初识云计算 -《AWS云端企业实战圣经》读书笔记
原书中涉及实操的地方,在本文中被省略。一是篇幅太长,放入文中太过累赘,二是原书成书过早,现在 AWS 的界面早已变化很大,不具备参考性。
第一章 谁在使用云计算
1、什么是云计算
云计算(cloud computing) 是一种基于互联网的计算方式,通过这种方式,共享的软硬件资源和信息可以按需求提供给计算机各种终端和其他设备。
云计算的“
云”,指的就是因特网。
2、历史
(1)云计算元年是何年?
一般认为,亚马逊 AWS 在 2006 年公开发布 S3 存储服务、SQS 消息队列及 EC2 虚拟机服务,正式宣告了现代云计算的到来。
在 2007 年底,AWS 使用的网络带宽就超过 Amazon 网站本身(Amazon 的网络流量位居世界前 15),AWS 也是 Amazon 的营业额成长最快的项目。
而如果从行业视角来看,我们也不妨视 2008 年为另一个意义上的云计算元年。原因是:
微软在 PDC2008 上宣布 Windows Azure 的技术社区预览版,正式开始微软众多技术与服务托管化和线上化的尝试;
Google 恰好也在 2008 年推出了 Google App Engine 预览版本,通过专有 Web 框架允许开发者开发 Web 应用并部署在 Google 的基础设施之上,这是一种更偏向 PaaS 层面的云计算进入方式;
国内的云计算标杆阿里云也是从 2008 年开始筹办和起步。
Amazon AWS、Microsoft Azure、Google Cloud 和国内的阿里云,乃是几个大厂推出的著名云计算平台。
(2)为什么 AWS 云计算服务是亚马逊先做出来,而不是 Google ?
1、亚马逊的业务天然对 IaaS 的需求很强烈
亚马逊的核心业务电子商务有太强的季节性,这在 2002-2003 年已经成为公司越滚越大的年度噩梦。如何有效地配置具备足够扩展性而且可以持续上线的基础系统的确是一个迫在眉睫的瓶颈。
2、Google 更倾向于 PaaS
Google 在 docker 流行起来之前十年就开始使用 container 技术了。这也就能够解释为什么 Google 在云计算领域推出的第一个服务就是 AppEngine。
2、IaaS、PaaS、SaaS
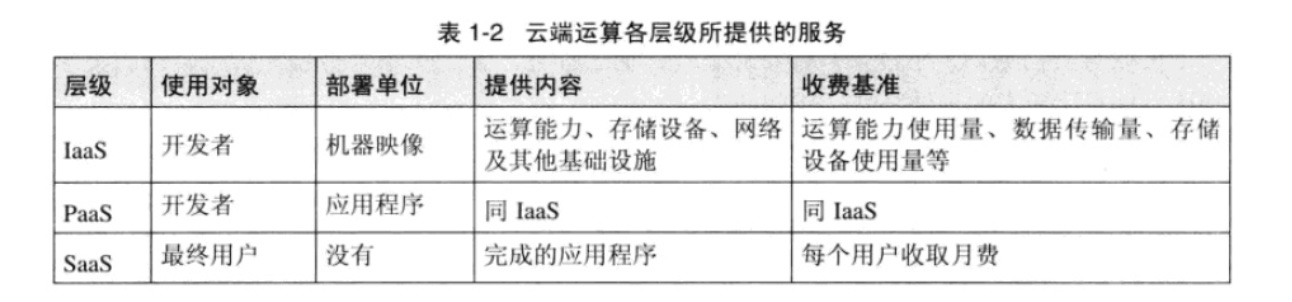
云计算一般分为三个层级,从最底层到最高层依次是 IaaS(Infrastructure as a Service 基础设施服务)、PaaS(Platform as a Service 平台服务)、SaaS(Software as a Service 软件服务)。如图:

IaaS
IaaS(基础设施服务)是通过因特网,以服务的形式提供运算能力、存储设备、网络及其他基础设施(如防火墙、DNS、Load balancers 等),以前也叫作 HaaS (Hardware as a Service,硬件服务)。
PaaS
与 IaaS 类似,PaaS(平台服务)也是通过因特网以服务的形式提供运算能力、存储设备、网络等。但是 PaaS 需要特定的执行环境(runtime environment),也就是说用户要按照 PaaS 服务提供者的规格来开发、部署,オ能在 PaaS 上面执行。
由于 PaaS 的抽象化程度比较高,所以 PaaS 的部署单位就是一个应用程序而已,而不像 IaaS 是整个机器的映像。
通常 PaaS 服务提供者都会提供开发套件(SDK)、集成开发工具(IDE)来帮助开发应用。
早期的 PaaS 不温不火(如 Google App Engine),但在后来大发展时代也找到了崛起之道,即不再寻求大一统的应用程序框架,而是更多提供标准的可复用中间件,并与其他 IaaS/PaaS 设施进行组合与联动。典型的例子包括 API 网关、负载均衡器、消息队列、泛数据库类服务等。
SaaS
SaaS(软件服务)则是完成的应用程序,通过因特网以服务的形式提供给用户。所以 SaaS 的用户就是最终用户(end user)。
web 应用和安装好的软件不一样,用户只需要 browser 就可以使用 SaaS 的应用(软件)。
区别:
3、云计算优点
弹性、可伸缩性
节省时间成本
节省人力成本
没有折旧
一定的安全性
现在 AWS 希望所有服务都使用新的
访问策略语言(Access Policy Language, APL),用同一套语法就可以设置所有 AWS 服务的访问权限。访问策略语言是一份 JSON 文件,可以很详细地设置访问的权限范围,例如:客户端的 P 地址、访问的时间、访问的资源的名称(可以用通用字符)。(缺点就是不太好写。)
4、未来趋势
(1)混合云
下面会详细谈到。
(2)垂直云
典型的垂直云代表有视频云、金融云、游戏云、政务云、工业云等。
5、使用云计算的著名公司
Twitter 用 AWS 管理存储空间,例如使用 S3 来存储用户的头像,以及备份数据。
Netflix 百分之百的运营都在 AWS 上。AWS 能有今天的成就,跟他们 Netflix 尽情折腾是有关系的。说到这个公司的折腾,他们专门编写了一个内部软件,叫 Chaos Monkey,这个疯猴应用会在不定的时间,不定的环节,有意的破坏云计算系统,好做备灾测试。
第二章 云计算领导者 AWS
1、什么是 AWS
AWS (Amazon Web Services),即亚马逊云计算服务,由亚马逊公司所创建的云计算平台,提供许多远程Web服务。
AWS 通过 ISO27001 认证,在系统安全和管理上面有一定的水平。
2、AWS 主要业务
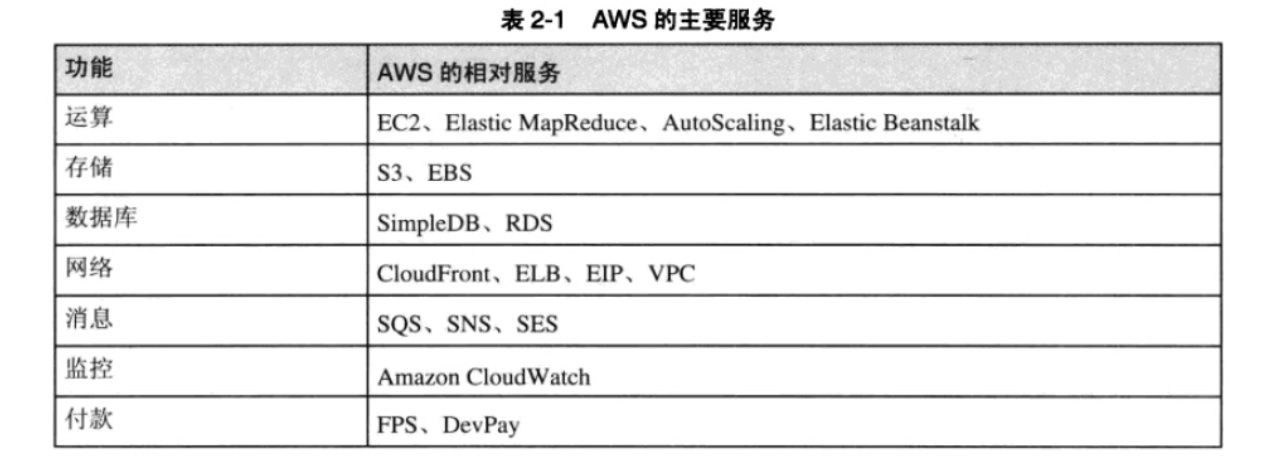
你可以选用你需要的 AWS 服务,去组合出适合你的软件架构。
以我的经验来说,开发一个完整的网络应用大约需要 3、4 种服务,如果架构复杂一点的话,7、8 种也足够了,所以 AWS 确实能够满足开发的需求。
3、如何开始使用 AWS
(1)为什么要有 地区 和 所在地
地区(Region)是地理上分离的大区域,例如美国东部(us-east-1) 或欧洲西部(eu-west-1)。
所在地(Availability Zone - AZ)则是在地区里面的数据中心所在的代号,例如“美国东部-1a”(us-east-1a)、“欧洲西部-1a”(eu-west-1a)。
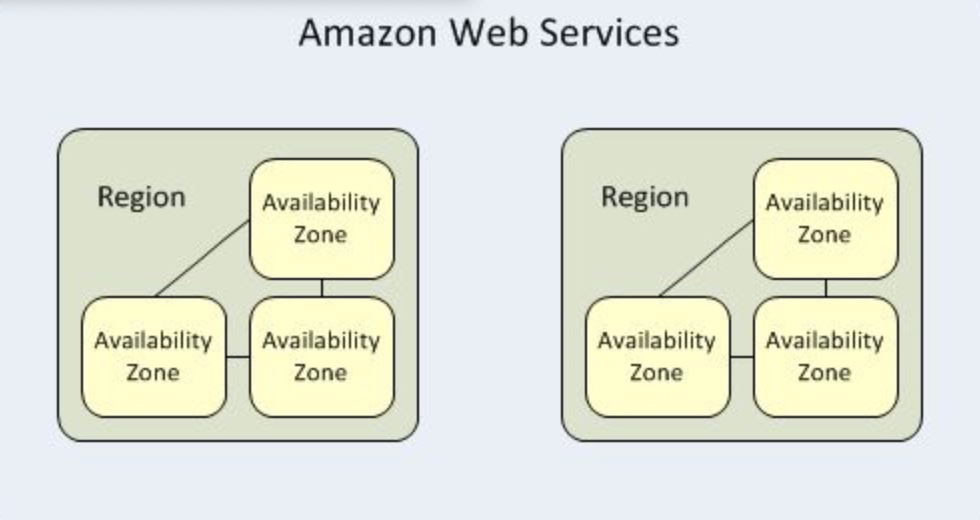
(1)容灾
例如:所在区(AZ)在物理上独立的意义是:独立的机房,独立的供电系统,独立的 ISP 接入系统等。这保证在一个 AZ 完全挂掉的情况下(比如电力故障,网络故障,甚至修路施工队的愚蠢的「实习生」挖断了光缆导致的 ISP 故障等),你的应用在另一个 AZ 还能正常使用。
(2)安全
例如:不同的所在区(AZ)就好像被隔离的沙箱,可以保证一定的安全性。还可以通过 IAM(Identity and Access Management)对不同 AZ 的EC2 实例上运行的应用程序提供安全凭证。
(3)性能
例如:不同的所在区(AZ)的EC2 虚拟机之间,可通过内部 IP 地址访问,提高传输性能。
1、建议尽量把 EC2 的虚拟机放在同一个所在地。
2、建议能用内部 IP 地址就尽量使用内部 P 地址。否则可能会收费。
(2)开始使用
1、网络服务(Web Services)接口
通常是同时提供 SOAP 和 REST 两种,另外还有一种类似 REST 的网络服务接口,叫作 Query AP,是把参数都使用查询字符串(query string)传送。
