python的scrapy框架的使用 和xpath的使用 && scrapy中request和response的函数参数 && parse()函数运行机制
这篇博客主要是讲一下scrapy框架的使用,对于糗事百科爬取数据并未去专门处理
最后爬取的数据保存为json格式
一、先说一下pyharm怎么去看一些函数在源码中的代码实现
按着ctrl然后点击函数就行了
先给出项目的目录:

二、先说一下setting.py文件中一些变量的含义
BOT_NAME = 'qsbk'
# 定义一下这个项目的根
# 以后想要把这个项目某一个文件中的某个内容导入到其他文件,就可以以“qsbk.文件名”来实现
# 例如:
# from qsbk.items import QsbkItem
# 这个意思就是将qsbk目录下的items.py文件中的QsbkItem类导入到此文件中
# 如果它的值为True,那么网站上没有爬虫协议,那么程序就会什么都不执行就停止运行
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 3 # 下载延迟打开,一方面防止ip被封,另一方面也不要给网站服务器太大压力
# 设置默认请求头
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'user-agent': ''
}
ITEM_PIPELINES = {
'qsbk.pipelines.QsbkPipeline': 300, # 通过管道输出数据,不解除这个注释,就不会运行pipelines.py一部分代码
# 值越小,优先级越高
}
携带cookie登录
# 后续的请求会自动携带之前的cookie (setting.py配置文件中不要禁用cookie,值为True)
# 禁用cookie (默认开启cookie)
# COOKIES_ENABLED = False
COOKIES_DEBUG = True # 开启cookie的调试信息
二、start.py文件
因为每次执行scrapy都需要在命令行下执行,用惯了pycharm之后看着不太习惯,所以这个文件就是代替在命令行下输入执行爬虫命令,它的执行结果也会在pycharm上显示,这样就不用每次打开cmd去运行scrapy的爬虫程序了
start.py内容:
from scrapy import cmdline
# qsbk_spider是你的爬虫程序文件,注意要把这个命令用split拆开
cmdline.execute("scrapy crawl qsbk_spider".split())
三、Item.py文件内容
import scrapy class QsbkItem(scrapy.Item):
# 这个是固定写法,也就是给QsbkItem类定义两个变量
# Item是爬虫爬取到数据后,传递给管道去存储数据的单位。传递给管道pipelines.py的Item也可以是字典形式
# 可以自己定义字典,最后返回这个字典也可以,(返回什么数据可以根据自己喜好,你也可以返回列表)
author = scrapy.Field()
content = scrapy.Field()
四、pipelines.py文件
我们使用scrapy内置类来完成导出数据,可见这个类可以自动把item变成字典,所以我们就不用去多处理
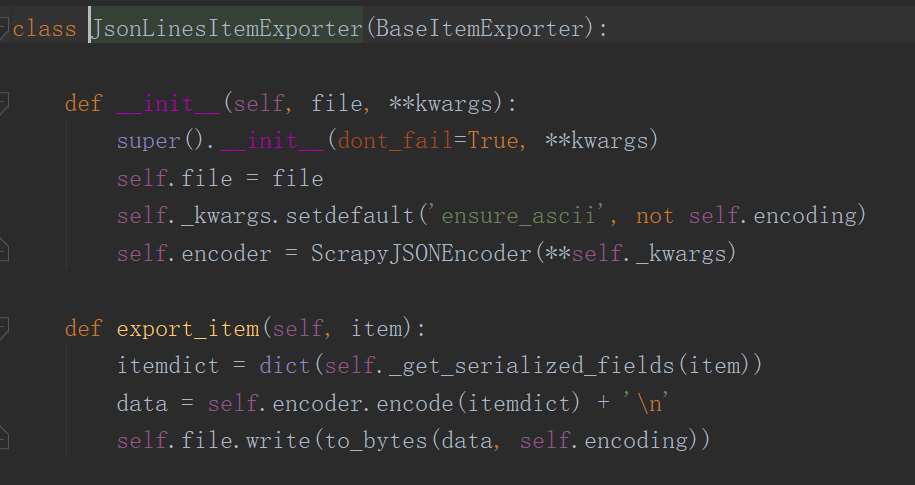
同时在这个文件中有三个函数,其中两个open_spider和close_spider文件中没有给我们定义,我们需要自己定义。这两个函数一个在爬虫开始时执行,一个在爬虫执行结束时执行
文件代码:
'''
下面给出两种不同类型的内置保存数据方式,请根据需求使用
当然也可以不使用内置函数来保存数据,可以自己写
''' # from scrapy.exporters import JsonItemExporter
# 每次会把数据放在内存,最后在一次性写入文件,存储的是一个josn类型的文件
# 坏处是比较耗费内存
# class QsbkPipeline:
# def __init__(self):
# self.fp = open('duanzi.json','wb')
# self.exporter = JsonItemExporter(self.fp,ensure_ascii=False,encoding='utf-8')
# self.exporter.start_exporting()
#
# def open_spider(self):
# print('爬虫开始了')
# def process_item(self, item, spider):
# self.exporter.export_item(item)
# return item
#
# def close_spider(self):
# self.exporter.finish_exporting()
# self.fp.close()
# print('爬虫结束了') from itemadapter import ItemAdapter
# 每次调用export_item就会把itrm存放在磁盘,坏处是每一次字典是一行,整个文件不是一个字典,好处是
# 每次写入磁盘,不会占用大量内存
from scrapy.exporters import JsonLinesItemExporter
