云上自动化 vs 云上编排
1 摘要
本文介绍了为什么在一个好的公有云或私有云中必须要有一个编排系统来支持云上自动化,以及实现这个编排系统的困难和各家的努力。同时提供了一套实现编排系统的原型,它包括了理论分析及主体插件框架,还给出一些细节控制的建议。希望有助于大家对“资源编排&应用编排”概念有更深的了解,也希望以开放的心态与大家一起努力,使得云真的像水电一样自然和普及。
2 为什么需要云上自动化
IT领域的自动化要求无需多言,每个程序员都知道这是必须品。自动化脚本,自动化测试,自动化部署等等,都是为了程序及围绕此程序的各类程序员跑的更加欢快。那么在云上我们是否还需要自动化?简单而言,初次使用无需考虑;深度用户需要云上自动化。具体体现在:
2.1 重复性的执行动作
在云上验证应用上线的工作中,有很多的事情是需要重复操作的。比如环境的销毁和重建;或者扩容的场景下,重复地完成多个新实例的配置动作。一旦此类操作的频率变高,比如一天一次或者一天多次的时候,你一定会觉得繁琐,并且开始尝试如何使得整个流程变的自动化,从而保证每一次执行是可重复的。也许你会写些Shell或者Python脚本,或者你主动调用云提供商的API,甚至借助某些工具如Chef,Puppet来完成这个目的。
重复是催生自动化的首要条件。
2.2 节约时间
在云上使用服务,有些操作是非常耗时的,比如创建数据库,创建VM,都需等待分钟级别的时间。一旦需要串行的创建多个耗时任务,就需要用户持续等待一段时间。而此时如果可以将整个流程自动化,则可以释放人为的等待过程,使程序员去完成其他更有价值的任务。
云上的流程自动化后,执行动作的总体耗时并不会减少,只是这段等待时间可以被转移,比如放在深夜执行。也正是这个原因(耗时没有减少,只是转移了),所以自动化后时间的节省,还是要以重复性为前途的。假如只是一次性的操作,那么“自动化节约的时间” vs “完成自动化的时间”一般都是不划算的。
2.3 基础环境的复制
这里的基础环境是指Infrastructure,是指应用跑在云上所需要的所有云服务的集合。例如一个典型Web网站的3层架构,前端+后台+数据库。在云上的某个区(例如华北区)域搭建好一套完整的系统后,遇到需要在华南区甚至另一个云提供商的云上,重新搭建一样的环境的时候,就会有系统复制的需求。是靠程序员手动一个一个组件的安装?还是自动化的一键重复部署?在有后者能力的情况下,当然后者是首选。
现在很多云厂商都推行一个叫做 Infrastructure As Code 的概念,使用机器可以理解的配置文件,来代替人工交互式的配置动作。并且这种配置文件可以通过版本管理系统像代码一样进行版本管理。这样对于企业的好处主要体现有3个:减小成本、提高效率、降低风险。
