Redis 设计与实现 4:字典
Redis 中,字典是基础结构。Redis 数据库数据、过期时间、哈希类型都是把字典作为底层结构。
字典的结构
哈希表
哈希表的实现代码在:dict.h/dictht ,Redis 的字典用哈希表的方式实现。
typedef struct dictht {
// 哈希表数组,俗称的哈希桶(bucket)
dictEntry **table;
// 哈希表的长度
unsigned long size;
// 哈希表的长度掩码,用来计算索引值,保证不越界。总是 size - 1
// h = dictHashKey(ht, he->key) & n.sizemask;
unsigned long sizemask;
// 哈希表已经使用的节点数
unsigned long used;
} dictht;
table是一个哈希表数组,每个节点的实现在dict.h/dictEntry,每个dictEntry保存一个键值对。size属性记录了向系统申请的哈希表的长度,不一定都用完,有预留空间的。sizemask属性主要是用来计算索引值 = 哈希值 & sizemask,这个索引值决定了键值对放在table的哪个位置。它的值总是size - 1,其实我有点不明白为啥计算的时候不直接用size - 1,知道的大佬请明示。used属性用来记录已经使用的节点数,size-use就是未使用的节点啦。
下图展示了一个大小为 4 的空哈希表结构,没有任何键值对
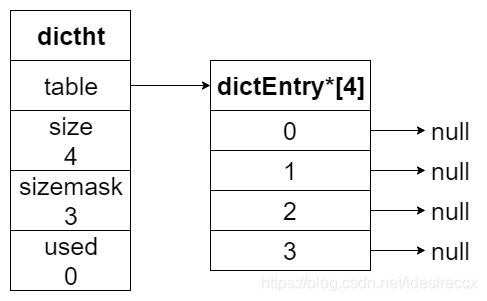
哈希节点
哈希表 dictht 的 table 的元素由哈希节点 dictEntry 组成,每一个 dictEntry 就是一个键值对
typedef struct dictEntry {
// 键
void *key;
// 值
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
// 下一个哈希节点,用于哈希冲突时拉链表用的
struct dictEntry *next;
