分布式缓存 — redis
redis是一种支持Key-Value等多种数据结构的存储系统。可用于缓存,事件发布或订阅,高速队列等场景。该数据库使用ANSI C语言编写,支持网络,提供字符串,哈希,列表,队列,集合结构直接存取,基于内存,可持久化。
为什么使用redis
在项目中使用redis,主要是从两个角度去考虑:性能和并发。当然,redis还具备可以做分布式锁等其他功能,但是如果只是为了分布式锁这些其他功能,完全还有其他中间件(如zookpeer等)代替,并不是非要使用redis。
- 性能 — 如下图所示,当需要执行耗时特别久、且结果不频繁变动的SQL,特别适合将运行结果放入缓存。这样,后面的请求就去缓存中读取,使得请求能够迅速响应
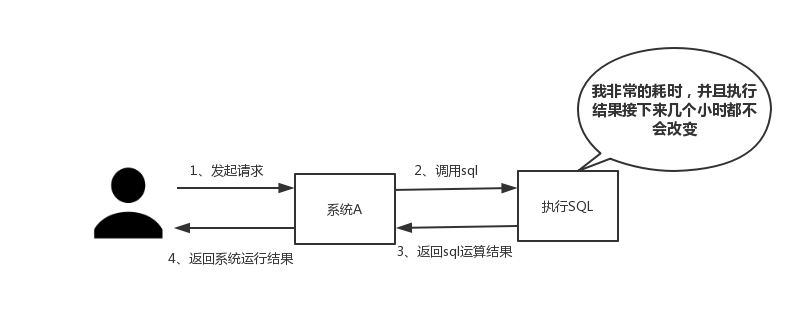
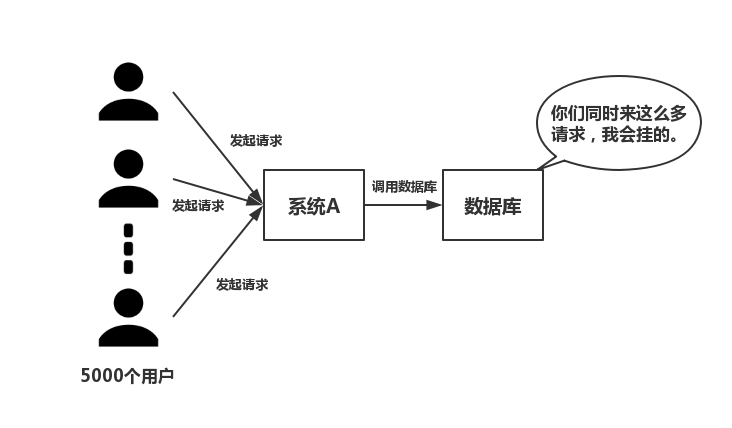
- 并发 — 如下图所示,在大并发的情况下,所有的请求直接访问数据库,数据库会出现连接异常。这个时候,就需要使用redis做一个缓冲操作,让请求先访问到redis,而不是直接访问数据库。
使用redis的缺点(常见)
- 缓存和数据库双写一致性问题
- 缓存雪崩问题
- 缓存击穿问题
- 缓存的并发竞争问题
redis的应用场景
- 会话缓存(最常用)
- 消息队列,比如支付3,活动排行榜或计数
- 发布,订阅消息(消息通知)
- 商品列表,评论列表等
单线程的redis为什么这么快
分析:这个问题其实是对redis内部机制的一个考察。其实根据博主的面试经验,很多人其实都不知道redis是单线程工作模型。
- 纯内存操作
- 单线程操作,避免了频繁的上下文切换
- 采用了非阻塞I/O多路复用机制
说一说I/O多路复用机制
举例说明:小曲在S城开了一家快递店,负责同城快送服务。小曲因为资金限制,雇佣了一批快递员,然后小曲发现资金不够了,只够买一辆车送快递。
经营方式一:客户每送来一份快递,小曲就让一个快递员盯着,然后快递员开车去送快递。慢慢的小曲就发现了这种经营方式存在下述问题
几十个快递员基本上时间都花在了抢车上了,大部分快递员都处在闲置状态,谁抢到了车,谁就能去送快递
随着快递的增多,快递员也越来越多,小曲发现快递店里越来越挤,没办法雇佣新的快递员了
快递员之间的协调很花时间
经营方式二:小曲只雇佣一个快递员。然后呢,客户送来的快递,小曲按送达地点标注好,然后依次放在一个地方。最后,那个快递员依次的去取快递,一次拿一个,然后开着车去送快递,送好了就回来拿下一个快递。
之下对比,第二种,效率更高。在上述比喻中:
每个快递员 —————> 每个线程
每个快递 —————> 每个socket(I/O流)
快递的送达地点 —————> socket的不同状态
客户送快递请求 —————> 来自客户端的请求
