Intelligence Beyond the Edge: Inference on Intermittent Embedded Systems
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! 以下是对本文关键部分的摘抄翻译,详情请参见原文。
Abstract
能量收集技术为未来的物联网应用提供了一个很有前景的平台。然而,由于这些设备中的通信非常昂贵,应用程序将需要“超出边缘”的推理,以避免在无意义的通信上浪费宝贵的能量。我们的结果表明,应用程序性能对推理精度非常敏感。不幸的是,精确的推理需要大量的计算和内存,而能量收集系统的资源严重受限。此外,能量收集系统间歇运行,经常发生电力故障,这会破坏结果,阻碍前进。
本文克服了这些困难,在能量搜索系统上首次给出了DNN推理的全面演示。我们设计并实现了SONIC,这是一个间歇感知的软件系统,专门支持DNN推理。SONIC引入了循环延续(loop continuation),这是一种新的技术,它大大降低了保证像DNN推断这样的循环繁重代码正确间歇执行的成本。为了构建一个完整的系统,我们进一步介绍了GENESIS,一个自动压缩网络以最佳平衡推理精度和能量的工具,以及TAILS,它利用一些微控制器中可用的SIMD硬件来提高能量效率。SONIC和TAILS都保证了正确的间歇执行,而不会在不同的电源系统中出现任何手动微调或性能损失。在商用微控制器上运行三个神经网络,SONIC和TAILS比最新技术分别减少了6.9和12.2倍的推理能量。
1. Introduction
能量收集技术的成熟和最近出现的可行的间歇计算模型为建立具有现有电池供电系统的大部分计算、传感和通信能力的复杂无电池系统提供了机会。许多未来的物联网应用需要频繁的决策,例如何时触发电池耗尽的摄像头,并且因为与其他设备通信通常是不切实际的昂贵,所以这些决策必须在本地做出。未来的物联网应用需要对原始传感器数据进行本地推理,推理精度将决定其性能。利用最新最先进系统的能量数据,我们表明这种本地推理可以将端到端应用程序性能提高400倍或更多。
近年来,深度神经网络(deep neural networks,DNNs)[44,66,69]在推理精度方面取得了长足的进步。DNNs依靠从许多例子中学习到的丰富模型,使用有限的、有噪声的输入实现复杂的推理。不幸的是,虽然DNNs比传统的替代方案[29,55]精确得多,但它们对计算的要求也更高。
典型的神经网络使用数千万的权值,需要数十亿的计算操作[44,66,69]。这些网络的目标是高性能、吞吐量优化的处理器,如GPU或谷歌的TPU,它每秒执行高达9万亿次的操作,同时消耗大约40瓦的功率[42]。即使是一个小的DNN(例如LeNet[46])也有超过一百万的权重和数百万的操作。最有效的DNN加速器优化性能和能源效率,消耗数百mW[11,12,26,31]。
挑战:与这些高性能系统形成鲜明对比的是,能量收集设备使用的是专为极低功耗操作而设计的简单微控制器(MCUs)。这些MCUs系统运行在低频(1-16MHz)下,具有非常小的内存(几万或几十万字节)。他们简单的架构限制了他们每秒执行几百万次操作,同时只消耗1-3mW的功率,比最近的DNN加速器低两个数量级。
对这些设备的DNN推断尚未探索,必须克服几个挑战,才能使新兴物联网应用于由商品组件构建的能量收集系统。最重要的是,随着电力供应的增加,能量收集系统会间歇性地运行,使高效、正确的软件开发变得复杂。操作周期取决于电力系统的特性,但通常较短——大约100000条指令。因此,现有DNN推理实现不能容忍间歇操作。
最近的工作提出了一种软件系统,它保证了任意程序在间歇电源上的正确执行[16,36,37,51,52,74]。这些系统增加了大量的运行时开销以确保正确性,在我们的实验中,将DNN推理速度平均降低了10倍。这些系统错过了利用计算结构降低保证正确性成本的机会。对于像DNN推理这样高度结构化和循环繁重的计算,这种错过的机会尤其昂贵。
我们的方法和贡献:本文首次展示了在一个广泛可用的能量收集系统上运行的现实世界神经网络上的间歇DNN推理。我们做出以下贡献:
- 我们首先分析能量收集系统中的能量消耗位置,并表明推断精度在很大程度上决定了物联网应用性能(第三章)。这鼓励了使用DNNs,尽管它们比简单但不太准确的推理技术增加了成本。
- 基于这一分析,我们提出了GENESIS,一种自动压缩网络以最大化物联网应用性能的工具(第五章)。GENESIS使用已知的压缩技术[9,14,32,57];我们的贡献是GENESIS优化地平衡了推理能量和准确性。
- 我们设计并实现了SONIC,一个用于DNN推断的软件系统,该系统专门支持间歇执行(第六章)。为了确保在低开销下的正确性,SONIC引入了循环延续,它利用DNN推理的规则结构选择性地违反了以前工作中基于任务的抽象[52],允许直接修改非易失性存储器。循环延续是安全的,因为SONIC通过循环顺序缓冲(loop-ordered buffering,对于卷积层)和稀疏撤销日志(sparse undo-logging,对于全连接层)确保循环迭代是等幂的。这些技术可以让SONIC在断电后从中断的位置恢复,消除任务转换和浪费的工作,这些工作困扰着以前的基于任务的系统。
- 最后,我们构建了TAILS,展示如何将硬件加速融入SONIC(第七章)。TAILS使用一些微控制器中可用的硬件来加速矩阵乘法和卷积。TAILS会自动校准其并行性,以确保间歇供电的正确性。
我们使用射频能量采集器[4,5]在TI MSP430微控制器[2]上评估SONIC & TAILS(第八、九章)。在三个真实世界的DNNs上[39,46,64],SONIC比Alpaca[52]平均提高了6.9倍的推理效率,Alpaca是一个最先进的间歇系统。TAILS利用DMA和SIMD进一步将效率平均提高12.2倍。
我们总结了并行间歇结构的未来研究方向,避免了当前能量收集MCUs的局限性,并提供了新的特性来有效地支持间歇(第十章)。
2. Background
