达梦产品技术支持培训-day6-DM性能诊断与优化
(本文只作为个人随笔用途,非官方文档,请勿作他用,谢谢)
1、DM8查询优化基本思路
1.1 操作系统性能诊断
linux常用系统监控命令
使用 top 命令查看cpu使用率
使用 iostat 命令查看磁盘I/O使用情况
使用 dstat 工具查看磁盘I/O使用情况
使用 free 命令查看内存使用情况
使用 nmon 工具监控系统一段时间的整体情况
使用 perf top 命令查看系统热点情况
top 主要关注DMserver 的CPU使用率,要分user CPU还是sys CPU,当user CPU高时认为工作比较好,当sys CPU高时,认为有问题。
iostat查看各个设备的状态,dstat查看服务器整体的情况
free -m/-g ,一般情况下认为cash和free都是可使用的内存,但是有些机器大部分内存都进了cash,则认为这是对数据库性能是不友好的,会产生性能下降的问题。还有要关注swap分区有没有使用,一旦使用了swap分区那么性能也会下降。
|
例如有一个密集交易型数据库服务器配置如下: CPU:4路8核 内存:256G 磁盘阵列:1T |
||||
|
参数名 |
含义 |
优化建议 |
默认值 |
建议值 |
|
MEMORY_POOL |
公共内存池,单位为M。 |
高并发时应调大,避免频繁向OS申请内存 |
80 |
2048 |
|
N_MEM_POOLS |
将公共内存池分片,减少并发访问冲突,单位为个。 |
|
4 |
4 |
|
BUFFER |
数据缓冲区,单位为M。 |
如果数据量小于内存,则设置为数据量大小;否则设置为总内存的2/3比较合适 |
1000 |
120000 |
|
BUFFER_POOLS |
BUFFER的分区数,一般配置为质数,取值范围为1~500,当MAX_BUFFER>BUFFER时,动态扩展的缓冲区不参与分区 |
并发较大的系统需要配置这个参数,减少数据缓冲区并发冲突,建议BUFFER=MAX_BUFFER |
1 |
101 |
|
MAX_BUFFER |
数据缓冲区扩展最大值 |
建议配置成=BUFFER |
1000 |
120000 |
|
RECYCLE |
用于缓冲临时表空间,单位为M |
高并发或大量使用with、临时表、排序等应该调大点 |
64 |
5000 |
|
SORT_BUF_SIZE |
排序缓存区,单位M |
建索引时调大点,平时默认 |
2 |
32 |
|
CACHE_POOL_SIZE |
用于缓存SQL、执行计划、结果集等 |
一般配置为1000M~4000M |
10 |
1024 |
|
DICT_BUF_SIZE |
数据字典缓存区,单位M |
用于缓存数据字典,默认5M,系统中对象个数较多时适当加大 |
5 |
256/512 |
|
HJ_BUF_GLOBAL_SIZE |
哈希连接使用的内存空间上限,单位M |
高并发、hash操作多应调大 |
500 |
5000 |
|
HJ_BUF_SIZE |
单个哈希连接使用的内存 |
有大表的hash连接应调大 |
50 |
500 |
|
HAGR_BUF_GLOBAL_SIZE |
聚集操作使用的内存上限,单位M |
高并发、大量的聚集操作如sum等应调大 |
500 |
5000 |
|
HAGR_BUF_SIZE |
单个聚集操作使用的内存 |
有大表的hash分组应调大 |
50 |
500 |
|
WORKER_THREADS |
工作线程的个数 |
建议设置为cpu核算或其两倍 1~64 |
4 |
32 |
|
ENABLE_MONITOR |
数据库系统监控的级别 |
性能优化时设置为3,运行时设为2 |
2 |
2或者3 |
|
OLAP_FLAG |
启用联机分析处理,0:不启用;1:启用;2: 不启用,同时倾向于使用索引范围扫描 |
联机交易系统建议设置为2,联机分析系统建议设置为1 |
0 |
2 |
|
OPTIMIZER_MODE |
优化器计划探测模式。设置为1时,采用了左深树方式进行探测,设置为0时,则采用的是卡特兰树方式进行探测 |
2016年以后的版本建议设置为1,采用新优化器 |
0 |
1 |
数据库内存分为两个部分
BUFFER 数据页 -- 磁盘读出的内容在内存的一个副本
MEMORY_POOL 运行时内存--- 计算的时候需要消耗的内存
CACHE_POOL SIZE 执行计划、SQL语句、结果集、PACKAGE信息
RECYLE 临时表 TEMP.DBF RECYCLE
CREATE #
SORT\ HASH JOIN \HAGR MTAB
TEMP.DBF RECYLE 写不下写DBF,就可能导致TEMP.DBF扩展
表格中没有RECYCLE_POOLS 质数 100左右
DICT BUF SIZE select * from v$db_cache;
HJ 和HAGR
HASH JOIN 和HASH AGR
HJ_BLK_BUF_SIZE 每次要内存的时候申请多少
HJ_BUF_SIZE 一个HASH JOIN 操作,最多使用多少内存
HJ_BUF_GLOBAL_SIZE 表示数据库一共可使用多少内存进行HJ操作
数据库会话监控
--查询活动会话数
select count(*) from v$sessions where state='ACTIVE'; --已执行超过2秒的活动SQL