减小成本很好理解,如上提到的,自动化可以将人力转移到其他任务上,提高程序员的产出。而效率的提升主要体现在通过自动化的配置可以将环境安装的实施过程缩短,如果有多个组件或者团队交互的话,提升效率就更明显了。同时自动化可以消除人为的错误,可重复的执行特性也提升实施过程的可靠性。
2.4 自助式服务
云上服务,如果做得好,应该是自助式的,就像自来水和电一样,即开即用,按需付费。只有这样子才可以支持任意的自动化按需供给、按需扩容,也才是云本身所具备的含义。
所以这一条理由其实是对云提供商提出的要求,你的云平台要能够支持用户自助式的按需使用各种云服务,并提供相应的使用计量信息(账单)和使用报告。只有当平台的后端实现流程是全自动化的,才能做到给用户的体验是完全自助式的。这跟淘宝商家的“有货随便拍”一个道理,否则没到下单前都得跟店家沟通,无法做到按需自助式使用。
2.5 小结:自动化的成本
任何需要自动化的东西,前提就是你需要重复的执行,只有当自动化的收益大于重复的成本,才会有自动化的需求出现。假如任务只是一次性的,那就不存在自动化的需求。相反我们相信从收益方面考虑,精心人工操作一遍会比将流程自动化更为划算。
好比有时候路上遇到口渴并不会想安装一套自来水,还不如直接买一瓶矿泉水来的实在,而在家里,则需要安装一套自来水系统,因为你每天都需要使用水。
云上的自动化提供了一种可靠性,它使得云资源,云服务的每一次创建的行为都是一致的,任何用户,任何组织的执行都是可重复的;同时也消除了由于人为操作可能的失误所带来的问题,是云上深度用户的必需品。
3 云上自动化演进
3.1自动化面临的困难
(1)云服务的种类丰富多样,导致想要完成全面的自动化并非易事。一个典型的云平台会提供了ECS(虚机),EVS(硬盘),VPC(网络),RDS(数据库),ELB(负载均衡)等等一系列数都数不清的服务。有一个新的术语叫做 AWS fatigued,就是说AWS每年都会上线各种新服务&新特性,使得用户对新上线的服务&特性都感到了“AWS疲乏”,疲于使用。
(2)云服务间的创建存在复杂的依赖关系。最典型的例子就是,当创建EIP的时候,需绑定VM,而创建CM的时候,又需要先创建Subnet,建Subnet的前提就是需要先有VPC。层层的依赖,以及交叉依赖,都为开发者在企图自动化的道路设置了拦路虎,使得完成自动化的成本大大提高。根据前面提到的成本大于重复性收益的时候,自动化就会被放弃。
(3)云上资源的使用方式与传统方式不同。用户从资源的完全拥有者变成资源的使用者,后台权限的降低,导致你无法掌控一切,使得不那么方便的定位资源初始化失败原因(也许云平台本身的Bug导致)。有时候不得不联系云提供商求助了解失败原因。另外在使用流程上也会稍有改变,原来你的软件包一次拷贝就到了验证环境,而在云上,也许你需要中转跳板才能达到目的。这些都加剧了自动化的实施困难。
3.2 自动化的尝试
