Prefrontal cortex as a meta-reinforcement learning system
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

Nature Neuroscience, 2018
Abstract
在过去的20年中,基于奖励的学习的神经科学研究已经集中在经典模型上,在该模型中,神经递质多巴胺通过调节神经元之间突触连接的强度,“在情况,动作和奖励之间建立联系”。然而,越来越多的最新发现使该标准模型处于压力之下。现在,我们利用人工智能的最新进展来介绍基于奖励的学习的新理论。在这里,多巴胺系统训练大脑的另一部分,即前额叶皮层,作为其自己的独立式学习系统进行操作。
这种新的观点容纳这样一种发现:既激励标准模型,又可以优雅地处理更广泛的观察结果。这为将来的研究提供了新的基础。
最近,在理解奖励驱动学习所涉及的机制方面取得了令人振奋的进步。通过从强化学习1(RL)领域引入思想,部分地实现了这一进步。最重要的是,这种输入导致了基于RL的多巴胺能功能理论。在这里,多巴胺(DA)的释放被解释为传达了奖励预测误差(RPE)信号2,这是在时序差分RL算法中集中体现的惊喜指数。根据该理论,RPE驱动纹状体中的突触可塑性,将经验丰富的动作-奖励联系转化为优化的行为策略3。在过去的二十年中,这一提议的证据不断增多,并将其确立为奖励驱动学习的标准模型。
但是,即使此标准模型已经固化,也积累了一些有问题的观察结果。对前额叶皮层(PFC)的研究产生了一个难题。越来越多的证据表明,PFC实现了基于奖励的学习机制,执行的计算与基于DA的RL的计算极为相似。早已确定,PFC的扇区代表动作,对象和状态的期望价值4-6。最近,已经出现了PFC还对最近的动作与奖励历史进行编码5,7-10。编码的变量集以及有关PFC中神经激活的时间分布的观察结果得出以下结论:“PFC神经元动态地[编码]从奖励与选择历史到对象价值,以及从对象价值到对象选择的转换”7。简而言之,PFC中的神经活动似乎反映了一组操作,这些操作一起构成了独立的RL算法。将PFC放置在DA旁边,我们获得了一张包含两个完整RL系统的图片,一个使用基于活动的表示,另一个使用突触学习。这些系统之间是什么关系?如果两者都支持RL,那么它们的函数是否仅仅是多余的?一种建议是,DA和PFC支持不同形式的学习,其中DA基于直接刺激-响应关联实施了无模型RL,而PFC执行了有模型RL,从而利用了任务结构的内部表示11,12。但是,对于这种双系统视图,一个明显的问题是重复观察到DA预测误差信号是由任务结构通知的,反映了很难与最初构架的标准理论相吻合的“推断”12,13和“有模型”14,15的价值估计。
在当前的工作中,我们为基于奖励的学习的基础计算提供了一个新的视角,该视角适应了由上述现有理论启发的发现,但也解决了许多普遍的难题。在更广泛的层面上,该理论为先前被认为无关的各种发现提出了一个连贯的解释。我们从三个关键前提开始:
System architecture. 与先前的工作16-18一致,我们将PFC以及与其连接的基底神经节和丘脑核概念化,形成了循环神经网络。该网络的输入包括感知数据,该数据包含或伴随着有关已执行动作和所获得奖励的信息19。在输出端,网络触发动作并发出状态价值的估计(图1a,b)。
Learning. 正如过去研究20-22中所建议的那样,我们假设前额叶网络(包括纹状体成分)中的突触权重是通过无模型RL程序进行调整的,其中DA传递RPE信号。通过这个角色,基于DA的RL程序可以改变循环前额叶网络的激活动态。
Task environment. 根据过去的提议23–25,我们假设RL不是在单个任务上发生,而是在动态环境中构成一系列相互关联的任务。因此,需要学习系统进行持续的推断和行为调整。
如前所述,这些前提都牢固地立足于现有研究。当前工作的新贡献是确定在同时满足三个前提时产生的新效果。正如我们将要展示的,当这些条件同时发生时,它们足以产生一种“元学习”26的形式,其中一种学习算法会产生第二种更有效的学习算法。具体来说,通过调整前额网络中的连接权重,基于DA的RL创建了第二个RL算法,该算法完全在前额网络的激活动态中实现。这种新的学习算法独立于原始算法,并且在适合任务环境的方式上有所不同。至关重要的是,新兴算法是成熟的RL程序:它可以解决探索与开发之间的折衷问题27,28,保持了对价值函数1的表示,并逐步调整了动作策略。考虑到这一点,并认识到一些先驱研究29-32,我们将总体效果称为“强化学习”。