} dictEntry;
next 指针是用于当哈希冲突的时候,可以形成链表用的。后续会将
字典
Redis 的字典实现在: dict.h/dict 。
typedef struct dict {
// 哈希算法
dictType *type;
// 私有数据,用于不同类型的哈希算法的参数
void *privdata;
// 两个哈希表,用两个的原因是 rehash 扩容缩容用的
dictht ht[2];
// rehash 进行到的索引值,当没有在 rehash 的时候,为 -1
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
// 正在跑的迭代器
unsigned long iterators; /* number of iterators currently running */
} dict;
// dictType 实际上就是哈希算法,不知道为啥名字叫 dictType
typedef struct dictType {
// hash方法,根据 key 计算哈希值
uint64_t (*hashFunction)(const void *key);
// 复制 key
void *(*keyDup)(void *privdata, const void *key);
// 复制 value
void *(*valDup)(void *privdata, const void *obj);
// key 比较
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
// 销毁 key
void (*keyDestructor)(void *privdata, void *key);
// 销毁 value
void (*valDestructor)(void *privdata, void *obj);
} dictType;
dictType 属性表示字典类型,实际上这个字典类型就是一组操作键值对算法,里面规定了很多函数。
privdata 则是为不同类型的 dictType 提供的可选参数。
如果有需要,在创建字典的时候,可以传入dictType 和 privdata。
dict.c
// 创建字典,这里有 type 和 privdata 可以传
dict *dictCreate(dictType *type, void *privDataPtr) {
dict *d = zmalloc(sizeof(*d));
_dictInit(d,type,privDataPtr);
return d;
}
// 初始化字典
int _dictInit(dict *d, dictType *type, void *privDataPtr) {
_dictReset(&d->ht[0]);
_dictReset(&d->ht[1]);
d->type = type;
d->privdata = privDataPtr;
d->rehashidx = -1;
d->iterators = 0;
return DICT_OK;
}
下图是比较完整的普通状态下的 dict 的结构(没有进行 rehash,也没有迭代器的状态):
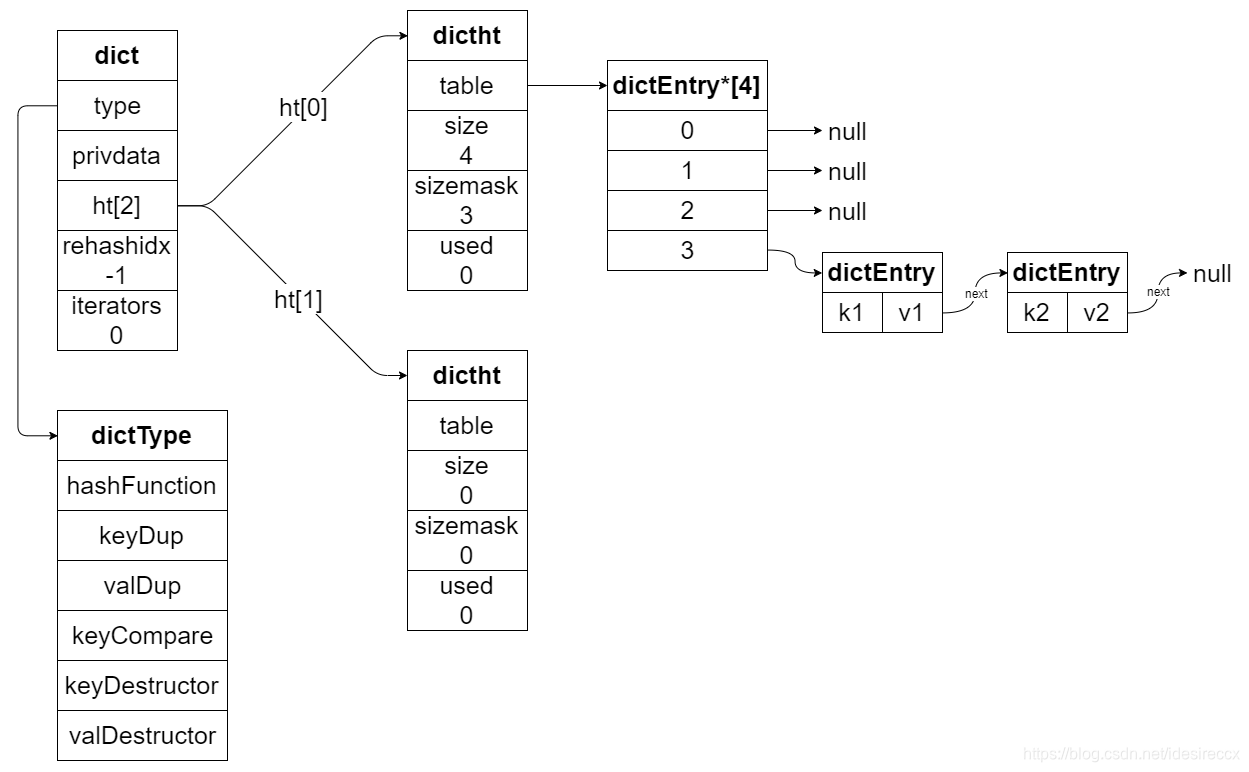 # 哈希算法
# 哈希算法
当字典中需要添加新的键值对时,需要先对键进行哈希,算出哈希值,然后在根据字典的长度,算出索引值。
// 使用哈希字典里面的哈希算法,算出哈希值
hash = dict->type->hashFunction(key)
// 使用 sizemask 和 哈希值算出索引值
idx = hash & d->ht[table].sizemask;
// 通过索引值,定位哈希节点
he = d->ht[table].table[idx];
哈希冲突
哈希冲突指的是多个不同的 key,算出的索引值一样。
Redis 解决哈希冲突的方法是:拉链法。就是每个哈希节点后面有个 next 指针,当发现计算出的索引值对应的位置有其他节点,那么直接加在前面节点后即可,这样就形成了一个链表。
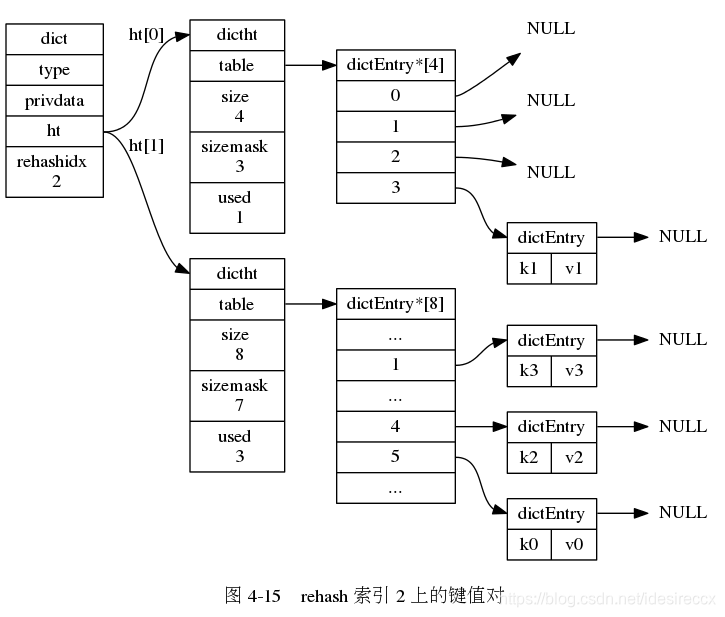