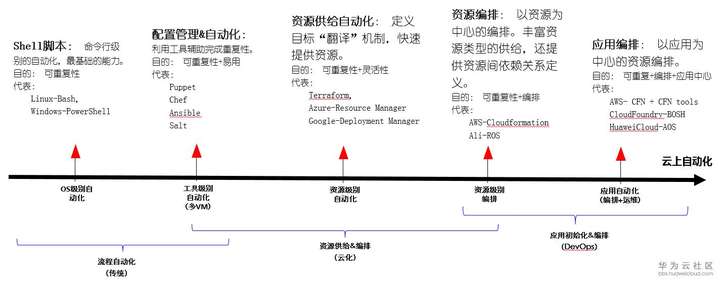
这里直接给一个图来总结了云上自动化的尝试历程,可以更加直观的了解这一领域的发展情况。不过在资源供给自动化和资源编排上其实边界也没有那么的明显,可以看到主要的差异是在灵活的语法上。在已有的自动化模板里面逐步增加一些灵活的语法,基本可以达到灵活编排的目的。
4 终极的自动化体系-编排
自动化是指一个任务流程中不需要人为的干预,而编排则是指多个任务流程可以提前规划,任务间可以互相配合,并行或者串行的执行。可以从最直接的定义上看到,只有做到任意的自动化流程控制才能称之为编排,是一个自动化的升级版。由此可见,如果某云厂商的一个编排系统,连一些基础的自动化流程都无法满足,那么它就不是一个好的编排系统。
4.1 云上的编排标杆
提到云上的编排系统,就不得不提老大哥AWS的Cloudformation了,基本上它已经是AWS云生态的一个标准,支撑应用市场以及服务目录完成任意IT软件和IT基础设施的初始化流程。
它的主要原理就是用户提供创建对象的各种属性,然后CFN协助完成对象的创建。例如初始化EC2,就是相当于创建VM虚拟机。那么用户就得提供属性:主机名,用什么镜像,硬盘多大,用什么网络,主机规格,安全组等。有了这些属性,CFN就可以确定如何调用EC2的API来创建VM了。
它之所以能力很强是因为它除了提供执行顺序的控制能力以外,在语法层面还提供了很多的内置函数,用户可以通过函数来引用变量,拼接变量值,控制执行细节。超丰富的编排对象,使得使用CFN基本可以满足任意AWS资源的自动化创建。
4.2 云上编排系统对比
这里分析三家典型的提供编排能力的云厂商能力分析表,不对之处也请联系纠正。(亚马逊CFN、阿里ROS、华为AOS)
√表示“强/做得好”,O表示“一般/待增强”,X表示“没有此特性”。
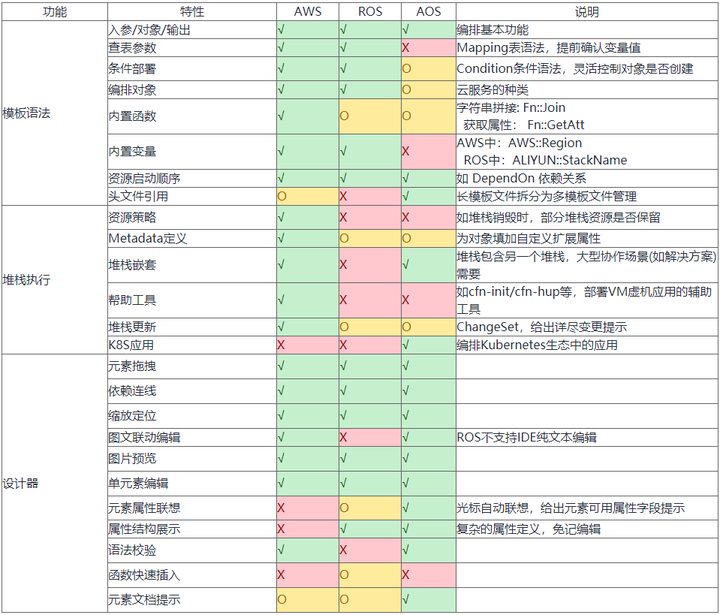
注:OpenStack的Heat编排能力类似AWS,但是无图形化设计器,这里就不列举了。
4.3 编排系统的不足
当前的编排系统都需要一个描述文件,来描述用户希望的执行流程。一般都会把这个描述文件称之为“模板”。通过模板来控制执行逻辑,这并不是一个问题,因为你能看到的业界编排系统都有自己的“模板”语法规则。问题在于,从无到有的写作一个新的模板,会比较困难,需要使用者学习一定的门槛,大家的第一感觉总是像在学习一门新的编程语言。
这个是由编排的目标对象的复杂度决定的:创建一个RDS数据库,就是会比单独创建一台VM,需要有更多的控制参数。于是一种新的模板语法,相当于一种新的编程语言。写过代码的你肯定知道,想要快速的编码,当然需要合适的IDE支撑。也正因此,一些有实力的编排系统就会推出相应的图形化设计器,其定位就是配套的模板写作IDE。