能量收集装置使用从其环境中提取的能量进行操作。收集到的能量不是连续可用的,因此能量收集设备在能量允许的情况下间歇工作。先前的研究表明,间歇性执行会导致内存不一致,影响进程,并遭受不终止条件的影响。此外,典型的能量收集装置是严重的资源紧张的,增加了资源管理的复杂性。为了激发SONIC&TAILS的贡献,我们总结了资源受限设备上间歇执行的挑战,并描述了先前间歇执行模型的低效性。
2.1. Intermittent execution on energy-harvesting devices
当环境中的可收获功率低于装置的工作功率时,能量收集装置间歇工作。为了在电力不足或周期性不可用的情况下运行,设备在硬件缓冲器(如电容器)中缓慢地积累能量,并在缓冲器满时运行。该装置在工作时耗尽缓冲区的能量,然后断电,等待缓冲区再次充满。
软件在能量收集装置的间歇执行模型中执行[10,41,51,53,54,62]。在间歇执行中,软件以突发的方式进行,在频繁的电源故障时重置。现有设备[2,72]混合易失性状态(例如,寄存器和SRAM)和非易失性存储器(例如,FRAM)。当非易失性存储器持续存在时,电源故障清除易失性状态。重复的电源故障阻碍了进程[62],并且可能由于部分或重复应用的非易失性内存更新而导致内存不一致[51]。这些进度和一致性问题会导致不正确的行为,从而偏离任何持续供电的执行[15]。
先前的工作使用软件检查点[37,51,74]和基于原子任务的编程模型[16,36,52]来解决进度和内存一致性问题。基于任务的系统在断电后重新启动,在最近的任务或检查点使用一致的内存。我们关注基于任务的模型,因为之前的工作表明,它们比检查点模型更有效[16,52]。
基于任务的间歇执行模型:基于任务的间歇执行模型通过在断电后重新启动任务来避免频繁的检查点,此时必须重新初始化所有寄存器和堆栈状态。为了确保内存一致性,任务确保部分任务执行的效果对后续的重新执行不可见。具体地说,读取然后写入的数据(即依赖于WAR)可能会暴露中断任务的结果。基于任务的系统通过重做日志记录(redo-logging)[52]和静态重复数据(static data duplication)[16]避免了“the WAR problem”。
基于任务的系统保证了正确的执行,但运行时开销很大。重做日志记录和静态复制都会根据写入的数据量按比例增加内存和计算。从一个任务过渡到下一个任务需要时间,因此任务很短,因此过渡常常会导致性能下降。长任务可以更好地分摊过渡成本,但在断电后会重新执行更多的工作。更糟糕的是,如果任务太长,需要的能量超过设备可以缓冲的能量,则任务将面临不终止。
我们用SONIC&TAILS解决的一个关键挑战是确保DNN推理的正确执行,同时避免以前基于任务的系统开销。我们通过SONIC循环延续来实现这一点,它通过允许WAR依赖性来循环索引变量,安全地“打破现有任务系统的规则”(第六章)。这是安全的,因为SONIC确保每个循环迭代都是等幂的。循环延续产生了巨大的收益,因为它有效地消除了重做日志记录、任务转换和浪费的工作。
资源约束:间歇系统资源严重受限。在本文中,我们研究了使用TI MSP430微控制器(MCU)构建的间歇系统,它是现有间歇系统中最常用的处理器〔17,33,34,35,65〕。这种MCU的频率通常为1-16MHz,与成熟的、基于2GHz Xeon的系统相比,留下了相当大的性能差距。间歇式系统的MCU通常还包含系统可用的所有内存,包括易失性的嵌入式SRAM和非易失性的嵌入式FRAM。嵌入式存储器体积小,容量因设备而异。典型的MSP430低功耗MCU包括1–4KB的SRAM和32–256KB的FRAM。虽然连续供电的嵌入式系统可能包括通过串行总线(i2c或SPI)可访问的更大内存,但大多数间歇式系统并不是由于其高访问能量和延迟。间歇系统的典型工作功率约为1mW。
2.2. Efficient DNN inference
深度神经网络(DNN)正成为从理解语音到图像识别等推理应用的标准[44,66,69]。架构界已经用加速器来响应,这些加速器可以提高推理和训练的性能,并降低功耗。一些架构关注密集计算[11,12,13],另一些关注稀疏计算[26,31,45,75],还有一些关注CNN加速[6,7,23,60,63,67]。工业界一直遵循这一趋势,为DNNs提供定制硅[42]。
最近的其他工作集中在降低DNN推理成本的算法技术上。接近零的权重通常可以“剪枝”而不会损失太多的精度[32,57]。推理也不需要全精度浮点运算,而权重精度的降低[22,31]降低了存储和计算成本。存储和计算的额外减少来自于对DNN计算的因子分解[9,14,40,59,68,70,71]。
尽管做出了这些努力,但对于能量收集系统来说,功耗仍然保持很高的数量级。即使在最有效的加速器上,DNN推断也会消耗数百毫瓦的能量[3,12,31]。最近电路界的节能DNN工作[27,61]在一定程度上降低了功耗,但在可编程性上有所妥协。
更重要的是,在所有这些先前的努力中,间歇操作仍然没有得到解决。这是本工作要解决的关键问题。
二值神经网络:为了进一步减少推理能量,一些系统将权值压缩到一个或几个位[18,24,43,49,50]。二值神经网络可能看起来很适合于能量收集系统,但由于几个原因,它们是有问题的。二值网络需要比等效DNN更多的参数来保持精度。因此,它们的内存占用经常超过我们设备的不足内存:例如,一个99%-accurate的MNIST二值网络需要4.4MB的权重[18],将其压缩到360KB会损失近10%的精度[8]。相比之下,GENESIS只有192KB,准确率达到99%。此外,商用微控制器缺乏降低精度模型所依赖的体系结构支持,如“人口计数”指令和本机降低精度算法[24,43]。在软件中模拟这些操作的成本将压倒较小权重带来的任何潜在好处。基于这些原因,我们得出结论,二值网络不太适合商业能量收集系统,尽管我们认为它们值得在未来的专门架构中考虑(第十章)。
3. Motivation for intermittent inference
如果没有“超越边缘”的智能,许多有吸引力的物联网应用将不切实际。这些设备上的通信成本太高,云计算等解决方案不太实用。取而代之的是,能量收集设备必须在本地决定如何消耗能量,例如何时传送传感器读数或何时激活昂贵的传感器,例如高分辨率相机。