为了演示,我们利用图1a中所示的简单模型,即循环神经网络(图1b),该模型的权重使用无模型RL算法进行训练,利用了深度学习研究的最新进展(请参见方法和补充图1)。我们在简单的“两臂赌博机” RL任务中考虑了该模型的性能。在每次试验中,系统都会输出一个动作:向左或向右。每个人都有产生奖励的可能性,但是这些概率随每次训练episode而变化,从而提出了一个新的赌博机问题。在对一系列问题进行了训练之后,固定了循环网络中的权重,并对系统进行了进一步的问题测试。 该网络探索了两臂,逐渐地转向了奖励较多的臂,其学习效率可与标准的机器学习算法相媲美(图1c,d)。
由于网络中的权重在测试时是固定的,因此系统的学习能力不能归因于用于调整权重的RL算法。相反,学习反映了循环网络的激活动态。作为训练的结果,这些动态实现了自己的RL算法,随着时间的推移集成了奖励信息,探索并改进动作策略(图1e,f和补充图2)。该学习到的RL算法不仅可以独立于最初用于设置网络权重的算法运作。它与原始算法的不同之处还在于,它特别适合于训练系统的任务分配。在图1d中给出了这一点的说明,该图显示了在对赌博机问题的结构化版本进行训练后同一系统的性能,其中在各个episode中的臂参数是反相关的。在这里,循环网络收敛于利用问题结构的RL算法,与非结构化任务相比,可以更快地识别出较优臂。
在以抽象计算术语介绍了元RL之后,我们现在返回到其神经生物学解释。首先将前额神经网络(包括其皮层下成分)视为循环神经网络。与标准模型一样,DA广播RPE信号,从而驱动前额叶网络中的突触学习。此学习的主要作用是通过调整前额网络的循环连接来塑造其动态。通过元RL,这些动态实现了第二种RL算法,该算法与原始DA驱动的算法不同,并采用了适合任务环境的形式。在此基础上,DA驱动的RL在扩展的一系列任务中扮演着角色。快速的任务内学习主要是由前额叶网络动态中固有的新兴RL算法介导的。
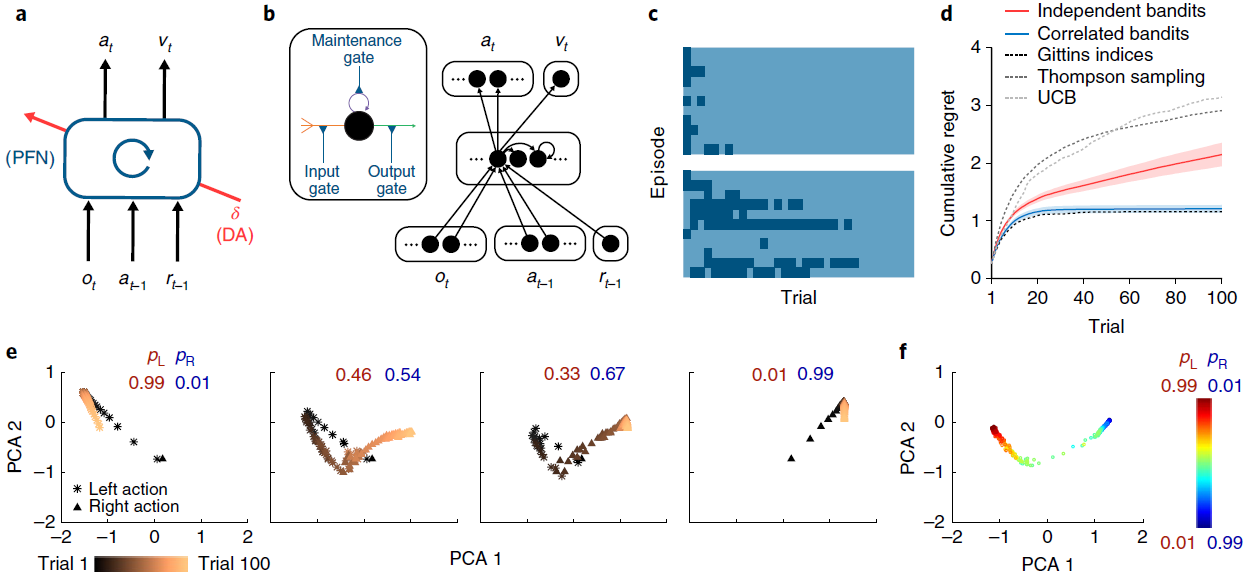
图1 | 元RL结构可跨episode学习,以在episode中有效学习。a,智能体架构。前额网络(PFN),包括直接与PFC连接的基底神经节和丘脑的部分,被建模为循环神经网络,其突触权重通过DA驱动的RL算法进行调整;o是感知输入,a是动作,r是奖励,v是状态值,t是时间步骤,δ是RPE。中央框表示一组全连接的LSTM单元。b,在我们的仿真中使用的神经网络实现的更详细的示意图。编码当前观察值,先前动作和奖励的输入单元将所有事物与隐含单元连接在一起,而隐含单元本身就是全连接的LSTM单元。这些单元依次通过softmax层(请参见方法)对动作进行编码,并使用一个线性单位对估计的状态价值进行编码,从而将所有事物连接在一起。插图:单个LSTM单位(请参见方法)。输入(橙色)是其他单位输出的加权总和,加上LSTM单位本身的活动(紫色)。输出(绿色)使这些求和的输入经过sigmoid非线性。所有三个量都被乘以门(蓝色)。在方法中提供了包括相关方程在内的全部详细信息。c,对于具有伯努利(第1臂,第2臂)奖励参数0.25、0.75(顶部)和0.6、0.4(底部)的赌博机问题的逐次试验模型行为。这两种颜色分别指示左动作和右动作。网络从探索向开发转换,使这一转换在更困难的问题上更加缓慢。d,在具有独立同分布的臂参数的赌博机上训练的元RL网络的性能,并在0.25、0.75(红色)上进行了测试,以累积遗憾的方式衡量,定义为玩次优(较低的奖励)臂时遭受的累积损失(以预期奖励计)。绘制了几种标准机器学习赌博机算法的性能以进行比较。蓝色表示经过对相关赌博机的训练(相同参数总和为1)后在同一个问题上的性能。阴影表示300次评估episode中的95%置信区间。e,在训练来自同一分布的问题后,在对相关赌博机进行测试时,在个别试验中反复神经网络激活模式的演变。pL表示动作“左”的奖励概率;pR表示采取动作“右”的奖励概率。f,从相关的赌博机任务中的步骤100开始,在一系列奖励参数上的循环神经网络活动模式。补充图2给出了进一步的分析。通过1个训练有素的网络对300个评估episode进行了分析,每个eposide包括100个试验。
Results
尽管它很简单,但元RL框架可以解释令人惊讶的神经科学发现,包括许多对DA的标准RPE模型带来困难的结果。为了调查框架的影响,我们进行了六个模拟实验,每个模拟实验着重于选择用来说明该理论核心方面的一组实验结果。在整个仿真过程中,我们继续应用图1a中的简单计算架构。这种方法显然抽象出许多神经解剖学和生理学细节(参见补充图3)。但是,它可以让我们在易于确定其计算来源的环境中演示关键效果。本着同样的精神,我们的模拟不仅仅关注与参数相关的数据拟合,而仅关注鲁棒的定性效果。