select * from (
SELECT sess_id,sql_text,datediff(ss,last_send_time,sysdate) Y_EXETIME,
SF_GET_SESSION_SQL(SESS_ID) fullsql,clnt_ip
FROM V$SESSIONS WHERE STATE='ACTIVE')
where Y_EXETIME>=2; --锁查询
select o.name,l.* from v$lock l,sysobjects o where l.table_id=o.id and blocked=1 --阻塞查询
with locks as(
select o.name,l.*,s.sess_id,s.sql_text,s.clnt_ip,s.last_send_time from v$lock l,sysobjects o,v$sessions s
where l.table_id=o.id and l.trx_id=s.trx_id ),
lock_tr as ( select trx_id wt_trxid,row_idx blk_trxid from locks where blocked=1),
res as( select sysdate stattime,t1.name,t1.sess_id wt_sessid,s.wt_trxid,
t2.sess_id blk_sessid,s.blk_trxid,t2.clnt_ip,SF_GET_SESSION_SQL(t1.sess_id) fulsql,
datediff(ss,t1.last_send_time,sysdate) ss,t1.sql_text wt_sql from lock_tr s,locks t1,locks t2
where t1.ltype='OBJECT' and t1.table_id<>0 and t2.ltype='OBJECT' and t2.table_id<>0
and s.wt_trxid=t1.trx_id and s.blk_trxid=t2.trx_id)
select distinct wt_sql,clnt_ip,ss,wt_trxid,blk_trxid from res;
1.3、SQL优化
数据库的性能问题最终都要涉及到SQL优化
标准SQL问题处理流程:生成日志 -> 日志入库 -> 分析SQL -> 优化方案
LOGCCOMIT 通过SVR_LOG 参数动态开关
--设置SQL过滤规则,只记录必要的SQL,生产环境不要设成1
-- 2 只记录DML语句 3 只记录DDL语句 22 记录绑定参数的语句
-- 25 记录SQL语句和它的执行时间 28 记录SQL语句绑定的参数信息 SELECT SF_SET_SYSTEM_PARA_VALUE('SQL_TRACE_MASK','2:3:22:25:28',0,1); --同步日志会严重影响系统效率,生产环境必须设置为异步日志
SELECT SF_SET_SYSTEM_PARA_VALUE('SVR_LOG_ASYNC_FLUSH',1,0,1); --下面这个语句设置只记录执行时间超过200ms的语句,建议拿全部
SELECT SF_SET_SYSTEM_PARA_VALUE('SVR_LOG_MIN_EXEC_TIME',200,0,1); --下面的语句查看设置是否生效
SELECT * FROM V$DM_INI where para_name='SVR_LOG_ASYNC_FLUSH';SELECT * FROM V$DM_INI where para_name='SQL_TRACE_MASK';SELECT * FROM V$DM_INI where para_name='SVR_LOG_MIN_EXEC_TIME'; --开启SQL日志:
SP_SET_PARA_VALUE(1, 'SVR_LOG', 1);
--关闭SQL日志:
SP_SET_PARA_VALUE(1, 'SVR_LOG', 0);
SQL分析流程
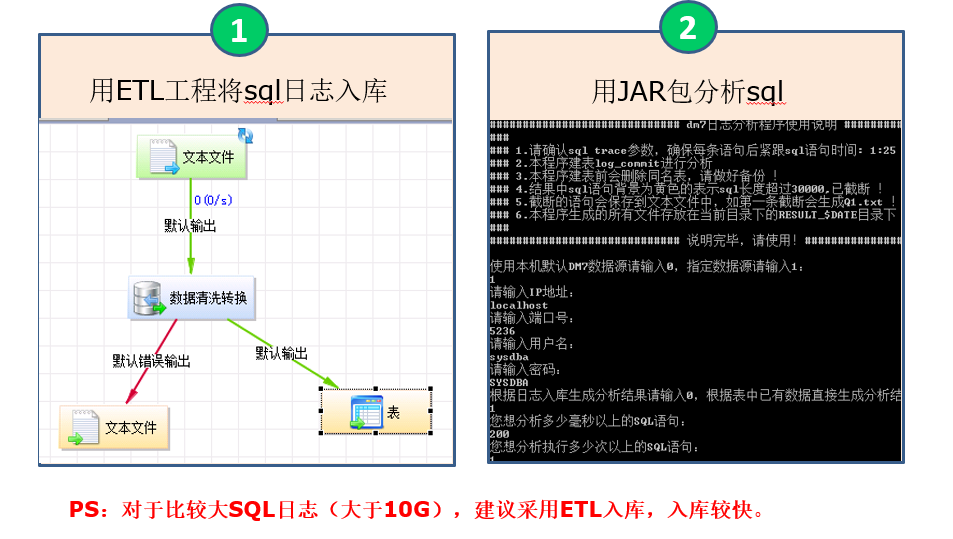
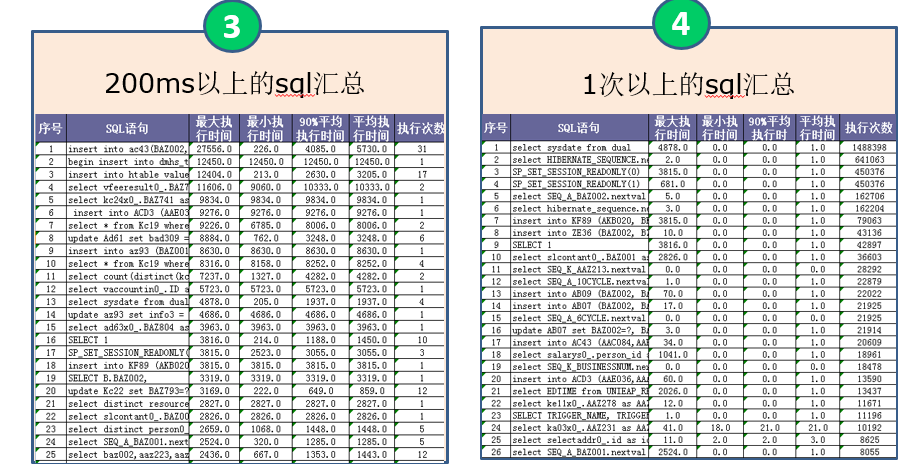
优化目标:
1、并发非常高:SQL特征:数量很少(5%),但是执行频率非常高,甚至达到每秒上百次,只要一慢,系统很可能瘫痪。优化级别:最优先处理。
2、并发一般:SQL特征:占大多数(80%),如果有慢的,对系统整体稳定性影响不大,但是会造成局部的某些操作慢。优化级别:次优先处理。
3、并发很少但特别慢:SQL特征:数量少(15%),往往是很复杂的查询,可能一天就执行几次,对系统整体影响不大,但是优化难度很大。优化级别:最后处理。
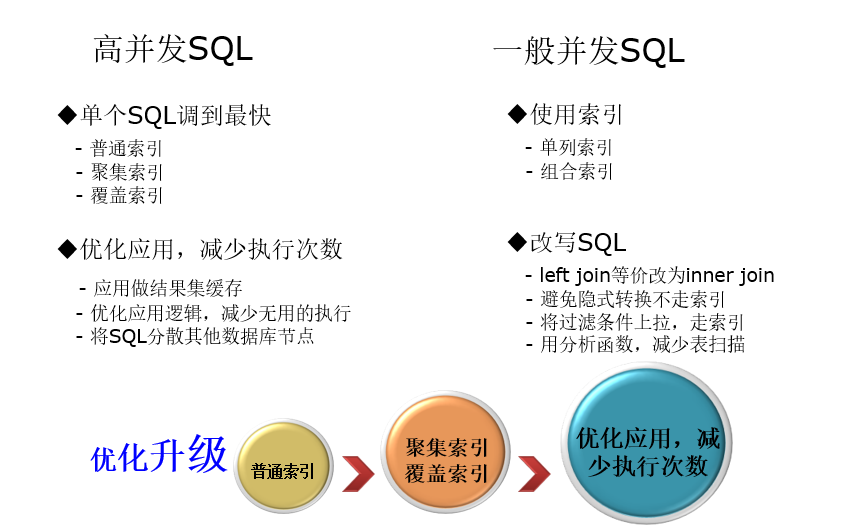
优化思路
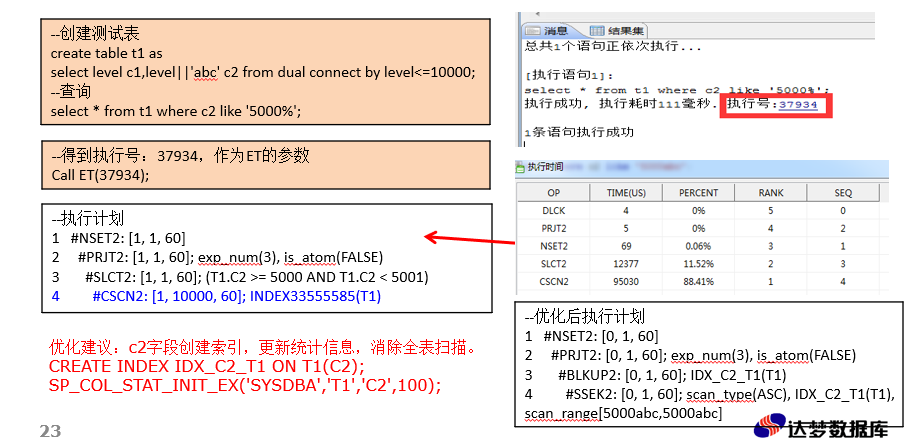
性能优化工具ET
ENABLE_MONITOR=1
MONITOR_SQL_EXEC=1
MONITOR_TIME=1
时,ET才能使用。
MONITOR_SQL_EXEC, 生产上不要全局打开
V$SQL_NODE_HISTORY
这个参数是可以会话级打开的,
CALL SF_SET_SESSION_PARA_VALUE('PARAM_NAME',PARA_VALUE);