本节说明了对能量收集、间歇操作装置的推断。我们展示了通信如何主宰能源,即使是最先进的低功耗网络,使得云计算不切实际。我们分析了能量消耗的位置,并表明,在一阶上,推理精度决定了系统性能,从而推动了DNNs在这些应用中的使用。使用这种分析,我们将比较不同的DNN配置,并找到一个最大化应用性能(第五章)。
3.1. The need for inference beyond the edge
今天,许多应用程序通过向云发送输入数据并等待响应,将大部分计算转移到云。不幸的是,通信不是免费的。事实上,在能量收集设备上,通信比本地计算和传感消耗的能量高出一个数量级。这些高成本意味着,即使在当今最高效的网络架构上,能量收集设备也无法将推理转移到边缘或云上。
例如,最新的OpenChirp网络架构允许传感器以极低的功耗远距离发送数据。为了发送一个8字节的数据包,一个地面传感器在大约800ms的时间内抽取120mA的电流[25]。使用最近的Capybara能量收集电力系统[17],这样的传感器将需要一个900mF电容器组发送一个8字节的数据包。这个大电容器阵列对设备施加了有效的占空比,因为设备在充电时必须空闲,然后才能发射。一个在阳光直射下拥有2cm x 2cm太阳能电池阵列的Capybara传感器节点(一个乐观的设置)需要大约120秒才能为一个900mF的电容器组充电[17]。因此,将每像素1B的单个28 x 28图像(例如,一个MNIST图像[47])发送到云中进行推断需要一个多小时。
相比之下,我们的全系统SONIC原型仅在10秒内对微弱的、采集到的射频能量进行局部推断——提升超过360倍。因此,SONIC&TAILS为能量收集设备上全新的推理驱动应用打开了大门。
3.2. Why accuracy matters
我们现在考虑一个示例应用程序,以说明推理精度如何决定端到端应用程序的性能。这种分析鼓励使用最先进的推理技术,即DNNs,而不是像支持向量机这样精度较低但成本较低的技术。
为了得出这些结论,我们采用了一个高层次的分析模型,将系统中的能量分为感知、通信和推理。(传感包括所有相关的本地处理,例如,设置传感器和后处理读数。)我们使用本地推断过滤传感器读数,以便仅传送“有趣的”传感器读数。我们的优点是可以以固定的捕获能量,发送感兴趣的传感器读数的数量(这也是执行时间的一个很好的替代)。我们把它表示为IMpJ,或者每焦耳感兴趣的信息。虽然这个指标没有捕捉到由于推断错误(即假阴性)而没有传达的感兴趣读数,但我们的分析表明需要高精度。
这个简单的模型捕捉了许多超出边缘的有趣的推理应用:例如,野生动物监测、灾难恢复、可穿戴设备、军事等。具体来说,我们考虑一个野生动物监测应用,其中带有小摄像头的传感器部署在具有OpenChirp连接性的广阔区域。这些传感器监测当地的刺猬种群,并在检测到刺猬时通过无线电发送图片。其目标是尽可能多地捕捉刺猬的图像,没有刺猬的图像没有任何价值。

无推断基线:我们的基线系统不支持本地推断,因此它必须传达每个图像。通信成本很高,所以这个基线系统性能不好。假设传感消耗Esense能量,通信一个传感器读数消耗Ecomm能量,感兴趣的事件以基本速率p发生(见表1)。然后,基线系统为每个事件花费Esense+Ecomm能量,其中只有占比为p的事件值得交流,其IMpJ为:

理想:虽然不可能建立,但理想的系统只传送感兴趣的传感器读数,即所有事件的一小部分p。因此,其IMpJ为:
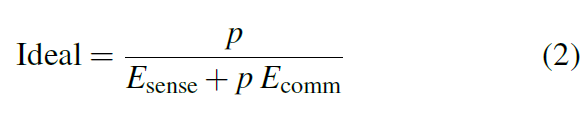
Oracle:类似地,Oracle系统只会传递感兴趣的传感器读数,但在这种情况下,推理是不自由的。它的推断是完全正确的,但是Oracle必须花费更多的能量来决定它是否值得通信。因此,Oracle有效地增加了感知成本,其IMpJ为:

本地推理:最后,我们考虑一个推理不完全准确的现实系统。与Oracle一样,每个传感器的读取都需要花费Esense+Einfer的能量。假设推理的真阳率为tp,真阴率为tn。由于通信非常昂贵,性能会受到错误通信、不感兴趣的传感器读数的影响,其概率为:(1-p)(1-tn)。其IMpJ为:
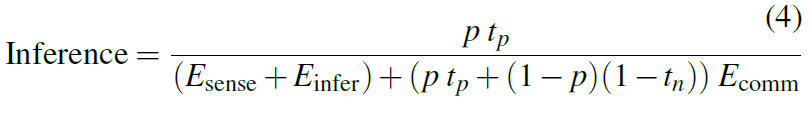
案例研究:野生动物监测:我们现在将此模型应用于早期的野生动物监测示例。刺猬是与世隔绝的动物,所以“有趣”的照片很少见,比如P=0.05。低功耗摄像头允许在低能耗下拍摄图像,例如,Esense ≈ 10mJ[58]。正如我们在上面看到的,传送图像是昂贵的,在OpenChirp[25]上使用Ecomm ≈ 23000mJ。最后,根据我们的SONIC&TAILS原型,推断需要Einfer ≈ 40mJ。
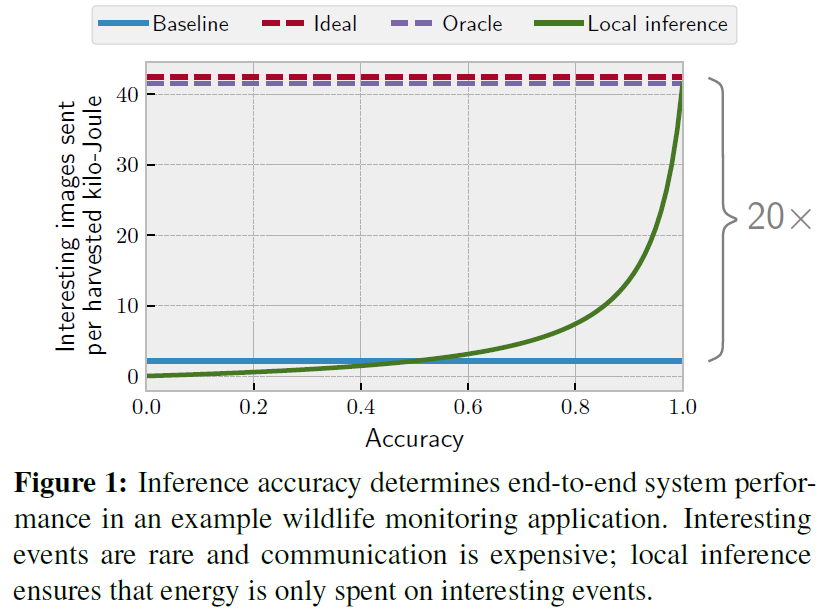
图1显示了将这些值插入模型后每个系统的IMpJ。为了简单起见,此图假定真阳率和真阴率相等,称为“准确度”。由于通信支配着能源预算,因此本地推理可以在1/p = 20x的量级上实现大的端到端收益。推断是不贵的,即使是相对罕见的事件;也就是说,Oracle非常接近理想。然而,要在实践中实现这些收益,推理必须是准确的,而且随着推理准确度的下降,收益迅速下降。当p值变化时,虽然效益的大小发生了变化(随着p值的减小而增大),但得到了定性相似的结果。
只发送推断结果:根据应用程序的不同,只发送推断结果而不是完整的传感器读数可以实现更大的端到端改进。例如,在这个野生动物监测示例中,能量收集设备可以在检测到刺猬时发送一个数据包,而不是发送完整的图像。其效果是显著降低了具有本地推理的系统的Ecomm,缓解了系统的瓶颈。在我们的野生动物监测例子中,Ecomm减少了98倍。
图2展示出仅发送推断结果时的端到端性能。本地推理可以显著降低通信能量:在没有本地推理的情况下,比起基线系统,可以检测和通信480倍多的事件。然而,这些降低也意味着推断是不可忽略的能源成本,Oracle与理想的差距是2.2倍——即使使用SONIC&TAILS的优化能源成本。这一差距很难在现有硬件上进一步缩小;我们将在第十章中讨论解决这一问题的方法。