Simulation 1: RL in the prefrontal network. 我们从PFC编码被整合到不断发展的选择价值表示中的最近的动作与奖励这个发现开始。为了证明元RL如何解释这一发现,我们模拟了Tsutsui et al.7以及Lau and Glimcher33的结果。两项研究都采用了一项任务,即猴子在两个视觉扫视目标之间进行选择,每个目标都能以间歇性变化的概率获得果汁奖励。在给定奖励计划的情况下,可以通过按照目标的产出对每个目标进行采样来估算最优策略33,而猴子则表现出这种“概率匹配”(图2a)。背外侧PFC7的记录显示了编码先前试验中选择的对象的活动,获得的奖励,对象的更新值以及每个即时动作(图2b),支持了PFC神经元反映逐项试验构造的结论,并根据最近的经验更新选择价值10。
我们通过在同一任务上训练元RL模型来模拟这些结果(请参见方法)。网络将其行为调整为适合每个任务实例,显示与并行实验结果非常相似的概率匹配(图2d)。细粒度分析得出的模式类似于在猴子行为中观察到的模式(图2c,f和补充图4)。请注意,该网络的权重在测试时是固定的,这意味着该网络的行为只能由前额叶循环神经网络活动的动态导致。与此相一致,我们在前额叶网络中发现了对Tsutsui et al.7报告的每个变量进行编码的单元(图2e)。
这些结果提供了元RL活动的另一种基本说明,DA驱动的训练产生了独立的基于前额叶的学习算法。在这种情况下,元RL解释了实验数据中观察到的行为和PFC活动,但也解释了通过DA驱动的学习如何同时出现这两种行为。
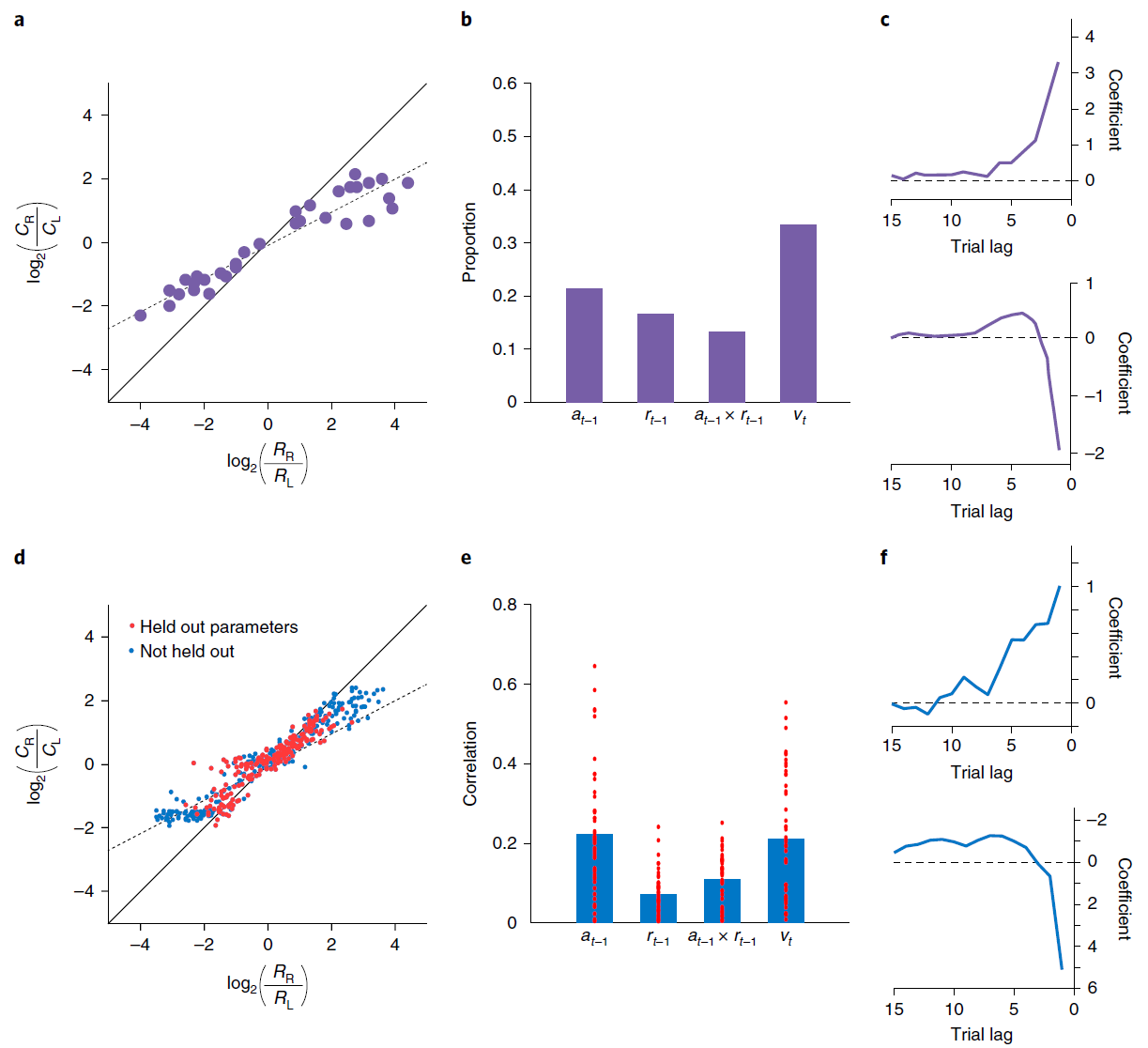
图2 | 模拟循环网络代码中的各个单元,用于记录动作和奖励历史记录。a,来自Lau and Glimcher的概率匹配行为33。Ci表示选择动作 i 的试验次数;Ri表示由动作 i 产生的奖励事件的数量。b,来自Tsutsui et al.7的PFC神经元编码的比例,在试验的初始固定时期,先前动作,先前奖励,这两个因素的相互作用以及当前选择值。c,滞后回归系数表明从Lau and Glimcher33中选择最近奖励的影响(顶部)和动作(底部)。d,模型匹配行为。红点表示泛化性能(请参见方法)。e,与b中相同的因素的偏相关系数(绝对值,Pearson的r),但在试验初次固定时跨模型中的各个单元。条形表示平均值。即时动作(未显示)的编码在单位之间也很普遍,并且通常比其他变量要强。f,回归权重与c中的权重相对应,但基于模型行为。c和f之间的系数尺度差异是由于回归程序中的微小差异所致,特别是使用了奖励历史 vs. 连续值(范围从0.35到0.6)。为了进行比较,Ttsutsui et al.7报告了过去奖励的影响的回归结果,该结果表明时间分布相似,但在滞后1达到峰值,系数为1.25。面板a-c经Tsutsui et al.7以及Lau and Glimcher33的许可改编。
Simulation 2: adaptation of prefrontal-based learning to the task environment. 元RL的一个关键方面是,在前额网络中出现的学习算法可能不同于创建它的基于DA的算法。我们在这里说明该原理,重点放在单个参数的差异上:学习率。为此,我们模拟了Behrens et al.[34]的实验结果。 这涉及到双臂赌博机任务,在回报概率保持稳定的“稳定”时期和波动的“不稳定”时期之间交替。 Behrens et al.[34]发现,与贝叶斯模型确定的最优策略相一致(根据任务波动的动态估计来调整其学习率),人类参与者在不稳定时期所采用的学习率要比稳定时期快(将3a,c进行对比)。神经影像数据确定了PFC内的一个区域(特别是背扣带回皮层),该区域的活动跟踪了贝叶斯模型的波动率估计。
图3b,d总结了在相同任务下具有固定权重的模型的行为。 该模型以前在一系列具有变化的波动的episode中进行过训练(请参见“方法和补充图5”),以模仿人类参与者执行任务时所经历的不同波动的先验经验。像人类学习者一样,网络可以动态地使其学习率适应不断变化的波动性。而且,正如用fMRI观察到的PFC活动一样,LSTM网络中的许多单位(37±1%)明确跟踪了波动性。
至关重要的是,图3d所示的学习率比管理基于DA的RL算法的学习率大几个数量级,后者在训练过程中调整了前额叶网络的权重(设置为0.00005)。因此,结果提供了具体的说明,说明了从元RL产生的学习算法可能与最初产生它的算法不同。结果还使我们能够强调该原理的重要推论,即元RL产生了实际上适合于任务环境的前额学习算法。在当前情况下,这种适应以学习率响应任务波动的方式体现出来。先前的研究提出了特殊目的机制来解释学习率的动态变化29,35。元RL将这些变化解释为一种新兴效果,是由一系列非常普遍的条件引起的。而且,动态学习率只是专业化的一种可能形式。当元RL在具有不同结构的环境中出现时,将出现不同定性的学习规则,这一点将在后续的模拟中得到说明。