小曲的经营方式 —————> 服务端运行的代码
一辆车 —————> CPU的核数
有如下结论:
- 经营方式一就是传统的并发模型,每个I/O流(快递)都有一个新的线程(快递员)管理。
- 经营方式二就是I/O多路复用。只有单个线程(一个快递员),通过跟踪每个I/O流的状态(每个快递的送达地点),来管理多个I/O流。
下面类比到真实的redis线程模型,如图所示
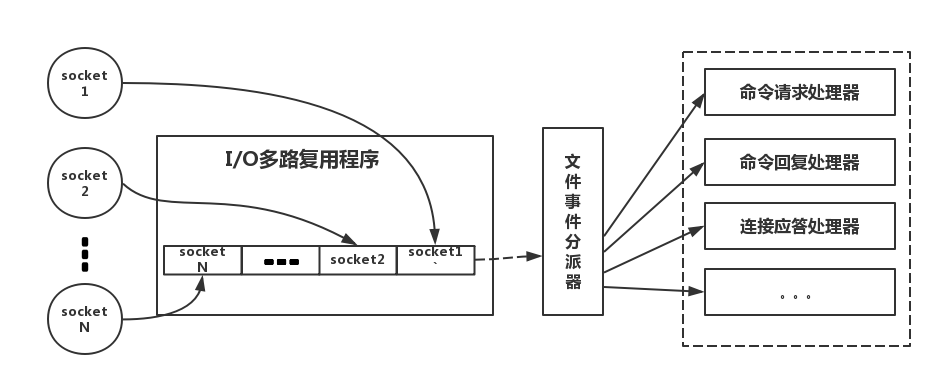
参照上图,简单来说。redis-client在操作的时候,会产生具有不同事件类型的socket。在服务端,有一段I/O多路复用程序,将其置入队列之中。然后,文件事件分派器,依次去队列中取,转发到不同的事件处理器中。
需要说明的是,除了I/O多路复用机制,redis还提供了select、epoll、evport、kqueue等多路复用函数库。
redis的数据类型,以及每种数据类型的使用场景
建议,在项目中用到后,再类比记忆,体会更深,不要硬记。基本上,一个合格的程序员,五种类型都会用到。
String
最常规的set/get操作,value可以是String也可以是数字。一般做一些复杂的计数功能的缓存。需要注意是一个键值最大存储512MB
hash
value存放的是结构化的对象,比较方便的就是操作其中的某个字段。博主在做单点登录的时候,就是用这种数据结构存储用户信息,以cookieId作为key,设置30分钟为缓存过期时间,能很好的模拟出类似session的效果。
list
使用List的数据结构,可以做简单的消息队列的功能。另外可以利用lrange命令,做基于redis的分页功能,性能佳用户体验好。还用一个场景很合适---取行情信息,也是个生产者和消费者的场景。LIST可以很好的完成排队,先进先出的原则。
set
set堆放的是一堆不重复值的集合,可以做全局去重的功能。为什么不用JVM自带的Set进行去重?因为我们的系统一般都是集群部署,使用JVM自带的Set,比较麻烦,难道为了一个做一个全局去重,再起一个公共服务,太麻烦了。
另外,就是利用交集、并集、差集等操作,可以计算共同喜好,全部的喜好,自己独有的喜好等功能。
sorted set
string类型的有序集合,也不可重复。sorted set多了一个权重参数score,集合中的元素能够按score进行排列,如果多个元素有相同的分数,则以字典序进行升序排序,因此可以做排行榜应用,取TOP N操作。可以用来做延时任务。最后一个应用就是可以做范围查找。
redis的过期策略以及内存淘汰机制
这个问题其实相当重要,到底redis有没用到家,这个问题就可以看出来。比如你redis只能存5G数据,可是你写了10G,那会删5G的数据,怎么删的?还有,你的数据已经设置了过期时间,但是时间到了,内存占用率还是比较高,什么原因?