阻塞与死锁
A B C D
SESS 更新 A B C D
SESS 更新 D C B A
所以业务上进行更新操作一定要保持固定顺序。
系统型阻塞
配置调度作业
调度作业由 TASK_THREAD 线程做,TASK_THREAD,还负责我们的PURGE 操作(DELETE 了一条数据,真实的腾出物理空间),如果我的调度作业很多,而且执行时间很长,TASK_THREAD是有限的,全部被调度作业占据,那么这个时候明显的 PURGE 动作就被阻塞。
PURGE操作:delete 时只是把数据打上不可见标识,purge操作讲这些数据从数据文件删除
通过 select * from v$task_queue 查询是否有系统性阻塞的作业。
如果已经发生这种情况,那么只能等操作完成或者重启,若想要防止这种阻塞则 TASK THREAD 放大 INI 参数。
2、执行计划详解
执行计划:一条SQL语句在DM数据库中执行过程或访问路径的描述
可通过 explain 关键字查看执行计划,也可以通过DM管理工具查看
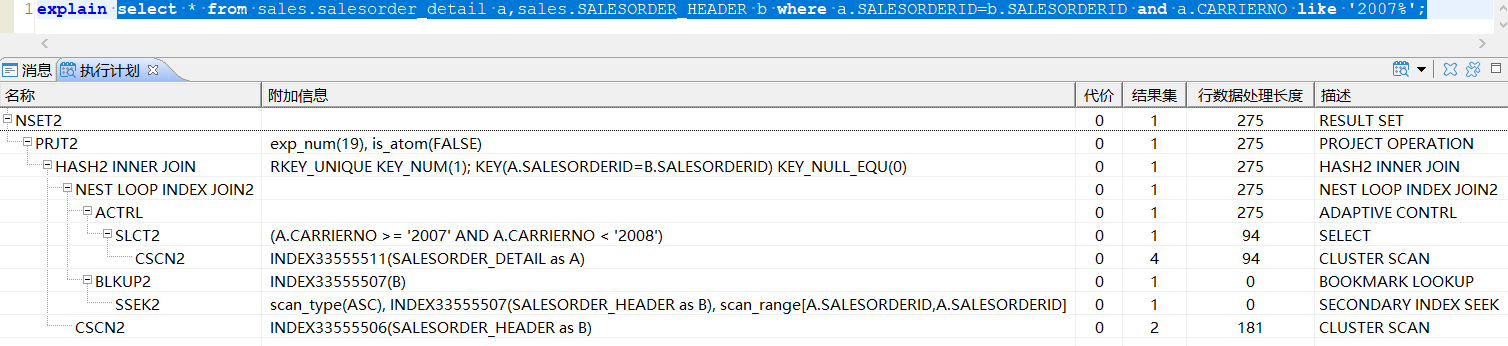
EXPLAIN SELECT * FROM T1;
1 #NSET2: [1, 10000, 156]
2 #PRJT2: [1, 10000, 156]; exp_num(5), is_atom(FALSE)
3 #CSCN2: [1, 10000, 156]; INDEX33556710(T1)
--用于结果集收集的操作符,一般是查询计划的顶层节点
EXPLAIN SELECT * FROM T1;
1 #NSET2: [1, 10000, 156]
2 #PRJT2: [1, 10000, 156]; exp_num(5), is_atom(FALSE)
3 #CSCN2: [1, 10000, 156]; INDEX33556710(T1)
--关系的“投影”(project)运算,用于选择表达式项的计算;广泛用于查询,排序,函数索引创建等
EXPLAIN SELECT * FROM T1 WHERE C2='TEST';
1 #NSET2: [1, 250, 156]
2 #PRJT2: [1, 250, 156]; exp_num(5), is_atom(FALSE)
3 #SLCT2: [1, 250, 156]; T1.C2 = TEST
4 #CSCN2: [1, 10000, 156]; INDEX33556717(T1)
--关系的“选择” 运算,用于查询条件的过滤。
EXPLAIN SELECT COUNT(*) FROM T1 WHERE C1 = 10;
1 #NSET2: [0, 1, 4]
2 #PRJT2: [0, 1, 4]; exp_num(1), is_atom(FALSE)
3 #AAGR2: [0, 1, 4]; grp_num(0), sfun_num(1)
4 #SSEK2: [0, 1, 4]; scan_type(ASC), IDX_C1_T1(T1), scan_range[10,10]
--用于没有group by的count sum age max min等聚集函数的计算
EXPLAIN SELECT COUNT(*) FROM T1;
1 #NSET2: [1, 1, 0]
2 #PRJT2: [1, 1, 0]; exp_num(1), is_atom(FALSE)
3 #FAGR2: [1, 1, 0]; sfun_num(1), EXPLAIN SELECT MAX(C1) FROM T1;
1 #NSET2: [1, 1, 0]
2 #PRJT2: [1, 1, 0]; exp_num(1), is_atom(FALSE)
3 #FAGR2: [1, 1, 0]; sfun_num(1),
--用于没有过滤条件时从表或索引快速获取MAX/MIN/COUNT值;DM数据库是世界上单表不带过滤条件下取COUNT值最快的数据库
EXPLAIN SELECT COUNT(*) FROM T1 GROUP BY C2;
1 #NSET2: [1, 100, 48]
2 #PRJT2: [1, 100, 48]; exp_num(1), is_atom(FALSE)
3 #HAGR2: [1, 100, 48]; grp_num(1), sfun_num(1)
4 #CSCN2: [1, 10000, 48]; INDEX33556717(T1)
--用于分组列没有索引只能走全表扫描的分组聚集,C2列没有创建索引
EXPLAIN SELECT COUNT(*) FROM T1 GROUP BY C1;
1 #NSET2: [1, 100, 4]
2 #PRJT2: [1, 100, 4]; exp_num(1), is_atom(FALSE)
3 #SAGR2: [1, 100, 4]; grp_num(1), sfun_num(1)
4 #SSCN: [1, 10000, 4]; IDX_C1_T1(T1)
--用于分组列是有序的情况下,可以使用流分组聚集,C1上已经创建了索引,SAGR2性能优于HAGR2
EXPLAIN SELECT * FROM T1 WHERE C1=10;
1 #NSET2: [0, 1, 156]
2 #PRJT2: [0, 1, 156]; exp_num(5), is_atom(FALSE)