下图展示了 {k1, v1} 和 {k2, v2} 哈希冲突的结构。
假设 k1 和 k2 算出的索引值都是 3,当 k2 发现 table[3] 已经有 dictEntry{k1,v1},那就 dictEntry{k1,v1}.next = dictEntry{k2,v2}。
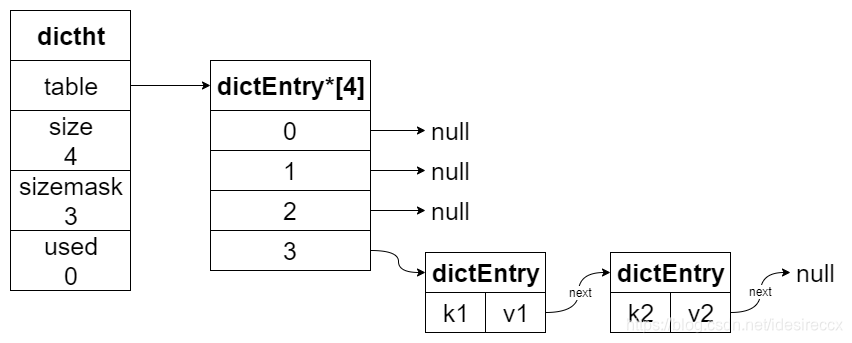
rehash
随着操作的不断进行,哈希表的长度会不断增减。哈希表的长度太长会造成空间浪费,太短哈希冲突明显导致性能下降,哈希表需要通过扩容或缩容,让哈希表的长度保持在一个合理的范围内。
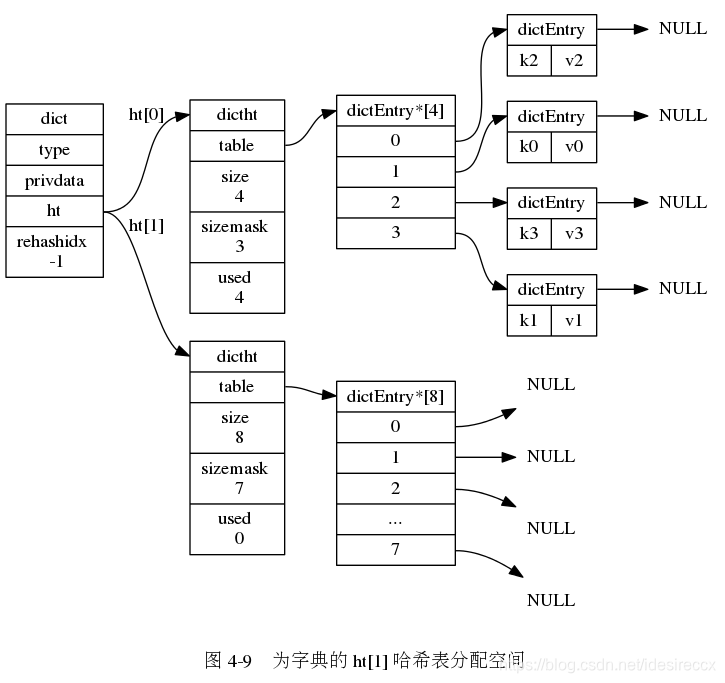
Redis 通过 ht[0] 和 ht[1] 来完成 rehash 的操作,步骤如下:
- 为 ht[1] 分配空间,分配的空间长度有两种情况:
- 扩容:第一个大于等于
ht[0].used * 2的 \(2^n\) 的数,例如 ht[0].used = 3,那么分配的是距离 6 最近的 \(2^3=8\) - 缩容:第一个大于等于
ht[0].used / 2的 \(2^n\) 的数,例如 ht[0].used = 6,那么分配的是距离 3 最近的 \(2^2=4\)
- 扩容:第一个大于等于
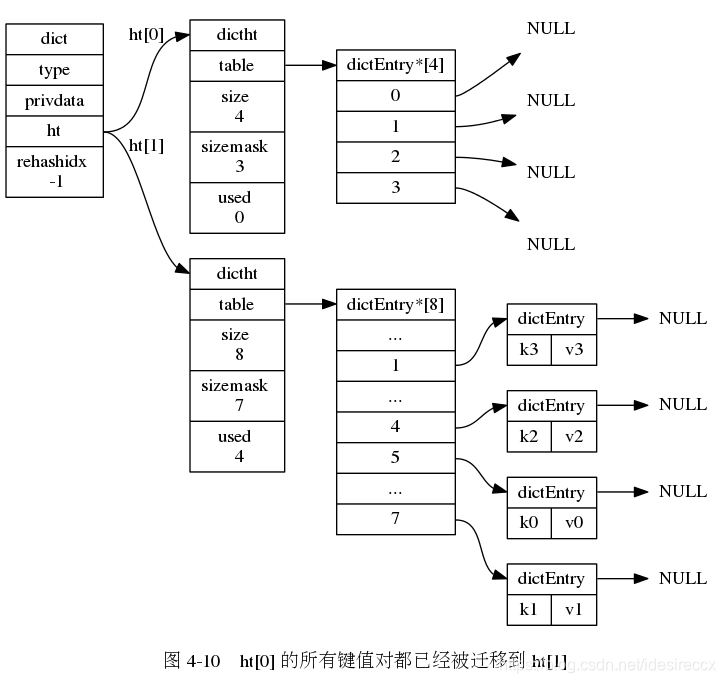
- 将 h[0] 上的键值对都迁移到 h[1],迁移的时候都是重新计算索引值的。由于 h[1] 的长度较长,之前在 h[0] 拉链的元素大概率会被分到不同的位置。
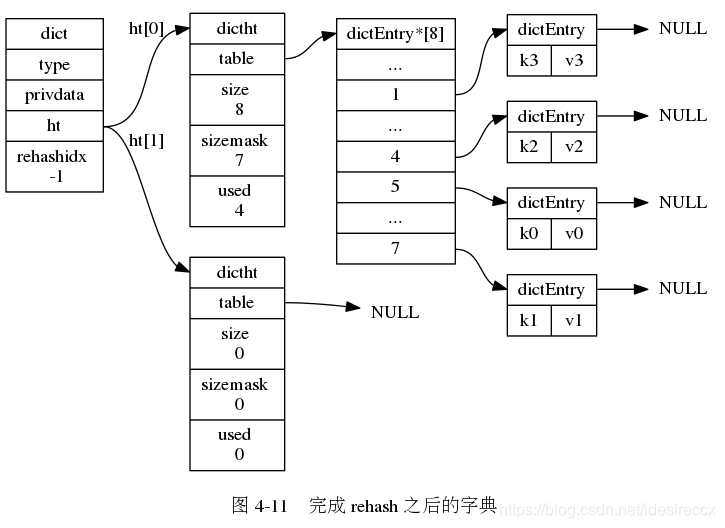
- ht[0] 所有的键值对迁移完之后,h[0] 释放,然后
h[0] = h[1],并把 h[1] 清空,为下次 rehash 准备
渐进式 rehash
上面说的 rehash 中的第二步,迁移的过程不是一次完成的。如果哈希表的长度比较小,一次完成很快。但是如果哈希表很长,例如百万千万,那这个迁移的过程就没有那么快了,会造成命令阻塞!