响应数据都是用 XML 格式。
2、AWS Management Console
即浏览器上的网页。
3、EC2 API Tools
可用来操作 EC2 的所有功能,是我最常用的工具。
4、AWS SDK
例如 for IOS or Android 的 SDK。
(3)注意事项
AWS 为了维持一定的服务质量,通常都会限制每个请求可以占用的时间,比如说 S3 或 Simpledb 如果请求的时间太长,会直接响应错误。
另外,为了应付可能的网络瞬间断线(不论是 AWS 内部或是因特网),有时客户端会收到状态码“500 Internal Server Error”或是“503 Service Unavailable”,通常这些错误都是可以重试的。重试的逻辑最好是用所谓的 exponential backoff(指数地等待),也就是每重试一次,应该要等久一点,才能再重试。使用 “exponential backoff” 可以让我们的应用程序避免受到单一错误的影响,最好是再配合异步的作业流程,让终端用户可以不用一直等待结果。
一般的公式是,第 n 次重试的时候,在 0~2"-1 之间,随机选一个数字作为等待的时间。比如说,我的单位用 100 毫秒(millisecond),也就是刚刚的结果乘以 100 ms,第一次重试的时候,我可以在 0~100 之间选一个毫秒,第二次重试,就是 0~300 之间选毫秒,当然你可以选适合的单位,但是重试要有一个极限,例如限制最大重试次数。
第三章 AWS上手必备工具
略
第四章 AWS基础:S3与云端存储服务
AWS 跟随了计算和存储分离的先进理念。
以存储功能来说,AWS 有 S3 (Simple Storage Service,简单存储服务)、Simpledb(简单数据库)及 RDS (Relational Database Service,关系型数据库服务)可以用。
EBS 虽然也是存储功能,不过是专属于 EC2 的。
区别:S3 提供的是像文件一样的一般性存储功能,而 Simpledb 是非关系型的数据库,RDS 则是 AWS 提供的关系型数据库服务。
1、简单存储服务:S3
(1)适用场景
不论你做什么样的网络应用,几乎都会碰到一个常见的使用情境,就是访问动态产生的数据。比如说,存储用户上传的照片,在网页上展示出来,或是让用户上传 PPT 文件,然后转成网页让人观看,或是存放每天爆增的日志文件或备份文件。这些使用情境通常有一个特色,就是你不知道数据量会增长得多快。
以标准存储来说,S3 的持久性(durability)是 99.999999999% (11 个 9),也就是如果你存了 1 万个对象在 S3, 在 1000 万年内オ会损失一个对象,可以说是超高的持久性。如果使用低备份存储来存对象,那持久性是 99.99% (4 个 9),也就是如果你存了 1 万个对象在 S3, 在 1 年内会损失一个对象。
低备份存储很适合存储那些非原始来源的文件,例如图片文件的缩图。如果缩图坏了可以从原图再产生。因为低备份存储的收费大约只有标准存储的 67%,所以如果存储的数量大的话,用低备份存储可以省下不少钱。如果这个对象消失了,之后对这个对象的任何操作,S3 都会响应 HTYP 状态码“405”(Method Not Allowed),让我们的系统可以从原始的文件再次产生这个衍生的对象。
(2)基本概念
S3 的两个组成层次是容器(bucket)和对象(object)。
1、容器
一个容器可以放无限个对象。
容器名称(bucket name)在 S3 里必须是唯一的(unique),这是因为每个对象都有唯可识别的 URL。一个账号可以建立 100 个容器,不过一般不需要那么多,多了反而难管理。我建议每一个应用或服务开一个容器就够了。
因为,和 EC2 类似,S3 的容器也有地区的架构。但和 EC2 不同的是,S3 的容器是全 AWS 有效的,而不是地区内有效的(region specific)。也就是说,如果笔者在“US- Standard”这个地区开一个叫“test”的容器,所有 AWS 的用户在所有地区就不能再开一个叫“test”的容器了。
2、对象
每个对象大小的限制是 5 TB。
(3)使用
现在选择地区的条件很简单,就是尽量和你的主机放在一起。以我们使用 EC2 来说,就是和 EC2 放在同一个地区就对了,因为在同地区内,EC2 和 S3 间的网络传输是不收费的,当然也有低网络延迟的好处
S3 同时支持“http”与“https”。
(4)对象版本
容器可以设置成记录对象版本(versioning),主要功能是:避免不小心用相同的对象名称覆盖了对象,或是不小心删除了该对象。我不建议使用“对象版本”的功能来管理对象,最好只用来记录对象的历史版本,因为版本识别码(version ID)是 S3 自动产生的,我们的程序没有控制权。而且对象的 URL 会多“versioned”参数,自己的系统在操作 S3 对删除(Delete)也是类似,S3 产生新的版本识别码,但是没有对象内容,而是一个“删除记号”(delete marker)。所以读取对象,但是没给版本识别码,会得到最新的版本。旧的版本还是可以用版本识别码读取得到。要永久删除一个版本,也要在做除操作的时候,指定版本识别码。
(5)标头(headers)及其他数据
有一些标头信息,建议每次在存储对象的时候,最好要加上去,方便日后读取。S3 有偷窥(peek)对象的功能,也就是只读取这个对象的标头信息。这在对象很大的时候很方便,我们可以先看标头信息,再决定要不要把这个对象读取下来。
1、建议添加的标头:
Content-Length:也就是对象的长度,大部分的函数库会自动加上去。
Content-Type:对象的类型,是 MIME Type 格式,大部分的函数库会依附文件名自动加上去,不过最好是自己明确地给定,比较不会有问题。
Cache-Control: HTTP 的缓存控制,一定要明确写清楚缓存的时间,如果这个对象不能缓存,也要注明不可以缓存。这在网站速度最佳化以及和 Cloudfront 合作的时候非常重要。
2、另外以下这些标头,可以视需要加上去:
Content-Disposition:如果想要实现用户单击链接的时候,浏览器自动另存新文件,可以加这个标头。例如设成:“Content-disposition: attachment; filename= test",Pdf 就会自动存档成 “test.pdf"。
Content-Encoding:通常用在压缩软件压缩过的对象,需要加这个标头。例如“Content- Encoding:deflate”。
Last-Modified 和 Content-MD5: 如果正确地更新这两个标头(可以只用其中之一),就能够知道 S3 上面存储的对象和本地有没有差异,能作为快速比对版本的用途。“x-amz-meta-*”:用户自定义的元数据,以“x-amz-meta-”开头。例如,我可以加上这个对象在关系型数据库的数据表和识别码对应,以下的例子,代表这个对象是在“photo”数据表,“id”是 92814:
X-amz-meta-entity: photo
x-amz-meta-entity-id: 92814
(6)访问控制列表(Access Control List)
容器和对象可以个别设置访问控制列表,如果对象不设置的话,就会继承容器的访问控制列表。
但是不建议对容器设置访问控制列表,而是直接对对象设置比较好。
(7)对象名称浏览(key listing)