class QsbkPipeline:
def __init__(self):
self.fp = open('duanzi.json','wb')
self.exporter = JsonLinesItemExporter(self.fp,ensure_ascii=False,encoding='utf-8')
# self.exporter.start_exporting() def open_spider(self,spider): # 爬虫开始的时候会执行
print('爬虫开始了') def process_item(self, item, spider): # 当有item输出传来的时候会执行
# 这样的话我们就不需要先将item转换为字典形式再去保存,我们可以直接传给导出器exporter
self.exporter.export_item(item)
# 只有下面return了,我们才可以对下一个item进行操作
return item def close_spider(self,spider): # 爬虫结束会执行
# self.exporter.finish_exporting()
self.fp.close()
print('爬虫结束了')
五、qsbk_spider文件
import scrapy
from scrapy.http.response.html import HtmlResponse
from scrapy.selector.unified import SelectorList
from qsbk.items import QsbkItem class QsbkSpiderSpider(scrapy.Spider):
name = 'qsbk_spider' # 同一类爬虫名字要相同,以便于命令行下运行
allowed_domains = ['qiushibaike.com'] # 控制爬虫范围,以访爬虫通过其他链接,爬到其他网站
# start_url可以传一个url也可以多个,这个url会传给引擎,然后引擎会传给调度器,调度器又会处理后传到
# 引擎,之后引擎传给下载器,下载器将数据又通过引擎传递到爬虫的parse函数,它的参数response就是返回的数据
start_urls = ['https://www.qiushibaike.com/text']
base_url = 'https://www.qiushibaike.com' def parse(self, response):
# selectorlist
duanzidivs = response.xpath('//*[@id="content"]/div/div[2]/div') #获取包含所有段子的div
for duanzidiv in duanzidivs:
# selector
# get()方法回去的是selector的第一个文本,get_all()获取的是所有文本
author = duanzidiv.xpath(".//div[1]/a[2]/h2/text()").get().strip()
content = duanzidiv.xpath(".//a[1]/div/span[1]/text()").getall() # getall方法会将所有文本信息转变成一个队列,然后转换成一个字段
content = ".".join(content).strip() # strip方法就是消除content字符串前后行
item = QsbkItem(author=author,content=content)
yield item # 让这个函数变成一个生成器函数
# 找到下一页按钮,并提取出里面href的内容,之后链接拼接形成新的url
next_url = response.xpath('//*[@id="content"]/div/div[2]/ul/li[8]/a/@href').get()
if not next_url:
return
else:
yield scrapy.Request(self.base_url+next_url,callback=self.parse)
六、xpath的简单使用
1、选取节点
| 表达式 | 描述 | 实例 | |
| nodename | 选取nodename节点的所有子节点 | xpath(‘//div’) | 选取了div节点的所有子节点 |
| / | 从根节点选取 | xpath(‘/div’) | 从根节点上选取div节点 |
| // | 选取所有的当前节点,不考虑他们的位置 | xpath(‘//div’) | 选取所有的div节点 |
| . | 选取当前节点 | xpath(‘./div’) | 选取当前节点下的div节点 |
| .. | 选取当前节点的父节点 | xpath(‘..’) | 回到上一个节点 |
| @ | 选取属性 | xpath(’//@calss’) | 选取所有的class属性 |
2、嵌在方括号内,用来查找某个特定的节点或包含某个制定的值的节点
| 表达式 | 结果 |
| xpath(‘/body/div[1]’) | 选取body下的第一个div节点 |
| xpath(‘/body/div[last()]’) | 选取body下最后一个div节点 |
| xpath(‘/body/div[last()-1]’) | 选取body下倒数第二个div节点 |