回答:redis采用的是定期删除+惰性删除策略。
为什么不用定时删除策略?
定时删除,用一个定时器来负责监视key,过期则自动删除。虽然内存及时释放,但是十分消耗CPU资源。在大并发请求下,CPU要将时间应用在处理请求,而不是删除key,因此没有采用这一策略.
定期删除+惰性删除是如何工作的呢?
定期删除,redis默认每个100ms检查,是否有过期的key,有过期key则删除。需要说明的是,redis不是每个100ms将所有的key检查一次,而是随机抽取进行检查(如果每隔100ms,全部key进行检查,redis岂不是卡死)。因此,如果只采用定期删除策略,会导致很多key到时间没有删除。
于是,惰性删除派上用场。也就是说在你获取某个key的时候,redis会检查一下,这个key如果设置了过期时间那么是否过期了?如果过期了此时就会删除。
采用定期删除+惰性删除就没其他问题了么?
不是的,如果定期删除没删除key。然后你也没即时去请求key,也就是说惰性删除也没生效。这样,redis的内存会越来越高。那么就应该采用内存淘汰机制。
在redis.conf中有一行配置,该配置就是配内存淘汰策略的:
# maxmemory-policy volatile-lru
redis 提供 6种数据淘汰策略:
no-eviction:当内存不足以容纳新写入数据时,新写入操作会报错。禁止驱逐数据。应该没人用吧。
allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key。推荐使用,目前项目在用这种。
allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key。应该也没人用吧,你不删最少使用Key,去随机删。
volatile-lru:当内存不足以容纳新写入数据时,在已设置过期时间的键空间中,移除最近最少使用的key。这种情况一般是把redis既当缓存,又做持久化存储的时候才用。不推荐
volatile-random:当内存不足以容纳新写入数据时,在已设置过期时间的键空间中,随机移除某个key。依然不推荐
volatile-ttl:当内存不足以容纳新写入数据时,在已设置过期时间的键空间中,将要过期的key优先移除。不推荐
ps:如果没有设置 expire 的key, 不满足先决条件(prerequisites); 那么 volatile-lru, volatile-random 和 volatile-ttl 策略的行为, 和 noeviction(不删除) 基本上一致。
redis和数据库双写一致性问题
一致性问题是分布式常见问题,还可以再分为最终一致性和强一致性。数据库和缓存双写,就必然会存在不一致的问题。答这个问题,先明白一个前提。就是如果对数据有强一致性要求,不能放缓存。我们所做的一切,只能保证最终一致性。另外,我们所做的方案其实从根本上来说,只能说降低不一致发生的概率,无法完全避免。因此,有强一致性要求的数据,不能放缓存。
回答:《分布式之数据库和缓存双写一致性方案解析》给出了详细的分析,在这里简单的说一说。首先,采取正确更新策略,先更新数据库,再删缓存。其次,因为可能存在删除缓存失败的问题,提供一个补偿措施即可,例如利用消息队列。
如何应对缓存穿透和缓存雪崩问题
这两个问题,一般中小型传统软件企业,很难碰到。如果有大并发的项目,流量有几百万左右。这两个问题一定要深刻考虑。
缓存穿透,即黑客故意去请求缓存中不存在的数据,导致所有的请求都怼到数据库上,从而数据库连接异常。
解决方案:
- 利用互斥锁,缓存失效的时候,先去获得锁,得到锁了,再去请求数据库。没得到锁,则休眠一段时间重试
- 采用异步更新策略,无论key是否取到值,都直接返回。value值中维护一个缓存失效时间,缓存如果过期,异步起一个线程去读数据库,更新缓存。需要做缓存预热(项目启动前,先加载缓存)操作。
- 提供一个能迅速判断请求是否有效的拦截机制,比如,利用布隆过滤器,内部维护一系列合法有效的key。迅速判断出,请求所携带的Key是否合法有效。如果不合法,则直接返回。
缓存雪崩,即缓存同一时间大面积的失效,这个时候又来了一波请求,结果请求都怼到数据库上,从而导致数据库连接异常。
解决方案:
- 给缓存的失效时间,加上一个随机值,避免集体失效。
- 使用互斥锁,但是该方案吞吐量明显下降了。
- 双缓存。我们有两个缓存,缓存A和缓存B。缓存A的失效时间为20分钟,缓存B不设失效时间。自己做缓存预热操作。然后细分以下几个小点
- 从缓存A读数据库,有则直接返回
- A没有数据,直接从B读数据,直接返回,并且异步启动一个更新线程
- 更新线程同时更新缓存A和缓存B
如何解决redis的并发竞争key问题
这个问题大致就是,同时有多个子系统去set一个key。此时要注意什么?百度发现答案基本都是推荐用redis事务机制。博主不推荐使用redis的事务机制。因为我们的生产环境,基本都是redis集群环境,做了数据分片操作。你一个事务中有涉及到多个key操作的时候,这多个key不一定都存储在同一个redis-server上。因此,redis的事务机制,十分鸡肋。
- 如果对这个key操作,不要求顺序
这种情况下,准备一个分布式锁,大家去抢锁,抢到锁就做set操作即可,比较简单。
- 如果对这个key操作,要求顺序
假设有一个key1,系统A需要将key1设置为valueA,系统B需要将key1设置为valueB,系统C需要将key1设置为valueC.