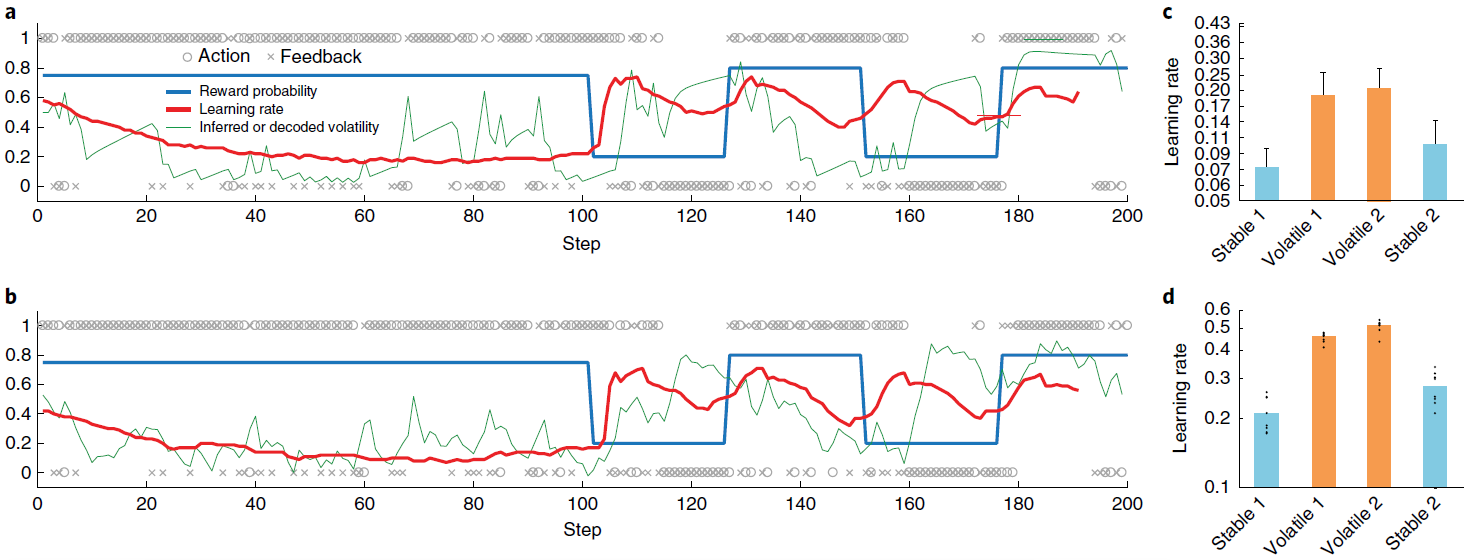
图3 | 学习型RL算法可根据环境的变化动态调整其学习率。a,Behrens et al.34在其不稳定赌博机任务上提出的贝叶斯模型的样本行为。蓝色是动作1的真实奖励概率(动作1和2的概率总和为1);o表示动作(上面为动作1,下面为动作2);x表示结果(上面为奖励,下面为无奖励)。绿色是预计波动率;红色是学习率。b,元RL模型的相应数量,如方法中所述对不稳定性进行解码。c,从Behrens et al.34重新绘制的人类行为摘要,显示了测试样本在s.e.m的情况下的平均学习率。d,相应的元RL行为表现出相似的模式,在不稳定任务块中具有较高的学习率。点代表来自采用不同随机种子的单独训练(n = 8)的数据。面板a和c经Behrens et al.34许可改编。
Simulation 3: reward prediction errors reflecting inferred value. 如前所述,标准模型的一个明显挑战是DA的RPE信号反映了任务结构的知识。一个例子就是Bromberg-Martin et al.12报告的“推断价值”效应。在执行任务的每个试验中,视觉目标都出现在显示器的左侧或右侧,并且猴子被期望扫向目标。在实验的任何时候,左目标或右目标都会产生果汁奖励,而另一个目标则不会,并且这些角色分配在整个测试过程中会间歇性地反转。关键观察到的是逆转后DA信号的变化:在猴子对一个目标的奖励发生变化之后,DA立即对另一个目标的出现做出了显著变化,反映出该目标的价值也发生了变化(图4a)。
这种推断价值效应以及其他相关发现引出了模型,其中PFC或海马体对抽象的隐状态表示进行编码19,36-38,然后可以将其送入生成RPE13的计算中。事实证明,相关的机制自然是由元RL引起的。为了证明这一点,我们在Bromberg-Martin et al.的任务12中训练了元RL模型。在测试中,我们观察到RPE信号复制了DA显示的模式。特别是,该模型清楚地再现了关键推断价值效应(图4b)。
此结果的解释很简单。在我们的体系结构中,RPE的奖励预测组件来自前额网络的状态价值输出,该数据与表明DA信号受PFC的预测影响的数据一致13。由于基于DA的训练使前额网络对有关任务动态的信息进行编码(图4c),因此该信息也体现在RPE的奖励预测组件中。
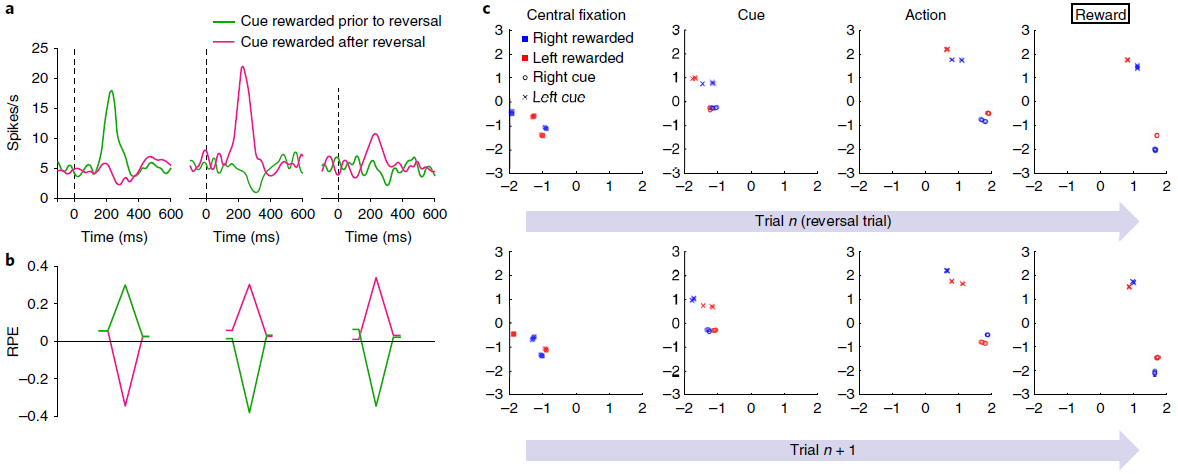
图4 | 模拟智能体的奖励预测误差与猴子中观察到的相似,反映的是推断价值,而不仅是经验价值。a,结果经Bromberg-Martin et al.12许可改编。多巴胺能活动响应于反转之前的信号(左)以及具有经验价值(中间)和推断价值(右)变化的信号。曲线代表了两只猴子的平均神经元响应(每条曲线n = 42-63)。b,来自模型的相应RPE信号。每个数据系列的起点和终点对应于初始注视和扫视步骤。峰谷对应于刺激表现。虽然经验数据中的RPE响应对于推断价值较小,但此处未显示,但Bromberg-Martin et al.12的其他经验结果显示了更多相似的模式。尤其是,在相同任务中不同动物的侧面habenula记录在条件下产生的RPE信号(和行为反应时间)相似得多。c,模拟3任务中各个步骤的循环神经网络活动(LSTM输出)的前两个主要成分,由1个训练有素的网络副本执行的1200个评估episode进行了分析。其他副本产生了非常相似的结果。最上面的一行着眼于逆转试验,在该试验中,最终的奖励反馈(最右边的面板)表示奖励目标已经相对于先前的试验进行了转换。第二行重点关注第一行检查的逆转试验之后的试验。活动模式根据任务的当前隐状态(即当前提示哪种信号)进行聚类,随后在每个试验中也根据选择的动作进行聚类。如最左边的面板(“中央注视”)所示,在每次试用开始时,网络的激活状态代表任务的隐状态,并且在进行逆转试验后突然恢复。
Simulation 4: ‘model-based’ behavior—the two-step task. 观察到结构敏感的DA信号的另一个重要设置是在旨在探测有模型的控制任务中。在这一类别中,研究最深入的任务也许是Daw et al.[15]引入的“两步”模型。在我们将考虑的版本中(图5a),每个试验都始于两个动作之间的决定。每个触发概率转换到两个可感知区分的第二阶段状态之一;对于每个动作,都有一个“常见”(高概率)转换和一个“罕见”(低概率)转换。然后,每个第二阶段状态都会提供具有特定概率的奖励,该奖励会间歇性地变化(请参见方法)。