下面来说说,redis 是如何渐进式地将 h[0] 中的键值对迁移到 h[1] 中的:
- 为 h[1] 开辟空间,字典同时持有 h[0] 和 h[1]
- 字典中的
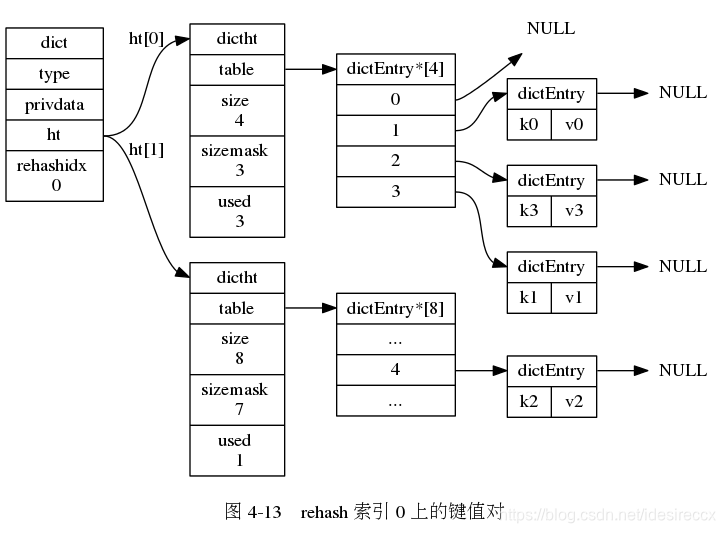
rehashidx维护了 rehash 的进度,设置为 0 的时候,开始 rehash - 字典每次增删改查的时候,除了完成指定操作之外,还会顺带把
rehashidx上的整条链表迁移到h[1]中。迁移完之后rehashidx + 1 - 随着字典的不断读取、操作,最终
h[0]上的所有键值对都会迁移到h[1]中。全部迁移完成之后rehashidx = -1
这种渐进式 rehash 的方式的好处在于,将庞大的迁移工作,分摊到每次的增删改查中,避免了一次性操作带来的性能的巨大损耗。
缺点就是迁移过程中 h[0] 和 h[1] 同时存在的时间比较长,空间利用率较低。
下面一系列的图,演示了字典是如何渐进式地 rehash ( 图片来自 《Redis 设计与实现》图片集 )





Redis 设计与实现 4:字典的更多相关文章
- Redis设计与实现 (三): 字典
哈希表 结构定义dict.h/dictht /* * 哈希表 * * 每个字典都使用两个哈希表,从而实现渐进式 rehash . */ typedef struct dictht { // 哈希表数 ...
- [Redis]Redis的设计与实现-链表/字典/跳跃表
redis的设计与实现:1.假如有一个用户关系模块,要实现一个共同关注功能,计算出两个用户关注了哪些相同的用户,本质上是计算两个用户关注集合的交集,如果使用关系数据库,需要对两个数据表执行join操作 ...
- Redis设计与实现(一~五整合版)【搬运】
Redis设计与实现(一~五整合版) by @飘过的小牛 一 前言 项目中用到了redis,但用到的都是最最基本的功能,比如简单的slave机制,数据结构只使用了字符串.但是一直听说redis是一个很 ...