S3 并没有目录的概念。
但可依对象名称来浏览,简单讲就是分页的功能。所以即使不知道对象的名称,也可以用浏览的方式,知道有哪些对象存在于 S3 容器里面。
可以理解成 search + pagination。
(8)多部分上传(Multipart Upload)
先把大文件分成许多小文件,然后再分别上传这些小文件。如果一个小文件上传挂掉了,只要重传那个小文件就可以了。你甚至可以只拥有一部分文件就开始上传。
最多可以分成 1024 份小文件。
(9)日志记录(logging)和范围读取(Range)
略
2、简单数据库:Simpledb
(1)适用场景
1、非关系型数据库
简单数据库(Simpledb)提供了比 S3 高级一点的存储服务,提供非关系型数据库服务。
类似市面上的如 Cassandra、Hbase、Hypertable、COUCHDB、Mongodb。
2、分布式
Simpledb 一样也是分地区,如果你有用 EC2,通常建议跟 EC2 在同一地区。
(2)数值数据
Simpledb 是没有数据类别,所有值都是 UTF-8 的字符串。虽然数据库的读写变得很容易,但是在处理数值数据上,应用层要处理更多事。
(3)查询
每个到 Simpledb 的查询,在返回结果里面都有一个叫“Box Usage”的数据,这个值表示这次查询用了多少系统资源。“Box Usage”会被查询的复杂度和数据的存储结构所影响,这个值越高,表示这个查询越昂贵。你可以把它想成是 CPU 利用率,因为这个值不包含存储和传输的资源。
昂贵不仅表示 Simpledb 的运算资源消耗得多,而且 Simpledb 也是用“Box Usage”来收费的。
如果查询时间超过 5s, 会得到“Request Timeout”的错误,这时再重试通常也没有用,因为这个查询就是无法在 5s内完成,解决之道是针对査询去做优化。
空值查询:
因为空值是没有建索引的,所以“is null'”是整个 Domain 扫描。如果要用空值的数据很多,又要用来查询,可以用特别的值存储为空值,例如:字符串 ”null“。
(4) 数据分割(partitioning)
数据分割也有水平和垂直两种。
水平分割是指同一种数据存储在不同的数据库实体里面,例如把“user”数据表,ID 小于 1000 万的存在第台,D 小于 2000 万的存在第二台……
垂直分割则是把不同种数据存储在不同的数据库实体,例如把“user”数据表存在第一台,“product'”数据表存在第二台……
垂直分割比较容易做到,而且还能支持原来的关系型数据库的功能,如联结查询。
水平分割就会让关系型数据库变得非常不好用了,必须要在应用层去额外处理许多工作,如合并查询数据、排序的查询等。
非关系型数据库通常使用水平分割,因为水平分割能提供最好的机器利用率以及高可用性、高可扩展性。
水平分割的做法常见的有两种:
1、依主键的值的范围来分
例如,第 0 到 100 万笔数据存在 A 存储空间,第 100 万到 200 万数据存在 B 存储空间。
2、是对主键做散列函数
例如,有 4 个存储空间(通常要是 2 的整数次方),先对主键做 MD5 计算,再对 MD5 的值对 4 取余数,就可以决定要存到哪个存储空间。
缺点:最大问题就是存储空间的数目不能随意改变,如果要改变,通常代表着要做数据转移。
(5)最终一致性
Simpledb 是分布式的数据库,存有多份副本(replicas)。每当有改变值的时候,Simpledb 要同步这些副本。而在一致性上面是用最终一致性(eventually consistent)的概念,也就是允许在某一时间点,集群内会有不一致的数据,但是最终会一致。
最终一致性的详细解释可以看本文最后。
如果用户 A 更新了一笔“user”数据之后,用户 B 连接到还没更新这笔数据的 Simpledb 集群节点,会读到旧的数据。这是一般(默认)的使用情境,叫最终一致性读取(eventually consistent read)
如果这不适合你的需求,那么 Simpledb 提供了另一种读取数据的方式,叫一致性读取(consistent read)。用一致性读取就不会读到旧的(stale)数据,但是在延迟(latency)和性能(throughput)方面都比最终一致性读取来得差。要使用一致性读取很简单,只要在读取的命令加上“Consistentread=true”这个参数就好了。
但即使是一致性读取,看起来是有点可怕,很容易会把数据弄错,建议使用 Simpledb 提供了“条件式的更新”的做法。
例如卖商品防止剩余库存是负数,就可以把条件设为库存必须>=要买的件数才能修改。
(6)和其他 AWS 服务合作
例如,因为 Simpledb 的值只能存 1KB,所以可以把 Simpledb 当成索引,用来查询存在 S3 里面的数据。Simpledb 查询到的 Item,有一项属性就是指向 S3 的 URL,可以去读 S3 上的数据。实际上,AWS 的 EMR (Elastic Mapreduce,一种大数据框架)就是这样使用 Simpledb 和 S3 的。EMR 把日志文件存在 S3, 但是把日志文件的索引写在 Simpledb,所以用户能查询 S3 里的数据。
(7)其他
Simpledb 是没有数据纲要(schema)的数据库。
3、关系型数据库服务:RDS
(1)适用场景
RDS(Relational Database Service)提供在云端上的关系型数据库服务(现在只有 MYSQL5.1),你可以把 RDS 看成是特殊化的 EC2, 只提供 MYSQL 的功能。
(2)使用
建议用 INNODB 数据库引擎,因为支持的特性更多,功能更丰富。
(3)维护
备份分自动备份和数据库快照。
第五章 AWS 核心:EC2 与其相关服务
EC2 即弹性运算云(Elastic Computing Cloud)。
AWS 中有很多服务是完全依附 EC2 的,EC2 确实是作为 AWS 的核心服务存在,所以想要真正掌握云计算 IaaS 的实质,对 BC2 一定要有相当程度的了解才行。
(1)使用
EC2 是用 AMI (Amazon Machine Image)作为模板的。
以面向对象程序(Object Oriented Programming, OOP)来比喻的话,AMI 就是类(class),EC2 虚拟机就是实体(Instance)。
AMI 有收费也有免费的。
(2)Instance storage(虚拟机存储)& EBS (Elastic Blocking Store)区别
Instance storage 是 EC2 的 短暂存储(断电后即数据丢失)。
EBS 是 EC2 的长期存储(且可扩充)。
Instance storage 和 EBS 都是完全依赖于 EC2 的存储服务。
基于上述两者分别有不同类型的 EC2 虚拟机,即: S3-backed 虚拟机和 EBS-boot 虚拟机。
但这两者的区别,现在已经没必要了解了。因为目前几乎 EC2 都是基于 EBS-boot。
如果想要了解更多,可以看:You Should Use EBS Boot Instances on Amazon EC2
(2)弹性 IP 地址
每个 EC2 虚拟机在开机以后,都会配发一个外部 IP 地址(public IP address),以及一个内部 IP 地址(private IP address)。这两个 IP 地址,在虚拟机的生命周期里面,可能会改好多次。
使用外部 IP 和内部 IP 有什么差别?