| xpath(‘/body/div[positon()<3]’) | 选取body下前两个div节点 |
| xpath(‘/body/div[@class]’) | 选取body下带有class属性的div节点 |
| xpath(‘/body/div[@class=”main”]’) | 选取body下class属性为main的div节点 |
| xpath(‘/body/div[price>35.00]’) | 选取body下price元素值大于35的div节点 |
3、通配符
| 表达式 | 结果 |
| xpath(’/div/*’) | 选取div下的所有子节点 |
| xpath(‘/div[@*]’) | 选取所有带属性的div节点 |
4、相对路径查询
| 轴名称 | 表达式 | 描述 |
| ancestor | xpath(‘./ancestor::*’) | 选取当前节点的所有先辈节点(父、祖父) |
| ancestor-or-self | xpath(‘./ancestor-or-self::*’) | 选取当前节点的所有先辈节点以及节点本身 |
| attribute | xpath(‘./attribute::*’) | 选取当前节点的所有属性 |
| child | xpath(‘./child::*’) | 返回当前节点的所有子节点 |
| descendant | xpath(‘./descendant::*’) | 返回当前节点的所有后代节点(子节点、孙节点) |
| following | xpath(‘./following::*’) | 选取文档中当前节点结束标签后的所有节点 |
| following-sibing | xpath(‘./following-sibing::*’) | 选取当前节点之后的兄弟节点 |
| parent | xpath(‘./parent::*’) | 选取当前节点的父节点 |
| preceding | xpath(‘./preceding::*’) | 选取文档中当前节点开始标签前的所有节点 |
| preceding-sibling | xpath(‘./preceding-sibling::*’) | 选取当前节点之前的兄弟节点 |
| self | xpath(‘./self::*’) | 选取当前节点 |
5、模糊查询
| 函数 | 用法 | 解释 |
| starts-with | xpath(‘//div[starts-with(@id,”ma”)]‘) | 选取id值以ma开头的div节点 |
| contains | xpath(‘//div[contains(@id,”ma”)]‘) | 选取id值包含ma的div节点 |
| and | xpath(‘//div[contains(@id,”ma”) and contains(@id,”in”)]‘) | 选取id值包含ma和in的div节点 |
| text() | xpath(‘//div[contains(text(),”ma”)]‘) | 选取节点文本包含ma的div节点 |
七、scrapy中request和response的函数参数

meta使用举例:
你在本级页面的上一级页面提取到了部分本级页面的信息,你就可以不用重复提取这部分“在上级页面提取的内容”,可以通过传参来完成


八、parse()函数运行机制
参考:https://blog.csdn.net/qq_43546676/article/details/89058986
1. 因为使用的yield,而不是return。parse函数将会被当做一个生成器使用。scrapy会逐一获取parse方法中生成的结果,并判断该结果是一个什么样的类型;
2. 如果是request则加入爬取队列,如果是item类型则使用pipeline处理,其他类型则返回错误信息。
3. scrapy取到第一部分的request不会立马就去发送这个request,只是把这个request放到队列里,然后接着从生成器里获取;
4. 取尽第一部分的request,然后再获取第二部分的item,取到item了,就会放到对应的pipeline里处理;
5. parse()方法作为回调函数(callback)赋值给了Request,指定parse()方法来处理这些请求 scrapy.Request(url, callback=self.parse)
6. Request对象经过调度,执行生成 scrapy.http.response()的响应对象,并送回给parse()方法,直到调度器中没有Request(递归的思路)
7. 取尽之后,parse()工作结束,引擎再根据队列和pipelines中的内容去执行相应的操作;
8. 程序在取得各个页面的items前,会先处理完之前所有的request队列里的请求,然后再提取items。
9. 这一切的一切,Scrapy引擎和调度器将负责到底。
由此可见,不是只有parse中的对象能返回给pipelines中,如果你继续对parse方法,继续用回调函数
yield Request(url, headers=header, callback=next)则回调函数中返回的item也可以在pipelines.py中,进行数据处理。
另外,在yield后面代码也要注意,因为,它会先执行yield后面代码,执行完后,再到request队列中取request,才会调用回调函数。