3 #BLKUP2: [0, 1, 156]; IDX_C1_T1(T1)
4 #SSEK2: [0, 1, 156]; scan_type(ASC), IDX_C1_T1(T1), scan_range[10,10]
--先使用2级别索引定位,再根据表的主键、聚集索引、rowid等信息定位数据行。
EXPLAIN SELECT * FROM T1;
1 #NSET2: [1, 10000, 156]
2 #PRJT2: [1, 10000, 156]; exp_num(5), is_atom(FALSE)
3 #CSCN2: [1, 10000, 156]; INDEX33556710(T1)
--CSCN2是CLUSTER INDEX SCAN的缩写即通过聚集索引扫描全表,全表扫描是最简单的查询,如果没有选择谓词,或者没有索引可以利用,则系统一般只能做全表扫描。在一个高并发的系统中应尽量避免全表扫描
EXPLAIN SELECT * FROM T1 WHERE C1=10;
1 #NSET2: [0, 1, 156]
2 #PRJT2: [0, 1, 156]; exp_num(5), is_atom(FALSE)
3 #BLKUP2: [0, 1, 156]; IDX_C1_T1(T1)
4 #SSEK2: [0, 1, 156]; scan_type(ASC), IDX_C1_T1(T1), scan_range[10,10] CREATE CLUSTER INDEX IDX_C1_T2 ON T2(C1);
EXPLAIN SELECT * FROM T2 WHERE C1=10;
1 #NSET2: [0, 250, 156]
2 #PRJT2: [0, 250, 156]; exp_num(5), is_atom(FALSE)
3 #CSEK2: [0, 250, 156]; scan_type(ASC), IDX_C1_T2(T2), scan_range[10,10] CREATE INDEX IDX_C1_C2_T1 ON T1(C1,C2);
EXPLAIN SELECT C1,C2 FROM T1;
1 #NSET2: [1, 10000, 60]
2 #PRJT2: [1, 10000, 60]; exp_num(3), is_atom(FALSE)
3 #SSCN: [1, 10000, 60]; IDX_C1_C2_T1(T1)
--SSEK2是二级索引扫描即先扫描索引,再通过主键、聚集索引、ROWID等信息去扫描表 CSEK2是聚集索引扫描只需要扫描索引,不需要扫描表 SSCN是索引全扫描,不需要扫描表
连接
主要有四种连接方式。
--nest loop
--直接做笛卡尔积,然后过滤连接条件
select /*+PHC_MODE_ENFORCE(1)*/* from sysobjects a, sysobjects b where a.id = b.id --nset loop with index
select /*+PHC_MODE_ENFORCE(2) ORDER(B A)*/A.*,B.ID from sysobjects a, sysobjects b where a.id = b.id ORDER BY B.ID --hash join
select /*+PHC_MODE_ENFORCE(4)*/* from sysobjects a, sysobjects b where a.id = b.id
select /*+PHC_MODE_ENFORCE(4) ORDER(A B)*/A.*,B.ID from sysobjects a, sysobjects b where a.id = b.id ORDER BY B.NAME --merge
select /*+ENABLE_HASH_JOIN(0) ENABLE_INDEX_JOIN(0)*/* from sysobjects a, sysobjects b where a.id = b.id
查询转换

--构造测试环境
CREATE TABLE TEST_TJ(ID INT,AGE INT);
BEGIN FOR I IN 1..100000 LOOP
INSERT INTO TEST_TJ VALUES(MOD(I,9700),TRUNC(RAND * 120));
END LOOP;
COMMIT;
END;
--创建系统包
SP_CREATE_SYSTEM_PACKAGES(1);
--更新单列统计信息
DBMS_STATS.GATHER_TABLE_STATS(USER, 'TEST_TJ',null,100,false, 'FOR ALL COLUMNS SIZE AUTO'); --更新所有列
SP_COL_STAT_INIT_EX(USER,'TEST_TJ','ID',100); --更新单列 --查看统计信息:频率直方图
DBMS_STATS.COLUMN_STATS_SHOW(USER, 'TEST_TJ','AGE');
--1.类型:频率直方图
--2.ENDPOINT_VALUE样本值: 1
--3.ENDPOINT_HEIGHT 样本值的个数:819
SELECT COUNT(*) FROM TEST_TJ WHERE AGE=1; --819

--查看统计信息:等高直方图