期望按照key1的value值按照 valueA-->valueB-->valueC的顺序变化。这种时候我们在数据写入数据库的时候,需要保存一个时间戳。假设时间戳如下
系统A key 1 {valueA 3:00}
系统B key 1 {valueB 3:05}
系统C key 1 {valueC 3:10}
那么,假设这会系统B先抢到锁,将key1设置为{valueB 3:05}。接下来系统A抢到锁,发现自己的valueA的时间戳早于缓存中的时间戳,那就不做set操作了。以此类推。
其他方法,比如利用队列,将set方法变成串行访问也可以。总之,灵活变通。
redis的发布与订阅
redis的发布与订阅(发布/订阅)是它的一种消息通信模式,一方发送信息,一方接收信息。
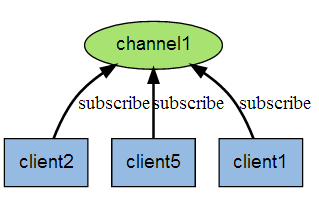
下图是三个客户端同时订阅同一个频道
下图是有新信息发送给频道1时,就会将消息发送给订阅它的三个客户端
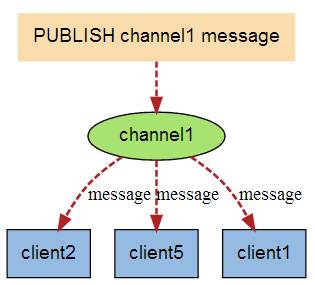
整理自:https://www.cnblogs.com/rjzheng/p/9096228.html#
分布式缓存 — redis的更多相关文章
- 一个技术汪的开源梦 —— 公共组件缓存之分布式缓存 Redis 实现篇
Redis 安装 & 配置 本测试环境将在 CentOS 7 x64 上安装最新版本的 Redis. 1. 运行以下命令安装 Redis $ wget http://download.redi ...
- 企业项目开发--分布式缓存Redis
第九章 企业项目开发--分布式缓存Redis(1) 注意:本章代码将会建立在上一章的代码基础上,上一章链接<第八章 企业项目开发--分布式缓存memcached> 1.为什么用Redis ...
- .NET分布式缓存Redis从入门到实战
一.课程介绍 今天阿笨给大家带来一堂NOSQL的课程,本期的主角是Redis.希望大家学完本次分享课程后对redis有一个基本的了解和认识,并且熟悉和掌握 Redis在.NET中的使用. 本次分享课程 ...
- 第十章 企业项目开发--分布式缓存Redis(2)
注意:本章代码是在上一章的基础上进行添加修改,上一章链接<第九章 企业项目开发--分布式缓存Redis(1)> 上一章说了ShardedJedisPool的创建过程,以及redis五种数据 ...
- 三点须知:当我们在开发过程中需要用到分布式缓存Redis的时候
当我们在开发过程中需要用到分布式缓存Redis的时候,我们首先要明白缓存在系统中用来做什么? 1. 少量数据存储,高速读写访问.通过数据全部in-momery 的方式来保证高速访问,同时提供数据落地的 ...
