Hadoop 学习之路(五)—— Hadoop集群环境搭建
一、集群规划
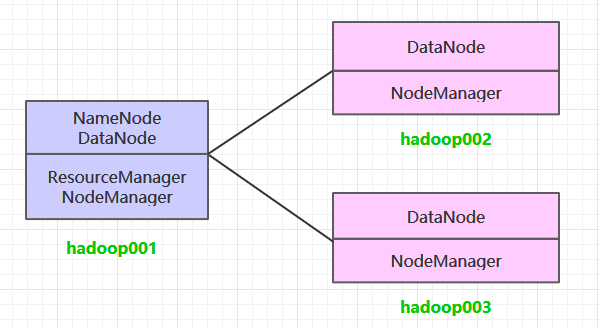
这里搭建一个3节点的Hadoop集群,其中三台主机均部署DataNode和NodeManager服务,但只有hadoop001上部署NameNode和ResourceManager服务。
二、前置条件
Hadoop的运行依赖JDK,需要预先安装。其安装步骤单独整理至:
三、配置免密登录
3.1 生成密匙
在每台主机上使用ssh-keygen命令生成公钥私钥对:
ssh-keygen
3.2 免密登录
将hadoop001的公钥写到本机和远程机器的~/ .ssh/authorized_key文件中:
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop001
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop002
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop003
3.3 验证免密登录
ssh hadoop002
ssh hadoop003
四、集群搭建
3.1 下载并解压
下载Hadoop。这里我下载的是CDH版本Hadoop,下载地址为:http://archive.cloudera.com/cdh5/cdh/5/
# tar -zvxf hadoop-2.6.0-cdh5.15.2.tar.gz
3.2 配置环境变量
编辑profile文件:
# vim /etc/profile
增加如下配置:
export HADOOP_HOME=/usr/app/hadoop-2.6.0-cdh5.15.2
export PATH=${HADOOP_HOME}/bin:$PATH
执行source命令,使得配置立即生效:
# source /etc/profile
3.3 修改配置
进入${HADOOP_HOME}/etc/hadoop目录下,修改配置文件。各个配置文件内容如下:
1. hadoop-env.sh
# 指定JDK的安装位置
export JAVA_HOME=/usr/java/jdk1.8.0_201/
2. core-site.xml
<configuration>
<property>
<!--指定namenode的hdfs协议文件系统的通信地址-->
<name>fs.defaultFS</name>
<value>hdfs://hadoop001:8020</value>
</property>
<property>
<!--指定hadoop集群存储临时文件的目录-->
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
</configuration>
3. hdfs-site.xml
<property>
<!--namenode节点数据(即元数据)的存放位置,可以指定多个目录实现容错,多个目录用逗号分隔-->
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/namenode/data</value>
</property>
<property>
<!--datanode节点数据(即数据块)的存放位置-->
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/datanode/data</value>
</property>
4. yarn-site.xml
<property>
