细说selenium的等待条件
selenium的显示等待
在进行UI自动化测试的时候,我们为了保持用例的稳定性,往往要设置显示等待,显示等待就是说明确的要等到某个元素的出现或者元素的某些条件出现,比如可点击、可见等条件,如果在规定的时间之内都没有找到,那么就会抛出Exception.
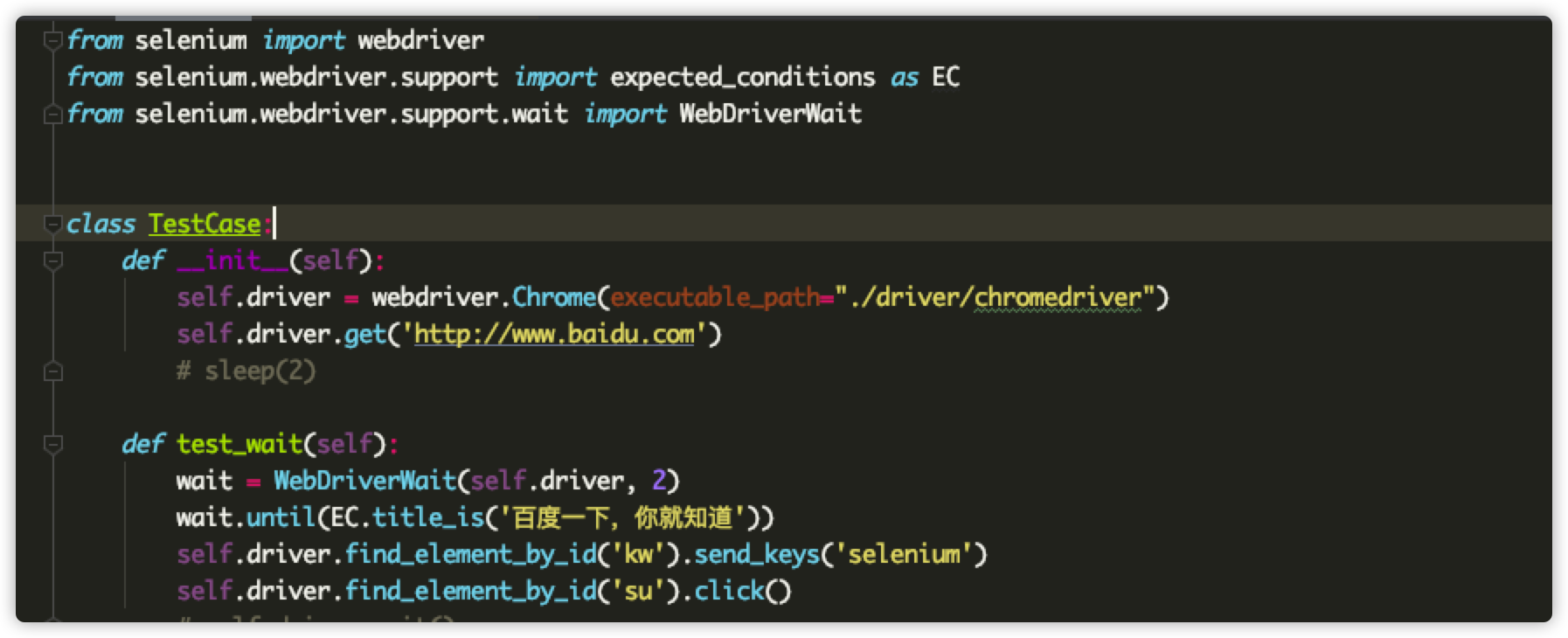
上面是我用selenium写的一个测试用例,展示了selenium中显示等待的使用方式,其中会使用到expected_conditions模块和WebDriverWait类,注意这里expected_conditions是一个py文件的文件名,也就是一个模块名,这个模块下面有很多的条件类,而我们用例中使用的title_is就是一个条件类。
WebDriverWait是一个类,这个类的作用就是根据一定的条件,不断的检查这个条件是否被满足了。WebDriverWait类只有两个方法,一个是until直到满足某个条件,另一个是until_not直到不满足某个条件。
class WebDriverWait(object):
def __init__(self, driver, timeout, poll_frequency=POLL_FREQUENCY, ignored_exceptions=None):
WebDriverWait有四个参数分别是, driver驱动, timeout超时时间, poll_frequency=POLL_FREQUENCY轮训时间,也就是去判断条件是否满足的时间间隔,默认是0.5秒, ignored_exceptions=None在等待的过程中需要忽略的异常,是一个可迭代的异常类集合,比如我们可以设置一个list,里面是[NoSuchElementException,NoSuchAttributeException,InvalidElementStateException....],默认情况下,是一个元组,只包含一个NoSuchElementException,因为只有元素出现,才能去判断条件是否满足,在不断轮训的过程中,肯定会发生NoSuchElementException,这个时候必须忽略掉这个异常,不然程序就会中断。
其中driver和timeout是毕传的位置参数,另外两个是选择传递的关键字参数,如果不传都有指定的默认值。
下面就进入我们今天的主题,selenium中的等待条件的讨论
等待条件
条件类的实现原理
在selenium.webdriver.support.expected_conditions这个模块里,存放着所有的等待条件,每个条件类的结构都是一样的一个__init__构造方法和一个__call__方法。
在python中,如果想把类型的对象当做函数来使用,那么就可以给这个类实现__call__方法,如下:
class TestCase:
def __init__(self):
self.driver = webdriver.Chrome(executable_path="./driver/chromedriver")
self.driver.get('http://www.baidu.com')
# sleep(2)
def __call__(self):
print(self.driver.title)
if __name__ == '__main__':
case = TestCase()
case()
case()对象的调用,就会执行__call__方法里面的逻辑打印当前页面的标题,我们取一个selenium的实现类:
class presence_of_element_located(object):
def __init__(self, locator):
self.locator = locator
def __call__(self, driver):
return _find_element(driver, self.locator)
这个条件类的意思是判断一个元素是否已经渲染到页面当中,在使用这个条件的时候需要先实例化,传入元素的定位,然后要进行判断的时候需要对实例对象进行调用并传入driver,对实例对象进行调用的时候就会执行__call__方法里的条件判断逻辑。
WebDriverWait是如何进行条件判断的
再回到文章开头看一下我们使用显示等待的代码:
wait = WebDriverWait(self.driver, 2)
wait.until(EC.title_is('百度一下,你就知道'))
先是实例化一个WebDriverWait对象,然后再调用until方法并且传递一个条件的实例对象,until方法里就会不断的去轮训条件是否满足。
def until(self, method, message=''):
screen = None
stacktrace = None
end_time = time.time() + self._timeout
while True:
try:
value = method(self._driver)
if value:
return value
except self._ignored_exceptions as exc:
screen = getattr(exc, 'screen', None)
stacktrace = getattr(exc, 'stacktrace', None)
time.sleep(self._poll)
if time.time() > end_time:
break
raise TimeoutException(message, screen, stacktrace)
method这个参数就是我们传递进来的条件的实例对象,value = method(self._driver)这里就是进行对象的调用,也就是执行了__call__方法里的逻辑。
selenium里都有哪些条件
- title_is 判断title是否出现
- title_contains 判断title页面标题是否包含某些字符
- presence_of_element_located 判断某个元素是否被加载到了dom树里,但是并不代表这个元素可见
- url_contains 判断当前url是否包含某个url
- url_matches 判断当前url是否符合某种格式
- url_to_be 判断当前url是否出现
- url_changes 判断当前url是否已经发生了变化
- visibility_of_element_located 判断某个元素是否被添加到了dom树里,且宽高都大于0
- visibility_of 判断看某个元素是否可见
- presence_of_all_elements_located 判断至少有一个元素存在于dom树中,返回所有定位到的元素
- visibility_of_any_elements_located 判断至少有一个元素在页面中可见
- visibility_of_all_elements_located 判断是否所有元素都在页面中可见
- text_to_be_present_in_element 判断指定的元素中是否包含了预期的字符串
- text_to_be_present_in_element_value 判断指定的元素属性值中是否包含了预期的字符串
- frame_to_be_available_and_switch_to_it 判断iframe是否可以switch进去
- invisibility_of_element_located 判断某个元素是否在dom中不可见
- element_to_be_clickable 判断某个元素是否可见并且是enable的,也就是说是是否可以点击
- staleness_of 等待某个元素从dom中删除
- element_to_be_selected 判断某个元素是否被选中了,一般用于下拉列表中
- element_located_to_be_selected 与上面的意思一样,只不过上面实例化的时候传入的是元素对象,这个传入的是定位
- element_selection_state_to_be 判断某个元素的选中状态是否符合预期
- element_located_selection_state_to_be 与上面一样,只不过传值不同而已
- number_of_windows_to_be 判断当前窗口数是否等于预期
- new_window_is_opened 判断是否有窗口增加
- alert_is_present 判断页面是否有弹窗
以上就是selenium支持的所有条件。
然后就是自定义了
说了那么多条件,其实我们也可以自己实现一个条件类,
class page_is_load:
def __init__(self, expected_title, expected_url):
self.expected_title = expected_title
self.expected_url = expected_url
def __call__(self, driver):
is_title_correct = driver.title == self.expected_title
is_url_correct = driver.current_url == self.expected_url
return is_title_correct and is_url_correct
上面是自己实现的一个条件类,根据页面的url和标题来判断页面是否被正确加载,
class TestCase:
def __init__(self):
self.driver = webdriver.Chrome(executable_path="./driver/chromedriver")
self.driver.get('http://www.baidu.com/')
# sleep(2)
def __call__(self):
print(self.driver.title)
def test_wait(self):
wait = WebDriverWait(self.driver, 2)
wait.until(page_is_load("百度一下,你就知道", "http://www.baidu.com/"))
欢迎大家去 我的博客 瞅瞅,里面有更多关于测试实战的内容哦!!