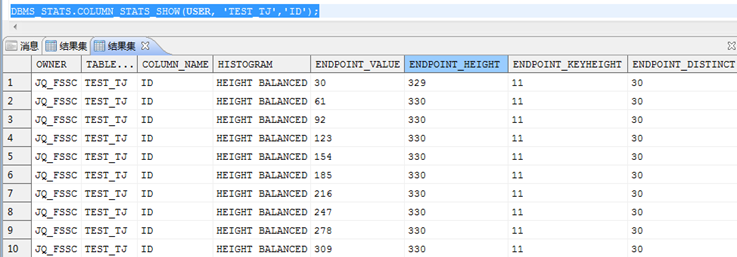
DBMS_STATS.COLUMN_STATS_SHOW(USER, 'TEST_TJ','ID');
--解读统计信息
--1.类型:等高直方图
--2.ENDPOINT_VALUE样本值: 30
--3.ENDPOINT_HEIGHT小于样本值大于前一个样本值的个数:329
SELECT COUNT(*) FROM TEST_TJ WHERE ID<30; --329
--4.ENDPOINT_KEYGHT样本值的个数:11
SELECT COUNT(*) FROM TEST_TJ WHERE ID=30; --11
--5.ENDPOINT_DISTINCT小于样本值大于前一个样本值之间不同样本的个数: 30
SELECT COUNT(DISTINCT ID) FROM TEST_TJ WHERE ID<30; --30
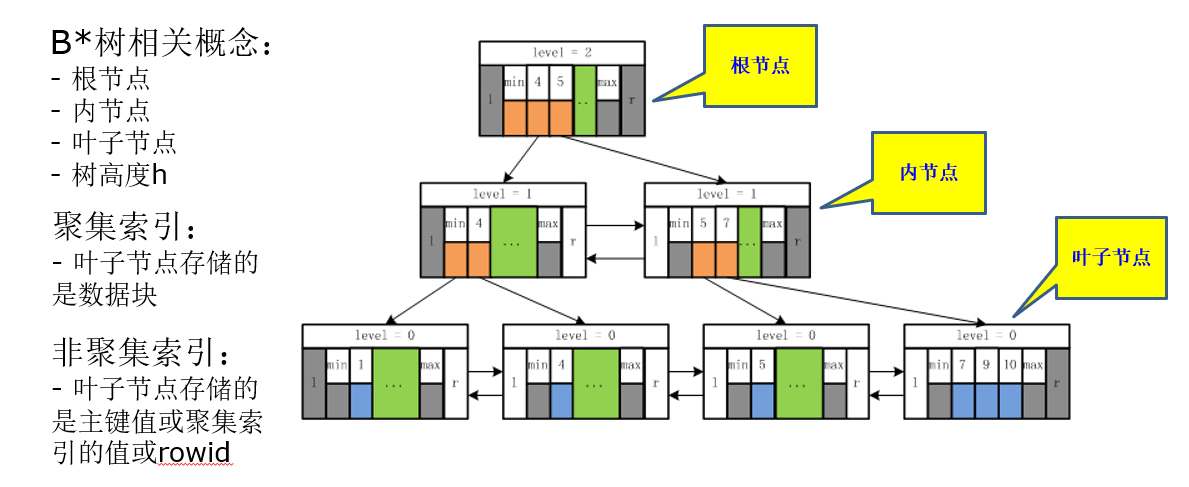
3.2、索引的存储结构
--创建表 插入10万条数据
CREATE TABLE TEST_INDEX(ID INT,AGE INT);
BEGIN
FOR I IN 1..100000 LOOP
INSERT INTO TEST_INDEX VALUES(MOD(I,9700),TRUNC(RAND * 120));
END LOOP;
COMMIT;
END;
--创建索引
CREATE INDEX IDX_ID_TEST_INDEX ON TEST_INDEX(ID);
CREATE INDEX IDX_AGE_TEST_INDEX ON TEST_INDEX(AGE);
--更新列统计信息
SP_COL_STAT_INIT_EX(USER,'TEST_INDEX','ID',100);
SP_COL_STAT_INIT_EX(USER,'TEST_INDEX','AGE',100); --返回少部分行 走索引
EXPLAIN SELECT * FROM TEST_INDEX WHERE ID=100;
1 #NSET2: [0, 11, 16]
2 #PRJT2: [0, 11, 16]; exp_num(3), is_atom(FALSE)
3 #BLKUP2: [0, 11, 16]; IDX_ID_TEST_INDEX(TEST_INDEX)
#SSEK2: [0, 11, 16]; scan_type(ASC), IDX_ID_TEST_INDEX(TEST_INDEX), scan_range[100,100] --返回大部分行 走全表扫描
EXPLAIN SELECT * FROM TEST_INDEX WHERE AGE>1 ;
1 #NSET2: [11, 98374, 16]
2 #PRJT2: [11, 98374, 16]; exp_num(3), is_atom(FALSE)
3 #SLCT2: [11, 98374, 16]; TEST_INDEX.AGE > 1
4 #CSCN2: [11, 100000, 16]; INDEX33556678(TEST_INDEX)
--只需要扫描索引 不用扫描表
EXPLAIN SELECT TOP 10 * FROM TEST_INDEX ORDER BY AGE ;
1 #NSET2: [10, 10, 16]
2 #PRJT2: [10, 10, 16]; exp_num(3), is_atom(FALSE)
3 #TOPN2: [10, 10, 16]; top_num(10)
4 #BLKUP2: [10, 100000, 16]; IDX_AGE_TEST_INDEX(TEST_INDEX)
5 #SSCN: [10, 100000, 16]; IDX_AGE_TEST_INDEX(TEST_INDEX) --只需要扫描索引 不用扫描表
EXPLAIN SELECT COUNT(DISTINCT AGE) FROM TEST_INDEX;
1 #NSET2: [17, 1, 4]
2 #PRJT2: [17, 1, 4]; exp_num(1), is_atom(FALSE)
3 #AAGR2: [17, 1, 4]; grp_num(0), sfun_num(1)
4 #SSCN: [10, 100000, 4]; IDX_AGE_TEST_INDEX(TEST_INDEX)
--创建测试表
create table tab(c1 int,c2 char(1),c3 char(1),c4 int);
--构造测试数据
insert into tab
select level c1,chr(mod(level,27)+65) c2,chr(mod(level,27)+65) c3,level c4
from dual
connect by level<=10000; --待优化语句如下:
SELECT * FROM TAB WHERE C1 BETWEEN 10 AND 20 AND C2 ='A' AND C3='B'; --创建索引
CREATE INDEX IDX_C1_C2_C3_TAB ON TAB(C1,C2,C3);
CREATE INDEX IDX_C2_C3_C1_TAB ON TAB(C2,C3,C1); --查看执行计划
EXPLAIN SELECT * FROM TAB WHERE C1 BETWEEN 10 AND 20 AND C2 ='A' AND C3='B';