比如AWS,阿里和华为都提供了在线的模板编辑IDE。设计器好坏的评价标准就是能否支撑方便的写作模板。
5 如何实现云上编排系统
一个编排系统的核心就是一个工作流引擎,负责分析各个步骤间的依赖关系,并按照DAG(有向无环图)模型来控制这些流程的执行顺序。而云上的编排,更加的具化,就是按依赖顺序创建各个云服务。
算法层面,我们可以称每个云服务为元素。创建各种云服务的过程,就是按顺序创建各个元素的过程。
5.1有向无环图DAG
有向无环图(Directed Acyclic Graph, DAG), 是有向图的一种,字面意思的理解就是图中没有环。常常被用来表示事件之间的依赖关系,用于管理任务之间的调度。
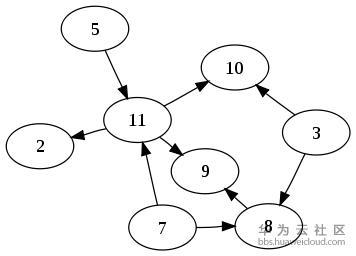
图:一个有向无环图的例子
其中所有节点的拓扑排序是有向无环图中经常需要使用到的算法,我们的系统原型也是按照此理论基础进行实现的。就是把所有元素按照DAG依赖关系确定好谁先谁后的顺序,具体算法大家可以在网上或者资料中搜索获得,这里就不细介绍了。排好序后,接下里的实现就是先完成底层的元素,再完成上层元素,直到所有元素都初始化完毕。以上就是我们的编排系统模型的理论参照。
5.2 编排系统原型
在这里我们假设有一个系统的初始化流程如下:
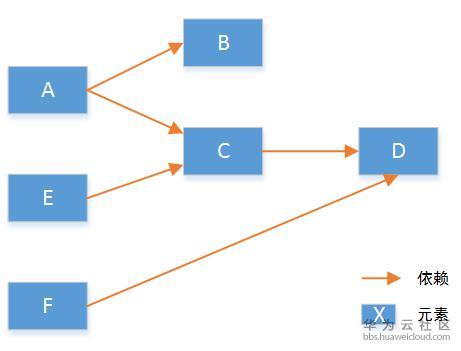
要实现所有元素按照设定好的顺序创建,我们遵从两个要点:(1)默认并行执行。(2)无依赖的先执行。具体算法实现上,我们首先将元素启动顺序分解为有向图,并遍历计算得到每个节点的依赖数。如下:
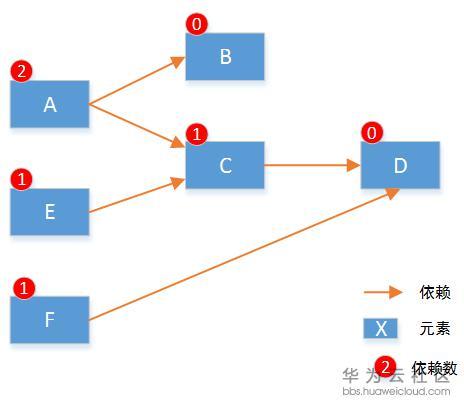
注:依赖只需要计算临近的节点就可以。
遵循之前的两个原则:那么元素B和元素D的依赖数是0,所以这两个元素可以先执行初始化。同时B和D之间无关,可以并行执行。
在任意一个元素执行完之后,所有依赖这些节点的依赖数减一,重新得到所有节点的依赖数:
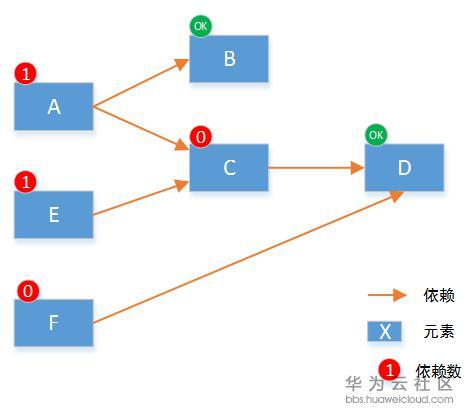
本次可以执行的元素就是C和F,因为它们的依赖数为0。在这两个元素执行完后,将依赖他们的元素的依赖数减一,重新得到所有节点依赖数:
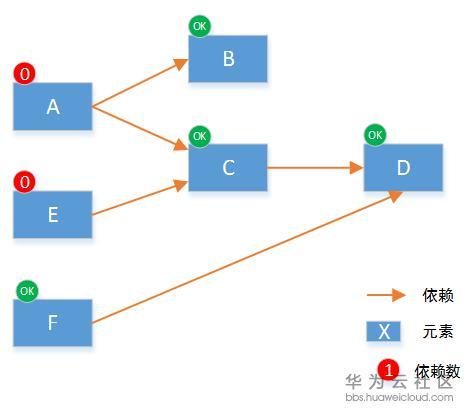
按照上述的逻辑递归执行,直到所有的元素都被执行完,整个工作流就完成了。它保证整个流程是按顺序用时最短的。从工作流实现原理可知,编排的能力强弱并不强调流程控制,而是编排元素,及编排语法的丰富程度。好的编排系统,可以快速的完成新元素的驱动开发,从而提供新服务的编排能力。
5.3 元素间信息传递