两步任务的有趣点在于它能够区分无模型学习和有模型学习。最重要的是异常转换后的行为。考虑在阶段1选定的触发不常见转换并随后得到奖励的动作。由动作-奖励关联驱动的无模型学习将增加在后续试验中重复相同的第一阶段动作的可能性。相反,有模型学习将考虑任务的转换结构,并增加选择相反动作的可能性(图5b)。人类15和啮齿动物39都通常表现出有模型学习的行为证据(图5c,d)。
我们在两步任务上训练了我们的元RL模型(请参阅方法),发现在测试中其行为采取了与有模型的控制相关的形式(图5c,e)。与以前的模拟一样,在冻结权重的情况下测试了网络。因此,观察到的行为是由循环前额网络的动态产生的。但是,重要的是要记住,网络是由无模型的DA驱动的RL算法训练的。在神经科学的背景下,这表明了有兴趣的可能性,即有模型RL的PFC实现实际上可能源于无模型的DA驱动的训练(进一步的分析,请参见图6-8)。
至关重要的是,两步任务是报告结构敏感的RPE信号的最早背景之一。 Daw et al.15特别使用fMRI,观察了人类腹侧纹状体中的RPE(DA的主要目标),该RPE跟踪了有模型RL算法预测的RPE。在我们的元RL模型中也会产生相同的效果(图5f,g)。
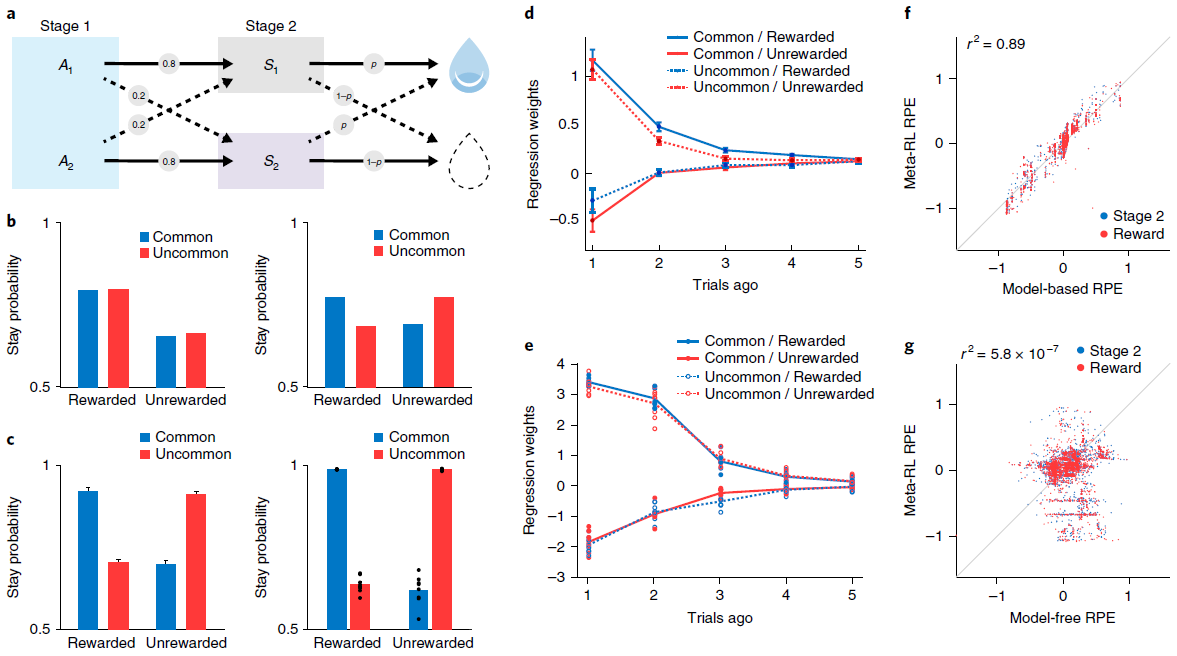
图5 | 学习到的RL算法可显示有模型的行为和RPE。a,两步任务的结构15,39,描述了第一阶段动作A1和A2如何概率性地转换到第二阶段状态S1和S2。b,顶部,无模型(左)和有模型(右)学习的典型行为模式。c,左图,来自Miller et al.39的数据,显示了基于典型模型的动物行为模式。曲线表示n = 6只大鼠的平均停留概率;误差条为s.e.m. 有关完整分布,请参见Miller et al.39。右图,网络的相应行为。点表示来自使用不同的随机种子(n = 8)单独训练的数据。d,Miller et al.39的更详细的分析显示,在多个试验滞后,转换类型和奖励对动物行为的影响。该图表示n = 21只大鼠的平均回归权重;误差线为s.e.m. 该模式排除了另一种无模型的机制(请参见补充图6)。e,对元RL行为的相应分析。点表示来自使用不同的随机种子(n = 8)单独训练的数据。f,g,在试验的不同阶段,模型RPE信号相对于有模型(f)和无模型(g)算法的预测的回归。由8个副本中的1个经过充分训练的网络对30个评估episode进行了分析,每个episode包括100个试验。面板c(左)和d经Miller et al.39许可改编。
Simulation 5: learning to learn. 模拟3和4集中于涉及任务的两个版本之间交替的场景,随着时间的推移,每个版本可能会变得很熟悉。在这里,我们将元RL应用于一项任务,在该任务中不断出现新的刺激,需要在最充分的意义上进行学习。在这种情况下,我们证明元RL可以说明过去的经验会加速新学习的情况,这种效果通常称为“学会学习”。
在最初启发该术语的任务中,Harlow40向猴子展示了两个不熟悉的对象,一个覆盖了包含食物奖励的井,另一个覆盖了空的井。动物在对象之间自由选择,并且如果存在的话可以获取食物奖励。然后随机重置对象的左右位置,并开始新的试验。在重复六次此过程之后,替换了两个全新的对象,然后再次开始该过程。在每个试验阶段中,选择一个对象始终如一地奖励,而另一个始终不予奖励。在训练的早期,猴子在每个块中收敛到正确对象上的速度很慢。但是经过大量的练习,猴子只经过一次试验就表现出了完美的性能,这反映了对任务规则的理解(图6b)。
为了评估元RL解释Harlow40的结果的能力,我们将他的任务转换为要求在模拟计算机显示器上呈现的图像之间进行选择的任务(图6a和补充视频1)。否则,该任务保持不变,每六个试验后引入一对不熟悉的图像。为了使我们的模型能够处理高维像素输入,我们使用常规的图像处理网络对其进行了扩充(请参见方法)。结果系统生成的学习曲线与经验数据非常相似(图6c)。经过训练,该网络在一次试验中学习了如何在每个新区域中做出响应,从而复制了Harlow40的“学会学习”效果。
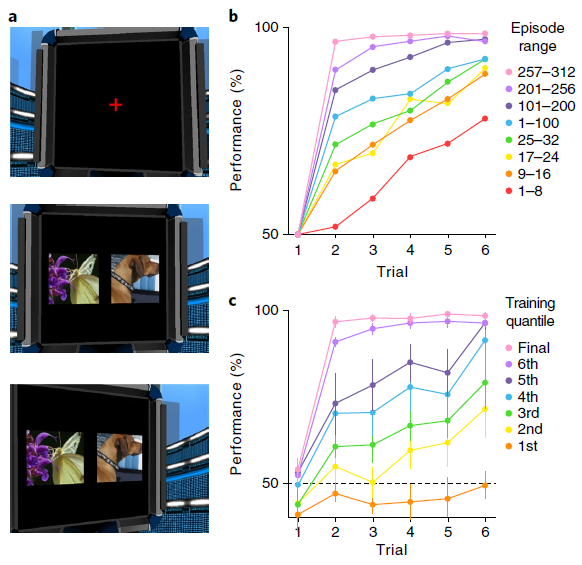
图6 | 元RL学习在视觉丰富的3D环境中学习抽象结构和新颖刺激。a,模拟5(全分辨率)的示例图像输入,显示了注视十字(上),初始刺激表现(中)和扫视结局(下)。b,在引入新对象之后以及在训练连接权重的多个点上,来自Harlow40的每个步骤的精度数据。c,训练的七个连续阶段(请参阅方法)的模型性能,在达到最高性能(50个副本中)的所有网络(n = 14)中取平均值。误差条代表95%置信区间。