假阴性:精确性在另一个维度上也很重要,特别是在只有推理结果被传达的情况下。如果感兴趣的事件是罕见的,那么就需要高精度,这样假阴性的噪声就不会引出真正感兴趣事件的信号。当p=0.05时,准确度(真阴性率)大约需要95%。这种考虑与图2一致:即使以更昂贵的推理为代价,也需要高的推理精度。因此,我们关注SONIC&TAILS中的深度神经网络,因为它们是最精确的,尽管我们的技术也有利于支持向量机等不太精确的方法。

4. System overview
本文描述了第一个在间歇运行的能量收集装置上有效地进行DNN推断的系统。图3展示出了本工作中的新系统组件,以及它们如何从高层DNN模型描述开始产生高效、间歇安全的可执行文件。这个系统有三个主要组成部分:GENESIS、SONIC和TAILS。
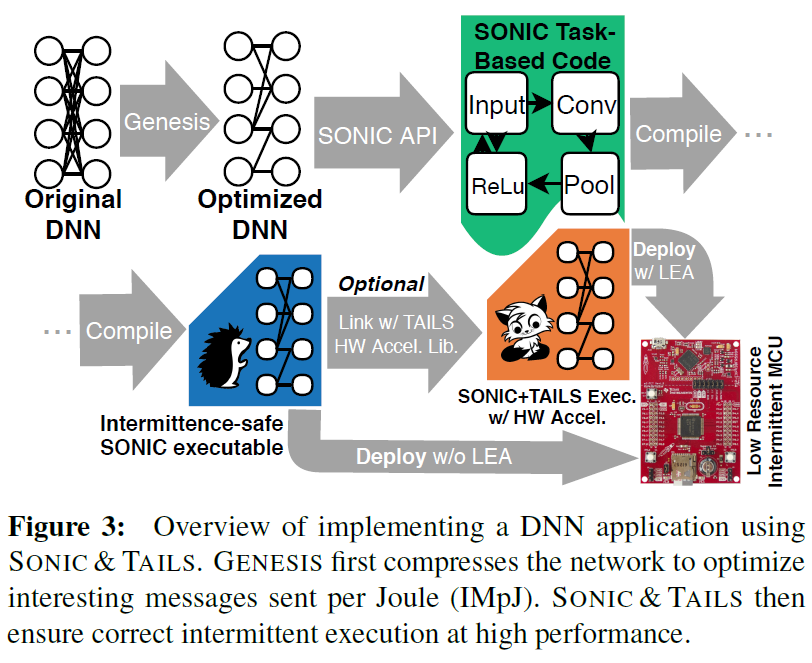
GENESIS(在间歇系统上生成能量感知网络以提高效率)是一个工具,它可以自动优化DNN,从程序员对网络的高级描述开始。GENESIS试图使用分离和修剪技术压缩网络的每一层。GENESIS的目标是找到一个在满足资源限制的同时优化IMpJ的网络。如图所示,GENESIS的输入是一个网络描述,其输出是一个优化压缩的DNN模型。第五章详细描述了GENESIS。
SONIC(仅软件的神经间歇性计算)是一种间歇性安全、基于任务的API和运行时系统,它包括DNN推理的专门支持,它安全地“打破现有任务系统的规则”以提高性能。SONIC与现有的基于任务的框架[16,52]兼容,允许无缝集成到更大的应用程序中。第六章详细描述了SONIC。
TAILS(tile-accelerated intermittent LEA support,tile加速间歇式LEA支撑)是SONIC运行库的替代品,它利用硬件矢量加速,特别针对TI低能量加速器(LEA)[1]。要使用TAILS,程序员只需要将编译后的二进制文件链接到启用TAILS的运行时系统。此运行时包括SONIC的所有优化和一套硬件加速向量操作,如卷积。第七章详细描述了细节。
从高级网络描述开始,程序员可以使用GENESIS、SONIC和TAILS来构建一个高效的、支持间歇DNN的应用程序,该应用程序满足资源约束,对间歇操作具有健壮性,并提供广泛可用的硬件加速。本文出版后,我们将开放我们所有的代码和数据集。
5. Optimal network compression with GENESIS
SONIC&TAILS要克服的第一个挑战是将神经网络拟合到能量收集系统的资源约束中。特别是,当前微控制器的有限存储容量对网络施加了硬约束。我们开发了一个名为GENESIS的工具,该工具应用分离和修剪技术(第二章),自动探索基线神经网络的不同配置,减少网络的资源需求。GENESIS改进了这些已知技术,通过在第三章中建立的模型,通过推理能量与真阳率和真阴率之间的平衡优化来最大化IMpJ。
5.1. Neural networks considered in this paper
本文考虑了三个网络,总结见表2。为了表示基于图像的应用程序(例如,野生动物监测和灾难恢复),我们考虑了MNIST[47]。我们考虑MNIST而不是ImageNet,因为ImageNet的大图像不适合资源受限设备的内存。为了表示可穿戴应用,我们考虑了人类活动识别(HAR)。HAR使用加速度计数据对活动进行分类[39]。为了表示音频应用程序,我们考虑了Google keyword spotting(OkG)[64],它对音频片段中的单词进行分类。我们也评估了几个支持向量机模型,但是没有一个适合于设备的支持向量机模型能够与DNN模型竞争[48]:由IMpJ测量,MNIST上的支持向量机执行性能差2倍,HAR上的支持向量机执行性能差8倍,并且我们找不到OkG的支持向量机模型能够接近DNN的性能。
5.2. Fitting neural networks on energy-harvesting systems
GENESIS评估了一个网络的许多压缩配置,并建立了Pareto边界。压缩在四个维度上有折衷,很难用pareto曲线来捕捉;这些维度包括真阴率、真阳率、内存大小(即参数)和计算/能量(即操作)。全连接层通常控制内存,而卷积层控制计算。GENESIS压缩了两者。
GENESIS用两种已知的技术压缩每一层:分离和修剪。分离(或秩分解)将m x n全连接层拆分为两个m x k和k x n矩阵乘法,或将m x n x k卷积滤波器拆分为三个m x 1 x 1、1 x n x 1和1 x 1 x k滤波器[9,14]。GENESIS使用Tucker张量分解与高阶正交迭代算法来分离层[20,21,73]。剪枝包括删除低于给定阈值的参数,因为它们对结果的影响很小[32,57]。
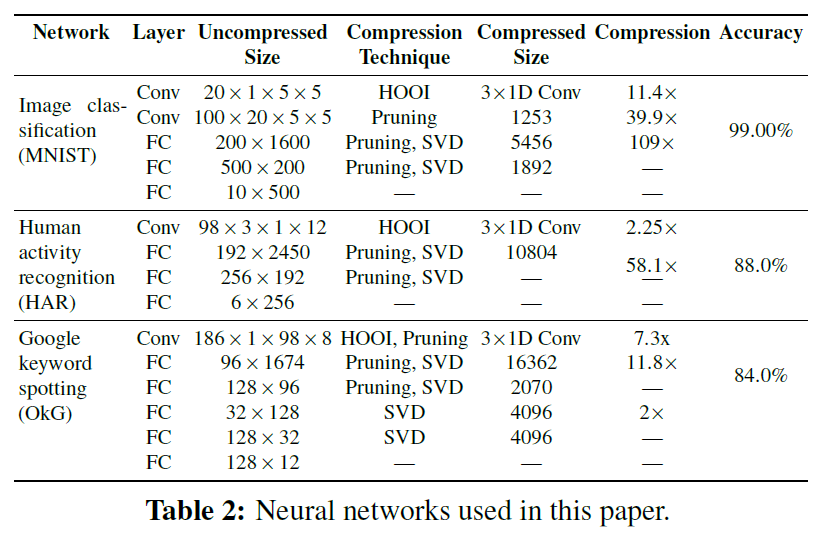
GENESIS在网络的每一层都扫描分离和修剪的参数,在压缩后重新训练网络以提高准确性。GENESIS依靠带有中值停止规则(Median Stopping Rule)的Ray Tune黑盒优化器来探索配置空间[28,56]。图4展示出了表2中的网络结果。图上的每个标记代表一个压缩配置,通过y轴上的推断精度和x轴上的推断能量来表示。可行的配置(即适合我们设备小内存的配置;请参阅第八章)显示为绿色圆圈,不可行配置为灰色 x。请注意,原始配置(大x)对所有三个网络都不可行,这意味着它们不能简单地移植到设备,因为它们的参数不适合内存。
图4还展示出了每种压缩技术的Pareto边界。一般来说,修剪比分离更有效,但这些技术是互补的。
5.3. Choosing a neural network configuration
GENESIS使用第三章的模型估计了一个配置的IMpJ,特别是公式4。用户为其应用程序指定了Esense和Ecomm,并按计算操作能源成本。根据这些参数,GENESIS为每个配置估计Einfer,并使用来自先前训练步骤的推断精度来估计应用程序性能。用户可以指定训练集中的哪个类是“有趣的”,让GENESIS计算特定应用程序的真阳率tp和真阴率tn。