如果每个元素初始化,都得记录着其他元素的信息,这种在实现上元素间就很耦合。为了保持每个元素在执行时候的独立性(即当前元素在初始化时,不用去了解其他元素的信息)。主体框架需要保持一个全局信息,然后在初始化一个元素的时候,把这个元素需要的信息告诉它就行。它自己完全不知道还有哪些其他元素,反正它自己需要的信息都有了。
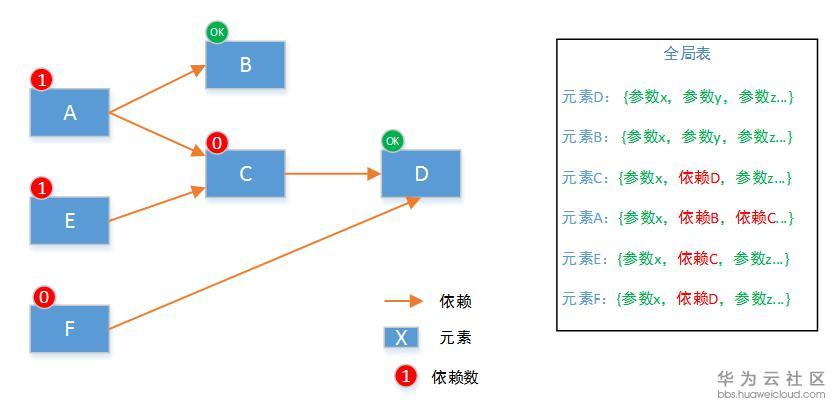
这里举例说明,调度框架维护一个全局信息,记录每个元素需要哪些参数才能初始化。上图绿色的需要用户提供,红色的则在被依赖对象创建后自动获得。比如创建VM需要VPC的ID,那么在VPC创建后,VPC的ID就知道了,这个字段不用用户提供。
所以在元素D初始化完成后,元素C就可以开始初始化了。这个时候,所有创建C的参数,都应该是确认的值。在调用C服务的初始化API的时候,不缺任何信息。这样在实现C的创建API和销毁API,就非常独立,只与C服务本身打交道。
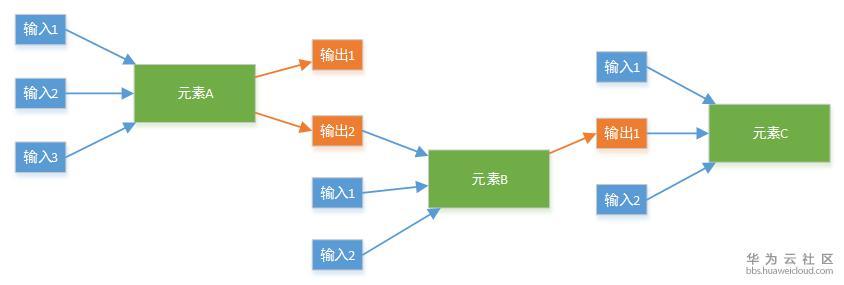
如上图,在开发新服务的时候,只需要了解新服务自身就可以了,所有想要的信息(可以直接要求用户提供,或者通过依赖获得),都会通过框架管理和传递。
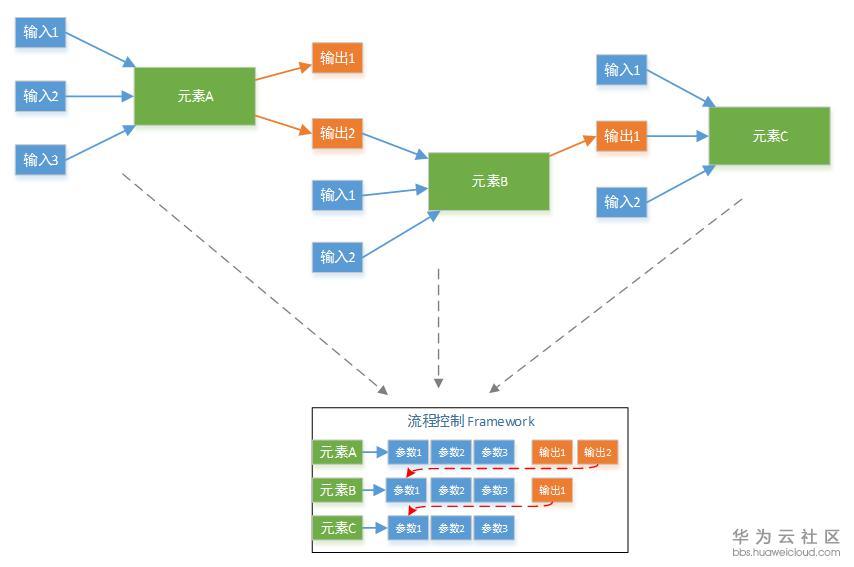
这就是我们的插件化框架,这个框架使得新增一种服务非常容易。因为服务的驱动开发是完全独立的。
5.4 插件设计
5.4.1 元素的生命周期
每一种云服务对象,在编排系统看来都是一个元素。新增一种元素的编排,就需要该元素提供增删改查等基础执行能力。编排系统的插件管理框架会根据用户执行动作,比如创建or销毁,来调用元素对应的API。
有了上一节的元素执行流程框架后,新增一个编排对象,只需要完成该元素的各种行为驱动就可以。例如:只要有创建和销毁VM的方法(API),那么就可以在编排元素里面增加一个EC2服务,就可以在模板里面增加这种元素的编排了。调度框架只是把它当做一个普通元素来对待。
5.4.2 用户自定义插件
基于插件框架每个元素驱动独立的优势,同时考虑到Kubernetes中的Resource对象也有自定义扩展特性(custom resource definition),可以设计一种元素插件支持用户定义自己的K8S编排对象的能力。即把用户提供的“信息”原封不动的传递给底层API。由底层系统去解释用户的“信息”。编排系统退化为只负责流程控制+信息传递通道。
5.4.3 操作的等待&进度
之前提过,有些云服务的操作非常耗时,如果不能提供整体进度的直观反馈,用户体验就会非常的差,以为整个执行流程挂死。所以在元素驱动的编写时,必须考虑进度和等待反馈,让编排框架能感知执行进度。使得用户可以知道当前在执行哪个元素,该元素的执行进度如何。从而确保整体的编排流程能够给用户最直接和友好的反映。