Simulation 6: the role of dopamine—effects of optogenetic manipulation. 元RL框架要求前额网络的输入包含有关最近奖励的信息。我们的实现通过输入标量信号来满足此要求,该标量信号明确表示在先前时间步骤上收到的奖励量(图1a)。但是,任何与奖励密切相关的信号就足够了。因此,诸如果汁的味道之类的感觉信号可能起必要的作用。另一个特别有趣的可能性是,有关奖励的信息可能由DA本身传达。在这种情况下,DA将扮演两个不同的角色。首先,与标准模型一样,DA将调节前额叶网络中的突触可塑性。其次,相同的DA信号将通过送入有关近期奖励的信息来支持前额网络中基于活动的RL计算41。我们修改了原始网络以提供RPE(代替奖励)作为该网络的输入(请参见方法和补充图9),发现它在模拟1–5的任务上产生了类似的行为。
元RL的这种变化为使用光遗传学技术阻断或诱导多巴胺能RPE信号的近期实验发现提供了新的解释42,43。为了说明这一点,我们考虑了Stopper et al.44进行的一项实验,该实验涉及具有间歇转换收益概率的两臂赌博机任务(请参见方法)。在从一个杠杆提供食物奖励期间阻止DA活动导致对该杠杆的偏好降低。相反,当一个杠杆无法产生食物时,人为地刺激DA释放会增加对该杠杆的偏好(图7a)。我们通过在补充图9中增加或减少向网络输入的RPE来模拟这些条件,并观察到类似的行为结果(图7b)。与以前的模拟一样,这些结果是在网络权重保持不变的情况下获得的。因此,由我们的模拟光遗传学干预引起的行为变化反映了多巴胺能RPE信号对前额叶网络内单位活动的影响,而不是对突触权重的影响。在这方面,本模拟因此提供了对实验结果的一种解释,该解释与从标准模型中得出的结果完全不同。
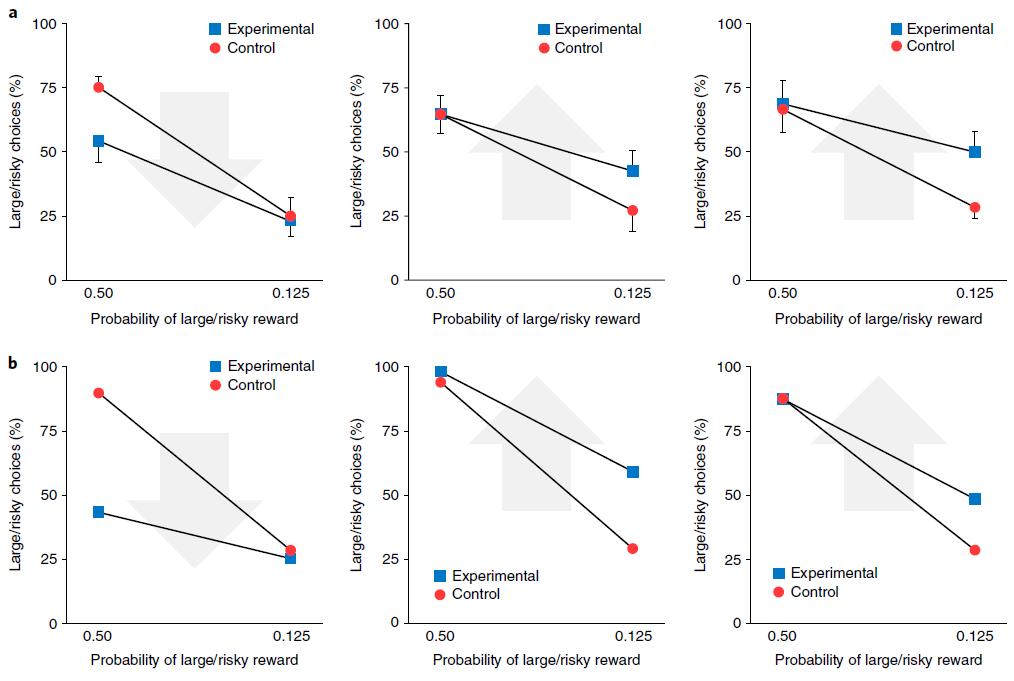
图7 | 多巴胺的双重作用:产生突触变化以进行缓慢学习,并携带有关奖励的信息以进行快速学习。a,行为数据经过Stopper et al.的许可改编44。他们的任务是反复选择一种杠杆,一个杠杆可靠地产生小额奖励(小/确定),而另一个产生大额奖励的概率为p(大/风险)。在对照条件下,大鼠在p = 0.5时比在p = 0.125(蓝色)时更频繁地选择大/风险杠杆。左图,发生大/风险回报时(n = 11)的光遗传学上阻断DA的效果。箭头指示光遗传学干预的转换方向。中心,当小/确定奖励出现时(n = 8)阻止DA的效果。右图,当大/风险奖励失败时触发DA的效果(n = 9)。所有图均表示均值±s.e.m. b,在由Stopper et al.44施加条件的情况下模拟行为,条件如a所示。
Functional neuroanatomy. 如我们的仿真结果所示,元RL提供了一个新的视角,通过它可以检查前额叶网络和DA系统的各自函数,以及它们在学习过程中的相互作用。正如我们已经注意到的,元RL理论的一个关键假设是前额网络可以理解为循环神经回路16-18。实际上,PFC位于多个循环回路的交叉点,涉及PFC自身内部的循环连接,与其他皮质区域的连接45,最重要的是与背侧纹状体和中腹丘脑的连接(补充图3)。普遍的观点是,在此皮质-基底节-丘脑-皮质环中纹状体的作用是通过控制信息流进入PFC电路来调节PFC的动态。据此,DA用作纹状体内的训练信号,通过时序差分学习来塑造门控函数的操作。使用这种更详细的皮质-纹状体环模型复制我们的模拟结果,是未来研究的重要目标。
值得注意的是,纹状体门控理论最初是由LSTM网络启发而来的,这种网络是我们在模拟中采用的那种模型(图1b)。确实,最近的工作提出了在PFC上运行的多种门控机制,它们直接与传统上在LSTM网络中实现的输入,内存和输出门控机制并行46(请参见方法)。尽管这些相似之处很吸引人,但也应注意,其他最新工作已使用缺少LSTM网络中涉及的门控机制的更通用的循环神经网络对PFC中的RL进行建模16,18。尽管我们已经确定的元RL效应仅依赖于复发的存在,而不依赖于任何特定的门控机制,但是测试特定的门控机制是否能够为人和动物的学习曲线和神经表征提供更精确的定量拟合将是有趣的。
我们在本文中考虑的神经科学数据主要集中在将背侧PFC与基底神经节连接的所谓“关联回路”中的结构上(补充图3)。但是,这只是大脑中几种此类循环回路中的一种,其他循环穿过皮质的其他区域(补充图3)。这就提出了一个问题,即其他循环回路(例如贯穿体感和运动皮层的“感觉运动回路”)是否也支持元RL。尽管我们不能排除在这些循环中也可能出现元学习形式的可能性,但我们观察到,本文描述的元RL效应只有在网络输入携带有关近期行为和奖励的信息以及网络动态支持在合适的时间段内信息的维护时才会出现。这两个因素可能使关联回路与其他皮质-基底节-丘脑-皮质回路47不同,这解释了为什么元RL可能在该回路中独特地出现(补充图3)。
