战系列(十一、大结局)
本篇是整个系列的最后一篇了,本来打算在系列的最后一两篇写一下关于k8s部署相关的内容,在构思的过程中觉得自己对k8s知识的掌握还很不足,在自己没有理解掌握的前提下我觉得也很难写出自己满意的文章,大家看 ...
- go-zero微服务实战系列(三、API定义和表结构设计)
前两篇文章分别介绍了本系列文章的背景以及根据业务职能对商城系统做了服务的拆分,其中每个服务又可分为如下三类: api服务 - BFF层,对外提供HTTP接口 rpc服务 - 内部依赖的微服务,实现单一 ...
- 微服务实战系列--Nginx官网发布(转)
这是Nginx官网写的一个系列,共七篇文章,如下 Introduction to Microservices (this article) Building Microservices: Using ...
- ASP.NET Core微服务实战系列
希望给你3-5分钟的碎片化学习,可能是坐地铁.等公交,积少成多,水滴石穿,码字辛苦,如果你吃了蛋觉得味道不错,希望点个赞,谢谢关注. 前言 这里记录的是个人奋斗和成长的地方,该篇只是一个系列目录和构想 ...
- Chris Richardson微服务实战系列
微服务实战(一):微服务架构的优势与不足 微服务实战(二):使用API Gateway 微服务实战(三):深入微服务架构的进程间通信 微服务实战(四):服务发现的可行方案以及实践案例 微服务实践(五) ...
- go-zero 微服务实战系列(一、开篇)
前言 在社区中经常看到有人问有没有基于 go-zero 的比较完整的项目参考,该类问题本质上是想知道基于 go-zero 的项目的最佳实践.完整的项目应该是一个完整的产品功能,包含产品需求.架构设计. ...
- 微服务实战系列(七)-网关springcloud gateway
1. 场景描述 springcloud刚推出的时候用的是netflix全家桶,路由用的zuul,但是据说zull1.0在大数据量访问的时候存在较大性能问题,2.0就没集成到springcloud中了, ...
- 微服务实战系列(五)-注册中心Eureka与nacos区别
1. 场景描述 nacos最近用的比较多,介绍下nacos及部署吧,刚看了下以前写过类似的,不过没写如何部署及与eureka区别,只展示了效果,补补吧. 2.解决方案 2.1 nacos与eureka ...
随机推荐
- Java学习day15
File是文件和目录路径名的抽象表示 文件和目录可以通过File封装成对象 对于File而言,封装的不是一个真正存在的文件,只是一个路径名,它可以存在,也可以不存在,要通过后续操作把路径的内容转换为具 ...
- brup去除mozilla等无用数据包的方法
方法一 针对火狐浏览器的解决方法 1.在firefox(火狐浏览器)地址栏中输入: about:config 2.然后出现搜索框,搜索以下内容,双击将它设置成false. network.captiv ...
- ubuntu16.04安装MATLAB R2017b步骤详解(附完整文件包)
摘要:介绍在ubuntu16.04中从下载到安装成功的完整步骤.本文给出MATLAB R2017b(Linux系统)的完整安装包百度云盘下载地址,逐步介绍一种简单易行的安装方法,在桌面创建快捷方式,最 ...
- MySQL远程连接、用户授权
目录 MySQL远程连接 创建用户.授权 MySQL添加用户.删除用户.授权及撤销权限 MySQL可授予用户的执行权限 MySQL远程连接 远程连接 授权 常见权限表 相关库:mysql 相关表:us ...
- Java 18 新特性:简单Web服务器 jwebserver
在今年3月下旬的时候,Java版本已经更新到了18.接下来DD计划持续做一个系列,主要更新从Java 9开始的各种更新内容,但我不全部都介绍,主要挑一些有意思的内容,以文章和视频的方式来给大家介绍和学 ...
- 技术分享 | SeleniumIDE用例录制
1.录制回放方式的稳定性和可靠性有限 2.只支持 Firefox.Chrome 3.对于复杂的页面逻辑其处理能力有限 环境准备 Chrome 插件:https://chrome.google.com/ ...
- 详解Kubernetes存储体系
Volume.PV.PVC.StorageClass由来 先思考一个问题,为什么会引入Volume这样一个概念? " 答案很简单,为了实现数据持久化,数据的生命周期不随着容器的消亡而消亡. ...
- 从旧金山到上海, HTTP/3 非常快!
HTTP/3 是超文本传输协议 (HTTP) 的第三个版本,它对 Web 性能来说意义重大, 让我们看看HTTP/3 如何让网站的速度变得更快! 等等,HTTP/2 发生了什么? 不是几年前才开始推广 ...
- Map传参优雅检验,试试json schema validator
背景 笔者目前所在团队的代码年代已久,早年规范缺失导致现在维护成本激增,举一个深恶痛疾的例子就是方法参数使用Map"一撸到底",说多了都是泪,我常常在团队内自嘲"咱硬是把 ...
- [源码解析] TensorFlow 分布式之 ParameterServerStrategy V2
[源码解析] TensorFlow 分布式之 ParameterServerStrategy V2 目录 [源码解析] TensorFlow 分布式之 ParameterServerStrategy ...