- 《Redis设计与实现》读书笔记
<Redis设计与实现>读书笔记 很喜欢这本书的创作过程,以开源的方式,托管到Git上进行创作: 作者通读了Redis源码,并分享了详细的带注释的源码,让学习Redis的朋友轻松不少: 阅 ...
- 《Redis设计与实现》
<Redis设计与实现> 基本信息 作者: 黄健宏 丛书名: 数据库技术丛书 出版社:机械工业出版社 ISBN:9787111464747 上架时间:2014-6-3 出版日期:2014 ...
- 探索Redis设计与实现9:数据库redisDb与键过期删除策略
本文转自互联网 本系列文章将整理到我在GitHub上的<Java面试指南>仓库,更多精彩内容请到我的仓库里查看 https://github.com/h2pl/Java-Tutorial ...
- 探索Redis设计与实现6:Redis内部数据结构详解——skiplist
本文转自互联网 本系列文章将整理到我在GitHub上的<Java面试指南>仓库,更多精彩内容请到我的仓库里查看 https://github.com/h2pl/Java-Tutorial ...
- 探索Redis设计与实现1:Redis 的基础数据结构概览
本文转自互联网 本系列文章将整理到我在GitHub上的<Java面试指南>仓库,更多精彩内容请到我的仓库里查看 https://github.com/h2pl/Java-Tutorial ...
- Redis设计原理简介
学完MySQL InnoDB之后,又开始学习和研究Redis. 首先介绍下书:<Redis设计与实现>第二版 黄健宏著,机械工业出版社,388页,基于redis3.0版本.版本有点低,这个 ...
随机推荐
- MySQL replace into那些隐藏的风险
目录 replace into时存在主键冲突 replace into时存在唯一索引冲突 replace into时存在主键冲突&唯一索引冲突 存在问题 结论 MySQL中 replace i ...
- Python的偏函数
import functools def showag(*args,**kwargs): print(args) print(kwargs) p1 = functools.partial(showag ...
- mysql给用户赋予所有权限
mysql给用户赋予所有权限(包括远程连接) 我们给mysql新创建的用户,希望它拥有更多权限,比如远程连接,方便我们操作,可以使用如下命令: GRANT ALL PRIVILEGES ON *.* ...
- Django的下载及命令
安装 命令行 pip3 install django==1.11.11 测试是否安装成功 django-admin 创建django项目 django-admin startproject 项目名称( ...
- fist-第六天冲刺随笔
这个作业属于哪个课程 https://edu.cnblogs.com/campus/fzzcxy/2018SE1 这个作业要求在哪里 https://edu.cnblogs.com/campus/fz ...
- Python之【模块】
双层装饰器 一个函数可以被多个装饰器装饰: 多层装饰器的本质是:嵌套: 执行规则是:解释自下而上,执行自上而下 •简单的用户权限验证程序: USE_INFO = {} # 初始化一个字典,用户存放用户 ...
- C#数据结构-二叉树-顺序存储结构
什么是二叉树:每个树的节点只有两个子树的树形结构. 为什么使用顺序存储结构:使用数组存放满二叉树的各结点非常方便,可以根据一个结点的索引号很容易地推算出它的双亲.孩子.兄弟等结点的编号,从而对这些结点 ...
- 【手把手学习flutter】Flutter打Android包的基本配置和包体积优化策略
[手把手学习flutter]Flutter打Android包的基本配置和包体积优化策略 关注「松宝写代码」,回复"加群" 加入我们一起学习,天天向上 前言 因为最近参加2020FE ...
- 第15.7节 PyQt入门学习:PyQt5应用构建详细过程介绍
一. 引言 在上节<第15.6节 PyQt5安装与配置>结束了PyQt5的安装和配置过程,本节将编写一个简单的PyQt5应用,介绍基本的PyQt5应用的文件组成及相关工具的使用. 本节的应 ...
- Syclover 第十次极客大挑战web题题解
这次有空的时候报名参加了一下三叶草的招新比赛,比赛时间是一个月,题目都挺基础挺好玩的,在这里记一下自己的题解同时把自己没有做的题目也跟着writeup做一遍 第一题:cl4y:打比赛前先撸一只猫!: ...