1 #NSET2: [0, 1, 112]
2 #PRJT2: [0, 1, 112]; exp_num(5), is_atom(FALSE)
3 #BLKUP2: [0, 1, 112]; IDX_C2_C3_C1_TAB(TAB)
4 #SSEK2: [0, 1, 112]; scan_type(ASC),IDX_C2_C3_C1_TAB(TAB),scan_range[(A,B,10),(A,B,20)] --查看执行计划 可以看出这个索引只能利用C1列
EXPLAIN SELECT * FROM TAB INDEX IDX_C1_C2_C3_TAB TT WHERE C1 BETWEEN 10 AND 20 AND C2 ='A' AND C3='B'; 1 #NSET2: [0, 1, 112]
2 #PRJT2: [0, 1, 112]; exp_num(5), is_atom(FALSE)
3 #SLCT2: [0, 1, 112]; (TT.C2 = A AND TT.C3 = B)
4 #BLKUP2: [0, 25, 112]; IDX_C1_C2_C3_TAB(TT)
5 #SSEK2: [0, 25, 112]; scan_type(ASC), IDX_C1_C2_C3_TAB(TAB as TT), scan_range[(10,min,min),(20,max,max))
3.4、关于不走索引的神话
1、条件列不是索引的首列
--创建表
CREATE TABLE TAB1(C1 INT,C2 CHAR(1),C3 CHAR(1),C4 INT);
--构造测试数据
INSERT INTO TAB1
SELECT LEVEL C1,CHR(MOD(LEVEL,27)+65) C2,CHR(MOD(LEVEL,27)+65) C3,LEVEL C4
FROM DUAL
CONNECT BY LEVEL<=10000;
COMMIT;
CREATE INDEX IDX_C1_C2 ON TAB1(C1,C2);
EXPLAIN SELECT * FROM TAB1 WHERE C2='A'; 1 #NSET2: [1, 250, 112]
2 #PRJT2: [1, 250, 112]; exp_num(5), is_atom(FALSE)
3 #SLCT2: [1, 250, 112]; TAB1.C2 = A
4 #CSCN2: [1, 10000, 112]; INDEX33556684(TAB1)
2、条件列上有函数或者计算
--正常情况
EXPLAIN SELECT * FROM TAB1 WHERE C1 =123;
1 #NSET2: [0, 1, 112]
2 #PRJT2: [0, 1, 112]; exp_num(5), is_atom(FALSE)
3 #BLKUP2: [0, 1, 112]; IDX_C1_C2_C3_TAB1(TAB1)
4 #SSEK2: [0, 1, 112]; scan_type(ASC), IDX_C1_C2_C3_TAB1(TAB1), scan_range[(123,min,min),(123,max,max)) --条件列上有函数
EXPLAIN SELECT * FROM TAB1 WHERE abs(C1) =123;
1 #NSET2: [137, 25000, 112]
2 #PRJT2: [137, 25000, 112]; exp_num(5), is_atom(FALSE)
3 #SLCT2: [137, 25000, 112]; exp11 = var1
4 #CSCN2: [137, 1000000, 112]; INDEX33556691(TAB1) --条件列上有计算EXPLAIN SELECT * FROM TAB1 WHERE C1-1 =123;
1 #NSET2: [137, 25000, 112]
2 #PRJT2: [137, 25000, 112]; exp_num(5), is_atom(FALSE)
3 #SLCT2: [137, 25000, 112]; TAB1.C1-1 = 123
4 #CSCN2: [137, 1000000, 112]; INDEX33556691(TAB1) EXPLAIN SELECT * FROM TAB1 WHERE C1 =123+1
1 #NSET2: [0, 1, 112]
2 #PRJT2: [0, 1, 112]; exp_num(5), is_atom(FALSE)
3 #BLKUP2: [0, 1, 112]; IDX_C1_C2_C3_TAB1(TAB1)
4 #SSEK2: [0, 1, 112]; scan_type(ASC), IDX_C1_C2_C3_TAB1(TAB1), scan_range[(123+1,min,min),(123+1,max,max))
3、存在隐式转换
--对条件列C1做了隐式的类型转换,将int类型转换为char类型
EXPLAIN SELECT * FROM TAB1 WHERE C1='1234567890'
1 #NSET2: [137, 25000, 112]
2 #PRJT2: [137, 25000, 112]; exp_num(5), is_atom(FALSE)