九、中间件的使用(以设置随机请求头为例)
通过对http://httpbin.org/user-agent 的访问,验证随机请求头设置是否成功
scrapy.Requst的dont_filter属性是用来通知这个请求是否要被去重机制处理
去重也就是如果这个链接之前被访问过,那么就不会再访问它(scrapy中默认是去重,值为False)
1、首先再middleware.py中定义一个随机请求头的类
class UserAgentMiddleWare:
User_Agent = [
"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0",
"Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727; .NET CLR 3.0.30729; .NET CLR 3.5.30729; InfoPath.3; rv:11.0) like Gecko",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11",
"Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; TencentTraveler 4.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Avant Browser)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
"Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (iPod; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (iPad; U; CPU OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (Linux; U; Android 2.3.7; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1" ]
def process_request(self,request,spider):
user_agent = random.choice(self.User_Agent)
request.headers['User-Agent'] = user_agent
2、然后再setting.py中激活中间件
DOWNLOADER_MIDDLEWARES = {
'qsbk.middlewares.UserAgentMiddleWare': 543,
}
3、之后在原来qsbk_spider.py中改一下就可以了
import scrapy
from scrapy.http.response.html import HtmlResponse
from scrapy.selector.unified import SelectorList
from qsbk.items import QsbkItem
import json class QsbkSpiderSpider(scrapy.Spider):
name = 'qsbk_spider'
allowed_domains = ['httpbin.org']
start_urls = ['http://httpbin.org/user-agent'] def parse(self, response):
user_agent = json.loads(response.text)['user-agent']
print('='*30)
print(user_agent)
print('='*30) # dont_filter=True这样的话链接就不会通过去重机制,而直接请求
yield scrapy.Request(url=self.start_urls[0],dont_filter=True)
在scrapy的引擎到下载器之间的中间件,我们可以复写两个函数来完成我们的一些操作,一个是process_request和process_response
具体内容如下


python的scrapy框架的使用 和xpath的使用 && scrapy中request和response的函数参数 && parse()函数运行机制的更多相关文章
- python基础编程: 编码补充、文件操作、集合、函数参数、函数递归、二分查找、匿名函数与高阶函数
目录: 编码的补充 文件操作 集合 函数的参数 函数的递归 匿名函数与高阶函数 二分查找示例 一.编码的补充: 在python程序中,首行一般为:#-*- coding:utf-8 -*-,就是告诉p ...
- Python爬虫 ---scrapy框架初探及实战
目录 Scrapy框架安装 操作环境介绍 安装scrapy框架(linux系统下) 检测安装是否成功 Scrapy框架爬取原理 Scrapy框架的主体结构分为五个部分: 它还有两个可以自定义下载功能的 ...
- Python爬虫Scrapy框架入门(2)
本文是跟着大神博客,尝试从网站上爬一堆东西,一堆你懂得的东西 附上原创链接: http://www.cnblogs.com/qiyeboy/p/5428240.html 基本思路是,查看网页元素,填写 ...
