Elastisearch在kibana下批量处理(mget和bulk)
一、批量查询
有点:能够大大减少网络的请求次数,减少网络开销
1、自定义设置index、type以及document id,进行查询
GET /_mget
{
"docs":[
{
"_index":"ecommerce",
"_type":"product",
"_id":1
},
{
"_index":"ecommerce",
"_type":"product",
"_id":2
}
]
}
查询结果,由于id唯一的document已经删除,所以查出id为2的文档

2、在对应的index、type下进行批量查询
注意:在ElasticSearch6.0以后一个index下只能有一个type,如果设置了多个type会报错:
GET ecommerce/product/_mget
{
"ids":[2,3]
}
或者
GET ecommerce/product/_mget
{
"docs":[
{
"_id":2
},
{
"_id":3
}
]
}
二、基于bulk的增删改
bulk语法:
- delete:删除一个文档,只要1个json串就可以了
- create:PUT /index/type/id/_create,强制创建
- index:普通的put操作,可以是创建文档,也可以是全量替换文档
- update:执行的partial update操作
注意点:
1、bulk api对json的语法有严格的要求,除了delete外,每一个操作都要两个json串,且每个json串内不能换行,非同一个json串必须换行,否则会报错
2、bulk操作中,任意一个操作失败,是不会影响其他的操作的,但是在返回结果里,会告诉你异常日志:
#index
{"index": {"metadata"}}
{"data"}
{"index": {"metadata"}}
{"data"}
#create
{"create": {"metadata"}}
{"data"}
{"create": {"metadata"}}
{"data"}
#update
{"update": {"metadata"}}
{"data"}
...
#delete
{"delete": {"metadata"}}
{"delete": {"metadata"}}
Bulk 一次请求 多次操作
1、批量创建,一个index,多个document
任意一个操作失败,是不会影响其他的操作的,但是在返回结果里,会告诉你异常日志:
POST _bulk
{ "index" : { "_index" : "test_index", "_type" : "test_type", "_id" : "1" } }
{ "uid":1,"age":21}
{ "index" : { "_index" : "test_index", "_type" : "test_type", "_id" : "2" } }
{ "uid":2,"age":22}
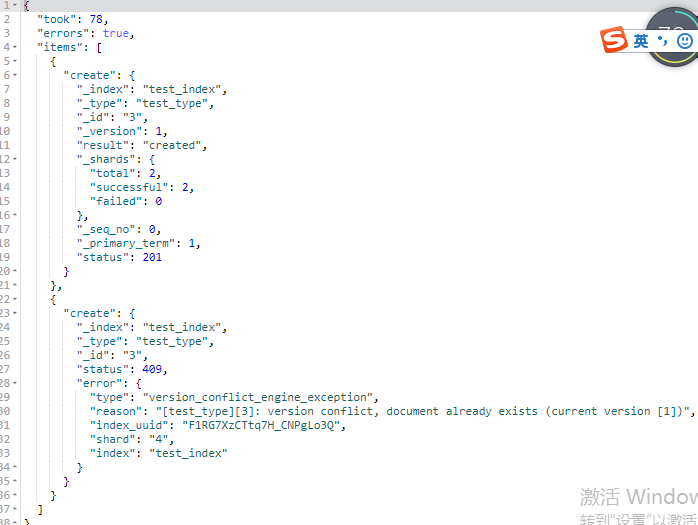
2、批量强制创建
任意一个操作失败,是不会影响其他的操作的,但是在返回结果里,会告诉你异常日志:
POST _bulk
{ "create" : { "_index" : "test_index", "_type" : "test_type", "_id" : "3" } }
{ "uid":3,"age":23}
{ "create" : { "_index" : "test_index", "_type" : "test_type", "_id" : "3" } }
{ "uid":3,"age":23}
3、修改
POST _bulk
{ "update" : {"_index" : "test_index", "_type" : "test_type", "_id" : "3"} }
{ "doc" : {"age" : 33} }
4、删除
删除一个文档,只要1个json串就可以了
POST _bulk
{ "delete" : { "_index" : "test_index", "_type" : "test_type", "_id" : "1" }}
{ "delete" : { "_index" : "test_index", "_type" : "test_type", "_id" : "5" }}
bulk api奇特的json格式
目前处理流程
直接按照换行符切割json,不用将其转换为json对象,不会出现内存中的相同数据的拷贝;
对每两个一组的json,读取meta,进行document路由;
直接将对应的json发送到node上去;
换成良好json格式的处理流程
将json数组解析为JSONArray对象,这个时候,整个数据,就会在内存中出现一份一模一样的拷贝,一份数据是json文本,一份数据是JSONArray对象;
解析json数组里的每个json,对每个请求中的document进行路由;
为路由到同一个shard上的多个请求,创建一个请求数组;
将这个请求数组序列化;
将序列化后的请求数组发送到对应的节点上去;
奇特格式的优缺点
缺点:可读性差;
优点:不需要将json数组解析为一个JSONArray对象,形成一份大数据的拷贝,浪费内存空间,能够尽可能地保证性能;
例如:
bulk size最佳大小一般建议说在几千条,大小在10MB左右。假设说现在100个bulk请求发送到了一个节点上去,然后每个请求是10MB,100个请求,就是1000MB = 1GB,然后每个请求的json都copy一份为jsonarray对象,此时内存中的占用就会翻倍,就会占用2GB的内存,甚至还不止。因为弄成jsonarray之后,还可能会多搞一些其他的数据结构,2GB+的内存占用。
占用更多的内存可能就会积压其他请求的内存使用量,比如说最重要的搜索请求,分析请求,等等,此时就可能会导致其他请求的性能急速下降。
另外的话,占用内存更多,就会导致java虚拟机的垃圾回收次数更多,跟频繁,每次要回收的垃圾对象更多,耗费的时间更多,导致es的java虚拟机停止工作线程的时间更多。
Elastisearch在kibana下批量处理(mget和bulk)的更多相关文章
- Elastisearch在kibana下常用命令总结
1.获取所有数据 GET /_search 2.创建一个Document PUT /ecommerce/product/1 { "name" : "gaolujie ya ...