5.5 TOSCA模型
有了调度框架&插件框架,剩下的就是配置文件的语法了,目前主要的可借鉴语法就是AWS的Cloudformation和TOSCA语法。其中AWS-CFN是以资源初始化为中心的,而TOSCA的定义为TOSCA is a specification that aims to standardize how we describe software applications and everything that is required for them to run in the “cloud”,可见TOSCA是更加偏向于面向App的。鉴于容器技术的流行,越来越多的应用以独立容器出现,不再强调需要传统的VM。我们觉得模板语法使用TOSCA是个不错的选择。
实际上,在自动化的过程中,你会发现:模板的语法并不是关键点。只要能自动化,模板写出来都不会相差太大,所以关键还是看自动化能力。这个就好比编程语言的选择,Java和Go,写二叉树遍历不会在意是用for还是用while。各种编程语言的主要区别在内置函数/库上,所以在模板的语法上提供丰富的自动化便利性才是目的。这一点需要向AWS学习,它提供了很多的内置函数。
6 总结
在云上,自动化其实是刚需,只有完成了自动化这个基座,才能构建出完整的云生态。而编排作为一种高级自动化能力,需要负起推动云生态走向完整的重任。是检验一个云厂商实力的硬通货。
华为PaaS团队在云上,特别是PaaS云上的自动化&编排领域,有多年的探索和积累。在此希望能与业界一起分享并推动云上编排领域的发展,使得在云的使用过程中能带来更好的用户体验,让云上自动化能真正如云这个趋势一样无处不在。
如果有好的想法&建议,也可以跟我们交流。
本文作者:华为PaaS架构师 唐老师
云上自动化 vs 云上编排的更多相关文章
- 阿里云祝顺民(江鹤):云原生SDWAN加速企业上云 引领未来智能网络
第二届中国SD-WAN峰会于11月16日在北京盛大开幕,阿里云以黄金赞助商之名隆重参与.作为全球前三,亚太第一的云计算厂商,阿里云一直引领云网技术的演进及应用落地.过去一年,阿里云发布以云为中心的云原 ...
- 揭秘!2周实现上云上市,阿里云SaaS上云工具包如何打造新云梯?
提到“上云”,很多人会理解成上IaaS,比如买一些计算.存储和网络云产品,把自己的应用系统部署上去.这的确是通常意义的上云.但对SaaS而言,需要从产品.商业.服务,三个维度考虑SaaS伙伴和客户的痛 ...
- 在阿里云服务器(ECS)上从零开始搭建nginx服务器
本文介绍了如何在阿里云服务器上从零开始搭建nginx服务器.阿里云服务器(ECS)相信大家都不陌生,感兴趣的同学可以到http://www.aliyun.com/product/ecs去购买,或到体验 ...