我们的大多数模拟都将所有PFC建模为一个没有区域专业化的单一全连接网络。但是,PFC内部存在重要的功能解剖区别。例如,在模拟1中看到的概率匹配行为和在模拟4中有模型学习模式在背外侧PFC中具有强大的神经相关性7,11,而在模拟2中建模的不稳定性编码在前扣带回皮层中报道34。尽管前扣带回和背外侧PFC的不同作用仍在争论中,但本理论的重要下一步将是考虑到元RL涉及的计算如何在这些区域中发挥作用,因为它们不同的细胞特性,内部电路和外部连接。同样重要的是位于所谓的“边缘环”中的PFC区域,包括眶额和腹侧PFC(请参见补充图3)。后者的两个区域都与奖励编码有关,而最近的工作表明,眶额皮质可能还编码了抽象的隐状态36,37,它们都是元RL的关键函数,如我们的一些模拟所示。再次,更全面的元RL理论发展将需要更明确地纳入这些区域的相对角色。
Discussion
我们利用元RL的概念提出了有关DA和PFC在基于奖励的学习中的作用的新建议。我们先进的框架保留了DA功能的标准RPE模型,但将其置于新的环境中,使其能够重新适应以前令人费解的发现。如我们的仿真所示,元RL解释了有关DA和PFC功能的各种观察结果,为解决这两个系统的文献之间提供了桥梁。
除了解释现有数据外,元RL框架还带来了许多可测试的预测。如我们所见,该理论表明PFC在有模型的控制中的作用至少部分是由DA驱动的突触学习引起的。如果这是正确的,则在初始训练期间干扰相位DA信号将干扰模拟4和5中研究的任务中有模型的控制的出现。另一个预测涉及有模型的多巴胺能RPE信号。元RL将这些信号归因于来自前额网络的价值输入。如果正确,那么损害或失活PFC或其相关的纹状体核应消除有模型的DA信号48。通过检查我们模型的前额叶网络部分中产生的活动模式,将这些模式视为执行相关任务的动物神经活动的预测器,可以指定进一步的预测。对这项工作有用的行为任务可能来自最近的工作,该工作牵涉到PFC在RL上下文中识别隐状态19,36-38和抽象规则49。
元RL还提出了一系列更广泛的问题,我们希望这些问题能够刺激新的实验工作。在元RL背景下,中边缘,中皮质和黑纹状体DA通路的相对作用可能是什么?元RL是否指向PFC的背侧和腹侧或内侧和外侧部门之间的分工的新解释?我们应该如何解释指向支持有模型和无模型RL的系统存在的数据(补充图7和8)?当元RL与保存episodic记忆的机制接触时,会出现哪些新的动态50?总而言之,元RL在有关基于奖励的学习的思想领域中提供了新的定位点,这可能在开发新的研究问题和解释新发现方面很有用。
Methods
可从https://doi.org/10.1038/s41593-018-0147-8获得包括数据可用性声明以及任何相关的登录号和参考方法。
Prefrontal cortex as a meta-reinforcement learning system的更多相关文章
- 论文笔记之:Asynchronous Methods for Deep Reinforcement Learning
Asynchronous Methods for Deep Reinforcement Learning ICML 2016 深度强化学习最近被人发现貌似不太稳定,有人提出很多改善的方法,这些方法有很 ...
- (转) Playing FPS games with deep reinforcement learning
Playing FPS games with deep reinforcement learning 博文转自:https://blog.acolyer.org/2016/11/23/playing- ...
- (转) Deep Learning Research Review Week 2: Reinforcement Learning
Deep Learning Research Review Week 2: Reinforcement Learning 转载自: https://adeshpande3.github.io/ad ...
- (转) Deep Learning in a Nutshell: Reinforcement Learning
Deep Learning in a Nutshell: Reinforcement Learning Share: Posted on September 8, 2016by Tim Dettm ...
- Awesome Reinforcement Learning
Awesome Reinforcement Learning A curated list of resources dedicated to reinforcement learning. We h ...
- (转) Deep Reinforcement Learning: Pong from Pixels