在 EC2 环境内的网络联机,最好都使用内部 IP。可以确保联机不会有较大的延退(latency)。
EC2 虚拟机进入“running”(开机)的状态时会配发 IP 地址,在每次“reboot”(重新开机),以及“stop”(暂停)再“stat”(启动)的时候,EC2 虚拟机都会重新配发 IP 地址(外部及内部)。这对于一些公开服务的服务器,例如网页服务器来说,很不方便,所以 AWS 提供了弹性 IP 地址(Elastic IP addresses, EIP)的功能。
弹性 IP 地址可以让你申请固定 IP 地址,然后把这个 IP 地址指定给一台虚拟机。 如果那个虚拟机挂掉,可以开另一台虚拟机,然后把这个弹性 IP 地址指定给新的虚拟机。这样对远程用户来说,还是连到同一个 IP 地址,只是服务器已经换了。
弹性 IP 只有外部 IP 地址,没有内部 IP 地址。
(3)解决利用 EC2 传送邮件的需求
EC2 的所有外部 IP 地址已经都在反垃圾邮件(anti-spam)服务的策略黑名单(Policy Block List)里面了,所以如果用 EC2 虚拟机去发送邮件,一般是会被退回的。
解决方法就是为邮件服务器申请一个弹性 IP 地址,然后填表格告诉 AWS 这是一台邮件服务器, AWS 会直接去各大反垃圾邮件服务,申请撤消这个弹性 IP 地址的黑名单。
或者,直接使用 AWS 在 2011 年 1 月推出了简单邮件服务(Simple Email Service, SES)。
(4)新机型
EC2 新机器类型:集群运算虚拟机、集群运算 GPU 虛拟机等……
EC2 新机器类型:集群运算 GPU 虛拟机
集群 GPU 运算虚拟机和集群运算虚拟机类似,都是为了应对大量运算(High- Performace omputing, HPC)的需求。
要利用集群 GPU 运算虚拟机的运算能力,就必须使用 NVIDIA 的 CUDA (Compute Unified Device Architecture) 平行运算架构,开发者可以用多种语言来开发 CUDA 的程序, 如C/C++、Java、Python、Ruby、FORTRAN 等。
第六章 AWS 高级:实现 EC2 部署策略
待写
第七章 AWS 架构关键 1 : 组建高可扩展性系统
1、什么是可扩展性
可扩展性(scalability),是系统的一种性质,指的是投入的运算资源,与能够得到的结果产出量之间的关系,这个关系会受到输入工作量的多寡来影响。
以网络应用来说,可以用每秒的服务请求数(输入),和每秒可以完成几个服务请求(输出)来计算。
对于增加/减少运算资源以提高服务能力有两种模式:
1、向上延展(scale up)/ 向下延展(scale down),又叫垂直延展(scale vertically)
向上延展是指增加单一节点的运算资源,例如增加 RAM,或是增加机器上的 CPU、网卡。
2、向外延展(scale out) / 向内延展(scale in)
向外延展是指增加更多的运算节点,理论上无限,但是受到通信的限制。
云计算在这里,可以发挥很大的作用,因为动态调配资源正是云计算的长处。
比如传统系统很难实现向下延展和向内延展,因为硬件花费已经支出了。AWS 可以让你在几分钟内减少运算资源,不论是向下延展或是向内延展。
云计算本身是方便实行高可扩展性的系统架构,但是如果你的系统本身不具备可扩展性,那你就不能指望把系统放上云计算的环境就自动变成高可扩展性。
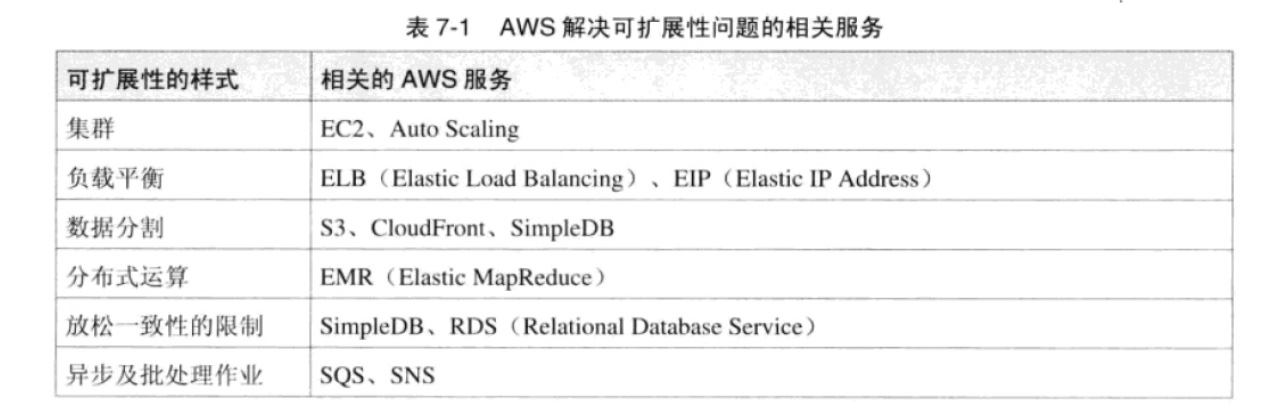
2、常见的高可扩展性架构模式
1、使用集群(clustering) + 负載平衡(load Balancing)的机制
2、数据分割(partitioning):垂直分割(vertical partitioning)+ 水平分割(horizontal partitioning)
3、分布式运算(distributed computing):如 Hadoop
4、放松一致性的限制(relaxed consistenc):例如非关系型数据库
5、异步(asynchronous)及批处理作业(batch)
异步在下面说到消息队列时还会进一步提到。
3、如何实现有效率同步联机
一般我们希望系统是无状态的(stateless),如此一来,节点间不用同步数据,每个服务请求也不用一定找同一台服务器。不过这是理想状态,实际上真正使用的网络服务,是很难完全达到无状态的,所以最好能用以下的策略来有效率地同步联机状态(session):
1、减少联机状态(session)的内容
2、使用简单的数据形态
尽量存简单的数据形态,如 int、string 等,避免存复杂的对象图谱(object graph),因为在同步联机状态的时候,序列化/反序列化(serialize/ deserialize)可能会造成大量的额外运算负担。
3、使用独立的联机状态存储库:例如数据库或是 memcached 集群。
4、AWS 解决可扩展性问题的相关服务
5、负载平衡
(1)在 AWS 上负载平衡的几种做法
1、循环轮替(Round robin DNS)
2、软件的负载平衡
针对同一个所在地
3、弹性负载平衡(Elastic Load Balancing, ELB)
针对不同所在地
4、全域服务器负载平衡(Global Server Load Balancing, GSLB)
针对全球范围。
(1)Round robin DNS
原理:就是在你的 DNS 设置上,把你的对外服务器的 IP 地址都对应到同一个域名上。用户端在査询这个域名时,排在第一笔的 IP 地址会一直更换。
缺点:用 Round robin DNS 的缺点还不少,不过主要都是在更改集群节点的时候发生的问题,比如:
1、由于 DNS 记录有 TTL (Time to live)的设置,用户端很可能只査询一次,还没逾时之前就不査询了。如果想把一个挂掉的集群节点移出 DNS 记录,用户端可能要很久以后才会看到。
2、不光是 TTL,DNS 査询记录在很多地方都有缓存,无法单靠设置 DNS 记录就能有效地更新客户端的 DNS 记录。例如 OS 会有 DNS 缓存,Java1.4 默认的行为是永久缓存 DNS 记录(直到 JVM 终结),浏览器也可以有自己的 DNS 缓存。
3、另外的一点,灵活性较差,不能控制用户端要使用哪一个 IP 地址来联机。
(2)软件的负载平衡
许多的网页服务器或应用程序服务器都有负载平衡的功能,像最常见的 Apache server、Lighttpd、nginx、varnish、Tomcat 等。也有专门的负载平衡的软件,例如 LVS、Pound 等。
(3)弹性负载平衡(ELB)
当 ELB 分派请求给负载平衡器内的虚拟机时,是完全平均分配给每个所在地的。ELB 不会考虑每个所在地内的虚拟机数量或大小。
所以如果使用多个所在地,要开始使用 ELB 的话,维持每个所在地间的运算资源的平衡是很重要的。最好的做法就是每个所在地,里面有一样的机器类型和一样的虚拟机数目,让 ELB 分配服务请求。
(4)全域服务器负载平衡(GSLB)
全域服务器负载平衡是一个很大的议题,通常需要和 ISP 合作或专门提供这个服务的公司才能达到。目前 AWS 也只有 Cloudfront 能够达到全域服务器负载平衡的功能,其他像 ELB 也只能达到同一地区不同所在地的负载平衡而已。
6、自动延展(Auto Scaling)
使用 Auto Scaling 的话,一定要会用 Cloudwatch。
在收费方面比较特别,Auto Scaling 本身并不收费,只计算 Cloudwatch 的收费。
(1)自动延展组(Auto Scaling Group)
自动延展组是用来管理自动延展行为的单位,代表着一群在 EC2 上的虚拟机如何增加或减少的规则。和 EC2 的概念一样,自动延展组也是只在一个地区内有效的。
设置包括:
启动设置(Launch Configuration):是开启 EC2 虛拟杌时所需要的参数。
触发器(tigger):这是定义如何触发自动延展组的延展操作。包括:时间间隔(Period)及突破时间门槛(Breachduration)。
通过 Cloudwatch 作为数据输入。
延展操作(scaling activities):是一个独立的操作,代表对自动延展组内的机器数量的增减。
地区(region)及所在地(availability zone)
设置自动延展的参数,需要更了解你的系统,才能达到好的效果。一般来说太频繁的增加、减少集群里的节点,很容易会增加额外的负担,反而拖累整体的性能和输出量。
(2)重新平衡(rebalancing)
Auto Scaling 会试着把虚拟机均匀地分布到每个所在地。但是,有时候有些所在地的容量(capacity)不够,或者有的所在地失效,Auto Scaling 可以在不受影响的所在地内开机器,等到原本的所在地恢复正常,Auto Scaling 会自动重新平衡(rebalancing)各所在地内的虚拟机的数目。
重新平衡时,Auto Scaling 会先开新机器,再关掉机器,所以不会影响系统的服务能量。因为是以这个原则来执行重新平衡,所以在重新平衡的时候,有可能会暂超过这个自动延展组所设置的机器上限。这只有在系统已经逼近机器数目上限,而且又需要重新平衡时才会发生。不过,Auto Scaling 有限制,在重新平衡时,不会超过所设置的机器数目上限的 10%。
第八章 AWS 架构关键 2 : 异步消息构建策略
1、什么是异步消息传递
前面提到,要建立高可扩展性系统很常见的一个做法是,在分布式的系统里使用异步 (asynchronous)传递消息的架构。
异步的好处是能让用户端不用一直等待回应,也让服务端有机会调节运算的资源。
缺点当然就是比同步的系统还要复杂。
2、消息导向中间件
“消息导向中间件(Message-oriented middleware, MOM),又叫面向消息的中间件,是支持在分布式系统之间发送和接收消息的软件或硬件基础结构。基于 MOM 的系统允许通过异步交换消息来进行通信。
它的发展很早,所以市场上有很多商业产品,像 IBM MQ、Microsoft MQ,开放源码的产品也不少,像 Apache Activemq、Apache Qpid、Rabbitmq。
“消息导向中间件”的标准大多是产品制定的,像 IBM MQ、Microsoft MQ、JMS 都自有一套标准,公开的也有 AMQP (Advanced Message Queuing Protocol)标准。消息传递发展到现在有所谓的 “企业服务总线”(ESB)及“服务导向架构”(SOA)等延伸的概念。
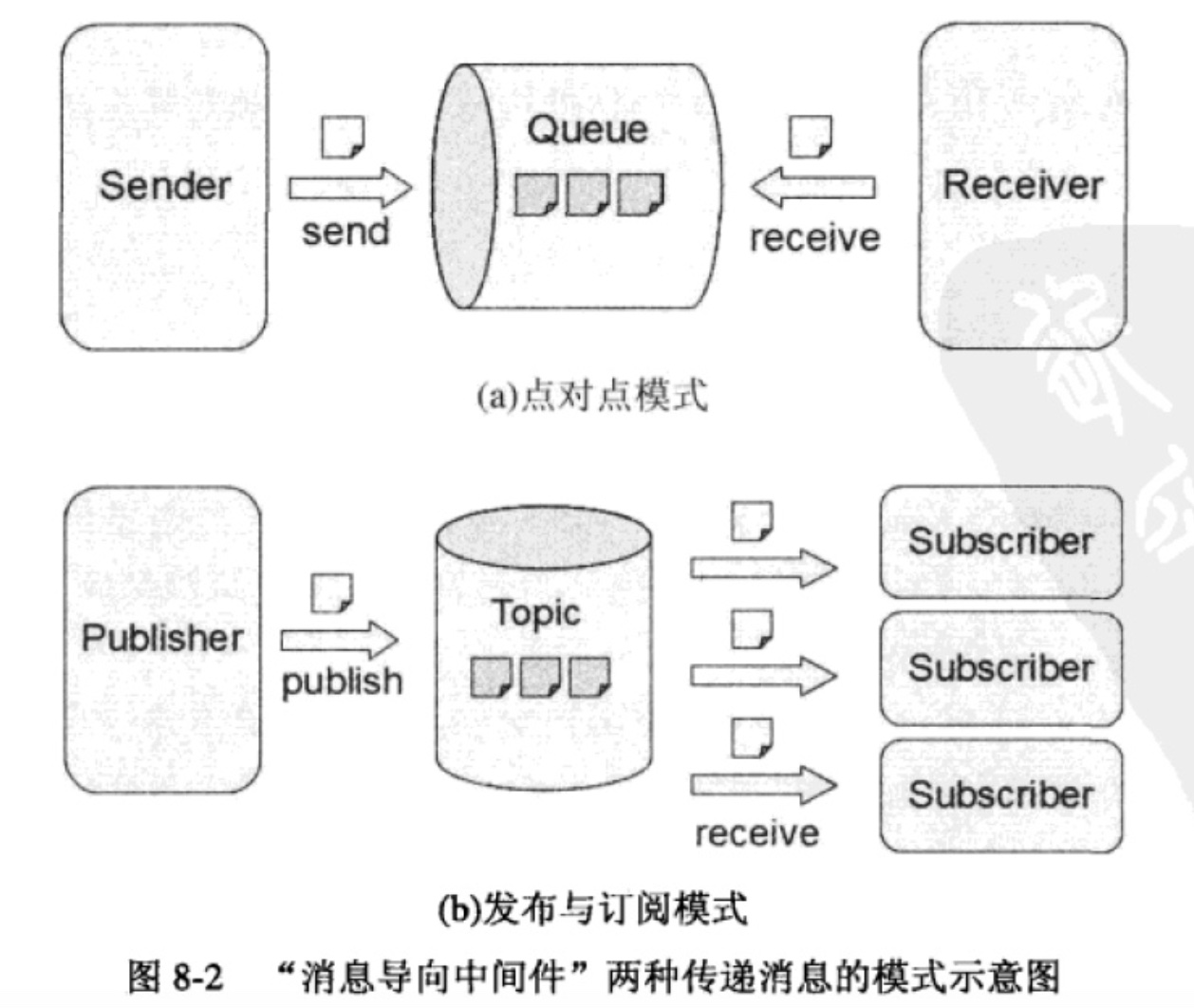
3、消息导向中间件 传递消息的模式
1、点对点模式(Point to Point)
2、发布与订阅模式(Publish and Subscribe)
详细见下图。
目前 AWS 有两个服务是作为消息传递的用途:
1、SQS (Simple Queue Service)的模式是点对点。
2、SNS (Simple Notification Service) 就是发布与订阅。
4、AMS 的简单队列服务(SQS)
简单队列服务(Simple Queue Service, SQS)基于点对点模式(Point to Point)。
优点:分布式
缺点:
1、没有公开标准:移植性差。
