(4)一起来看下mybatis框架的缓存原理吧
本文是作者原创,版权归作者所有.若要转载,请注明出处.本文只贴我觉得比较重要的源码,其他不重要非关键的就不贴了
我们知道.使用缓存可以更快的获取数据,避免频繁直接查询数据库,节省资源.
MyBatis缓存有一级缓存和二级缓存.
1.一级缓存也叫本地缓存,默认开启,在一个sqlsession内有效.当在同一个sqlSession里面发出同样的sql查询请求,Mybatis会直接从缓存中查找。如果没有则从数据库查找
下面我们贴一下一级缓存的测试结果
String resource = "mybatis.xml";
//读取配置文件,生成读取流
InputStream inputStream = Resources.getResourceAsStream(resource);
//返回的DefaultSqlSessionFactory是SqlSessionFactory接口的实现类,
//这个类只有一个属性,就是Configuration对象,Configuration对象用来存放读取xml配置的信息
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
//SqlSession是与数据库打交道的对象 SqlSession对象中有上面传来的Configuration对象,
//SqlSession对象还有executor处理器对象,executor处理器有一个dirty属性,默认为false
//返回的DefaultSqlSession是SqlSession接口的实现类
SqlSession sqlSession = sqlSessionFactory.openSession();
//SqlSession sqlSession2 = sqlSessionFactory.openSession();
//通过动态代理实现接口 ,用动态代理对象去帮我们执行SQL
//这里生成mapper实际类型是org.apache.ibatis.binding.MapperProxy
DemoMapper mapper = sqlSession.getMapper(DemoMapper.class);
DemoMapper mapper2 = sqlSession.getMapper(DemoMapper.class);
//这里用生成的动态代理对象执行
String projId="0124569b738e405fb20b68bfef37f487";
String sectionName="标段";
List<ProjInfo> projInfos = mapper.selectAll(projId, sectionName);
List<ProjInfo> projInfos2 = mapper2.selectAll(projId, sectionName);
System.out.println(projInfos.hashCode());//这里和下面那条的查询结果的hashcode是一样的
System.out.println(projInfos2.hashCode());//
sqlSession.close(); sqlSession = sqlSessionFactory.openSession();