<!--配置NodeManager上运行的附属服务。需要配置成mapreduce_shuffle后才可以在Yarn上运行MapReduce程序。-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<!--resourcemanager的主机名-->
<name>yarn.resourcemanager.hostname</name>
<value>hadoop001</value>
</property>
</configuration>
5. mapred-site.xml
<configuration>
<property>
<!--指定mapreduce作业运行在yarn上-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5. slaves
配置所有从属节点的主机名或IP地址,每行一个。所有从属节点上的DataNode服务和NodeManager服务都会被启动。
hadoop001
hadoop002
hadoop003
3.4 分发程序
将Hadoop安装包分发到其他两台服务器,分发后建议在这两台服务器上也配置一下Hadoop的环境变量。
# 将安装包分发到hadoop002
scp -r /usr/app/hadoop-2.6.0-cdh5.15.2/ hadoop002:/usr/app/
# 将安装包分发到hadoop003
scp -r /usr/app/hadoop-2.6.0-cdh5.15.2/ hadoop003:/usr/app/
3.5 初始化
在Hadoop001上执行namenode初始化命令:
hdfs namenode -format
3.6 启动集群
进入到Hadoop001的${HADOOP_HOME}/sbin目录下,启动Hadoop。此时hadoop002和hadoop003上的相关服务也会被启动:
# 启动dfs服务
start-dfs.sh
# 启动yarn服务
start-yarn.sh
3.7 查看集群
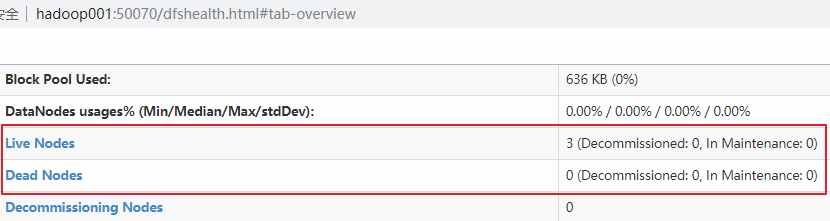
在每台服务器上使用jps命令查看服务进程,或直接进入Web-UI界面进行查看,端口为50070。可以看到此时有三个可用的Datanode:
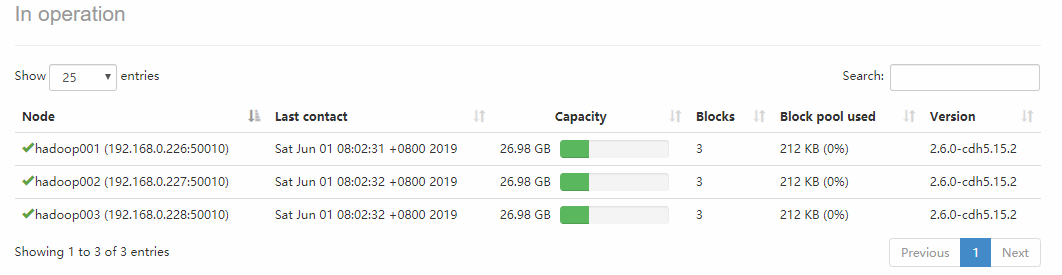
点击Live Nodes进入,可以看到每个DataNode的详细情况:
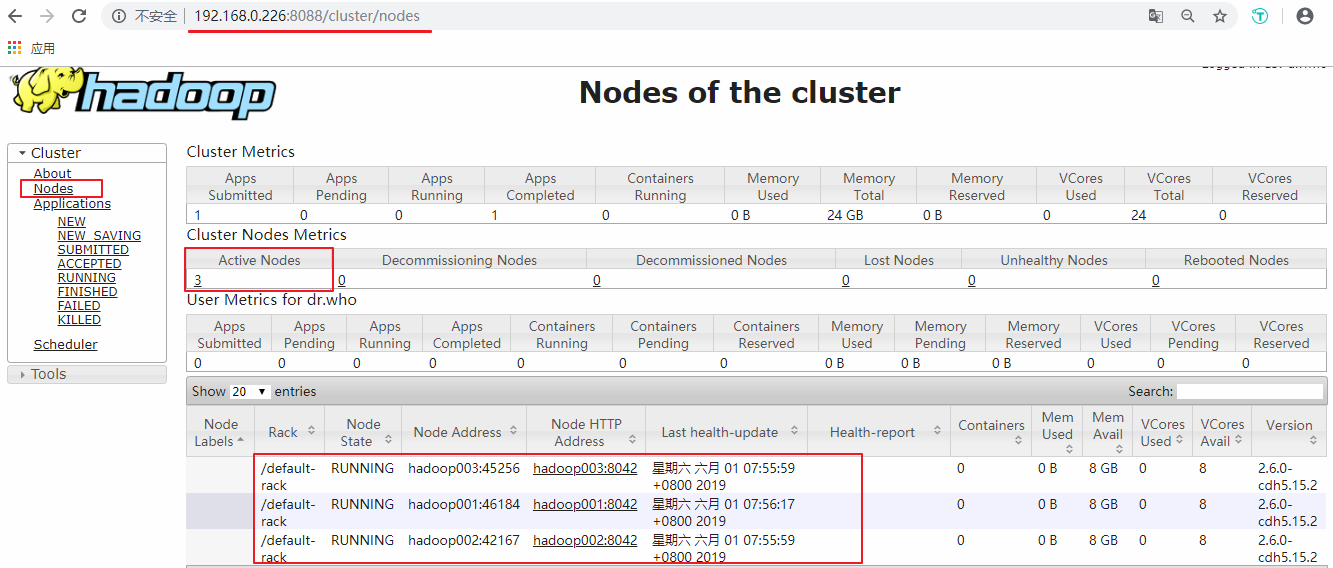
接着可以查看Yarn的情况,端口号为8088 :
五、提交服务到集群
提交作业到集群的方式和单机环境完全一致,这里以提交Hadoop内置的计算Pi的示例程序为例,在任何一个节点上执行都可以,命令如下:
hadoop jar /usr/app/hadoop-2.6.0-cdh5.15.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.15.2.jar pi 3 3
更多大数据系列文章可以参见个人 GitHub 开源项目: 程序员大数据入门指南
Hadoop 学习之路(五)—— Hadoop集群环境搭建的更多相关文章
- Hadoop 2.6.0-cdh5.4.0集群环境搭建和Apache-Hive、Sqoop的安装
搭建此环境主要用来hadoop的学习,因此我们的操作直接在root用户下,不涉及HA. Software: Hadoop 2.6.0-cdh5.4.0 Apache-hive-2.1.0-bin Sq ...
- Hadoop 学习之路(八)—— 基于ZooKeeper搭建Hadoop高可用集群
一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS 高可用和 YARN 高可用,两者的实现基本类似,但 HDFS NameNode 对数据存储及其一致性的要求 ...