图5展示了通过模型映射图4中的每个点的结果。对于这些结果,我们使用第三章的Esense,第八章里我们的SONIC&TAILS原型中每次操作的能量,并假设OpenChirp网络[25],根据输入大小估计Ecomm。
GENESIS选择可行的配置,最大化估计的端到端性能(即IMpJ)。图5展示了该选择是非平凡的。推理能量和准确性都会影响端到端的应用性能,简单地选择最精确的可行配置是不够的,因为它可能会浪费太多的推理能量。
真阳率、真阴率和推断能量以难以预测的方式影响端到端应用程序的性能。简单地选择最精确的配置,就像扭曲的蓝色曲线在??中所暗示的那样,是不够的,因为它可能会浪费太多的能量,或在真阳率或真阴率上表现不佳。
6. Efficient intermittent inference with SONIC
SONIC是第一个针对资源受限、间歇操作设备进行推理优化的软件系统。SONIC支持大多数DNN计算中常见的操作,通过一个简单的API向程序员公开这些操作。SONIC的功能是作为SONIC运行时系统支持的任务集合实现的,SONIC运行时系统是Alpaca运行时系统的修改版本[52]。这些任务实现DNN功能,SONIC运行时系统保证正确的间歇操作。
对DNN推断的专门化间歇支持产生了很大的好处。以前的基于任务的间歇执行模型[16,52]可以将性能平均降低19倍和10倍(第九章)。SONIC大大降低了这些开销,比标准的DNN推理实现减少到仅25%-75%,DNN推理不允许间歇操作。
SONIC通过消除以前基于任务的系统中的三个主要开销来源来实现这些增益:重做日志记录、任务转换和浪费的工作(第二章)。我们的关键技术是循环延续,它有选择地违反了循环索引变量的任务抽象。循环延续允许SONIC直接修改循环索引,而无需频繁和昂贵的保存和恢复。通过将循环索引直接写入非易失性内存,SONIC在每次循环迭代后检查其进程,消除了昂贵的任务转换,并在断电时浪费了工作。
循环延续是安全的,因为SONIC确保每个循环迭代都是等幂的。SONIC分别通过循环顺序缓冲和稀疏撤销日志来保证卷积层和完全连接层的幂等性。这两种技术确保了在不静态私有化或动态检查点数据的情况下的幂等性。
6.1. The SONIC API
表3列出了顶级SONIC API及其用途。为了调用接口,程序员填充一个层调用数据结构。层调用结构包含神经元权重、偏差、输入激活数据的计数和值,以及保存调用结果的内存位置。填充数据结构后,程序员将其推送到全局任务调用堆栈中,指定应成功调用的应用程序级任务,并转换到接口的任务。完成后,接口任务转换到指定的后续任务,应用程序继续。
SONIC API允许程序员通过常见的线性代数原语描述DNN的结构。正如程序员在基于任务的间歇编程模型[16,36,52]中将任务链接在一起一样,程序员将SONIC的任务链接在一起,以表示DNN推理流水线的控制和数据流。SONIC的API公开了程序员调用的功能,就像他们程序中的任何其他任务一样(特别是模块化任务组[16,52])。尽管SONIC“打破了”典型的基于任务的间歇系统的规则,但是程序员在使用SONIC API编写程序时不需要解释这些差异。SONIC提供的程序级行为保证与其他基于任务的间歇执行模型相同:SONIC任务将通过确保重复的、中断的执行尝试是等幂的,从而在断电的情况下以原子方式执行。

6.2. The SONIC runtime implementation
DNN推理由神经网络各层中的循环控制。SONIC通过确保这些循环在间歇功率下正确执行,同时比以前的基于任务的系统增加更少的开销,从而优化DNN推断。
任务型系统中的循环:典型的任务型间歇系统有两种循环:短循环和长循环。短循环的所有迭代都适合一个任务,并且将在不消耗设备所能缓冲的能量的情况下完成。短回路在易失性存储器中保持控制状态,这些变量在断电时清除。当电源恢复时,任务将重新启动并完成。短循环操作的数据通常是非易失性的(即“任务共享”[52]),如果读取和更新,则必须备份(静态或动态)以确保它们保持一致。短循环的问题是它们总是从头开始,浪费地重复已经完成的循环工作。相比之下,一个具有多个迭代的长循环不适合一个任务;一个长循环需要比设备能够缓冲的更多的能量,并且可能永远不会终止。程序员必须将循环迭代拆分为多个任务,要求在每次迭代时进行任务转换,并要求控制状态和数据不易失性和备份。长循环的问题在于,它们可能导致不终止,并且在跨任务拆分时,会带来巨大的私有化和任务转换开销。
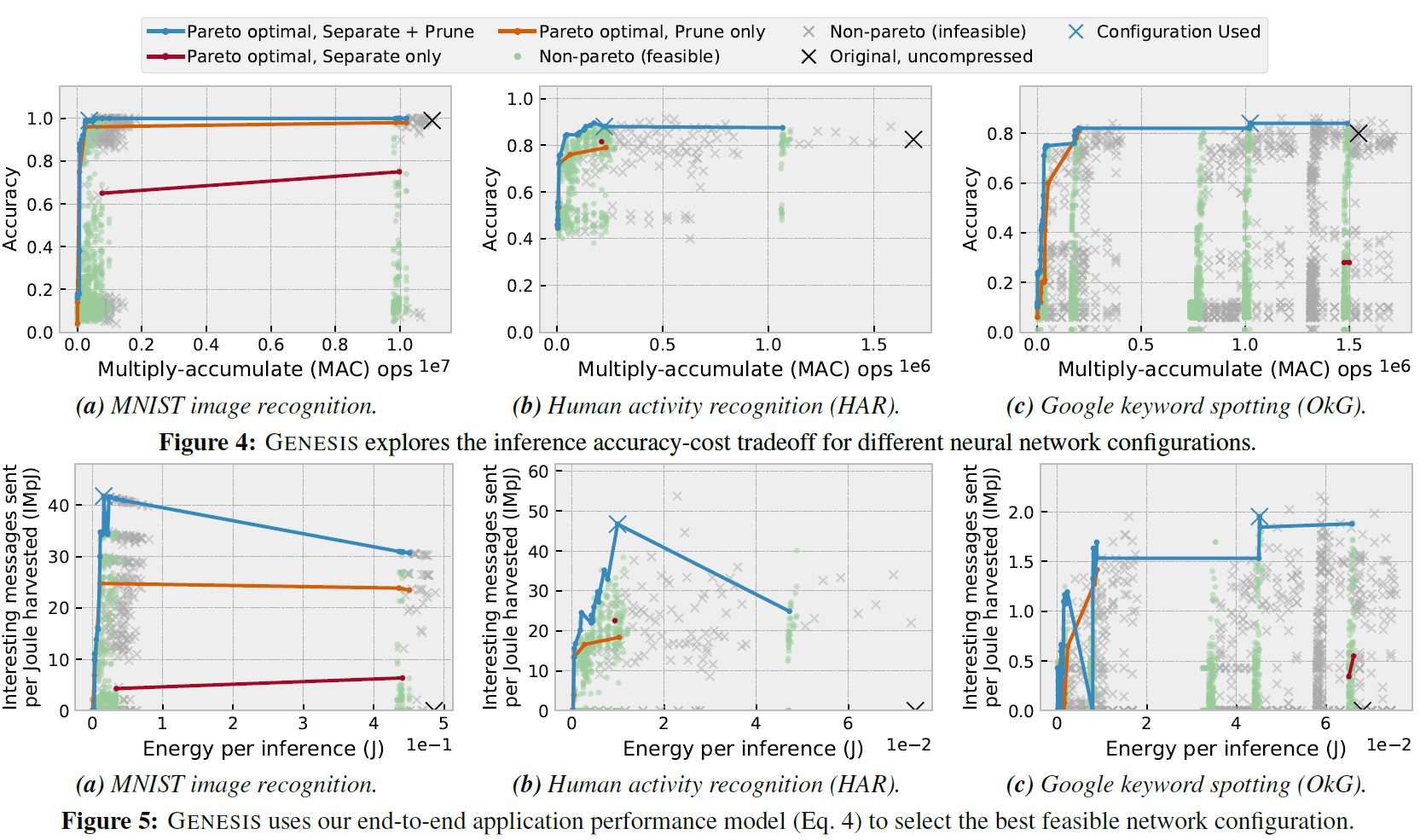
任务平铺是将循环的迭代分解为任务的简单方法。任务平铺循环对每个任务执行固定数量的迭代。任务平铺分摊了任务转换开销,但有可能在单个任务中执行的迭代次数超过设备的能量缓冲区所能支持的次数,从而导致不终止。图6显示了循环的间歇执行,使用左边的能量轨迹计算点积,使用5(Tile-5)和12(Tile-12)两个固定的tile大小。Tile-5在失败前完成四次迭代时浪费工作。Tile-12阻碍前进,因为设备缓冲的能量不足,无法完成12次迭代。
6.2.1. Loop continuation
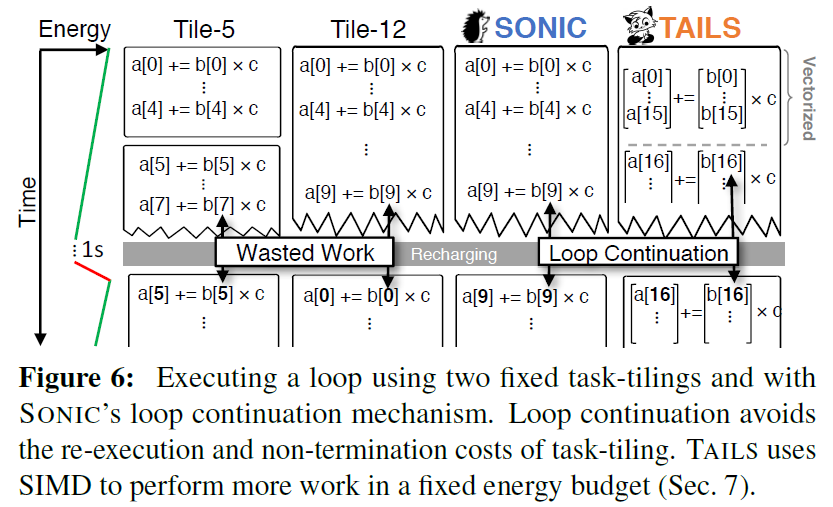
SONIC的循环延续是一种间歇性安全优化,可以避免在包含长时间运行的循环嵌套的任务中浪费工作、不必要的数据私有化和任务转换开销。循环延续的工作方式是直接修改循环控制变量和在循环嵌套中操作的内存,而不是在任务之间分割长时间运行的循环。循环延续允许在单个任务中循环任意的迭代次数,既不终止也不过度的状态管理开销。循环延续将循环的控制变量和直接操作的数据存储在非易失性内存中,而无需备份。当循环继续任务重新启动时,其(易失性)局部变量将在任务开始时重新初始化。但是,循环控制变量保留其状态,循环从上次尝试的迭代开始继续。
图7展示了通过将Task_Convolve的循环控制状态存储在非易失性存储器中,循环继续如何工作。SONIC通过在迭代结束时更新循环的控制变量i,而不是在重新执行时重置它,来确保循环的控制变量i是正确的。控制变量更新期间或之后的电源故障可能需要循环体嵌套重复一次迭代,但它从不跳过一次迭代。
