总算给女盆友讲明白了,如何使用stream流的filter()操作
一、引言
在上一篇文章中《这么简单,还不会使用java8 stream流的map()方法吗?》分享了使用stream的map()方法,不知道小伙伴还有印象吗,先来回顾下要点,map()方法是把一个流中的元素T转换为另外一个新流中的元素R,转换完成后两个流的元素个数不发生改变,具体怎么使用,请小伙伴移步上篇查看。在上篇文章中遗留了一个问题,本篇文章来解决它。先来看stream的另一个API--filter()方法。
二、概述
先来看下filter方法的定义,
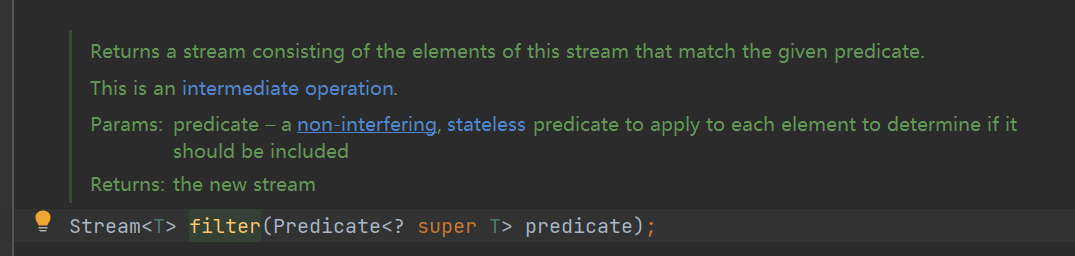
该方法返回一个新流,这个新流中的元素要匹配给定的表达式。从方法的入参及出参可以看到返回的新流中的元素和元素流中的元素类型是一致的,和map()方法不同的是新流的元素个数要小于等于原始流的元素个数。
下面看下示意图,更清晰,

是不是很简单,下面看下具体的用法。
三、详述
以”找出一年级的所有学生的成绩“为例,来看下怎么使用filter()方法。同样初始化五个学生,
Data.java
package com.example.log.stream.test;
import com.example.log.stream.entity.Student;
import java.util.ArrayList;
import java.util.List;
/**
* @date 2022/11/30 22:43
*/
public class Data {
public static List<Student> initData(){
List<Student> students= new ArrayList<>();
Student s1=new Student();
s1.setName("王五");
s1.setSchoolClass("一年级");
s1.setChineseScore(100);
s1.setMathScore(100);
students.add(s1);
Student s2=new Student();
s2.setName("李四");
s2.setSchoolClass("一年级");
s2.setChineseScore(100);
s2.setMathScore(100);
students.add(s2);
Student s3=new Student();
s3.setName("李思");
s3.setSchoolClass("二年级");
s3.setChineseScore(100);
s3.setMathScore(100);
students.add(s3);
Student s4=new Student();
s4.setName("王五");
s4.setSchoolClass("三年级");
s4.setChineseScore(100);
s4.setMathScore(100);
students.add(s4);
Student s5=new Student();
s5.setName("赵三");
s5.setSchoolClass("一年级");
s5.setChineseScore(100);
s5.setMathScore(100);
students.add(s5);
return students;
}
}Student.java类这里不在贴出,有兴趣的可以自己写,或参考上篇文章中的定义。直接看怎么实现。
3.1、找出一年级的所有学生成绩
要找出一年级的所有学生成绩,就要根据schoolClass进行过滤,看下使用filter()方法怎么写。
package com.example.log.stream.test;
import com.example.log.stream.entity.Student;
import java.util.List;
import java.util.stream.Collectors;
/**
* 测试filter()方法
* @date 2022/12/1 21:01
*/
public class TestFilter {
public static void main(String[] args) {
List<Student> students=Data.initData();
//使用filter对schoolClass进行过滤,满足条件的返回true,否则返回false,达到过滤的目的
List<Student> firstClass=students.stream().filter(student -> {
if("一年级".equals(student.getSchoolClass())){
return true;
}
return false;
}).collect(Collectors.toList());
//打印新的流
for (Student student:firstClass) {
System.out.println(student);
}
System.out.println("---------------------");
for (Student student:students) {
System.out.println(student);
}
}
}使用filter()方法,该方法中的函数式接口,返回一个boolean类型的值,从而决定了该元素是否会写入到新流中。看下结果,

如果现在有这样一个需求,找出所有的一年级的学生,并给他们的数学成绩都减1分。要怎么办?