- shell下批量重命名svn文件的方法
shell下批量重命名svn文件的方法 目标: 将svn目录下所有文件重命名 , 原文件前缀为 ucc_ , 批量改为 xmd_ 用tree看下当前svn目录 ucc_1.c ucc_1.h ucc_ ...
- 06_Elasticsearch 批量获取mget
06_Elasticsearch 批量获取mget 现在有: http://192.168.32.81:9200/bank/bank_account/1 http://192.168.32.81:92 ...
- Linux下批量管理工具pssh安装和使用
Linux下批量管理工具pssh安装和使用 pssh工具包 安装:yum -y install pssh pssh:在多个主机上并行地运行命令 pscp:把文件并行地复制到多个主机上 prsync:通 ...
- Elasticsearch学习笔记(十)批量查询mget、批量增删改bulk
一.批量查询 mget GET /_mget { "docs":[ { "_index":" ...
- python实现指定目录下批量文件的单词计数:并发版本
在 文章 <python实现指定目录下批量文件的单词计数:串行版本>中, 总体思路是: A. 一次性获取指定目录下的所有符合条件的文件 -> B. 一次性获取所有文件的所有文件行 - ...
- Linux 下批量创建用户(shell 命令)
第一种方法: 用shell批量创建用户,分为2中:1,批量创建的用户名无规律 :2.批量创建的用户名有规律首先,来说下批量创建的用户名无规律的shell:先把需要批量创建的用户名用一个文本文档列出来, ...
- Linux下批量修改文件及文件夹所有者及权限
Linux下批量修改文件及文件夹所有者及权限需要使用到两个命令,chmod以及chown 例:对/opt/Oracle/目录下的所有文件与子目录执行相同的权限变更: chmod -R 700 /opt ...
- Linux下批量删除空文件
Linux下批量删除空文件(大小等于0的文件)的方法 find . -name "*" -type f -size 0c | xargs -n 1 rm -f 用这个还能够删除指定 ...
随机推荐
- 小程序view的显示与隐藏
需要在全局数据块中,设定一个控制键. data: { ......//省略其他代码 showView: true }, 然后是在wxml中,view的class中设置2个class,并用三目表达式来进 ...
- webpack项目如何正确打包引入的自定义字体
webpack项目如何正确打包引入的自定义字体 一. 如何在Vue或React项目中使用自定义字体 在开发前端项目时,经常会遇到UI同事希望在项目中使用一个炫酷字体的需求.那么怎么在项目中使用自定义字 ...
- 题解-The Number of Good Intervals
题面 The Number of Good Intervals 给定 \(n\) 和 \(a_i(1\le i\le n)\),\(m\) 和 \(b_j(1\le j\le m)\),求对于每个 \ ...
- Tensorflow学习笔记No.10
多输出模型 使用函数式API构建多输出模型完成多标签分类任务. 数据集下载链接:https://pan.baidu.com/s/1JtKt7KCR2lEqAirjIXzvgg 提取码:2kbc 1.读 ...
- centos 7.5搭建oracle DG
一.背景 1.IP分配 主库:192.168.12.5 node1 备库:192.168.12.6 node2 2.环境 主库已安装数据库软件,已建库,并有业务数据 备库已安装数据库软件,未建库 二. ...
- Springboot mini - Solon详解(七)- Solon Ioc 的注解对比Spring及JSR330
Springboot min -Solon 详解系列文章: Springboot mini - Solon详解(一)- 快速入门 Springboot mini - Solon详解(二)- Solon ...
- js处理浏览器兼容
1.try catch 在try中执行我们的代码,如果在执行的过程中发生了异常信息,我们在catch中写代替的执行方案 前提:不兼容四位情况下,执行对应的代码,需要发生异常错误才可以检测到 弊端:不 ...
- 通过镜像下载最新Android源码
参考了这两篇博客: http://blog.sina.com.cn/s/blog_70b9730f01016peg.html http://www.cnblogs.com/act262/p/41790 ...
- 面试 HTTP和HTML 浏览器
HTTP和HTML 浏览器 #说一下http和https #参考回答: https的SSL加密是在传输层实现的. (1)http和https的基本概念 http: 超文本传输协议,是互联网上应用最为广 ...
- [日常摸鱼]bzoj1968 [Ahoi2005]COMMON 约数研究
题意:记$f(n)$为$n$的约数个数,求$\sum_{i=1}^n f(i)$,$n \leq 10^6$. 我也不知道为什么我要来做这个- 直接枚举每个数会是哪些数的约数-复杂度$O(n log ...