图6显示了SONIC使用循环继续执行。尽管电源中断,但在第九次循环迭代时仍会继续执行,而不是重新启动整个循环嵌套或每五次迭代(Tile-5)。

6.2.2. Idempotence tricks
通常,从循环嵌套的中间重新启动可能会使被操纵的数据部分更新,并且可能不一致。但是,循环延续是安全的,因为SONIC的运行时系统使用循环顺序缓冲或稀疏撤消日志来确保每个循环迭代都是等幂的。SONIC从不要求迭代中的某个操作读取同一迭代中另一个操作生成的值。因此,由于电源中断而重复重新执行的迭代将始终看到正确的值。
循环顺序缓冲:循环顺序缓冲是用于卷积层(和密集的全连接层)的双重缓冲机制,确保每个循环迭代都是等幂的,而无需昂贵的重做日志记录(参见[52])。由于MSP430设备没有复杂的缓存机制,而不是优化重用和数据位置,SONIC优化了提交所需的项的数量。通过在DNN推断中对循环重新排序,并根据需要对部分激活进行双缓冲,SONIC能够完全消除循环迭代中的提交。
评估稀疏或密集卷积需要SONIC对层的整个输入激活矩阵应用滤波器。SONIC命令循环迭代,在转到下一个过滤器元素之前,将过滤器的每个元素应用到输入激活的每个元素(即将它们相乘)。对于等幂,SONIC将部分累积的值写入中间输出缓冲区,而不是将更新应用到适当的输入矩阵。在对输入中的每个条目应用一个过滤器元素并将部分结果存储在中间缓冲区中之后,SONIC将输入缓冲区与中间缓冲区交换,并继续移动到下一个过滤器值。
由于SONIC从不在一次迭代中读取和写入相同的内存位置,因此它避免了第2.3节中描述的WAR问题。因此循环迭代是等幂的。图7显示了在循环顺序缓冲下,SONIC在计算Task_Convolve中的部分结果时从不读取和写入同一矩阵缓冲区。完成此任务后,SONIC转换到Task_Next_Filter,后者交换缓冲区指针并从过滤器获取要应用的下一个值。
稀疏撤消日志记录:虽然循环顺序缓冲足以确保每个循环迭代都是等幂的,但有时它是不必要的浪费。出现这个问题是因为循环顺序缓冲在每个任务完成后在缓冲区之间交换,所以它必须在缓冲区之间复制数据,即使数据没有被修改,以防将来读取数据。这种复制在稀疏的全连接层上是浪费的,在这些层中,大多数过滤器权重被剪除,因此在一次迭代中很少修改激活。通过循环顺序缓冲,SONIC最终花费了大部分时间和精力在缓冲区之间复制未经修改的激活。
为了消除这种低效性,SONIC引入了稀疏撤销日志,通过撤销日志而不是双缓冲来确保幂等性。为了确保原子性,稀疏撤消日志记录通过两个索引变量(读和写索引)跟踪循环的进度。应用筛选器时,SONIC首先将原始的未修改激活复制到规范内存位置,然后增加读取索引。SONIC然后计算修改后的激活并将其写回原始激活缓冲区(没有单独的输出缓冲区)。然后它增加写索引并继续下一次迭代。这种两阶段的方法保证了正确的执行,因为如果更新过程中出现电源故障,稀疏撤消日志记录将从缓冲的原始值恢复计算输出值。
稀疏撤消日志记录确保每个任务的工作随着所做修改的数量而增长,而不是输出缓冲区的大小(与循环顺序缓冲不同)。但是,稀疏撤销日志记录使每次迭代的内存写入次数增加了一倍,因此在大多数数据被修改的密集层上效率低下,因此循环顺序缓冲的效率显著提高。最后,请注意,与以前的基于任务的系统不同,稀疏撤销日志记录确保了具有恒定空间开销的幂等性,并且在迭代之间没有任务转换。
7. Hardware acceleration with TAILS
TAILS通过结合广泛可用的硬件加速来提高SONIC的性能,从而更有效地进行推理。程序员可以选择将其SONIC应用程序链接到TAILS运行时系统,使应用程序能够使用直接内存访问(DMA)硬件来优化块数据移动,并使用简单的向量加速器,如TI低能加速器(LEA)并行执行操作。LEA支持有限冲激响应离散时间卷积(FIR DTC),直接实现DNN推理所需的卷积。
TAILS的一个关键特性使得其在间歇式能量收集装置中的有效使用是,TAILS运行时系统在运行时自适应地绑定硬件参数,以最大限度地提高操作吞吐量而不超过设备的能量缓冲区。我们的TAILS原型根据使用设备的固定能量缓冲区成功完成的操作数自适应地确定DMA块大小和LEA向量宽度。在校准这些参数之后,TAILS使用它们来配置可用的硬件单元,并在之后执行推断。
7.1. Automatic one-time calibration
在第一次执行之前,TAILS应用程序运行一个简短的递归校准例程,以确定DMA块大小和LEA向量大小。该例程确定可以将其最大化到LEA的操作缓冲器中的最大向量大小,使用FIR DTC的过程,以及DMA返回到非易失性存储器,而不超过设备的能量缓冲和阻碍进展。如果在电源故障前没有完成tile大小,则重新执行校准任务,将tile大小减半。当FIR DTC完成并且TAILS使用该tile大小进行后续计算时,校准结束。
7.2. Accelerating inference with LEA
一旦TAILS确定了它的tile大小,应用程序就会运行,使用DMA和LEA计算密集和稀疏卷积以及密集矩阵乘法。LEA有一些限制:它只支持密集操作,并且只能从设备的小4KB SRAM(而不是256KB FRAM)读取数据。TAILS使用DMA将输入移动到SRAM中,调用LEA,然后DMA将结果返回到FRAM。本机支持密集层:全连接层使用LEA的矢量MAC操作,卷积使用LEA的一维FIR DTC操作。为了支持二维和三维卷积,TAILS迭代地应用一维卷积并累积这些卷积的结果。TAILS使用循环顺序缓冲来确保对部分累积值的更新是等幂的。
稀疏操作需要更多的努力。TAILS使用LEA进行稀疏卷积,首先使滤波器密集(用零填充)。使过滤器致密化是很便宜的,因为每个过滤器都被多次重复使用,从而降低了其创建成本。然而,这确实意味着LEA执行不必要的工作,这有时会损害性能。基于这个原因,我们使用LEA的点积运算来代替1 x p x 1因子卷积层的FIR-DTC。