3.2、给一年级的所有同学的数学成绩减1分
我们可以在上面的基础上进行修改,完成此需求,
package com.example.log.stream.test;
import com.example.log.stream.entity.Student;
import java.util.List;
import java.util.stream.Collectors;
/**
* 测试filter()方法
* @date 2022/12/1 21:01
*/
public class TestFilter {
public static void main(String[] args) {
List<Student> students=Data.initData();
//使用filter对schoolClass进行过滤,满足条件的返回true,否则返回false,达到过滤的目的
List<Student> firstClass=students.stream().filter(student -> {
if("一年级".equals(student.getSchoolClass())){
//所有一年级的学生,数学减1分
student.setMathScore(student.getMathScore()-1);
return true;
}
return false;
}).collect(Collectors.toList());
//打印新的流
for (Student student:firstClass) {
System.out.println(student);
}
System.out.println("---------------------");
for (Student student:students) {
System.out.println(student);
}
}
}只需在上面的基础上增加一行代码即可,即符合条件的都减1分,看下打印结果。

从上面的解雇可以看到使用filter完成了该功能,但带来的一个副作用是原始数据也变了,主要是因为修改的是通过一个引用指向的对象。其实不太建议这样去写,因为filter()方法从字面意思就可以知道,它的作用就是过滤,最好不要参杂其他的逻辑,可以再加一个map()方法。
TestFilter2.java
package com.example.log.stream.test;
import com.example.log.stream.entity.Student;
import java.util.List;
import java.util.stream.Collectors;
/**
* 测试filter()方法
* @date 2022/12/1 21:01
*/
public class TestFilter2 {
public static void main(String[] args) {
List<Student> students=Data.initData();
//使用filter对schoolClass进行过滤,满足条件的返回true,否则返回false,达到过滤的目的
List<Student> firstClass=students.stream().filter(student -> {
if("一年级".equals(student.getSchoolClass())){
return true;
}
return false;
}).map(student -> {//map()方法
//设置数学成绩减1
student.setMathScore(student.getMathScore()-1);
return student;
}).collect(Collectors.toList());
//打印新的流
for (Student student:firstClass) {
System.out.println(student);
}
System.out.println("---------------------");
for (Student student:students) {
System.out.println(student);
}
}
}上面在使用完filter后,由于是一个stream流,那么继续使用map()方法,对上一步过滤出的元素再对数学成绩减1操作,最后得到结果。通过一个示意图,
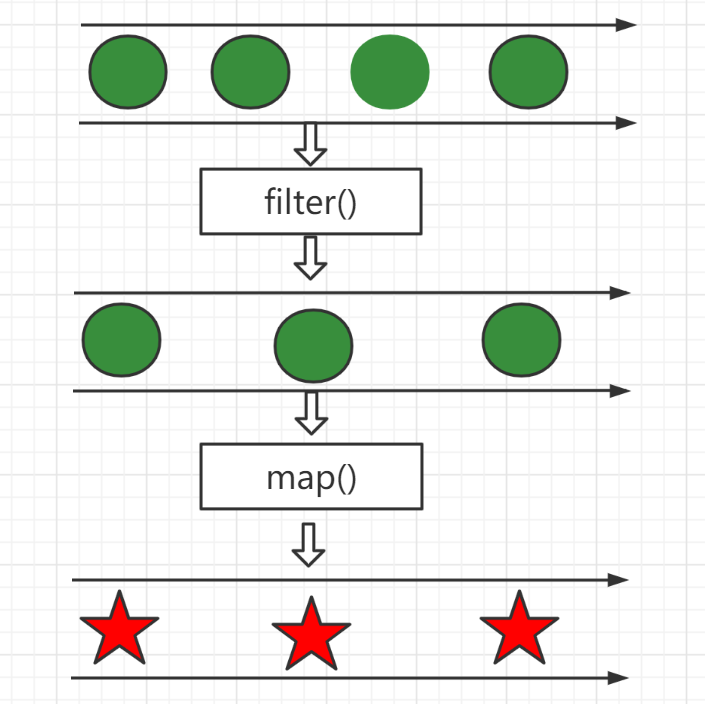
这样是不是比直接在fliter()中更加清晰。
四、总结
stream的filter()方法是要通过true/false来筛选元素,为true的会放到新流中,反之为false的不会放到新流中。
推荐阅读
这么简单,还不会使用java8 stream流的map()方法吗?
有不正之处,欢迎指正,谢谢!
感谢动动小手关注公众号【良工说技术】,更多精彩不容错过。

总算给女盆友讲明白了,如何使用stream流的filter()操作的更多相关文章
- 【ZZ】终于有人把云计算、大数据和人工智能讲明白了!
终于有人把云计算.大数据和人工智能讲明白了! https://mp.weixin.qq.com/s/MqBP0xziJO-lPm23Bjjh9w 很不错的文章把几个概念讲明白了...图片拷不过来... ...