细说selenium的等待条件的更多相关文章
- Python selenium —— 一定要会用selenium的等待,三种等待方式解读
发现太多人不会用等待了,博主今天实在是忍不住要给大家讲讲等待的必要性. 很多人在群里问,这个下拉框定位不到.那个弹出框定位不到…各种定位不到,其实大多数情况下就是两种问题:1 有frame,2 没有加 ...
- Selenium 延时等待
在 Selenium 中, get() 方法会在网页框架加载结束后结束执行,此时如果获取 page_source ,可能并不是浏览器完全加载完成的页面: 如果某些页面有额外的 Ajax 请求,我们在网 ...
- Python爬虫之设置selenium webdriver等待
Python爬虫之设置selenium webdriver等待 ajax技术出现使异步加载方式呈现数据的网站越来越多,当浏览器在加载页面时,页面上的元素可能并不是同时被加载完成,这给定位元素的定位增加 ...
- Web自动化测试 五 ----- selenium的等待和切换
一.selenium的三种等待 当执行python的selenium代码时,如果需要定位一个元素或者点击一个元素,需要考虑到网速等多方面原因,导致页面加载速度慢,元素还未加载出来,这样就会导致找不到对 ...
- 转 Python selenium 强制等待显示等待隐式等待
1. 1. 强制等待第一种也是最简单粗暴的一种办法就是强制等待sleep(xx),强制让闪电侠等xx时间,不管凹凸曼能不能跟上速度,还是已经提前到了,都必须等xx时间. 看代码: # -*- codi ...
- 【转载】一定要会用selenium的等待,三种等待方式必会
转载地址:http://blog.csdn.net/huilan_same/article/details/52544521,感谢博文,学习了 原文: 发现太多人不会用等待了,博主今天实在是忍不住要给 ...
- Java&Selenium智能等待方法封装
Java&Selenium智能等待方法封装 ExpectedConditions方法还有很多,自然也可以继续扩展很多 package util; import org.openqa.selen ...
- selenium显示等待解决浏览器未加载完成查找控件的问题
问题描述:wap版支付成功后,跳转到支付成功页,查找的元素已出现,如图的:元素1,元素2,但是提示查找的元素超时,失败,并且每到这个页面都会报页面超时,不能查找到页面元素 原始代码: try{ op. ...
- selenium - 常用等待操作
# 4. 等待操作 # 强制等待from time import sleepsleep(10) # 隐性等待# 设置最长等待时间,在这个时间在只要有个时间点加载完成,则执行下一步代码,比sleep智能 ...
随机推荐
- 二叉树的镜像(剑指offer-18)
题目描述 操作给定的二叉树,将其变换为源二叉树的镜像. 解析 先前序遍历这棵树的每个结点,如果遍历到的结点有子结点,就交换它的两个子节点, 当交换完所有的非叶子结点的左右子结点之后,就得到了树的镜像 ...
- 学习记录 | 文件收集-Php
宝贝推荐 推荐新手使用phpStudy这个建站,太方便了 实验初衷 大学什么事情都多,所以什么事情都要偷一下懒,大学总有收不完的青年大学习,我就想能不能来个自助收集然后捣鼓,捣鼓就有了简单的收集程序. ...
- React当中的路由使用
React 当中的路由 使用React构建的单页面应用,要想实现页面间的跳转,首先想到的就是使用路由.在React中,常用的有两个包可以实现这个需求,那就是react-router和react-rou ...
- Pop!_OS配置JAVA环境
Pop!_OS配置JAVA环境 #0x0 安装vscode #0x1 安装JDK #0x2 配置vscode #0x3 安装Eclipse #0x0 安装vscode 见Pop!_OS下安装C++编程 ...
- C#联合WINCC之数据通信
[公众号dotNet工控上位机:thinger_swj] 在工控领域中,WINCC仍然占有很大的市场份额.很多时候我们说学习C#开发上位机可以取代传统的组态软件,两者就像冤家一样,然而,即使是冤家,也 ...
- Java String:字符串常量池(转)
作为最基础的引用数据类型,Java 设计者为 String 提供了字符串常量池以提高其性能,那么字符串常量池的具体原理是什么? 字符串常量池的设计思想是什么? 字符串常量池在哪里? 如何操作字符串常量 ...
- 一个简单的Maven小案例
Maven是一个很好的软件项目管理工具,有了Maven我们不用再费劲的去官网上下载Jar包. Maven的官网地址:http://maven.apache.org/download.cgi 要建立一个 ...
- Go Pentester - HTTP Servers(3)
Building Middleware with Negroni Reasons use middleware, including logging requests, authenticating ...
- Active Directory - Server Remote administration management
Windows Admin Center: https://www.microsoft.com/en-us/evalcenter/evaluate-windows-admin-center Remot ...
- Ethical Hacking - NETWORK PENETRATION TESTING(22)
MITM - Wireshark WIreshark is a network protocol analyser that is designed to help network administa ...