2、因为基于分布式,所以不保证“先进先出”。
3、对于多个分布式节点,用取样(sampling)的方式读取消息。所以你不能预期,明明已经写入队列的消息,马上就能读得到。
4、因为基于分布式,有可能拿到已被删除的消息。不过也可以解决。就是设计你的系统,能够接受同一个消息多次,而不会有数据错误,也就是实现“幂等函数”(idempotent function)。
5、单条消息的最大限制为 8 KB。如果消息的大小超过就必须把内容先存到别的地方了,例如 S3 或 Simpledb,然后把真正内容的 URL 写在消息里面,再传出去。
(1)消息与消息队列
Queue URL:这是在建立新的 Queue 的时候,会产生代表这个 Queue 的 URL。
控制 Queue 的权限,是使用 AWS 的访问权限策略语言(APL)来描述的。
消息识别码(Message ID):是 SQS 给每个消息的识别码。
(2)消息被读并处理
接收存根(Receipt handle):每次成功读取一个消息时,SQS 会发一个接收存根给你。这个接收存根代表一个读取消息的操作,之后要删除或修改这个消息,都要使用接收存根。也就是说不能知道消息识别码就把这个消息删除,而是一定要先读过才行。每次读消息拿到的接收存根都不同,但是只有最新的可以成功地删除或修改消息。
在一般的消息导向中间件系统里,也有类似的做法,就是接收者要回复
确认信号(ACK),消息中介者才把消息从队列里删除。
(3)消息被读却迟迟不被处理
为了避免一个客户端把消息读出来之后,一直不处理这个消息(通常是挂掉了),例如上面说的不拿着接收存根去处理该消息(或者不回复 ACK),造成其他用户端不能处理这个消息,所以 SQS 有“读取逾时”的做法。消息在变成不可读取之后,在“读取逾时”(Visibility timeout)内(默认为 30 s),这个消息不会被读取到。但是如果超过“读取逾时”,这个消息还没被删除,那 SQS 会把这个消息再变成“可读取”(Visible),让其他用户端有机会可以读到这个消息。
在实践中会发生这样的事,就是如果一个消息还处理没完,但是“读取逾时”快到了,又不想放弃,这时候可以延长“读取逾时”。一个消息的“读取逾时”最长只有 12 个小时,不可以再延长了。
(4)消息一直没被读
如果这个消息待在队列里太久(最长 14 天), SQS 也会删除它。
5、AMS 的简单通知服务(SNS)
SNS (Simple Notification Service) 基于发布与订阅模式(Publish and Subscribe)。
SNS 目前支持以下的订阅后的通知方式:
E-mail、HMIP、HTTPS 、SQS。
第九章 AWS 架构关键 3 : 高可用性的云计算
1、什么是可用性
可用性(availability)的计算方法是,在一段时间内(通常是一年),系统可以被使用(uptime)的总时间的比例。
以一年的时间来计算,如果可用性是 99.9% (3 个 9),那么系统离线(downtime)的总时间就是 8 小时多,如果可用性是 99.999% (5 个 9),那么一年只能离线 5 分 15 秒。
2、CloudFront
为了让客户端能够更快地下载数据,AWS 提供了 CDN (Content Delivery Network 内容传递网络) 服务,叫 CloudlFront。
(1) CDN
边缘服务器在 CDN 里叫边缘地点(edge location),当客户端向 Cloudlfront 请求一个文件时,Cloudfront 会决定哪一个边缘地点去服务这个请求最快。
如果这个边缘地点没有客户端要的那个文件时,边缘地点就会去来源服务器,把该文件抓下来,并且在这个边缘地点存储一份,也就是缓存。下次有用户来这个边缘地点要这个文件时,就会直接从边缘地点传递给客户端。
放在边缘地点的文件,默认是存储 24 小时。如果文件逾时(expiration)之后,当下次又有用户请求这个文件时,边缘地点就会再次去来源服务器读取一次。
(2) 发布单位(distribution)
发布单位(distribution)是 Cloudfront 的部署单位,代表一个来源服务器和一个 Cloudfront 域名的连接。
发布单位:分“下载”(distribution)和“流”(streaming distribution)两种。
来源服务器:可以使用 S3 容器或自定义来源服务器(Custom Origins)。
自定义来源服务器接受来自 Cloudfront 的请求需考虑下面的情形:
Cloudfront 只接收“GET”及“HEAD”服务请求
Cloudfront 忽视查询字符串(query string,也就是问号后面的东西)
Set-cookie 标头会被移除,所以不能依赖 cookie 来响应内容。
自定义来源服务器看到的客户端 IP 是 Cloudfront,所以不能依赖客户端 IP 来响应内容。
自定义来源服务器给 Cloudfront 的回应(response)还要符合若干的特性:略
(3)服务私有内容(private content)
CloudFront 也可设置服务私有内容。例如用户要付费之后,オ能取得一个暂时可用的 URL 去下载文件,或只有某些客户端 IP 地址才能下载。

3、用 Amazon Cloudwatch 监视系统健康
(1)传统
原理:
监视程序和监视器之间的信息传递,一般可以用 SNMP 协议。
收集数据的做法有许多种,一般分成以下 3 种:推(push)、拉(pull)、混合(hybrid)。
用途:
收集系统的信息主要有两个用途:
1、在系统出现缺失的时候,有机会发出警告给管理人员,快速地反映系统的问题。
