9.python3实用编程技巧进阶(四)
4.1.如何读写csv数据
爬取豆瓣top250书籍
import requests
import json
import csv
from bs4 import BeautifulSoup books = []
def book_name(url):
res = requests.get(url)
html = res.text
soup = BeautifulSoup(html, 'html.parser')
items = soup.find(class_="grid-16-8 clearfix").find(class_="indent").find_all('table') for i in items:
book = []
title = i.find(class_="pl2").find('a')
book.append('《' + title.text.replace(' ', '').replace('\n', '') + '》') star = i.find(class_="star clearfix").find(class_="rating_nums")
book.append(star.text + '分') try:
brief = i.find(class_="quote").find(class_="inq")
except AttributeError:
book.append('”暂无简介“')
else:
book.append(brief.text) link = i.find(class_="pl2").find('a')['href']
book.append(link) global books
books.append(book) print(book) try:
next = soup.find(class_="paginator").find(class_="next").find('a')['href']
# 翻到最后一页
except TypeError:
return 0
else:
return next next = 'https://book.douban.com/top250?start=0&filter='
count = 0 while next != 0:
count += 1
next = book_name(next)
print('-----------以上是第' + str(count) + '页的内容-----------') csv_file = open('D:/top250_books.csv', 'w', newline='', encoding='utf-8')
w = csv.writer(csv_file)
w.writerow(['书名', '评分', '简介', '链接'])
for b in books:
w.writerow(b)
结果
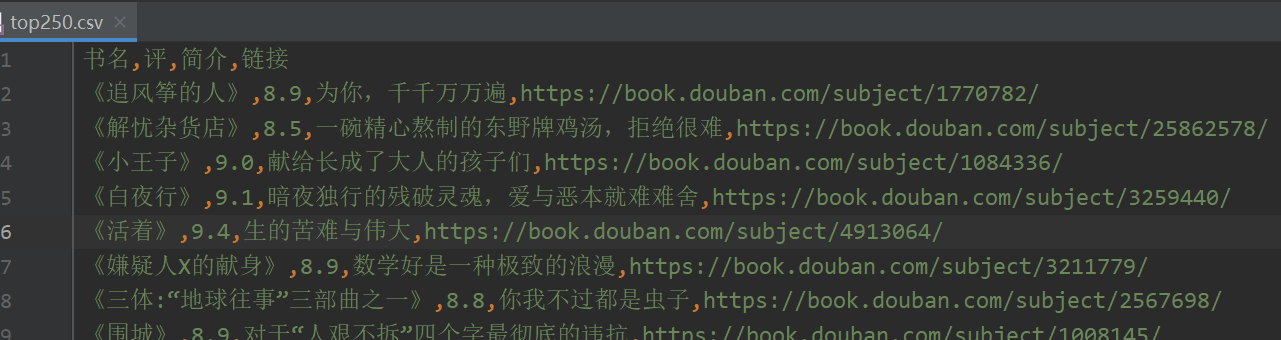
把评分为9.0的书籍保存到book_out.csv文件中
'''
1.爬取豆瓣评分排行前250本书,保存为top250.csv
2.读取top250.csv文件,把评分为9.0以上的书籍保存到另外一个csv文件中
''' import csv #打开的时候必须用encoding='utf-8',否则报错
with open('top250_books.csv', encoding='utf-8') as rf:
reader = csv.reader(rf)
#读取头部
headers = next(reader)
with open('books_out.csv', 'w', encoding='utf-8') as wf:
writer = csv.writer(wf)
#把头部信息写进去
writer.writerow(headers) for book in reader:
#获取评分
score = book[1]
#把评分大于9.0的过滤出来
if score and float(score) >= 9.0:
writer.writerow(book)
4.2.如何读写excel
安装两个库
pip install xlrd xlwt
读取excel
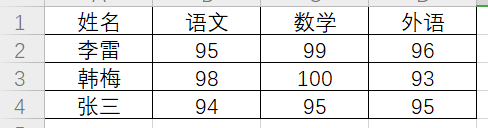
#4.2.如何读取excel
import xlrd
book = xlrd.open_workbook('demo.xlsx')
sheet = book.sheet_by_index(0)
#获取有多少行多少列
print(sheet.nrows) #
print(sheet.ncols) #
print(sheet.cell(0,0)) #text:'姓名'
print(sheet.cell_value(0,0)) #姓名
print(sheet.row_values(0)) #['姓名', '语文', '数学', '外语']
print(sheet.row_values(1,1)) #[95.0, 99.0, 96.0]
求分数的总和
#4.2.如何读写excel
import xlrd, xlwt
rbook = xlrd.open_workbook('demo.xlsx')
rsheet = rbook.sheet_by_index(0)
k = rsheet.ncols
#在最后添加一列 ‘总分’
rsheet.put_cell(0,k,xlrd.XL_CELL_TEXT, '总分', None)
for i in range(1,rsheet.nrows):
#求分数总和
t = sum(rsheet.row_values(i, 1))
rsheet.put_cell(i,k,xlrd.XL_CELL_NUMBER,t,None)
wbook = xlwt.Workbook()
wsheet = wbook.add_sheet(rsheet.name)
for i in range(rsheet.nrows):
for j in range(rsheet.ncols):
wsheet.write(i,j,rsheet.cell_value(i,j))
wbook.save('out.xlsx')
结果

9.python3实用编程技巧进阶(四)的更多相关文章
- Python3实用编程技巧进阶✍✍✍
Python3实用编程技巧进阶 整个课程都看完了,这个课程的分享可以往下看,下面有链接,之前做java开发也做了一些年头,也分享下自己看这个视频的感受,单论单个知识点课程本身没问题,大家看的时候可以 ...