- Hadoop集群环境搭建步骤说明
Hadoop集群环境搭建是很多学习hadoop学习者或者是使用者都必然要面对的一个问题,网上关于hadoop集群环境搭建的博文教程也蛮多的.对于玩hadoop的高手来说肯定没有什么问题,甚至可以说事“ ...
- 大数据 -- Hadoop集群环境搭建
首先我们来认识一下HDFS, HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.它其实是将一个大文件分成若干块保存在不同服务器的多个节点中.通过联网 ...
- Spark集群环境搭建——Hadoop集群环境搭建
Spark其实是Hadoop生态圈的一部分,需要用到Hadoop的HDFS.YARN等组件. 为了方便我们的使用,Spark官方已经为我们将Hadoop与scala组件集成到spark里的安装包,解压 ...
- Hadoop+Spark:集群环境搭建
环境准备: 在虚拟机下,大家三台Linux ubuntu 14.04 server x64 系统(下载地址:http://releases.ubuntu.com/14.04.2/ubuntu-14.0 ...
- hadoop集群环境搭建之zookeeper集群的安装部署
关于hadoop集群搭建有一些准备工作要做,具体请参照hadoop集群环境搭建准备工作 (我成功的按照这个步骤部署成功了,经实际验证,该方法可行) 一.安装zookeeper 1 将zookeeper ...
- hadoop集群环境搭建之安装配置hadoop集群
在安装hadoop集群之前,需要先进行zookeeper的安装,请参照hadoop集群环境搭建之zookeeper集群的安装部署 1 将hadoop安装包解压到 /itcast/ (如果没有这个目录 ...
- hadoop集群环境搭建准备工作
一定要注意hadoop和linux系统的位数一定要相同,就是说如果hadoop是32位的,linux系统也一定要安装32位的. 准备工作: 1 首先在VMware中建立6台虚拟机(配置默认即可).这是 ...
- Hadoop完全分布式集群环境搭建
1. 在Apache官网下载Hadoop 下载地址:http://hadoop.apache.org/releases.html 选择对应版本的二进制文件进行下载 2.解压配置 以hadoop-2.6 ...
随机推荐
- 斯托克斯定理(Stokes' theorem)
1. 几种形式 ∮∂SPdx+Qdy+Rdz=∬S∣∣∣∣∣∣cosα∂∂xPcosβ∂∂yQcosγ∂∂zR∣∣∣∣∣∣dS ∮∂Ωw=∬Ωdw 左边是内积: 右边是外积: 物理上的应用: ∮∂SE ...
- Android实现图片滚动控件,含页签功能,让你的应用像淘宝一样炫起来
首先题外话,今天早上起床的时候,手滑一下把我的手机甩了出去,结果陪伴我两年半的摩托罗拉里程碑一代就这么安息了,于是我今天决定怒更一记,纪念我死去的爱机. 如果你是网购达人,你的手机上一定少不了淘宝客户 ...
- 自定义WPF 窗口样式
原文:自定义WPF 窗口样式 Normal 0 false 7.8 pt 0 2 false false false EN-US ZH-CN X-NONE 自定义 Window 在客户端程序中,经常需 ...
- 1 WCF 一个基础理论 以及如何实现一个简单wcf服务
1 SOA : service oriented architecture 面向服务的架构 2 web service标准 3 概念理解图 4 WCF类库 项目的 wcf简单实现 首先创建一个简单的w ...
- 整了一天,明白一个道理:线程里post数据,即loop.exec+quit,然而这个quit之后,导致无法在线程里建立新的loop.exec,直接就退出了
跟踪到exec的代码里,发现: 无奈,把第二个post移到主线程里去执行了. 如果大家发现有好办法,请告知我.
- WPF的消息机制(一)- 让应用程序动起来
原文:WPF的消息机制(一)- 让应用程序动起来 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/powertoolsteam/article/det ...
- ASP.NET Core Identity 迁移数据 - ASP.NET Core 基础教程 - 简单教程,简单编程
原文:ASP.NET Core Identity 迁移数据 - ASP.NET Core 基础教程 - 简单教程,简单编程 ASP.NET Core Identity 迁移数据 上一章节中我们配置了 ...
- 微信小程序之商品属性分类
所提及的购物数量的加减,现在说说商品属性值联动选择. 为了让同学们有个直观的了解,到电商网截了一个图片,就是红圈所示的部分 现在就为大家介绍这个小组件,在小程序中,该如何去写 下图为本项目的图: wx ...
- UVA10940 - Throwing cards away II(找到规律)
UVA10940 - Throwing cards away II(找规律) 题目链接 题目大意:桌上有n张牌,依照1-n的顺序从上到下,每次进行将第一张牌丢掉,然后把第二张放到这叠牌的最后.重复进行 ...
- C/S和B/S两种架构区别与优缺点分析
C/S和B/S,是再普通不过的两种软件架构方式,都可以进行同样的业务处理,甚至也可以用相同的方式实现共同的逻辑.既然如此,为何还要区分彼此呢?那我们就来看看二者的区别和联系. 一.C/S 架构 1. ...