3 #SLCT2: [137, 25000, 112]; exp_cast(TAB1.C1) = var1
4 #CSCN2: [137, 1000000, 112]; INDEX33556691(TAB1) --后面的常量小于10位,优化器对常量做了类型转换,这时可以走索引
EXPLAIN SELECT * FROM TAB1 WHERE C1='123456789'
1 #NSET2: [0, 1, 112]
2 #PRJT2: [0, 1, 112]; exp_num(5), is_atom(FALSE)
3 #BLKUP2: [0, 1, 112]; IDX_C1_C2_C3_TAB1(TAB1)
4 #SSEK2: [0, 1, 112]; scan_type(ASC), IDX_C1_C2_C3_TAB1(TAB1), scan_range[(exp_cast(123456789),min,min),(exp_cast(123456789),max,max)) --写SQL的时候数据类型最好匹配,不要让优化器来做这种隐式的类型转换
EXPLAIN SELECT * FROM TAB1 WHERE C1=1234567890
1 #NSET2: [0, 1, 112]
2 #PRJT2: [0, 1, 112]; exp_num(5), is_atom(FALSE)
3 #BLKUP2: [0, 1, 112]; IDX_C1_C2_C3_TAB1(TAB1)
4 #SSEK2: [0, 1, 112]; scan_type(ASC), IDX_C1_C2_C3_TAB1(TAB1), scan_range[(1234567890,min,min),(1234567890,max,max))
4、如果走索引会更慢
--创建测试表
CREATE TABLE TX(ID INT, NAME VARCHAR(100));
--插入数据
BEGIN
FOR X IN 1 .. 100000 LOOP
INSERT INTO TX VALUES(X, 'HELLO');
END LOOP;
COMMIT;
END;
--创建索引 更新统计信息
CREATE INDEX TXL01 ON TX(ID);
SP_INDEX_STAT_INIT(USER,'TXL01'); --返回记录较多 不走索引
EXPLAIN SELECT * FROM TX WHERE ID <50000;
1 #NSET2: [12, 49998, 60]
2 #PRJT2: [12, 49998, 60]; exp_num(3), is_atom(FALSE)
3 #SLCT2: [12, 49998, 60]; TX.ID < 50000
4 #CSCN2: [12, 100000, 60]; INDEX33556697(TX)
--返回记录较少 走索引
EXPLAIN SELECT * FROM TX WHERE ID <500;
1 #NSET2: [8, 498, 60]
2 #PRJT2: [8, 498, 60]; exp_num(3), is_atom(FALSE)
3 #BLKUP2: [8, 498, 60]; TXL01(TX)
4 #SSEK2: [8, 498, 60]; scan_type(ASC), TXL01(TX), scan_range(null2,500)
5、没有更新统计信息
--创建测试表
CREATE TABLE TY(ID INT, NAME VARCHAR(100));
--插入数据
BEGIN
FOR X IN 1 .. 100000 LOOP
INSERT INTO TY VALUES(X, 'HELLO');
END LOOP;
COMMIT;
END;
--创建索引
CREATE INDEX TYL01 ON TY(ID); --未更新统计信息
EXPLAIN SELECT * FROM TY WHERE ID <500;
1 #NSET2: [12, 5000, 60]
2 #PRJT2: [12, 5000, 60]; exp_num(3), is_atom(FALSE)
3 #SLCT2: [12, 5000, 60]; TY.ID < 500
4 #CSCN2: [12, 100000, 60]; INDEX33556699(TY) --更新统计信息
SP_INDEX_STAT_INIT(USER,'TYL01');
EXPLAIN SELECT * FROM TY WHERE ID <500;
1 #NSET2: [8, 498, 60]
2 #PRJT2: [8, 498, 60]; exp_num(3), is_atom(FALSE)
3 #BLKUP2: [8, 498, 60]; TYL01(TY)
4 #SSEK2: [8, 498, 60]; scan_type(ASC), TYL01(TY), scan_range(null2,500)
3.5、索引对DML语句的影响
达梦产品技术支持培训-day6-DM性能诊断与优化的更多相关文章
- 达梦产品技术支持培训-day7-DM8数据库备份与还原-原理
(本文部分内容摘自DM产品技术支持培训文档,如需要更详细的文档,请查询官方操作手册,谢谢) 1.DM8备份还原简介 1.1.基本概念 (1)表空间与数据文件 ▷ DM8表空间类型: ▷ SYSTEM ...