- Python3实用编程技巧进阶
Python3实用编程技巧进阶 整个课程都看完了,这个课程的分享可以往下看,下面有链接,之前做java开发也做了一些年头,也分享下自己看这个视频的感受,单论单个知识点课程本身没问题,大家看的时候可以 ...
- Python3实用编程技巧进阶 ☝☝☝
Python3实用编程技巧进阶 ☝☝☝ 1.1.如何在列表中根据条件筛选数据 # 1.1.如何在列表中根据条件筛选数据 data = [-1, 2, 3, -4, 5] #筛选出data列表中大于等 ...
- 6.python3实用编程技巧进阶(一)
1.1.如何在列表中根据条件筛选数据 # 1.1.如何在列表中根据条件筛选数据 data = [-1, 2, 3, -4, 5] #筛选出data列表中大于等于零的数据 #第一种方法,不推荐 res1 ...
- 7.python3实用编程技巧进阶(二)
2.1.如何拆分含有多种分隔符的字符串 #2.1.如何拆分含有多种分隔符的字符串 s = 'ab;cd|efg|hi,jkl|mn\topq;rst,uvw\txyz' #第一种方法 def my__ ...
- 8.python3实用编程技巧进阶(三)
3.1.如何实现可迭代对象和迭代器对象 #3.1 如何实现可迭代对象和迭代器对象 import requests from collections.abc import Iterable,Iterat ...
- 10.python3实用编程技巧进阶(五)
5.1.如何派生内置不可变类型并修其改实例化行为 修改实例化行为 # 5.1.如何派生内置不可变类型并修其改实例化行为 #继承内置tuple, 并实现__new__,在其中修改实例化行为 class ...
- EF – 2.EF数据查询基础(上)查询数据的实用编程技巧
目录 5.4.1 查询符合条件的单条记录 EF使用SingleOrDefault()和Find()两个方法查询符合条件的单条记录. 5.4.2 Entity Framework中的内部数据缓存 DbS ...
- EF – 2.EF数据查询基础(上)查询数据的实用编程技巧
目录 5.4.1 查询符合条件的单条记录 EF使用SingleOrDefault()和Find()两个方法查询符合条件的单条记录. 5.4.2 Entity Framework中的内部数据缓存 DbS ...
随机推荐
- ThinkPHP5.x.x各版本实战环境getshell
#这个文章我之前在t00ls已经分享过了 #内容只是对tp5的实战环境下getshell做的记录,中间遇到的一些小问题的突破,没啥技术含量 -5.1.18 http://www.xxxxx.com/? ...
- Cesium专栏-裁剪效果(基于3dtiles模型,附源码下载)
Cesium Cesium 是一款面向三维地球和地图的,世界级的JavaScript开源产品.它提供了基于JavaScript语言的开发包,方便用户快速搭建一款零插件的虚拟地球Web应用,并在性能,精 ...
- sqlserver刷新视图
sqlserver 用于刷新当前数据库所有视图的存储过程 create procedure dbo.proc_refreshview as begin ) declare cur_view curso ...
- Scrapy对接Selenium
首先pip安装selenium,然后下载浏览器驱动 WebDrive下载地址 chrome的webdriver:http://chromedriver.storage.googleapis.com/i ...
- java8-08-创建stream流
为什么用stream 应用函数式编程 配合Lamdba表达式 更快操作集合类 数组 什么是 stream ...
- 01-Node.js学习笔记-模块成员的导出导入
什么是Node.js Node.js是一个让javascript运行在服务端的开发平台: Node.js能做什么? 1.基于社交网络的大规模web应用: 2.命令行工具 3.交互式终端程序 4.带有图 ...
- acwing 835. Trie字符串统计
地址 https://www.acwing.com/problem/content/description/837/ 维护一个字符串集合,支持两种操作: “I x”向集合中插入一个字符串x: “Q ...
- HTML连载42-清空默认边距、文字行高
一. webstorm取色技巧:webstorm内置了颜色取色器,我们对某种颜色未知的时候,可以利用下图中的取色器,进行颜色识别. 二.系统会默认给body添加外边距,因此我们对 ...
- spring cloud 2.x版本 Config配置中心教程
前言 本文采用Spring cloud本文为2.1.8RELEASE,version=Greenwich.SR3 本文基于前面的文章eureka-server的实现. 参考 eureka-server ...
- 【shell脚本】点名器===randomName.sh
随机点名,从name.txt文件中读取名字 [root@VM_0_10_centos shellScript]# cat randowName.sh #!/bin/bash # 随机点名器 # 需提前 ...