DemoMapper mapper5 = sqlSession.getMapper(DemoMapper.class);
List<ProjInfo> projInfos5 = mapper5.selectAll(projId, sectionName);
System.out.println(projInfos5.hashCode());//这里和上面两条的查询结果的hashcode是不一样的

好,我们可以看到,上面两条的查询结果的hashcode一样,第三条不一样,一级缓存生效了
2.二级缓存是mapper级别的,就是说二级缓存是以Mapper配置文件的namespace为单位创建的。
二级缓存默认是不开启的,需要手动开启二级缓存,如下需要在mybatis配置文件中的settting标签里面加入开启
<settings>
<!-- 开启二级缓存。value值填true -->
<setting name="cacheEnabled" value="true"/>
<!-- 配置默认的执行器。SIMPLE 就是普通的执行器;
REUSE 执行器会重用预处理语句(prepared statements); BATCH 执行器将重用语句并执行批量更新。默认SIMPLE -->
<setting name="defaultExecutorType" value="SIMPLE"/>
</settings>
实现二级缓存的时候,MyBatis要求返回的对象必须是可序列化的,如图
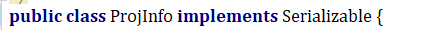
还要在mapper,xml文件中添加cache标签,标签里的readOnly属性需填true 如下:
<cache readOnly="true" ></cache>
<select id="selectAll" resultType="com.lusaisai.po.ProjInfo">
SELECT id AS sectionId,section_name AS sectionName,proj_id AS projId
FROM b_proj_section_info
WHERE proj_id=#{projId} AND section_name LIKE CONCAT('%',#{sectionName},'%')
</select>
我们再来看下二级缓存的运行结果
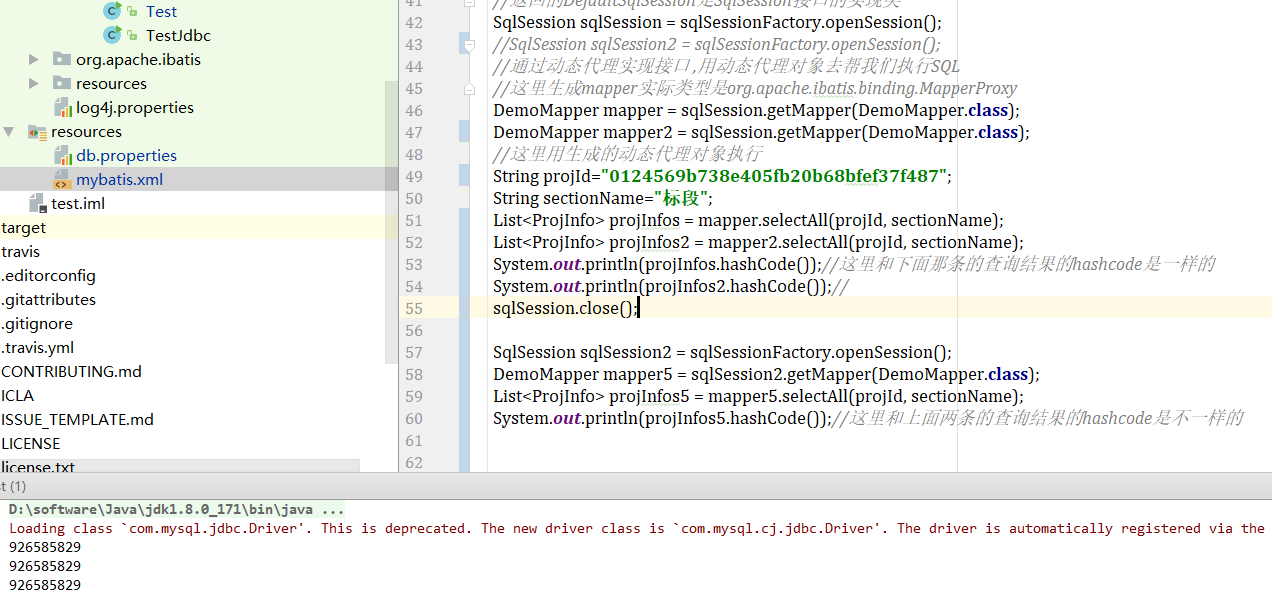
我们可以看到二级缓存也生效了.
下面来看看缓存的源码,大家猜底层是使用什么实现的,前面的流程就不一一看了,主要贴一下缓存的代码,
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
//
BoundSql boundSql = ms.getBoundSql(parameterObject);
CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
//这个跟进去看戏,应该是真正的jdbc操作了
return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
我们可以看到,上面的生成了一个缓存的key,具体怎么实现的就先不看了,看下key这个对象有什么属性吧
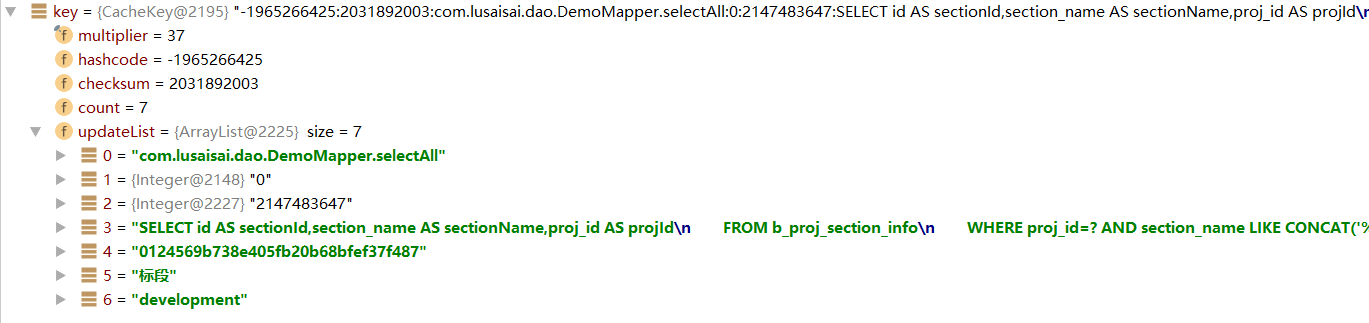