- 达梦产品技术支持培训-day8-DM8数据库备份与还原-实操
1.DM8的备份还原方法 Disql 工具:联机数据备份与还原,包括库备份.表空间备份与还原.表备份与还原: DMRMAN 工具:脱机数据库备份还原与恢复: 客户端工具 MANAGER和CONSOL ...
- 达梦产品技术支持培训-day2-DM8常用SQL
(本文只作为随笔或个人笔记,非官方文档,请勿作他用,谢谢) DM8数据库的SQL兼容性很高,和Oracle差距不大,以下是个人认为比较关键的部分. 1.关键动词 create --新建 drop -- ...
- 达梦产品技术支持-DM8-数据库安装
(该文档只适合个人环境搭建,未涉及到数据库的各种参数配置,未涉及到数据库规划,若需要企业环境搭建请咨询专业人员) 基于Windows的安装 windows下安装是图形化界面,与linux下的图形化界面 ...
- .NETCore 访问国产达梦数据库
前言 武汉达梦数据库有限公司成立于2000年,为中国电子信息产业集团(CEC)旗下基础软件企业,专业从事数据库管理系统的研发.销售与服务,同时可为用户提供大数据平台架构咨询.数据技术方案规划.产品部署 ...
- [开源] .Net 使用 ORM 访问 达梦数据库
前言 武汉达梦数据库有限公司成立于2000年,为中国电子信息产业集团(CEC)旗下基础软件企业,专业从事数据库管理系统的研发.销售与服务,同时可为用户提供大数据平台架构咨询.数据技术方案规划.产品部署 ...
- 达梦数据库产品支持技术学习分享_Week2
本周主要从以下几个方面进行本人对达梦数据库学习的分享,学习进度和学习情况因人而异,仅供参考. 一.文本命令行工具使用的方法(Disql和dmfldr) 二.数据库备份 三.定时作业功能 四.系统表和动 ...
- 达梦数据库产品支持技术学习分享_Week1
本周主要从以下几个方面进行本人对达梦数据库学习的分享,学习进度和学习情况因人而异,仅供参考. 一.达梦数据库的体系架构 二.达梦数据库的安装 三.达梦数据库的数据类型 四.达梦数据库的DDL.DML. ...
- mybatis plus 支持达梦DM 数据库啦
最近由于公司项目需要使用DM数据库,现在就官方源码修改了,完美支持达梦数据库的代码生成器.官方说的v3.0.RELEASE版本支持达梦数据库,不知道说的支持包括支持代码生成器么? 怀着兴奋的心情,兴高 ...
随机推荐
- playable
探索TimelinePlayableAPI,让Timeline为所欲为 https://blog.csdn.net/qq826364410/article/details/80534892 Playa ...
- cordova 环境配制和创建插件
环境配制 英文网站:http://cordova.apache.org/ 中文网站:http://cordova.axuer.com/ 安装Cordova Cordova的命令行运行在Node.js ...
- SpringCloud 服务负载均衡和调用 Ribbon、OpenFeign
1.Ribbon Spring Cloud Ribbon是基于Netflix Ribbon实现的-套客户端―负载均衡的工具. 简单的说,Ribbon是Netlix发布的开源项目,主要功能是提供客户端的 ...
- HDU - 6570 - Wave(暴力)
Avin is studying series. A series is called "wave" if the following conditions are satisfi ...
- 组件给App全局传值vue-bus的使用
npm安装 npm install vue-bus main.js引入 import VueBus from 'vue-bus' Vue.use(VueBus) 组件 getHouse(e){ thi ...
- Qt绘图学习(1)
paintEvent()被调用的时机;1.当窗口第一次被show()的时候,Qt程序会自动产生一个绘图事件,调用绘图事件:2.重新调整窗口部件大小的时候,系统也会产生一个绘制事件.3.当窗口部件被其他 ...
- Redis数据类型读写语法
---字符类型的用法(语法大小写不做限制)1.创建string字符串写:SET 列名 "键值"读:get 列名特性:可以包含任何数据,比如jpg图片或者序列化的对象,一个键最大能存 ...
- 01_Python基础知识梳理
1.计算机知识基础 1.计算机组成 计算机底层: 点子电路,计算机只能识别两个数 0 1 硬件: 处理器(CPU), 运行内存(RAM), 主板(总线设备), 外部存储设备(硬盘U盘等 ...
- vue父子组件状态同步的最佳方式
哈喽!大家好!我是木瓜太香,一位老牌儿前端工程师,平时我们在使用 vue 开发的时候,可能会遇到需要父组件与子组件某个状态需要同步的情况,通常这个是因为我们封装组件的时候有一个相同的状态外面要用,里面 ...
- python应用 曲线拟合 02
前情提要 CsI 闪烁体晶体+PD+前放输出信号满足: $U(t) = \frac{N_f\tau_p}{\tau_p-\tau_f} \left[ e^{-\frac{t}{\tau_p}}-e^{ ...