- Python -- Scrapy 框架简单介绍(Scrapy 安装及项目创建)
Python -- Scrapy 框架简单介绍 最近在学习python 爬虫,先后了解学习urllib.urllib2.requests等,后来发现爬虫也有很多框架,而推荐学习最多就是Scrapy框架 ...
- Python学习---爬虫学习[scrapy框架初识]
Scrapy Scrapy是一个框架,可以帮助我们进行创建项目,运行项目,可以帮我们下载,解析网页,同时支持cookies和自定义其他功能. Scrapy是一个为了爬取网站数据,提取结构性数据而编写的 ...
- 爬虫基础(五)-----scrapy框架简介
---------------------------------------------------摆脱穷人思维 <五> :拓展自己的视野,适当做一些眼前''无用''的事情,防止进入只关 ...
- 5、爬虫系列之scrapy框架
一 scrapy框架简介 1 介绍 (1) 什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被集成了各种功能(高性能 ...
- 爬虫--Scrapy框架的基本使用
流程框架 安装Scrapy: (1)在pycharm里直接就可以进行安装Scrapy (2)若在conda里安装scrapy,需要进入cmd里输入指令conda install scrapy ...
- 爬了个爬(三)Scrapy框架
参考博客:武Sir Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓取 ...
随机推荐
- 爬虫-urllib3模块的使用
urllib3是一个功能强大,对SAP健全的 HTTP客户端,许多Python生态系统已经使用了urllib3. 一.安装 sudo pips install urllib3 二.创建PoolMana ...
- .NET 云原生架构师训练营(模块二 基础巩固 敏捷开发)--学习笔记
2.7.1 敏捷开发 敏捷介绍 敏捷的起源 敏捷软件开发宣言 敏捷开发十二原则 生命周期对比 敏捷开发的特点 敏捷的发展 敏捷的核心 敏捷的起源 2001年,17个老头子在一起一边滑雪,一边讨论工作, ...
- 【Spring】XML方式实现(无参构造 有参构造)和注解方式实现 IoC
文章目录 Spring IoC的实现方式 XML方式实现 通过无参构造方法来创建 1.编写一个User实体类 2.编写我们的spring文件 3.测试类 UserTest.java 4.测试结果 通过 ...
- leetcode 117. 填充每个节点的下一个右侧节点指针 II(二叉树,DFS)
题目链接 https://leetcode-cn.com/problems/populating-next-right-pointers-in-each-node-ii/ 题目大意 给定一个二叉树 s ...
- 手动验证MySQL Innodb RR级别加锁 需要注意的几个点
记录几个坑 优化器在表行数比较少的时候 会使用全表扫描,会造成全表所有的行加锁,所以需要使用force index 强制使用索引 来实现gap-lock(间隙锁)的应用 next-lock 加锁 会锁 ...
- IOC技术在前端项目中的应用
目录 背景 什么是IOC 如何实现一个IOC 第一步:实现一个容器 第二步:用好装饰器 第三步:使用容器 扩展和展望 最后 背景 前端发展至今已经过去30余年,前端应用领域在不断壮大的过程中,也变得越 ...
- 使用 tke-autoscaling-placeholder 实现秒级弹性伸缩
背景 当 TKE 集群配置了节点池并启用了弹性伸缩,在节点资源不够时可以触发节点的自动扩容 (自动买机器并加入集群),但这个扩容流程需要一定的时间才能完成,在一些流量突高的场景,这个扩容速度可能会显得 ...
- Redis 实战 —— 09. 实现任务队列、消息拉取和文件分发
任务队列 P133 通过将待执行任务的相关信息放入队列里面,并在之后对队列进行处理,可以推迟执行那些耗时对操作,这种将工作交给任务处理器来执行对做法被称为任务队列 (task queue) . P13 ...
- jQuery 勾选启用输入框
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- babel : 无法加载文件 C:\Users\win\AppData\Roaming\npm\babel.ps1,因为在此系统上禁止运行脚本。有关详细信息,请参阅 https:/ go.micros
babel报错:babel : 无法加载文件 C:\Users\win\AppData\Roaming\npm\babel.ps1,因为在此系统上禁止运行脚本.有关详细信息,请参阅 https:/ g ...