我们可以看到,key对象有这条sql语句除了结果之外的所有信息,还有hashcode等等,我们继续跟进去
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
//MappedStatement的作用域是全局共享的,这里的cache是接口,有多个实现类
Cache cache = ms.getCache();
if (cache != null) {
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, boundSql);
@SuppressWarnings("unchecked")
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
//前面是缓存处理跟进去
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
我们看下Cache 的实现类

有很多,这里就不深究了,继续往下看,我们看下list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql)这行代码,这是处理一级缓存的方法,点进去看下
这里用到我们前面生成的key了
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
queryStack++;
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
//进这里,继续跟
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
return list;
}
我们关注下list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;这行代码,点进去看下
@Override
public Object getObject(Object key) {
return cache.get(key);
}
我截个图,看下上图的PerpetualCache对象底层是怎么实现的
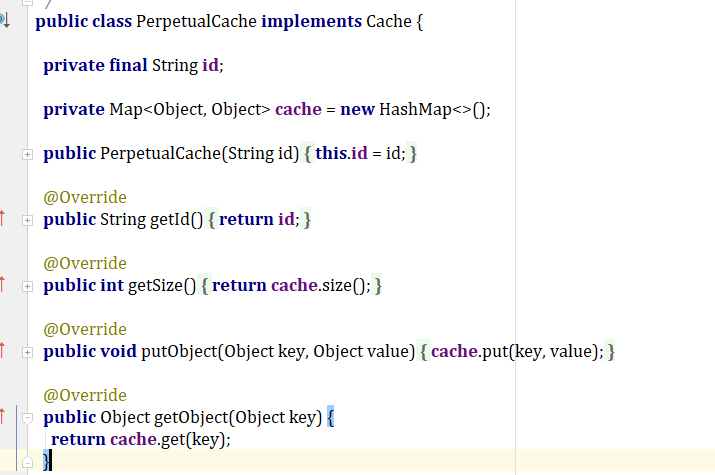
好,很明显了,这里一级缓存是用的hashmap实现的.
下面我们看下二级缓存的代码,上面的List<E> list = (List<E>) tcm.getObject(cache, key);这行代码跟进去
public Object getObject(Cache cache, CacheKey key) {
return getTransactionalCache(cache).getObject(key);
}
继续跟
@Override
public Object getObject(Object key) {
// issue #116
Object object = delegate.getObject(key);
if (object == null) {
entriesMissedInCache.add(key);
}
// issue #146
if (clearOnCommit) {
return null;
} else {
return object;
}
}
截个图看下delegate对象的属性,很多层