2、能展望未来。利用过去的数据,可以得知系统可能潜在的弱点,在问题发生之前,有时间解决它。根据长期的资源利用模式,也可以规划将来系统可以改进的方向。可以说是好处多多。
工具:
传统最常用的监视工具就是 RRDTOOL 。
(2)使用 Cloudwatch
“基本监视” 免费。
“详细监视” 收费。
缺点:目前来说,不建议使用 Cloudwatch 来作为完整系统的监视工具,因为有很多局限性。最好自己另外安装监视工具。如果使用 Cloudwatch 的话,也一定要自己把数据存下来。
第十章 AWS 活用策略 :企业云端优化方案
1、数据存储加密
(1)文件层级
对个别文件做加解密处理,通常是传到 S3 或 Simpledb 这种存设备上面,麻烦的地方在于自己要个別处理加解密的步骤。有很多开放源代码(open source)的工具可以用,例如 GNUPG。
(2)文件系统层级
在文件系统层级做加密,因为是透明化(transparently)的,所以存储的时候不用自己另外处理。工具有Encfs 可以用存储设备层级。
(3)存储设备层级
在存储设备层级做加密,可以使用各种文件系统,当然也可以用在 EBS volumes 和 ephemeral storage 上。工具有 dm-crypt 可以用。
2、安全组(security groups)
(1)功能
1、设置来源的 IP 地址范围(用 CDR 表示)
使用防火墙(firewall) 的基本原则,就是只开需要使用的 IP 地址和联机端口(port)。
2、开放 ssh
3、开放 RDP(远程桌面)
等等
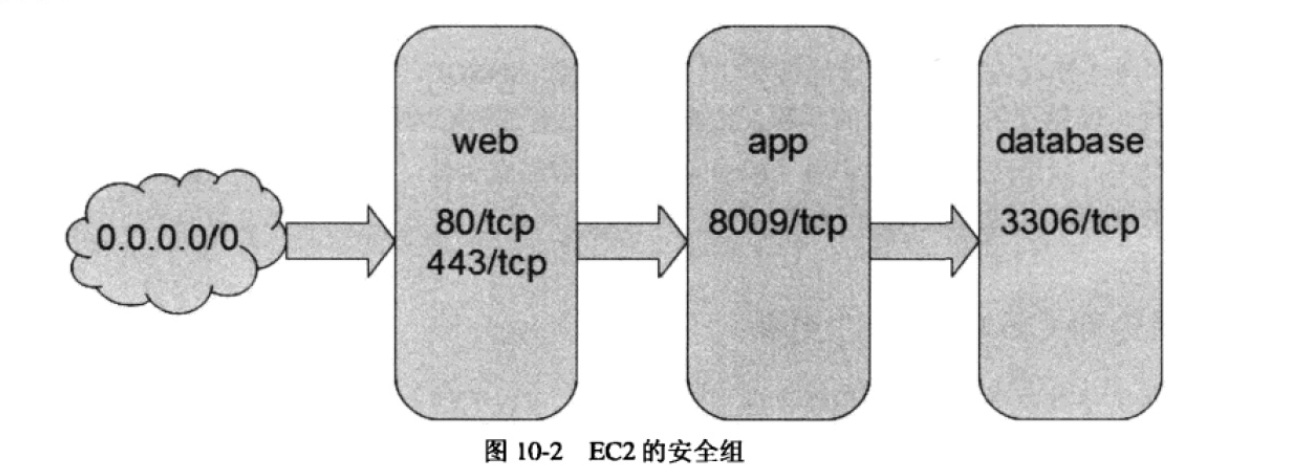
(2)范例
下面是一个常见 web 应用如何设置安全组的范例(见图):
“web”安全组开放了80/tcp和443/tcp给全世界(0.0.0.00)
“app”安全组开放了8009/tcp 给“web”安全组
“database”安全组开放了 3306/tcp 给“app”安全组
(3)不建议用 Iptables
一般来说,EC2 的安全组已经够用了,如果嫌安全组不好用的话,可以自己安装防火墙软件,例如 Iptables,但是不建议,原因如下:
1、在 EC2 虚拟机上安装防火墙软件,代表所有联机和服务请求都要经过这台机器,平白增加一个网络的瓶颈。
2、每一台机器都要去做一样的防火墙设置,非常烦琐。
3、一般防火墙软件是以 IP 地址范国来设置的,但是 EC2 虚拟机的 IP 地址是动态的,增加了设置上的困难和麻烦。如果要自动初始化 EC2 虚拟机,也会增加复杂度。而 EC2 的安全组是以虚拟机所属的组来套用的,不用管 IP 地址的变动。
4、除非很熟悉该防火墙软件,否则很容易就弄成自己也联不进去,只好把那 EC2 虚拟机关掉。而 EC2 的安全组还是可以在 EC2 外面使用 API 修改的。
3、如何善用花在 ANS 上的每块钱
拿 EC2 的机器为例,有 3 种收费方式:
1、默认就是“On-Demand”,也就是没有最低收费,开启就收费。
但是“On-Demand”的费率是最高的。
2、“Reserved Instances”,就是先付一笔年费(有 1 年或 3 年两种),之后只要开启 EC2 虚拟机,就会用比较便宜的费率。
所以如果我们有长期使用 EC2 的打算,就一定要优先考虑使用 Reserved Instances 的收费方式。
3、“Spot Instances”,这是非常特别的一种计费方式,简单来讲就是用“竞标”的方式购买运算资源。
如果目前 EC2 的运算资源还很多,也就是客户要求运算资源很少,那就可以用较便宜的价格买到 EC2 的运算资源,但是如果大家都要用,那价格就会上涨。
跟电费很像,价格随着用电需求变化(例如一年的不同季节,一天的不同时段,定价不一样)
也就是说,如果有大量的工作,但是并不急着完成。那 Spot Instances 就是好的选择。
4、用分布式运算处理大量数据
云端上的 Hadoop: EMR (Elastic Map Reduce)。
待写
5、虚拟私有云 VPC
(1)公有云 & 私有云 & 混合云 区别
公有云不赘述了。
- 成本更低 — 无需购买硬件或软件,仅对使用的服务付费。
- 无需维护 — 维护由服务提供商提供。
- 近乎无限制的缩放性 — 提供按需资源,可满足业务需求。
- 高可靠性 — 具备众多服务器,确保免受故障影响。
私有云由专供一个企业或组织使用的云计算资源构成。
- 灵活性更高 — 组织可自定义云环境以满足特定业务需求。
- 安全性更高 — 资源不与其他组织共享,从而可实现更高控制性和安全性级别。
- 缩放性更高 — 私有云仍然具有公有云的缩放性和效率。
要搭建自己的云计算环境,现在也有很多项目,大多是开放源码的产品。例如:Eucalyptus、OpenNebula、Nimbus、Cloud.com、OpenStack。
混合云通常被认为是“两全其美”,它将本地基础架构或私有云与公有云相结合。
例如,对于基于 Web 的电子邮件等大批量和低安全性需求可使用公有云,对于财务报表等敏感性和业务关键型运作可使用私有云(或其他本地基础架构)。
(2)什么是虚拟私有云?跟私有云有什么区别?
私有云不赘述了。
但虚拟私有云计算(VPC)并不是一个真正的私有云,而是公有云资源供个人使用。所以实际上虚拟私有云计算是一种混合云。
虚拟私有云计算之于公有云计算有如虚拟私有网络(Virtual Private Network, VPN)之于公共网络。
(3)用 AWS 的虚拟私有云扩张既有系统
一般公司(企业)很可能已经搭建了信息系统,如果想要维持目前系统的运行,又想要利用云计算的好处,有什么好的做法可以实现?