最后,稀疏的全连接层在LEA上是低效的,因为过滤器不能被重用。我们发现TAILS的大部分时间都花在填充过滤器上,尽管付出了很大的努力,我们还是无法使用LEA加速稀疏的完全连接层。因此,TAILS在软件中执行稀疏的全连接层,就像SONIC一样。
8. Methodology
在图8中的设置中,我们在16MHz的TI-MSP430FR5994[2]上实现SONIC和TAILS。该板连接到距3W动力脚轮发射器[5]1米远的动力脚轮P2210B[4]收集器。我们在连续电源和间歇电源上运行所有配置,使用三种不同的电容器大小:1mF、50mF和100μF。

在设备上运行代码:我们使用MSPGCC 6.4进行编译,使用TI的MSPDriverlib进行DMA,使用TI的DSPLib进行LEA。我们使用GCC而不是Alpaca的LLVM后端,因为LLVM缺乏对20位寻址的支持,并且为MSP430生成的代码比GCC慢。
测量:我们使用第二个MSP430FR5994测量间歇性执行。测量MCU上的GPIO引脚通过一个电平移位器连接到间歇装置,允许它计数重新启动和信号何时开始和停止计时。我们通过软件和硬件的组合来实现自动测量,这些软件和硬件编译配置二进制文件,将二进制文件闪烁到设备上,并与测量MCU通信以收集结果。系统启动一个继电器,在用于重新编程的持续电源和用于测试的间歇电源之间切换。
测量能量:通过计算GPIO脉冲之间的电荷周期数,我们可以确定在不同码区消耗的能量。对于更细粒度的方法,我们构建了一组微标号来计算特定操作(例如,FRAM的负载)在单个充电周期中可以运行多少次。然后我们分析在推理过程中每个操作被调用的次数,并按每个操作的能量进行缩放,以获得详细的能量分解。
比较基线:我们将SONIC和TAILS与四个DNN推理实现进行比较。第一个实现是一个标准的基线实现,它不允许间歇操作(它不终止)。其他三个实现基于Alpaca[52]并通过平铺迭代来分割循环,如图6所示。
9. Evaluation
我们现在对我们的原型进行评估,以证明:(i)SONIC&TAILS保证正确的间歇执行;(ii)SONIC&TAILS在最新技术中大大减少了推理能量和时间;以及(iii)SONIC&TAILS在各种网络中的性能良好,无需任何手动微调。
9.1. SONIC & TAILS significantly accelerate intermittent DNN inference over the state-of-the-art
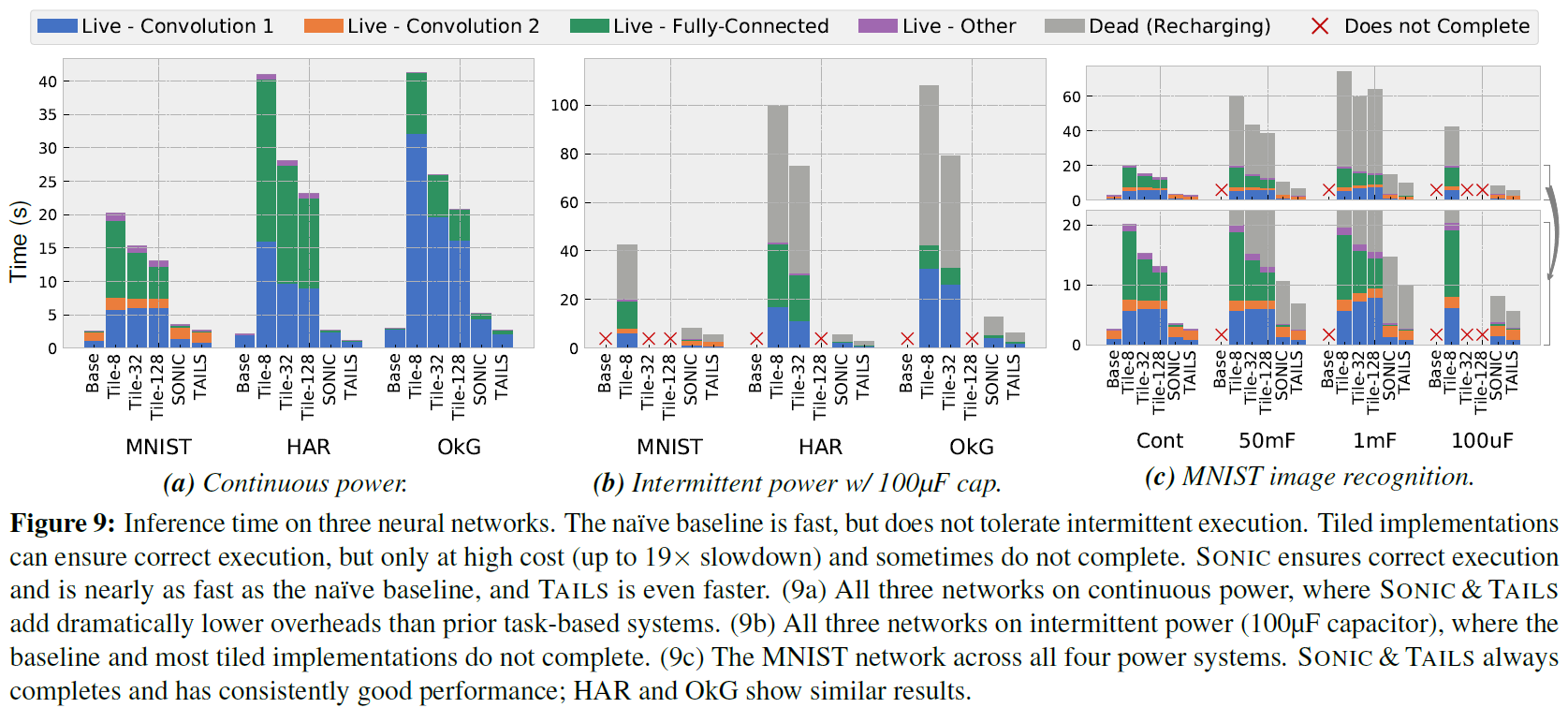
图9展示了我们考虑的三个网络的推理时间(表2)。对于每个网络,我们评估了在四个不同的电力系统上运行的六个实现。我们将推理时间分为:充电所花的死亡时间;每个卷积层(占主导地位)所花的活区时间;全连接层所花的活跃时间;以及其他一切。
首先,请注意SONIC&TAILS保证每个电力系统上的每个网络都能正确执行。这种情况不适用于原始基线,它不能在间歇电源下正常运行,也不适用于先前基于任务的间歇系统的大多数tile。唯一可靠地正确执行的另一个实现是Tile-8,因为它的tile很小,总是在一个充电周期内完成。其他tile在某些配置上失败:带100μF电容的MNIST上的Tile-32失败,而在100μF的所有网络上的Tile-128失败。
SONIC&TAILS保证在比Tile-8低得多的管理费用下正确执行。在整个网络中平均,Tile-8在连续功率下比原始基线慢13.4倍,而SONIC比基线慢1.45倍,TAILS比基线快1.2倍。换言之,SONIC比平铺Alpaca[52]平均提高6.9的性能,TAILS提高12.2倍。此外,SONIC&TAILS电容器的执行时间是一致的。
较大的tile大小在一定程度上分摊了管理费用,但由于它们不能在所有网络或电容器大小上完成,因此它们是一个不具吸引力的实现选择。SONIC&TAILS保证了所有电容器尺寸的正确间歇执行,同时也比最大的tile快:即使与Tile-128相比,SONIC在连续功率上平均快5.2倍,而TAILS快9.2倍。
DMA和LMA都提高了TAILS的效率。我们测试了由软件模拟DMA和LEA的配置,发现LEA一致地将性能提高了1.4倍,而DMA平均将性能提高了14%。
最终,这些结果表明,推断是可行的商品能量收集设备,并且SONIC&TAILS大大减少了管理费用,超过最先进的方法。
9.2. Loop-continuation nearly eliminates overheads due to intermittence
图10显示,SONIC&TAILS的间接费用主要来自支持间歇所需的控制。条形图中阴影较深的区域表示计算层内核(即主循环)所花时间的比例,而较浅的区域表示控制开销(即任务转换和设置/卸载)。基线和SONIC之间的性能差异主要归因于较轻的控制区域。这表明SONIC的循环延续和幂等技巧在原始基线上施加了很小的开销,该基线在寄存器中累积值并避免内存写入(但不允许间歇性)。
TAILS的开销也来自于控制;TAILS显著加快了内核的速度。由于LEA的定点表示,在调用FIR-DTC之前,TAILS的控制开销很大,这迫使TAILS进行位移激活。此外,LEA没有左移位操作(它有右移位),因此这些移位必须在软件中完成。这些移位占图10中控制时间的大部分。
图10还展示了Tile-32的时间分解。与SONIC&TAILS不同,Tile-32在控制和内核上花费的时间要多得多。这是因为Alpaca对所有写入的值使用重做日志以确保等幂性,因此每次写入都需要动态缓冲(内核时间)和在任务完成时提交(控制时间)。SONIC&TAILS有效地消除了重做日志,避免了这些开销。

9.3. SONIC & TAILS use much less energy than tiling
能量收集系统的大部分时间都是断电充电,因此执行时间在很大程度上取决于能源效率。图11显示SONIC&TAILS由于比其他方案需要更少的能量而获得高性能。在图9中,推断能量与充电所花费的停滞时间成正比。由于死亡时间支配着推理时间,SONIC&TAILS在推理能量方面的改进与它们在推理时间方面的相似。