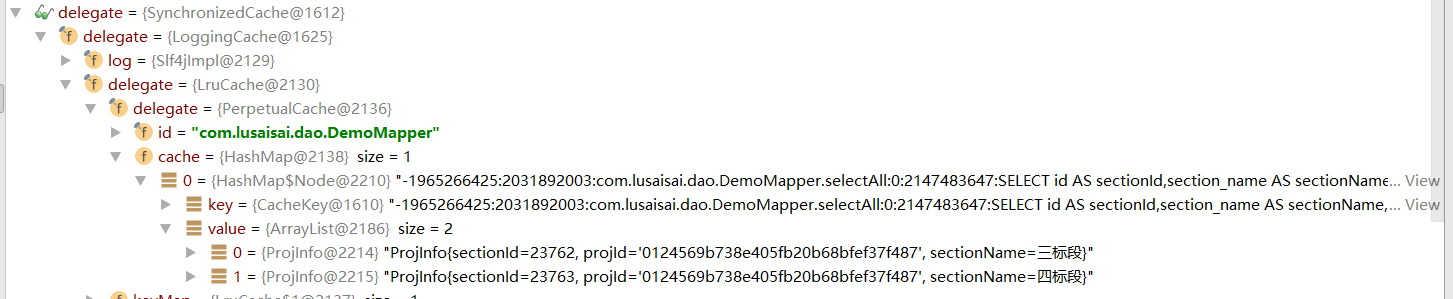
我们可以看到所有数据都在这里了.网上找的图

再来一段缓存的关键代码,这里就是包装了一层层对象的代码
private Cache setStandardDecorators(Cache cache) {
try {
MetaObject metaCache = SystemMetaObject.forObject(cache);
if (size != null && metaCache.hasSetter("size")) {
metaCache.setValue("size", size);
}
if (clearInterval != null) {
cache = new ScheduledCache(cache);
((ScheduledCache) cache).setClearInterval(clearInterval);
}
if (readWrite) {
cache = new SerializedCache(cache);
}
cache = new LoggingCache(cache);
cache = new SynchronizedCache(cache);
if (blocking) {
cache = new BlockingCache(cache);
}
return cache;
} catch (Exception e) {
throw new CacheException("Error building standard cache decorators. Cause: " + e, e);
}
}
好,再来张图总结一下
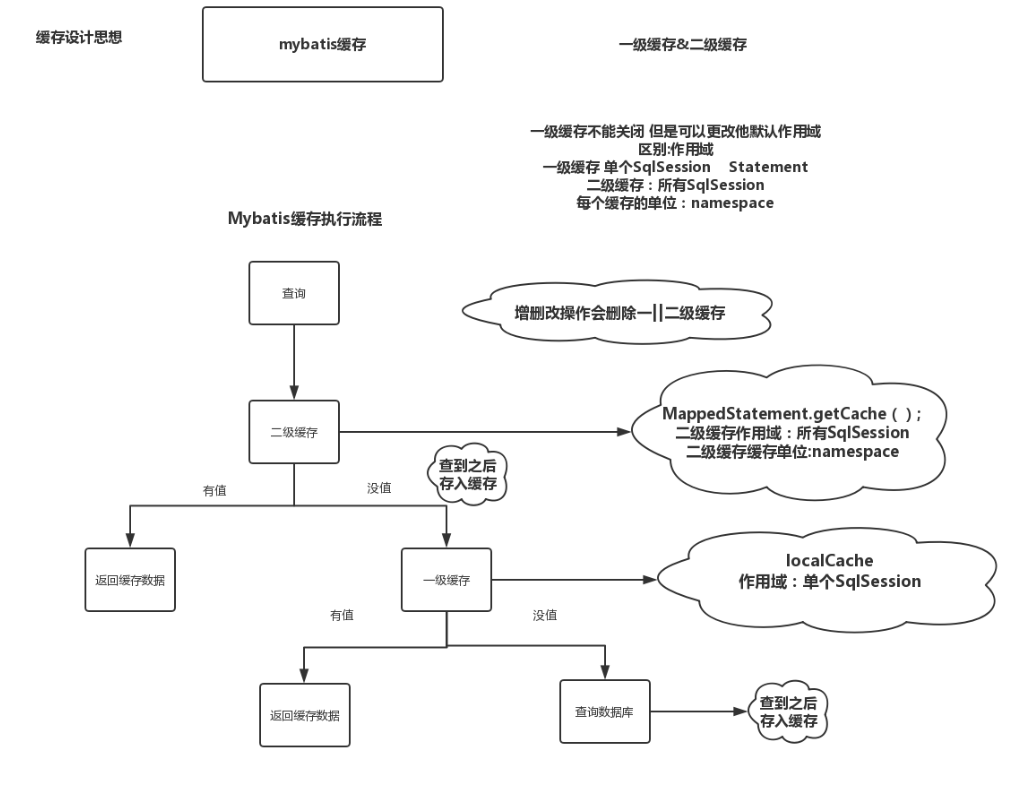
最后,如果我们和spring整合,那么此时mybatis一级缓存就会失效,因为sqlsession交给spring管理,会自动关闭session.
关于如何和spring整合就后面再来讲吧,下面一段时间,我会先研究一下spring源码,spring专题见啦
(4)一起来看下mybatis框架的缓存原理吧的更多相关文章
- MyBatis:二级缓存原理分析
MyBatis从入门到放弃七:二级缓存原理分析 前言 说起mybatis的一级缓存和二级缓存我特意问了几个身边的朋友他们平时会不会用,结果没有一个人平时业务场景中用. 好吧,那我暂且用来学习源码吧.一 ...
- mybatis两级缓存原理剖析
https://blog.csdn.net/zhurhyme/article/details/81064108 对于mybatis的缓存认识一直有一个误区,所以今天写一篇文章帮自己订正一下.mybat ...
- 手写mybatis框架-增加缓存&事务功能
前言 在学习mybatis源码之余,自己完成了一个简单的ORM框架.已完成基本SQL的执行和对象关系映射.本周在此基础上,又加入了缓存和事务功能.所有代码都没有copy,如果也对此感兴趣,请赏个Sta ...
- CodeIgniter框架的缓存原理分解
用缓存的目的:(手册上叙述如下,已经写得很清楚了) Codeigniter 支持缓存技术,以达到最快的速度. 尽管CI已经相当高效了,但是网页中的动态内容.主机的内存CPU 和数据库读取速度等因素直接 ...