可以使用 Amazon VPC (Virtual Private Cloud 虚拟私有云)把现有的数据中心(data center)和 AWS 的运算资源做结合。
VPC 让你可以在 EC2 上面开一个分离的区域,然后用 VPN (Virtual Private Network)联机把这个区域和你的数据中心连接。
(4)使用
待写
其他
根据芬兰国家广播公司 YLE 的报导,芬兰的运输与通讯部已经把 IMB 宽带网络访问权明定为法定权利。自 2010 年 7 月起,芬兰所有的人民,都将享有访问 1MB 宽带网络的权利。并且在 2015 年底之前,再把宽带网络权利提升到 100 MB。
人民有享受网络的权利,真好。
拓展
1、RDBMS VS NoSQL
(1)CAP 理论
在理论计算机科学中,影响分布式系统的一项重要理论就是 CAP 理论(CAP theorem),又被称作布鲁尔定理(Brewer's theorem)。根据 CAP 理论,在分布式的系统里,以下 3 种性质,在同一时间里,最多只能满足两项:
CAP理论的证明:Brewer's CAP Theorem
数据一致性(Consistency, C):所有节点的数据在某一时间点是一致的。
可用性(Availability, A):任一个节点失效不影响其他节点继续工作。
断层容忍性(Partition Tolerance, P):通常发生在网络断线的时候,整个系统被分成两个小系统(partition),也就是有断层。这时候虽然有很多消息会遗失,但是系统能够正常工作。
理解CAP理论的最简单方式是想象两个节点分处分区两侧。允许至少一个节点更新状态会导致数据不一致,即丧失了C性质。如果为了保证数据一致性,将分区一侧的节点设置为不可用,那么又丧失了A性质。除非两个节点可以互相通信,才能既保证C又保证A,这又会导致丧失P性质。
(2)ACID & BASE
关系型数据库强调的是交易(transaction)的 ACID (Atomicity 原子性, Consistency 一致性, Isolation 隔离性, Durability 持久性)特性。
A (Atomicity) 原子性
原子性很容易理解,也就是说事务里的所有操作要么全部做完,要么都不做,事务成功的条件是事务里的所有操作都成功,只要有一个操作失败,整个事务就失败,需要回滚。例如银行的转账。
C (Consistency) 一致性
一致性也比较容易理解,也就是说数据库要一直处于一致的状态,事务的运行不会改变数据库原本的一致性约束。例如现有完整性约束a+b=10,如果一个事务改变了a,那么必须得改变b,使得事务结束后依然满足a+b=10,否则事务失败。
例如从A账户转100元至B账户,同时从B账户转100元至C账户,但是无论哪一个时间点他们三个的余额总是是保持不变的。
I (Isolation) 隔离性
所谓的隔离性是指并发的事务之间不会互相影响,如果一个事务要访问的数据正在被另外一个事务修改,只要另外一个事务未提交,它所访问的数据就不受未提交事务的影响。比如现有有个交易是从A账户转100元至B账户,在这个交易还未完成的情况下,如果此时B查询自己的账户,是看不到新增加的100元的。
D (Durability) 持久性
持久性是指一旦事务提交后,它所做的修改将会永久的保存在数据库上,不会再回滚,即使出现宕机也不会丢失。
但是非关系型数据库强调的是 BASE (Basically Available 基本可用, Soft-state 软状态/柔性事务, Eventual consistency 最终一致性)。
说起来很有趣,BASE的英文意义是碱,而ACID是酸。真的是水火不容啊。
Basically Available 基本可用
基本可用是指分布式系统在出现故障的时候,允许损失部分可用性,即保证核心可用,支持分区失败(e.g. sharding碎片,划分数据库)。
电商大促时,为了应对访问量激增,部分用户可能会被引导到降级页面,服务层也可能只提供降级服务。这就是损失部分可用性的体现。
Soft state 软状态
弱状态也称为软状态,和硬状态相对,是指允许系统中的数据存在中间状态,并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据同步的过程存在延时。Eventually consistent 最终一致性
最终数据是一致的就可以了,而不是时时一致。是指系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。
BASE理论是对CAP理论的延伸,核心思想是即使无法做到强一致性(Strong Consistency),CAP的一致性就是强一致性),也可以采用适合的方式达到最终一致性(Eventual Consitency)。
弱一致性和强一致性相反,最终一致性是弱一致性的一种特殊情况。
放松(强)一致性的要求,可以说是 NOSQL 数据库为了实现高可扩展性、高可用性的取舍(trade off)了。
通常这不是非常严重的问题,“乐观并行控制”(Optimistic Concurrency Control, OCC)可以帮我们解决一部分的问题。
ACID和BASE代表了两种截然相反的设计哲学,在分布式系统设计的场景中,系统组件对一致性要求是不同的,因此ACID和BASE又会结合使用。
2、XX 性的汇总对比
(1)可伸缩性 与 可扩展性 的区别
可扩展性(scalability)是系统的一种性质,指的是投入的运算资源,与能够得到的结果产出量之间的关系,这个关系会受到输入工作量的多寡来影响。
光投入不行,还得有与之相匹配的产出。
可伸缩性(scalable) = 可扩展性。
(2)可靠性 与 可用性 的区别
可靠性(reliability),为一个服务连续无故障运行的时间,无故障运行的时间越长,可靠性就越高。
只要中断就会极大影响可靠性。
可用性(availability)的计算方法是,在一段时间内(通常是一年),系统可以被使用(uptime)的总时间的比例。
极端情况下,中断许多次,但每次恢复的时间极短,可用性也会很高。
在上文说到 CAP 的时候,也提到可用性,即那个 A(Availability):任一个节点失效不影响其他节点继续工作。
这个解释比较专门,不具普适性。
初识云计算 -《AWS云端企业实战圣经》读书笔记的更多相关文章
- 《Go并发编程实战》读书笔记-初识Go语言
<Go并发编程实战>读书笔记-初识Go语言 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在讲解怎样用Go语言之前,我们先介绍Go语言的特性,基础概念和标准命令. 一. ...
- 《Apache kafka实战》读书笔记-管理Kafka集群安全之ACL篇
<Apache kafka实战>读书笔记-管理Kafka集群安全之ACL篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 想必大家能看到这篇博客的小伙伴,估计你对kaf ...
- 《Apache Kafka 实战》读书笔记-认识Apache Kafka
<Apache Kafka 实战>读书笔记-认识Apache Kafka 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.kafka概要设计 kafka在设计初衷就是 ...
- 《Go并发编程实战》读书笔记-语法概览
<Go并发编程实战>读书笔记-语法概览 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客我们会快速浏览一下Go的语法,内容涉及基本构成要素(比如标识符,关键字,子 ...
- 《Apache kafka实战》读书笔记-kafka集群监控工具
<Apache kafka实战>读书笔记-kafka集群监控工具 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 如官网所述,Kafka使用基于yammer metric ...
- 《Apache Kafka实战》读书笔记-调优Kafka集群
<Apache Kafka实战>读书笔记-调优Kafka集群 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.确定调优目标 1>.常见的非功能性要求 一.性能( ...
- 《Java并发编程实战》读书笔记一 -- 简介
<Java并发编程实战>读书笔记一 -- 简介 并发的历史 并发的历史,也是人类利用有限的资源去提高生产效率的一个的例子. 设想现在有台计算机,这台计算机具有以下的资源: 单核CPU一个 ...
- 《Kinect应用开发实战》读书笔记---干货集合
本文章由cartzhang编写,转载请注明出处. 所有权利保留. 文章链接: http://blog.csdn.net/cartzhang/article/details/45029841 作者:ca ...
- 《Java 8实战》读书笔记系列——第三部分:高效Java 8编程(四):使用新的日期时间API
https://www.lilu.org.cn/https://www.lilu.org.cn/ 第十二章:新的日期时间API 在Java 8之前,我们常用的日期时间API是java.util.Dat ...
随机推荐
- linux初学者-软件安装与管理篇
linux初学者-软件安装与管理篇 在linux的学习和工作中需要安装许多的软件.在redhat的linux操作系统下,软件一般都是rpm格式的.以下将介绍一些软件安装和管理的内容. 1.软件名称 在 ...
- Android Studio电脑不支持HAXM的解决办法
Intel HAXM is required to run this AVD. Your CPU does not support required features (VT-x or SVM). U ...
- 【Sublime】设置显示编码格式
Mac 上的 Sublime 显示编码格式,设置方法: 右下角显示的 UTF-8 就是当前的编码格式. 添加如下代码: { "font_size": 18, // Display ...
- 【iOS】edgesForExtendedLayout
在 iOS 7.0 中,苹果引入了一个新的属性,叫做 edgesForExtendedLayou,它的默认值为 UIRectEdgeAll. 当你的容器是 navigationController 时 ...
- 二进制文件安装安装etcd
利用二进制文件安装安装etcd etcd组件作为一个高可用强一致性的服务发现存储仓库. etcd作为一个受到ZooKeeper与doozer启发而催生的项目,除了拥有与之类似的功能外,更专注于以下四点 ...
- React进阶之路书籍笔记
React进阶之路: "于复合类型的变量,变量名不指向数据,而是指向数据所在的地址.const命令只是保证变量名指向的地址不变,并不保证该地址的数据不变,所以将一个对象声明为常量必须非常小心 ...
- python自动化测试框架unittest
对于刚学习python自动化测试的小伙伴来说,unittest是一个非常适合的框架: 通过unittest,可以管理测试用例的执行,自动生成简单的自动化测试报告: 首先我们尝试编写编写一个最简单的un ...
- Pandas 库之 DataFrame
How to use DataFrame ? 简介 创建 DataFrame 查看与筛选数据:行列选取 DataFrame 数据操作:增删改 一.About DataFrame DataFrame 是 ...
- Javaweb表格加载---DataTable
Datatables是一款jquery表格插件.它是一个高度灵活的工具,可以将任何HTML表格添加高级的交互功能. 使用 jQuery Datatable 构造数据列表,并且增加或者隐藏相应的列,已达 ...
- MacOS VSCode 安装 GO 插件失败问题解决
0x00 问题重现 Installing golang.org/x/tools/cmd/guru FAILED Installing golang.org/x/tools/cmd/gorename F ...