9.4. Where does SONIC’s energy go?
图12通过示出在不同操作上花费的能量的比例来进一步表征SONIC。蓝色区域表示内存操作,橙色区域表示控制指令,绿色区域表示内核内的算术指令,紫色区域表示任务转移开销,灰色区域表示剩余的未计数能量。控制指令占SONIC能量的26%,另外14%的系统能量来自FRAM写入循环索引。理想情况下,这些开销将在许多内核操作中分摊,但这样做需要更高效的体系结构,正如我们在下一节中讨论的那样。
10. Future intermittent architecture research
我们在构建SONIC&TAILS方面的经验表明,通过一个内置支持间歇操作的并行架构,有很大的机会加速间歇推理。SONIC&TAILS通过专门的DNN推理演示了在低开销下执行间歇推理所必须跟踪的状态的基本原理。
然而,用于能量采集系统的典型微控制器不适合有效的推断,我们已经确定了几个机会,可以通过更好的硬件支持来显著改进它们。这些微控制器是顺序的单周期处理器,因此在“有用的工作”上花费很少的精力[38]。例如,通过从图12中减去nop指令的能量,我们估计SONIC将其40%的能量用于指令获取和解码。这在像DNN推断这样的高度结构化计算上尤其浪费,因为这些开销可以很容易地在许多操作中摊销[30]。
MSP430应该通过LEA提供这个缺少的支持,但是不幸的是LEA有很多限制。调用LEA是昂贵的,因此需要调用尽可能多的LEA工作。但是LEA只能读写一个小的(4KB)SRAM缓冲区,这限制了它的并行性。这也迫使SRAM和FRAM之间频繁、昂贵的DMA。DMA不能与LEA重叠,也不支持跨步访问或分散聚集。LEA只支持密集操作,这使得它比稀疏的全连接层上的软件效率低。LEA在支持方面有惊人的差距:它不支持向量左移或标量乘,迫使TAILS在软件中执行这些操作。而在软件中,整数乘法是一个内存映射的外设,需要4条指令设置,9个周期完成。总之,这些限制意味着sonic&tails花费的能量超过了必要的,并且有足够的空间通过更好的架构来提高推理效率。
此外,这种体系结构还有机会为间歇性提供内置支持。理想情况下,间歇式体系结构应该提供不同大小的非易失性存储器,允许经常保持的值(例如循环索引)驻留在小而有效的存储器中。由于易失性存储器需要较少的能量来访问,体系结构还应该为经常重复使用的值(例如卷积滤波器)提供易失性存储器,这些值足够大,不限制并行性。体系结构还应支持将值提交到非易失性存储器,例如,在电源故障前自动保存的寄存器和硬件缓冲区。这种支持将使SONIC&TAILS显著提高效率;例如,只要消除频繁写入循环索引的FRAM,就可以节省14%的系统能量。
最后,并行间歇体系结构在管理间歇、混合波动性和并行性方面面临新的挑战。并行架构通过在许多飞行中的操作中分摊管理费用来提高效率。但是,在飞行中,当动力失效时,操作次数越多,浪费的工作就越多。工作必须持续到非易失性存储器,但非易失性存储器比易失性存储器更昂贵。间歇性并行架构必须仔细平衡这些问题以使效率最大化[19, 30]。
11. Conclusion
本文认为,智能“超越边缘”将使物联网应用的新类别成为可能,并首次在商品能量收集系统上演示了有效的DNN推理。我们提出了一个高层次的分析,为什么推理精度重要,并使用这种分析,以建立GENESIS,一个工具,自动压缩网络,以最大限度地提高端到端的应用性能。SONIC&TAILS随后专门提供间歇性支持,以确保正确执行,而不受电源系统的影响,同时在最先进的技术上分别将管理费用减少6.9和12.2倍。
Intelligence Beyond the Edge: Inference on Intermittent Embedded Systems的更多相关文章
- Using QEMU for Embedded Systems Development
http://www.opensourceforu.com/2011/06/qemu-for-embedded-systems-development-part-1/ http://www.opens ...
- Important Programming Concepts (Even on Embedded Systems) Part V: State Machines
Earlier articles in this series: Part I: Idempotence Part II: Immutability Part III: Volatility Part ...
- Using an open debug interconnect model to simplify embedded systems design
Using an open debug interconnect model to simplify embedded systems design Tom Cunningham, Freescale ...
- Memory Leak Detection in Embedded Systems
One of the problems with developing embedded systems is the detection of memory leaks; I've found th ...
- NAND Flash memory in embedded systems
参考:http://www.design-reuse.com/articles/24503/nand-flash-memory-embedded-systems.html Abstract : Thi ...
- Single-stack real-time operating system for embedded systems
A real time operating system (RTOS) for embedded controllers having limited memory includes a contin ...
- Edge Intelligence: On-Demand Deep Learning Model Co-Inference with Device-Edge Synergy
边缘智能:按需深度学习模型和设备边缘协同的共同推理 本文为SIGCOMM 2018 Workshop (Mobile Edge Communications, MECOMM)论文. 笔者翻译了该论文. ...
- 《Design by Contract for Embedded Software》 翻译
原文: Design by Contract for Embedded Software (state-machine.com) Design by Contract is the single mo ...
- Embedded System.
Soc ( System on Chip) Soc is an integrated circuit (IC) that integrates all components of a computer ...
随机推荐
- 在excel中如何给一列数据批量加上双引号
在实际开发中,会遇到这样的需求,大量的数据,需要从配置文件里读取,客户给到的枚举值是字符串,而配置文件里的数据,是json格式,需要加上双引号,这样就需要使用Excel来批量格式化一下数据. 客户给到 ...
- 线程_ThreadLocal
import threading # 创建ThreadLocal对象 house = threading.local() def process_paper(): user = house.user ...
- python基础day3_str基础函数操作方法及for循环
字符串操作 s = 'uiehSdc hdsj$jfdks@' s1 = s.capitalize() #仅仅只首字母大写 print(s1) # 结果Uiehsdc s2 = s.upper() # ...
- 探究:编程语言那么多,为什么偏偏是 C 语言成了大学的必修课?
谁叫你不幸生在中国了? ——何祚庥(中国科学院院士) 这是一本给非计算机专业的大学生的C语言的书.“我不是学计算机的,为啥要学C语言?”这个问题每年在中华大地都会被问上几百万次.被问的对象可能是老师, ...
- [转]17个常用的JVM参数
作者:SimpleSmile_5177 来源:https://www.cnblogs.com/Simple-Object/p/10272326.html 前言 大家都知道,jvm在启动的时候,会执行默 ...
- Idea 提交配置说明
Idea 提交配置说明# Auto-update after commit :自动升级后提交 keep files locked :把文件锁上,我想这应该就只能你修改其他开发人不能修改不了的功能 在你 ...
- Cesium加载倾斜摄影数据
(1)倾斜摄影数据仅支持 smart3d 格式的 osgb 组织方式, 数据目录必须有一个 “Data” 目录的总入口, “Data” 目录同级放置一个 metadata.xml 文件用来记录模型的位 ...
- CentOS7 安装 Nexus
CentOS7 安装 Nexus 所需软件包 jdk-8u231-linux-x64.tar.gz nexus-3.24.0-02-unix.tar.gz 创建安装目录 mkdir -p /opt/n ...
- ArrayList继承关系分析
目录 继承关系 Iterable Collection List AbstractCollection AbstractList RandomAccess Serializable Cloneable ...
- Java并发--基础知识
一.为什么要用到并发 充分利用多核CPU的计算能力 方便进行业务拆分,提升应用性能 二.并发编程有哪些缺点 频繁的上下文切换 时间片是CPU分配给各个线程的时间,因为时间非常短,所以CPU不断通过切换 ...