- 分布式缓存Redis应用场景解析
Redis的应用场景非常广泛.虽然Redis是一个key-value的内存数据库,但在实际场景中,Redis经常被作为缓存来使用,如面对数据高并发的读写.海量数据的读写等. 举个例子,A网站首页一天有 ...
- ASP.Net Core使用分布式缓存Redis从入门到实战演练
一.课程介绍 人生苦短,我用.NET Core!缓存在很多情况下需要用到,合理利用缓存可以一方面可以提高程序的响应速度,同时可以减少对特定资源访问的压力. 所以经常要用到且不会频繁改变且被用户共享的 ...
- 小D课堂 - 零基础入门SpringBoot2.X到实战_第9节 SpringBoot2.x整合Redis实战_37、分布式缓存Redis介绍
笔记 1.分布式缓存Redis介绍 简介:讲解为什么要用缓存和介绍什么是Redis,新手练习工具 1.redis官网 https://redis.io/download ...
- 【开源项目系列】如何基于 Spring Cache 实现多级缓存(同时整合本地缓存 Ehcache 和分布式缓存 Redis)
一.缓存 当系统的并发量上来了,如果我们频繁地去访问数据库,那么会使数据库的压力不断增大,在高峰时甚至可以出现数据库崩溃的现象.所以一般我们会使用缓存来解决这个数据库并发访问问题,用户访问进来,会先从 ...
- CYQ.Data V5 分布式缓存Redis应用开发及实现算法原理介绍
前言: 自从CYQ.Data框架出了数据库读写分离.分布式缓存MemCache.自动缓存等大功能之后,就进入了频繁的细节打磨优化阶段. 从以下的更新列表就可以看出来了,3个月更新了100条次功能: 3 ...
随机推荐
- Java学习日报7.12
public class HelloWorld{ public static void main(String[] args) { System.out.println("Hello Wro ...
- Android stdio使用时遇到的一些问题
(1)android stdio加载布局时 Exception raised during rendering: com/android/util/PropertiesMap ...
- sql操作数据库(3)-->外键约束、数据库表之间的关系、三大范式、多表查询、事务
外键约束 在新表中添加外键约束语法: constraint 外键约束名称 foreign key(外键的字段名称) references 主表表名(主键字段名) 在已有表中添加外键约束:alter t ...
- IDEA maven项目报错,找不到或无法找到主类
最近在写UDF,依赖复制的公司的依赖, <dependency> <groupId>org.apache.hive</groupId> <artifactId ...
- Docker-MsSqlServer和安装版本异同
创建SqlServer容器 docker run -e "ACCEPT_EULA=Y" -e "SA_PASSWORD=<YourStrong@Passw0rd&g ...
- i5 11300H和i5 10300H 的区别
i5-11300H 为 4 核 8 线程,主频 3.1GHz,睿频 4.4GHz,三级缓存 8MB 选 i5-11300H还是i5 10300h 这些点很重要!看完你就知道了https://list. ...
- WPF TreeView Indent 减少节点的缩进
www.swack.cn - 原文链接:WPF TreeView Indent 减少节点的缩进 问题 最近一个需求,需要在界面中实现Windows资源管理器TreeView的界面.但是我发现,我做出的 ...
- OOP、封装、继承、多态,真的懂了吗?
平时只要一提起来面向对象编程OOP的好处,随口就能说出来,不就是封装.继承.多态么,可他们的含义是什么呢,怎么体现,又有什么非用不可的好处啊.可能平时工作中天天在用OOP,仅仅是在用OOP语言,就是一 ...
- 新蜂商城的mybatis plus版本,添加了秒杀专区、优惠卷领取以及后台搜索功能
本项目是在newbee-mall项目的基础上改造而来,将orm层由mybatis替换为mybatis-plus,添加了秒杀功能.优惠劵功能以及后台搜索功能,喜欢的话麻烦给我个star 后台管理模块添加 ...
- LeetCode876 链表的中间结点
给定一个带有头结点 head 的非空单链表,返回链表的中间结点. 如果有两个中间结点,则返回第二个中间结点. 示例 1: 输入:[1,2,3,4,5] 输出:此列表中的结点 3 (序列化形式:[3,4 ...