Andrej Karpathy blog About Hacker's guide to Neural Networks Deep Reinforcement Learning: Pong from ...
- (转)Applications of Reinforcement Learning in Real World
Applications of Reinforcement Learning in Real World 2018-08-05 18:58:04 This blog is copied from: h ...
- 论文笔记:Learning how to Active Learn: A Deep Reinforcement Learning Approach
Learning how to Active Learn: A Deep Reinforcement Learning Approach 2018-03-11 12:56:04 1. Introduc ...
- 18 Issues in Current Deep Reinforcement Learning from ZhiHu
深度强化学习的18个关键问题 from: https://zhuanlan.zhihu.com/p/32153603 85 人赞了该文章 深度强化学习的问题在哪里?未来怎么走?哪些方面可以突破? 这两 ...
- [转]Introduction to Learning to Trade with Reinforcement Learning
Introduction to Learning to Trade with Reinforcement Learning http://www.wildml.com/2018/02/introduc ...
随机推荐
- 第十四章 JDK新特性回顾
14.1.JDK5新特性回顾 自动装箱.拆箱 静态导入 增强for循环 可变参数 枚举 泛型 元数据 14.2.JDK7新特性回顾 对Java集合(Collections)的增强支持 在switch中 ...
- Day02_SpringCloud
学于黑马和传智播客联合做的教学项目 感谢 黑马官网 传智播客官网 微信搜索"艺术行者",关注并回复关键词"乐优商城"获取视频和教程资料! b站在线视频 0.学习 ...
- pandas_时间序列和常用操作
# 时间序列和常用操作 import pandas as pd # 每隔五天--5D pd.date_range(start = '',end = '',freq = '5D') ''' Dateti ...
- 7.9 NOI模拟赛 数列 交互 高精 字符串
这是交互题 也是一个防Ak的题目 4个\(subtask\) 需要写3个不尽相同的算法. 题目下发了交互程序 所以调试的时候比较方便 有效防止\(CE\). 题目还有迷糊选手的点 数字位数为a 范围是 ...
- HTML与XHTML之间的区别
HTML与XHTML之间的差别,粗略可以分为两大类比较:一个是功能上的差别,另外是书写习惯的差别.关于功能上的差别,主要是XHTML可兼容各大浏览器.手机以及PDA,并且浏览器也能快速正确地编译网页. ...
- linux之FTP服务搭建 ( ftp文件传输协议 VSFTPd虚拟用户)
FTP服务搭建 配置实验之前关闭防火墙 iptables -F iptables -X iptables -Z systemctl stop firewalld setenforce 0 1.ftp简 ...
- SpringBoot 发送邮件和附件
作者:yizhiwaz 链接:www.jianshu.com/p/5eb000544dd7 源码:https://github.com/yizhiwazi/springboot-socks 其他文章: ...
- 笨办法学python3练习代码ex18.py
#命名.变量.代码.函数 #this one is like your scripts with argv def print_two(*args): arg1, arg2 = args #将参数解包 ...
- 【FZYZOJ】愚人节礼物 题解(状压DP)
前言:麻麻我会写状压DP了! ---------------------------- 题目描述 愚人节到了!可爱的UOI小朋友要给孩子们送礼物(汗-原题不是可爱的打败图么= =..).在平面直角坐标 ...
- .NET 异步详解
前言 博客园中有很多关于 .NET async/await 的介绍,但是很遗憾,很少有正确的,甚至说大多都是"从现象编原理"都不过分. 最典型的比如通过前后线程 ID 来推断其工作 ...