- mvc上传到云虚拟机的问题解决
我用vs2015写了个小网站,.Net Framework4.5. mvc 5,发布到本机iis上正常,在美橙申请了一个云虚拟机,发布过程中遇到的一些问题记录如下: 1.服务器支持的版本比较低 上传后 ...
- 百度editor调用【图片上传阿里云】
百度editor调用简单,但是图片和文件上传阿里云就有点难度了.下面我详细说一下. 百度富文本编辑器下载地址:http://ueditor.baidu.com/website/download.htm ...
- 微信小程序基于腾讯云对象存储的图片上传
在使用腾讯云对象存储之前,公司一直使用的是传统的FTP的上传模式,而随着用户量的不断增加,FTP所暴露出来的问题也越来越多,1.传输效率低,上传速度慢.2.时常有上传其他文件来攻击服务器,安全上得不到 ...
- 阿里云MySQL远程连接不上问题
解决阿里云MySQL远程连接不上的问题:step1:1.修改user表:MySQL>update user set host = '%' where user = 'root'; 2.授权主机访 ...
- 如何在IIS上发布网站 在阿里云服务器windows server2012r iis上部署.net网站
如何在IIS上发布网站 本片博客记录一下怎么用IIS发布一个网站,以我自己电脑上一个已经开发完成的网站为例: 1.打开项目 这是我电脑上的一个项目,现在我记录一下将这个项目发布到iis上的整个过程 ...
- Fit项目图片上传和云存储的调通
项目中关于动作的说明需要相应的配图,这样可以更直观的说明动作要点.本篇主要为项目中动作的新增和编辑做准备,确定适合场景的上传操作逻辑以及图片的存储和加载的方法. 一 上传方案 a) 本来所用的模板中是 ...
随机推荐
- python 模块 来了 (调包侠 修炼手册一)
模块 什么是模块 模块:就是一系列功能的结合体 ,也可以说 一个.py文件包含了 Python 对象定义和Python语 那么 他就 可以说是 一个模块 模块的三种来源: 1.内置的(python解释 ...
- ASP.NET Core Blazor Webassembly 之 渐进式应用(PWA)
Blazor支持渐进式应用开发也就是PWA.使用PWA模式可以使得web应用有原生应用般的体验. 什么是PWA PWA应用是指那些使用指定技术和标准模式来开发的web应用,这将同时赋予它们web应用和 ...
- 使用docker创建rocketMQ容器
一.rocketMQ安装 (一)安装NameSrv 1.创建nameSrv数据挂载文件夹 mkdir -p /usr/data/rocketMQ/data/namesrv/logs mkdir -p ...
- node+ajax实战案例(6)
8.删除客户 8.1.发送id到后台 删除用户信息比较简单,只需要把对应行的id发送到后台就可以了 oTable.onclick = function (ev) { var ev = ev || ev ...
- Java使用IO流读取TXT文件
通过BufferedReader读取TXT文件window系统默认的编码是GBK,而IDE的编码多数为UTF-8,如果没有规定new InputStreamReader(new FileInputSt ...
- nginx使用热部署添加新模块
简介 当初次编译安装nginx时,http_ssl_module 模块默认是不编译进nginx的二进制文件当中,如果需要添加 ssl 证书.也就是使用 https协议.那么则需要添加 http_ssl ...
- PDF无法复制/打印/编辑怎么办?
PDF的内容不能复制/打印/编辑,主要有两种原因: 1.PDF文件设置了权限保护 2.PDF内容是图片 第一种,PDF被设置了权限保护 这种的特点是可以选中PDF里的文字,但无法复制 PDF格式标准内 ...
- 洛谷 P6082 [JSOI2015]salesman
题意 给定一棵\(n\)个点的树,有点权,你从\(1\)号点开始一次旅行,最后回到\(1\)号点.每到达一个点,你就能获得等于该点点权的收益, 但每个点都有进入该点的次数限制,且每个点的收益只能获得一 ...
- 「疫期集训day4」硝烟
那真是一阵恐怖的炮击(that boomed booms),响亮的炮音(that noise),滚滚的硝烟(that smoke),熊熊的火焰在围绕着我们前进...小心前进(go and be car ...
- centos7-解决vim无法找到问题
vim编辑器是Linux中的强大组件,是vi编辑器的加强版 在Linux命令行输入vim时提示:-bash:vim:common not found,之后按着查询到的解决办法整好了: 解决步骤如下 ...