- Spring Boot + Mybatis + Redis二级缓存开发指南
Spring Boot + Mybatis + Redis二级缓存开发指南 背景 Spring-Boot因其提供了各种开箱即用的插件,使得它成为了当今最为主流的Java Web开发框架之一.Mybat ...
- Mybatis拦截器实现原理深度分析
1.拦截器简介 拦截器可以说使我们平时开发经常用到的技术了,Spring AOP.Mybatis自定义插件原理都是基于拦截器实现的,而拦截器又是以动态代理为基础实现的,每个框架对拦截器的实现不完全相同 ...
- mybatis源码专题(2)--------一起来看下使用mybatis框架的insert语句的源码执行流程吧
本文是作者原创,版权归作者所有.若要转载,请注明出处.本文以简单的insert语句为例 1.mybatis的底层是jdbc操作,我们先来回顾一下insert语句的执行流程,如下 执行完后,我们看下数据 ...
- SpringBoot 下 mybatis 的缓存
背景: 说起 mybatis,作为 Java 程序员应该是无人不知,它是常用的数据库访问框架.与 Spring 和 Struts 组成了 Java Web 开发的三剑客--- SSM.当然随着 Spr ...
- 【Mybatis框架】查询缓存(一级缓存)
做Java的各位程序员们,估计SSH和SSM是我们的基础必备框架.也就是说我们都已经至少接触过了这两套常见的集成框架.当我们用SSH的时候,相信很多人都接触过hibernate的两级缓存,同样,相对应 ...
随机推荐
- codeforces 264 B. Good Sequences(dp+数学的一点思想)
题目链接:http://codeforces.com/problemset/problem/264/B 题意:给出一个严格递增的一串数字,求最长的相邻两个数的gcd不为1的序列长度 其实这题可以考虑一 ...
- hdu 2895 01背包 Robberies
Robberies Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total S ...
- CSS3 04. 伸缩布局、设置主轴,侧轴方向、主/侧轴对齐方式、 伸缩比例、元素换行、换行控制、覆盖父元素的align-items;控制子元素顺序、web字体、突变字体
CSS3 在布局方面做了非常大的改进,对块级元素的布局排列变得十分灵活,适应性非常强,其强大的伸缩性,在响应式开发中可以发挥极大的作用.(兼容性不好) 必要元素: 指定一个盒子为伸缩盒子 displa ...
- HTTPS页面使用CNZZ统计代码,Chrome显示警告怎么办?
很多站长会遇到一个问题,网站加入CNZZ的JS统计代码后,Chrome浏览器出现警告:阻止跨站解析器阻断脚本通过document.write调用(A parser-blocking, cross si ...
- 【LeetCode】334#递增的三元子序列
题目描述 给定一个未排序的数组,判断这个数组中是否存在长度为 3 的递增子序列. 数学表达式如下: 如果存在这样的 i, j, k, 且满足 0 ≤ i < j < k ≤ n-1, 使得 ...
- myslq5.7安装以及root密码找回
一.mysql安装 创建用户和用户组: groupadd mysqluseradd -g mysql mysql -s /sbin/nologin 解压压缩文件并创建软链接 tar -xvf mysq ...
- .Net基础篇_学习笔记_第六天_for循环语法_正序输出和倒序输出
for TAB 和 forr TAB using System; using System.Collections.Generic; using System.Linq; using System. ...
- 转换地图 (康托展开+预处理+BFS)
Problem Description 在小白成功的通过了第一轮面试后,他来到了第二轮面试.面试的题目有点难度了,为了考核你的思维能量,面试官给你一副(2x4)的初态地图,然后在给你一副(2x4)的终 ...
- IO流——File类(文件流类)
java语言的输入输出操作是借助于输入输出包java.io来实现的,按传输方向分为输入流与输出流,从外设传递到应用程序的流为输入流,将数据从应用程序输入到外设的流为输出流. File类的构造方法: 1 ...
- Java中关于泛型集合类存储的总结
集合类存储在任何编程语言中都是很重要的内容,只因有这样的存储数据结构才让我们可以在内存中轻易的操作数据,那么在Java中这些存储类集合结构都有哪些?内部实现是怎么样?有什么用途呢?下面分享一些我的总结 ...