- 没讲明白的水题orz
有一道解释程序的水题没给非计算机专业的同学讲明白orz,在这里再练一下.. 源代码完全没有缩进真是难以忍受.. p.s.懂递归就不用看了#include <stdio.h> int n = ...
- [CSP-S模拟测试]:小盆友的游戏(数学 or 找规律)
题目传送门(内部题110) 输入格式 第一行一个整数$N$,表示小盆友的个数. 第二行$N$个整数$A_i$,如果$A_i=-1$表示$i$目前是自由身,否则$i$是$A_i$的跟班. 输出格式 一个 ...
- Scala 深入浅出实战经典 第41讲:List继承体系实现内幕和方法操作源码揭秘
Scala 深入浅出实战经典 第41讲:List继承体系实现内幕和方法操作源码揭秘 package com.parllay.scala.dataset /** * Created by richard ...
- Scala 深入浅出实战经典 第39讲:ListBuffer、ArrayBuffer、Queue、Stack操作代码实战
王家林亲授<DT大数据梦工厂>大数据实战视频 Scala 深入浅出实战经典(1-64讲)完整视频.PPT.代码下载:百度云盘:http://pan.baidu.com/s/1c0noOt6 ...
- 云计算分布式大数据Hadoop实战高手之路第八讲Hadoop图文训练课程:Hadoop文件系统的操作实战
本讲通过实验的方式讲解Hadoop文件系统的操作. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发布云 ...
- 第三百六十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)基本的索引和文档CRUD操作、增、删、改、查
第三百六十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)基本的索引和文档CRUD操作.增.删.改.查 elasticsearch(搜索引擎)基本的索引 ...
- MEF入门之不求甚解,但力求简单能讲明白(四)
上一篇我们已经可以获取各种FileHandler的实例和对应的元数据.本篇,我们做一个稍微完整的文件管理器. 1.修改接口IFileHandler,传入文件名 namespace IPart { pu ...
- 终于有人把云计算、大数据和 AI 讲明白了
最近学习hadoop以及生态,顺便看到了这篇文章,总结的很到位,转载下. 我今天要讲这三个话题,一个是云计算,一个大数据,一个人工智能,我为什么要讲这三个东西呢?因为这三个东西现在非常非常的火,它们之 ...
- 哪5种IO模型?什么是select/poll/epoll?同步异步阻塞非阻塞有啥区别?全在这讲明白了!
系统中有哪5种IO模型?什么是 select/poll/epoll?同步异步阻塞非阻塞有啥区别? 本文地址http://yangjianyong.cn/?p=84转载无需经过作者本人授权 先解开第一个 ...
随机推荐
- 如何使用Arthas定位问题
在我们日常的工作中,经常会遇到一些线上才会遇到的问题.Arthas无疑是我们在工作中,定位线上问题的神奇.下面,我将介绍一下我们在工作中经常用到的一些功能. dashboard 首先我们可以通过das ...
- 面试说:聊聊JavaScript中的数据类型
前言 请讲下 JavaScript 中的数据类型? 前端面试中,估计大家都被这么问过. 答:Javascript 中的数据类型包括原始类型和引用类型.其中原始类型包括 null.undefined.b ...
- python csv写入多列
import csv import os def main(): current_dir = os.path.abspath('.') file_name = os.path.join(current ...
- 跟我学Python图像处理丨带你掌握傅里叶变换原理及实现
摘要:傅里叶变换主要是将时间域上的信号转变为频率域上的信号,用来进行图像除噪.图像增强等处理. 本文分享自华为云社区<[Python图像处理] 二十二.Python图像傅里叶变换原理及实现> ...
- @input含义和用法
@input :一般用于监听事件只要输入的值变化了就会触发input 示例: <div id="div1"> <input type="text&quo ...
- 把train数据集生成txt(test同理)
import cv2 import numpy as np import os import sys import pickle data_dir = os.path.join("./&qu ...
- SpringMVC访问静态资源的问题。
在项目中引用css和js文件一直出错,反复修改文件路径始终访问不到.究其原因原来是应该在web.xml 文件中添加访问静态资源的默认servlet. 如下. <servlet-mapping&g ...
- Netty 学习(十):ChannelPipeline源码说明
Netty 学习(十):ChannelPipeline源码说明 作者: Grey 原文地址: 博客园:Netty 学习(十):ChannelPipeline源码说明 CSDN:Netty 学习(十): ...
- mysql 过程和函数语法学习笔记
CREATE DEFINER=`root`@`%` PROCEDURE `test`(`num` int) BEGIN /*定义变量*/ DECLARE sex TINYINT(2) DEFAULT ...
- 后端框架的学习----mybatis框架(6、日志)
六.日志 如果一个数据库操作,出现了异常,我们需要排错,日志就是最好的帮手 setting设置 <settings> <setting name="logImpl" ...